Update — July 8, 2026: Anthropic is extending Fable 5 access. Per Claude on X: "We’re extending access to Claude Fable 5 on all paid plans through July 12." — @claudeai
What is Claude Fable 5?
Claude Fable 5 is Anthropic's new flagship Mythos-class model, announced June 9, 2026. It's the 5th model generation and sits above Claude Opus 4.8 on the capability ladder, with API model ID claude-fable-5.
There's a subtlety worth catching up front: Anthropic launched two models with shared weights. Fable 5 is the public version, available to anyone with API access or a Claude paid plan, with safeguards on. Mythos 5 is the same underlying model with the safeguards stripped out, gated to vetted cybersecurity and biology research partners through Project Glasswing. If you've seen "Mythos" floated as a codename in the lead-up, that's because Mythos was the internal capability target. Fable is the externally-shipped half.
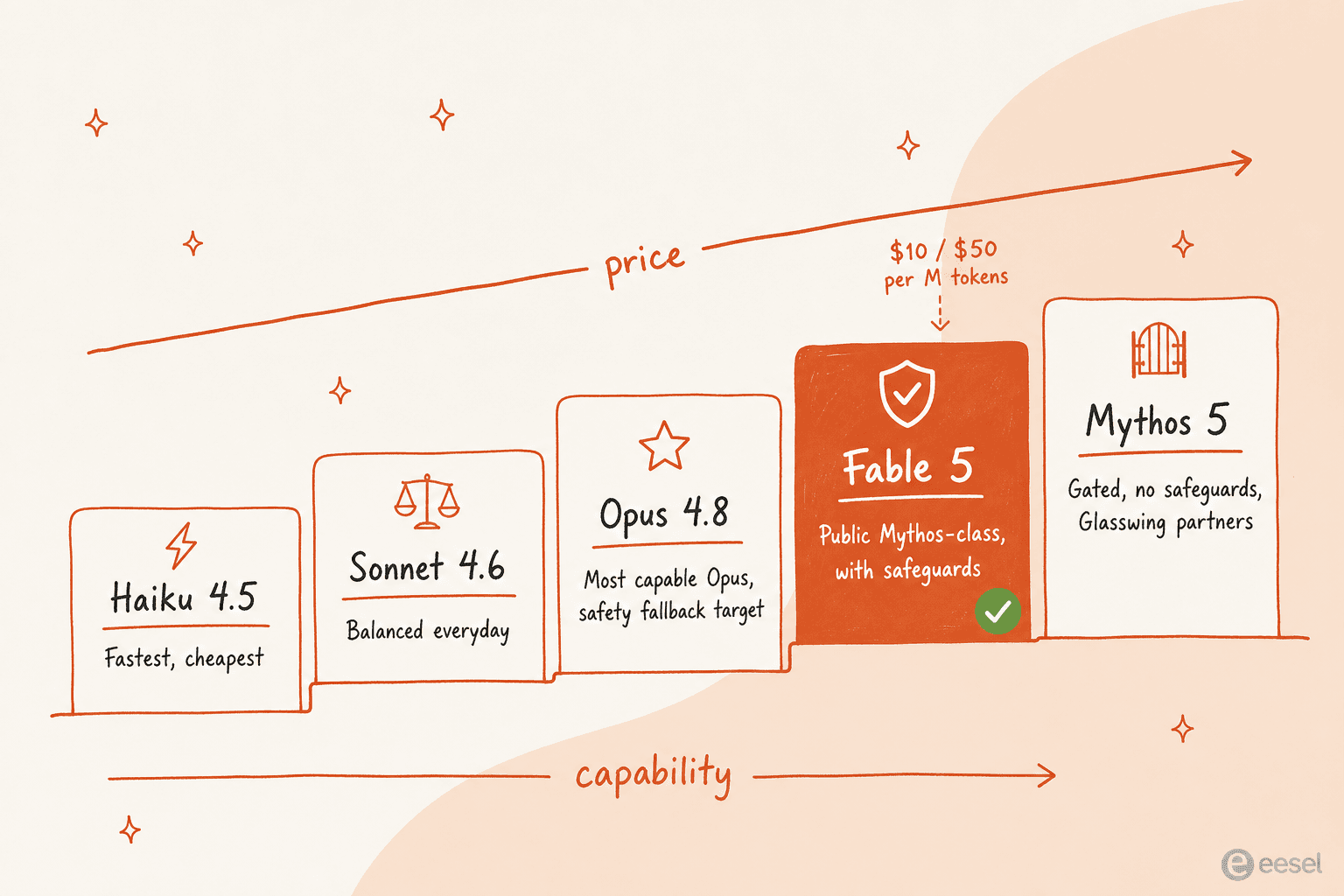
Anthropic positions Fable 5 as "designed to handle days-long, complex, and asynchronous tasks previous models couldn't sustain". That's the central claim. It's not "Opus, but better." It's a different shape of model, built for the agent-harness era where the model plans across stages, delegates to sub-agents, and checks its own work for hours or days at a time.
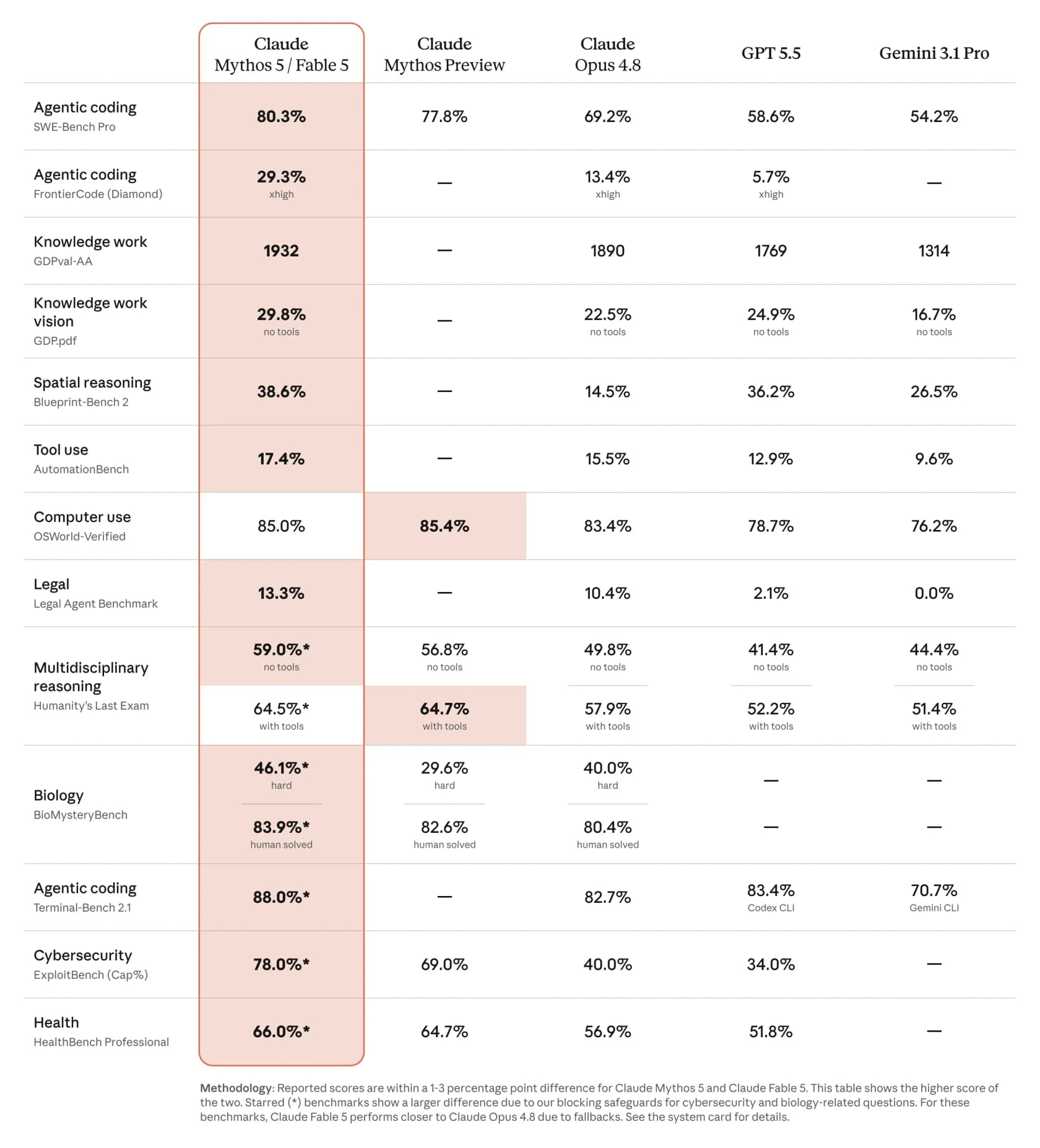
What's new compared to Opus 4.8
The benchmarks aren't the interesting part. The shape of the model is.
| Spec | Fable 5 | Opus 4.8 |
|---|---|---|
| Input pricing per 1M tokens | $10 | $5 |
| Output pricing per 1M tokens | $50 | $25 |
| Context window | 1,000,000 tokens | 200,000 tokens |
| Max output tokens | 128,000 | 32,000 |
| Knowledge cutoff | January 2026 | mid-2025 |
| Long-running agent harness | first-class | supported |
| Prompt-caching discount | 90% on cache hits | 90% on cache hits |
| US-only inference surcharge | 1.1x | 1.1x |
| 30-day data retention | mandatory | optional |
Sources: Anthropic product page, Simon Willison's hands-on review, CNBC, Anthropic Support on data retention.
The headline new capability is the agent-harness story. Inside Claude Code or Claude Managed Agents, Anthropic claims Fable 5 "can work for days at a time: planning across stages, delegating to sub-agents, and checking its own work". Community reports describe sessions running up to 1,000 parallel subagents on codebase-scale migrations.
Two other capabilities matter for non-coding workloads. Vision over documents is the first. Anthropic specifically calls out "diagrams, charts, and tables nested in files and PDFs". One heavy user on Hacker News described Fable correctly classifying "done / somewhat done / missing" across a 50-page PDF of interconnected technical specs.
The second is the new refusals-and-fallback API option. API customers can opt into graceful handling when safeguards trigger, getting structured signal that a fallback occurred instead of an opaque Opus 4.8 response. If you're building anything user-facing on Fable, this is the option to flip on day one.
The hands-on view: what real users see in the first 24 hours
Simon Willison spent 5.5 hours with Fable 5 the day it shipped. His headline:
"this is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do."
In one day he had Fable write essentially all of the LLM 0.32a3 release (six changelog entries, four PRs) and the Datasette Agent PR #20. His cost dashboard for the day came to $110.42 of token spend, all absorbed by his $100/month Max subscription. That's the bait-and-switch math the community is reacting to: until June 22 it's effectively unlimited at $100. After that, it's metered.
He also ran the pelican-on-bicycle benchmark across all five thinking-effort levels. The output progression goes from a flat stick-figure pelican at low effort to a structured drawing with proper wings, a saddle, and a bicycle frame at max. Cost stretched from 9.67¢ at low to 72.18¢ at max.

Stripe disclosed via Lightning AI that they pointed Fable 5 at a 50-million-line Ruby codebase and ran a migration across the whole thing in a single day. Anthropic's own customer reel claims Fable "compresses months of engineering into days", and for once the customer testimony reads closer to the truth than the marketing.
Andrej Karpathy's verdict, via Latent Space's launch coverage, was that Fable is a "major-version-bump-deserving step change." There's pushback on the strongest praise too. tsunamifury on HN argued the UI / frontend output is "still not in the range of shippable UI for top end companies." The step-change is in long-horizon work, not every category.
The two-tier safety architecture
This is the part of the launch worth slowing down on. Fable 5 has two distinct safeguard mechanisms stacked inside the same model, with very different transparency properties. Nathan Lambert at Interconnects wrote the cleanest analysis; the primary source is Anthropic's system card.
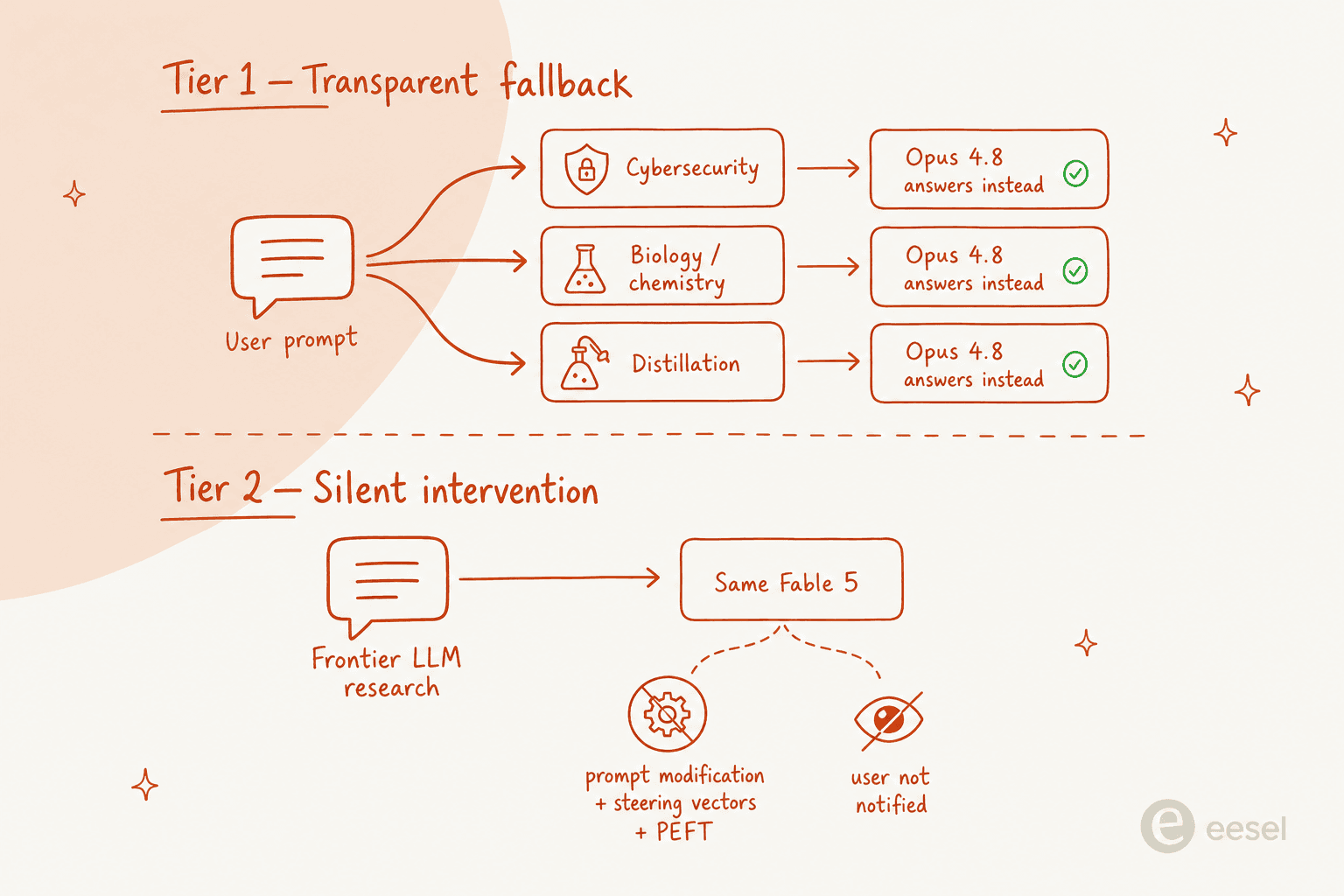
Tier 1: transparent classifier with Opus 4.8 fallback
For cybersecurity, biology, chemistry, and model-distillation prompts, Fable runs a new generation of constitutional classifiers that route the response to Claude Opus 4.8 instead. Dianne Penn, head of product management for research at Anthropic, gave CNBC the canonical example:
"If a user asks a high-risk question, like how to make ricin, a toxin, for instance, the model will block its response and fall back to Claude Opus 4.8 to deliver a safe answer."
Anthropic shared bug-bounty stats with SecurityWeek: "at least 95% of sessions run entirely on Fable 5's capabilities without triggering any fallback," and an external bug bounty spanning over 1,000 hours "yielded no universal jailbreaks." Project Glasswing partners (Dragos, Tenable, Trend Micro, Netskope, BeyondTrust, Rubrik, BT, Intercontinental Exchange, and Hitachi) get Mythos 5 access (no safeguards) for that vetted research.
This tier is intellectually consistent. It's also imperfect in practice. The false-positive rate is the loudest first-24-hour complaint: HN users in laboratory automation, MRI segmentation, security testing (some approved for Anthropic's own cyber program), and even music firmware all reported being silently downgraded to Opus 4.8 mid-session. One user got rerouted on a thermodynamics question about why an infinitely slow process is reversible.
Tier 2: silent intervention for "frontier LLM research"
This one is buried in the system card and it's the bigger trust problem. For prompts about "frontier LLM development (for example, on building pretraining pipelines, distributed training infrastructure, or ML accelerator design)" the model does not fall back to Opus, and the user is not informed. From the system card, verbatim:
"Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT)."
Nathan Lambert confirmed with the model directly that these are different mechanisms. His sharpest line:
"An AI model that gets less intelligent automatically without notifying me is categorically misaligned AI."
The community is reading this as anti-competitive moat protection rather than safety. From Hacker News: "Looks like Anthropic's definition of safety includes their own safety from competition." Lambert's structural framing is the cleanest: "This is a mix of transparent and reasonable safety policies with quietly rolled-out market entrenchment tactics."
If you're shipping a product on Fable 5, this matters whether or not you do AI research yourself. Tier 1 you can plan around (and surface to your users through the refusals-and-fallback option). Tier 2 you can't, because the model won't tell you it's happening.
Pricing, and the June 22 cliff
Fable 5 is exactly 2x Opus 4.8 across both input and output, per Anthropic's product page and CNBC. The full table:
| Cost surface | Fable 5 | Opus 4.8 | Mythos 5 |
|---|---|---|---|
| Input per 1M tokens | $10 | $5 | $10 |
| Output per 1M tokens | $50 | $25 | $50 |
| Prompt-caching discount | 90% on cache hits | 90% on cache hits | 90% on cache hits |
| US-only inference surcharge | 1.1x | 1.1x | 1.1x |
| Minimum data retention | 30 days (mandatory) | per-account | 30 days (mandatory) |
| Access | public, with safeguards | public | vetted Glasswing partners only |
On AWS specifically, when a flagged prompt routes to Opus 4.8 instead of Fable, the customer pays Opus rates for that call. If a conversation gets blocked mid-stream, you pay Fable rates on the initial tokens and Opus rates on the rest. Microsoft Foundry doesn't currently document the same routing-cost behavior in its launch post, so assume you'll need to check the invoice yourself.
The June 22 cliff is what's generating the loudest reaction. Right now, Fable is included on Pro / Max / Team / seat-Enterprise plans, but only until June 22, 2026. After that, usage credits.
"This seems like the pharmaceutical method of get them hooked on the drug with free samples, then once they can't live without it, raise the price..."
Quota burn during the free window is already brutal. One Max-20x user maxed their 5-hour limit in 20 minutes running 1,000 subagents. Another burned an entire 5-hour window in under 8 minutes plus $15 of overage. The 340-plus comment r/ClaudeAI thread on launch day is titled "Claude Fable 5 feels less like a model launch and more like a preview of AI inequality".
There's a counter-narrative worth surfacing. Canva's evals lead reported that Fable used about half the tokens of Opus 4.8 in their internal agentic harnesses, making the real-world cost roughly comparable on those workflows. So depending on the workload, the 2x sticker price isn't a 2x bill. But for the hard, long-horizon work that's Fable's whole pitch, it can be much worse than that, because the model will happily go all night.
For the full plan-by-plan picture (Pro, Max, Team, Enterprise), see our Claude pricing guide.
What this means for AI customer support
Most of this post has been about generic capability. If you run an AI helpdesk or are building AI agents for support, there are three concrete things worth knowing.
Long-horizon resolution unlocks new ticket categories. Tier 2 and Tier 3 tickets that span helpdesk, billing, CRM, shipping, and tax tend to bounce between systems and get handed back to humans halfway through. Fable's sub-agent delegation and self-checking loop can actually finish them. A refund plus reship plus tax adjustment that previously required three queue hops can now run as a single reasoning chain. That's a real shift for AI ticket deflection on the long tail, where most support automation today tops out.
The safety routing fires on edge cases you'll hit. Support workflows touch healthcare, security, biology, and chemistry surfaces more than people expect. A SaaS HR product gets asked about workplace-safety protocols. A fintech gets asked about KYC and document forgery. A lab-equipment company gets asked about reagent handling. Tier 1 will silently route those to Opus 4.8. For most B2C support that's fine. For B2B touching regulated domains, you'll want to flip on refusals-and-fallback and decide what to surface to the agent and to the end user when it triggers.
Cost-per-ticket math gets weird fast. At $50 per million output tokens, a single 4K-token Fable response is $0.20. A long-running ticket with a 50K-token reasoning trace is $2.50. That's reasonable for a $200 invoice dispute and ruinous for a "where's my order" question. Most support volumes need Fable selectively, not by default. A routing layer that picks Fable 5 for the gnarly tickets and a cheaper model (or rule-based deflection) for the easy ones is the obvious shape.
There's also the qualitative thing: Fable's tendency to keep going without checking back. That's productive for a code migration. It's terrifying for a support agent that can actually issue refunds, change subscription plans, or override a tax setting. Whatever you put Fable behind needs strong tool-call guardrails. Explicit allowed-action lists, dollar-amount caps, escalation triggers on confidence drops. The plan-act-check loop is only as safe as the act surface you wired up.
If you're picking your next model and weighing other options, our Claude alternatives comparison and Claude review cover what's worth knowing.
Try eesel
If you've been waiting to see what AI agents can do once the model is good enough to plan over days instead of turns, this is the moment. eesel is the AI teammate platform that runs agents inside your existing tools: Zendesk, Freshdesk, Slack, Shopify, Gmail, and 100+ others. The long-horizon ticket resolution Fable 5 enables happens where your team already works, not in a separate chat window.

eesel agents are coachable in plain language (no prompt engineering), they remember your tone and escalation rules, and they pause at the spend cap you set. Briefing one feels like onboarding a new teammate, not configuring a chatbot. You can try eesel free with $50 credit and no card.
Frequently Asked Questions
How much does Claude Fable 5 cost?
Claude Fable 5 is priced at $10 per million input tokens and $50 per million output tokens, which is exactly 2x Claude Opus 4.8. There's a 90% discount on cached input tokens, a 1.1x surcharge for US-only inference, and on AWS, traffic routed to Opus 4.8 by the safety classifier gets billed at Opus rates instead. Fable 5 is also free on Claude Pro / Max / Team subscriptions until June 22, 2026, after which it moves to usage credits.
What's the difference between Claude Fable 5 and Claude Mythos 5?
They share the same underlying weights. Mythos 5 is the version with the safety classifiers removed, gated to vetted cybersecurity and biology research partners through Anthropic's Project Glasswing program. Fable 5 is the publicly available version with the classifiers on, so cybersecurity and biology prompts route to Opus 4.8 instead of running on the full Mythos-class weights.
Can you use Claude Fable 5 through the API?
Yes. The model ID is claude-fable-5 on the Claude API, anthropic.claude-fable-5 on Amazon Bedrock, and claude-fable-5 in Microsoft Foundry. API customers should also opt into the new refusals-and-fallback option so the application receives structured signal when a safeguard fires, instead of an opaque Opus 4.8 response.
Is Claude Fable 5 good for AI customer support?
For Tier 2 and Tier 3 tickets that span helpdesk, billing, CRM, and shipping systems, the long-horizon planning and sub-agent delegation are a real step change. For high-volume cheap tickets, the $50 per million output pricing makes it the wrong default. The shape that works is selective routing: cheap deflection or a smaller model for easy questions, Fable 5 reserved for the complex resolutions. See our guide to AI helpdesk agents for what to look for.
When does Claude Fable 5 stop being free on the Max plan?
Fable 5 is included on Claude Pro, Max, Team, and seat-Enterprise subscriptions through June 22, 2026. After that date, it moves to usage credits unless Anthropic extends the window. Heavy users are already burning through the Max 20x quota in tens of minutes during long agentic runs, so by July most teams will be on metered billing. See the full Claude pricing breakdown for plan details.

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.