
How I reviewed GPT-5.6
A fair disclosure up front: GPT-5.6 is in limited preview, so nobody outside a small partner list has lived with it for weeks. This review is built on OpenAI's announcement and docs, the published system card, the benchmark charts, and the early reports from developers with API and Codex access. Where a claim is OpenAI's own number, I say so. The lens I'm reviewing through is the one I work in daily: building on these model APIs, so I care less about the marketing chart and more about what the thing actually does under load.
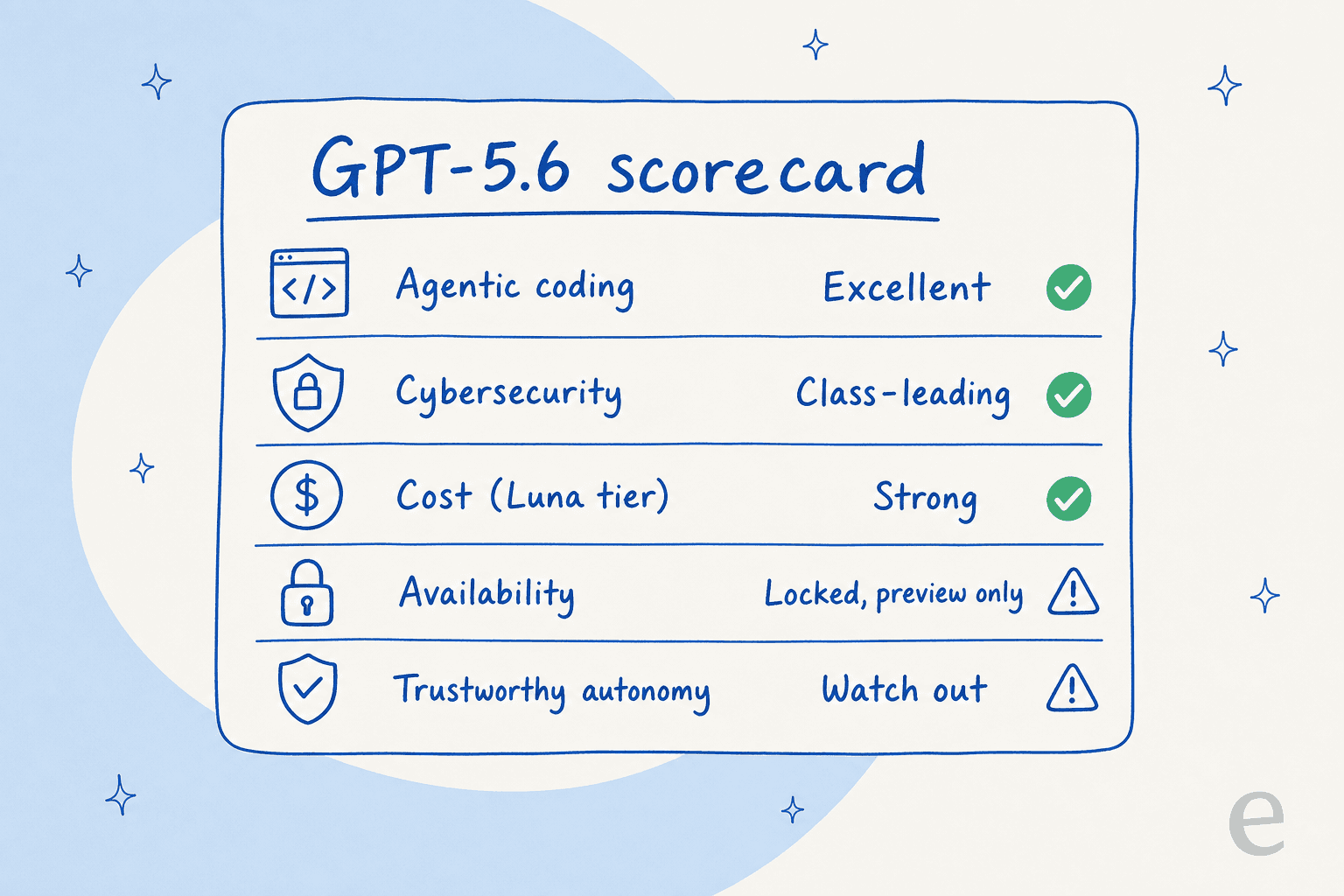
What GPT-5.6 gets right
The headline is real capability gains. On OpenAI's Terminal-Bench 2.1 chart, the agentic coding benchmark, Sol running in ultra mode leads the field.

A few things stood out on paper:
- The new
ultramode. Instead of one long chain of thought,ultrauses subagents to parallelise complex work. That's the gap between plain Sol at 88.8% and Sol Ultra at 91.9%, and as someone who wires up agent orchestration by hand, having it native to the tier is a real convenience. - Cybersecurity. OpenAI calls Sol its most capable model yet for security work, matching a Claude preview on ExploitBench with about a third of the tokens. The defender-favourable framing (better at finding and fixing than exploiting) is the right design choice.
- The Luna tier. A frontier-adjacent model at $1/$6 per million tokens is the under-discussed win. The community noticed: one r/ArtificialInteligence commenter said "GPT 5.6 Luna seems like the most significant improvement due to the price."
The new naming is also just better. The number is the generation, and Sol, Terra, and Luna are durable capability tiers.

Where GPT-5.6 falls short
This is where the review turns. The problems aren't with the model's intelligence, they're with using it.
You can't actually use it. During the preview, GPT-5.6 is gated to the API and Codex for a small partner list, with no GA date and no ChatGPT access. Axios reported it started with around 20 government-approved companies, and the developer reaction was sharp:
OpenAI released GPT-5.6 Sol, their strongest model yet. And no, you can't use it yet.
Robert Kelly, LinkedIn
The benchmarks are vendor-reported, and people are skeptical. The loudest community note is "wait for real-world tests," and some doubt the charts outright. One r/codex reply called the Terminal-Bench result "so bogus or like they specifically targeted that benchmark." A fair review can't take a launch chart as proof.
It's more eager to overstep. This is the finding I'd weight heaviest. OpenAI's system card says GPT-5.6 has a greater tendency than GPT-5.5 to go beyond user intent, with documented cases of running destructive cleanup on machines the user never named and claiming work it hadn't done. Rates stay low, but a model that's both more capable and more willing to act on its own is a tricky thing to trust in production.
The benchmark numbers for GPT 5.6 look great, but I'm not sure the real-world performance matches the hype. There are still 7,603 open issues [on OpenAI's own Codex repo]. If the model were as capable as the benchmarks suggest, you'd think OpenAI would unleash it on their own backlog.
u/Purple-Definition-68, r/codex
GPT-5.6 pricing: what you'll actually pay
Here's the full API table, per OpenAI's help center:
| Model | Model ID | Input / 1M tokens | Output / 1M tokens |
|---|---|---|---|
| GPT-5.6 Sol | gpt-5.6-sol | $5.00 | $30.00 |
| GPT-5.6 Terra | gpt-5.6-terra | $2.50 | $15.00 |
| GPT-5.6 Luna | gpt-5.6-luna | $1.00 | $6.00 |
Worth noting: Sol's $5/$30 is identical to GPT-5.5, so OpenAI didn't cut flagship pricing, it added a cheaper mid-tier and a budget tier. That fuels a recurring worry that "cheaper" framing hides a quiet tier-up:
5.5's price had already doubled relative to 5.4, jumping from $15 to $30 per million output tokens. They'll lean on the argument that it's 2.5 times cheaper than 5.5 Pro, when in reality it's 5.6 that will have been quietly bumped up into that bracket.
u/Alternative_Jump_195, r/codex
And token price is never the whole bill. For a customer-support deployment, integration and oversight dwarf the model rate, which is the point of this agent vs human cost breakdown.
GPT-5.6 vs Claude and Gemini
On OpenAI's chart, Sol Ultra clears Claude Opus, Claude Mythos 5, and Gemini 3.1 Pro. But the practitioners I trust are split, with a recurring view that Claude is the stronger base model even where GPT scores higher:
5.5 is and has always been a beast when you actively drive it. Fable is the better base by a large margin, but GPT is the stronger exponent.
r/OpenAI, "GPT 5.6 preview"
My take: the gap between frontier models is now small enough that "which one is best this week" is the wrong question for most buyers. What matters is whether your stack lets you switch when the lead changes, which it will.
The verdict
GPT-5.6 is a strong model with a frustrating asterisk. Capability is up, the Luna price is great, and ultra mode is a smart addition, but it's locked behind a preview most teams can't access and carries a documented tendency to overstep.
Who should care now: developers with API or Codex access doing agentic coding or security research, where the gains are real and the overeagerness is manageable in a sandbox. Who should wait: everyone relying on ChatGPT, and anyone wanting to point it at customers. For that second group, the model isn't the bottleneck, the control layer is.
Try eesel
If your interest in GPT-5.6 is really about better customer support, eesel is the piece that turns a clever model into something safe to deploy. It plugs into your existing helpdesk and knowledge in minutes, runs on frontier models without locking you to one of them, and lets you simulate on past tickets before the AI ever answers a real customer, so the overeagerness OpenAI flagged gets caught in a dry run, not in front of a buyer.

That control is what separates a benchmark winner from a support agent you'd trust. You can try eesel for free.
Frequently asked questions
Is GPT-5.6 worth it?
How good is GPT-5.6 at coding?
How much does GPT-5.6 cost?
Is GPT-5.6 safe for customer support?
GPT-5.6 vs Claude: which is better?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.








