
What Claude Sonnet 5 actually is
I build integrations and APIs for a living, so when a new model drops I read the docs before the launch thread. Here is what Anthropic's own docs say Claude Sonnet 5 is, minus the marketing gloss.

Anthropic announced Sonnet 5 at the end of June 2026 as "our most agentic Sonnet yet," and made it the day-one default for free and Pro Claude users. It is the balanced tier of the Claude 5 family. It runs a 1M-token context window and up to 128K tokens of output, the same ceiling as the Opus tier. The pitch is that it reaches near-Opus quality specifically on coding and agentic tasks, the kind of multi-step, tool-using work a support agent does, while costing far less to run. Anthropic's rough framing is that Sonnet 5 at medium effort is comparable to the previous Sonnet 4.6 at high, and Sonnet 5 at high is comparable to 4.6 at max. In other words, you get more for the same setting.
Where it sits in the family is the real story. Anthropic now ships four public tiers, and Sonnet 5 is the one most teams will actually put into production.
A few things are new under the hood, and they matter more than the version number suggests:
- Adaptive thinking is on by default. You no longer set a fixed "thinking budget" in tokens. The model decides how much to reason per request, and you nudge it with an
effortdial instead. xhigheffort arrives at the Sonnet tier. Sonnet 5 is the first balanced-tier Claude model with thexhighsetting, which Anthropic recommends for the hardest coding and agentic runs. It is the same dial Claude Code leans on.- High-resolution vision. Sonnet 5 reads images up to 2576px on the long edge, useful if your support flows involve screenshots or receipts.
- A new tokenizer. More on this below, because it quietly changes your bill.
Claude Sonnet 5 pricing
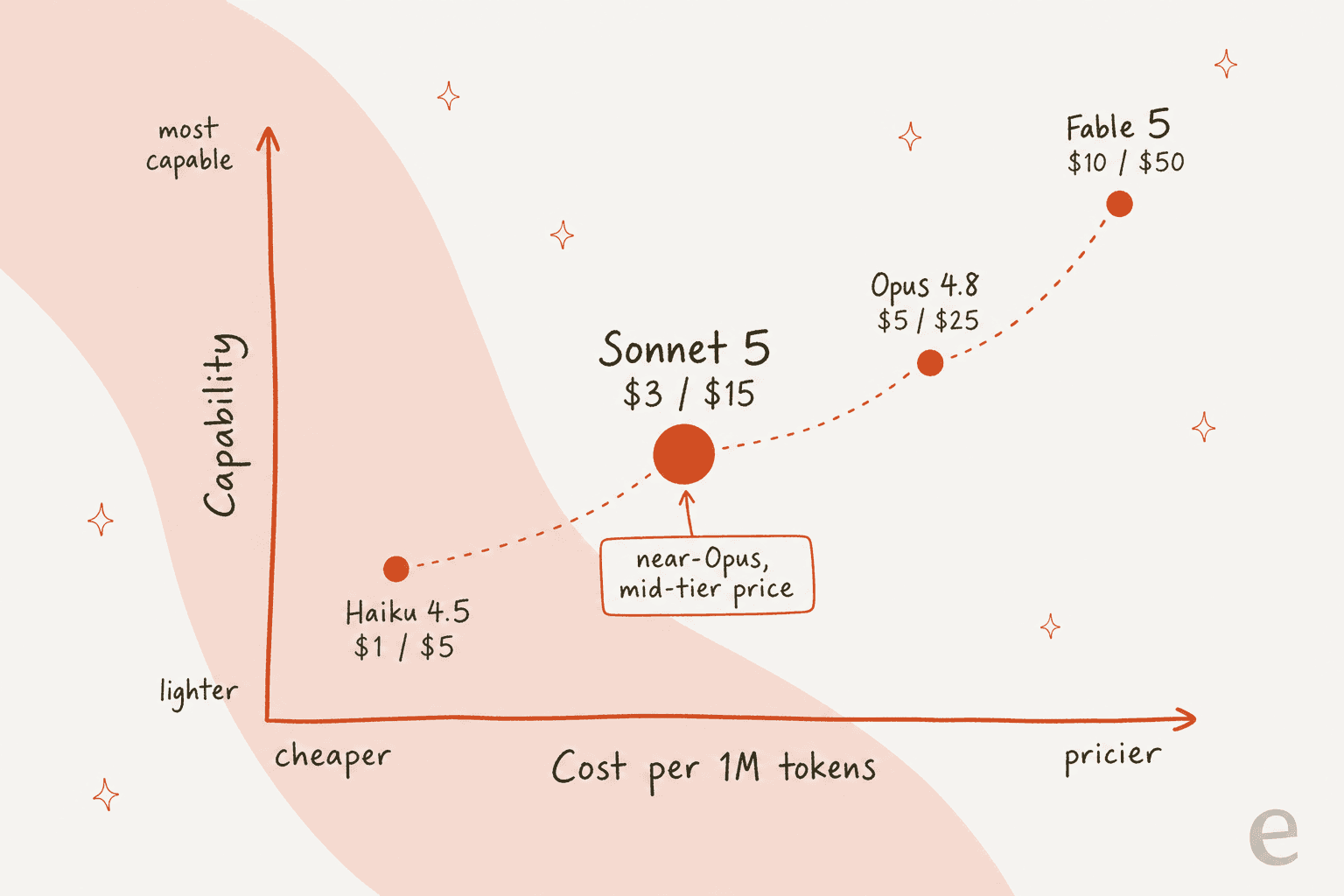
Here is the part everyone actually came for. Sonnet 5 API pricing is $3 per million input tokens and $15 per million output, with introductory rates of $2/$10 running through 31 August 2026. On the consumer side, Sonnet is the "balanced" tier inside a Claude subscription.
Set against its siblings, the value case is clear:
| Model | Input ($/1M) | Output ($/1M) | Context | Best for |
|---|---|---|---|---|
| Haiku 4.5 | $1 | $5 | 200K | Fast, cheap, simple tasks |
| Claude Sonnet 5 | $3 (intro $2) | $15 (intro $10) | 1M | Coding and agentic work at scale |
| Opus 4.8 | $5 | $25 | 1M | Hardest long-horizon autonomous work |
| Fable 5 | $10 | $50 | 1M | The most demanding reasoning |
So Sonnet 5 is roughly 40% cheaper than Opus 4.8 on both input and output, while claiming most of its capability on the tasks a support agent runs. For a queue doing millions of tokens a month, that gap compounds fast.
But there is a catch that does not show up on the price sheet. Sonnet 5 uses a new tokenizer that counts roughly 30% more tokens for the same text than Sonnet 4.6 did. The per-token price is lower, but each conversation now is more tokens, so your real cost per resolved ticket can land somewhere different than a back-of-envelope estimate suggests.
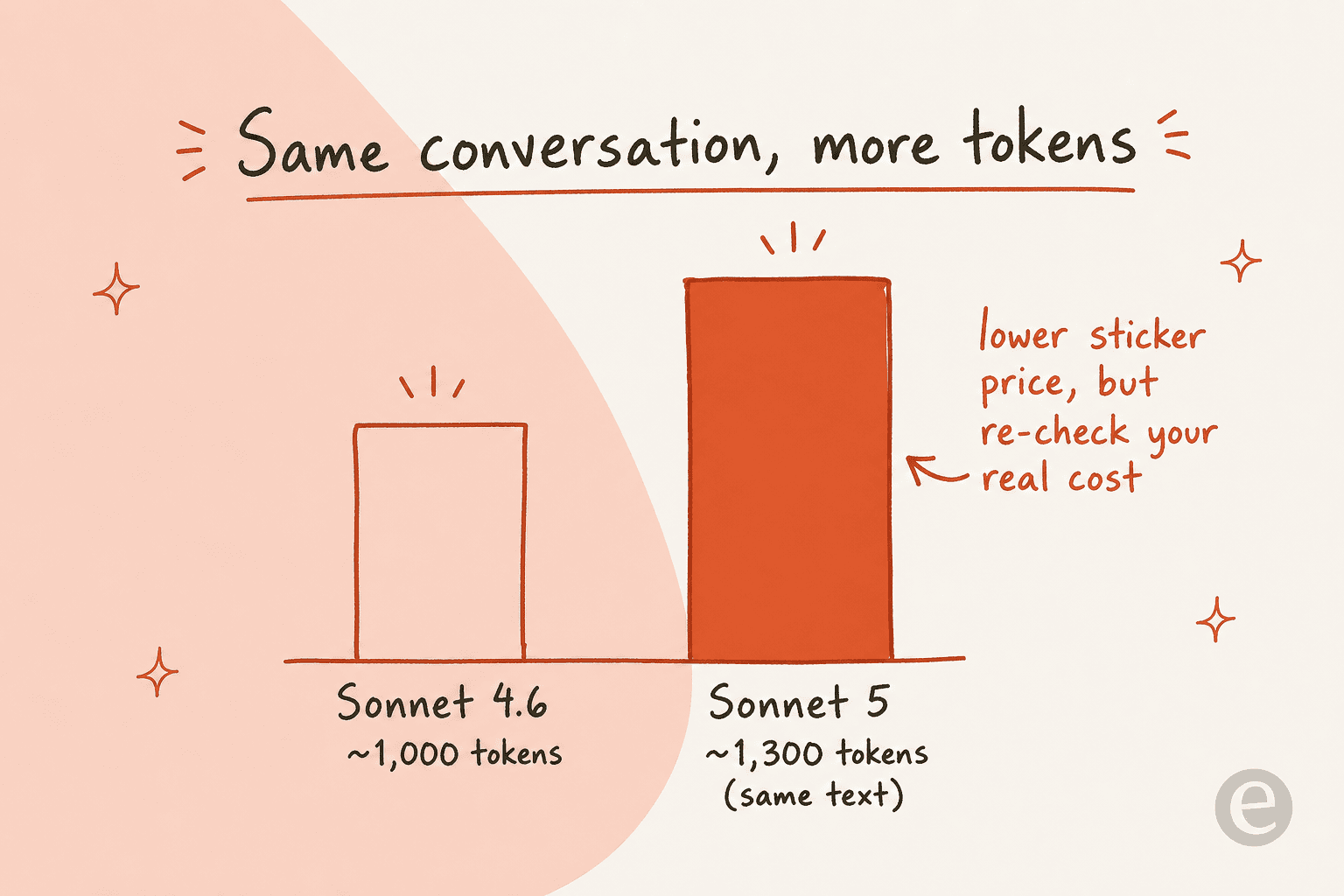
This is already the live debate about Sonnet 5. Boosters call it Opus-level work at Sonnet prices, but sharper takes on X point out that once the intro discount ends and you run at high effort, the per-task cost can actually land above Opus 4.8 on independent indexes. Both can be true: the sticker is lower, the token count is higher, and effort dials the total either way.
The hands-on reactions lean the same way. In an early-impressions thread on r/ClaudeAI (90+ comments within hours of launch), one developer opened with exactly the trade this whole post is about:
"Been using Sonnet 5 on [xhigh] effort about 30 minutes on mainly tasks I would delegate to Opus 4.8..."
early-impressions thread, r/ClaudeAI
That is the signal worth watching: people reaching for Sonnet 5 on work they used to hand to Opus. Whether it holds up on your tickets is a question a benchmark cannot answer, which is the whole point of the next section.
The practical move: measure token usage on your own tickets against claude-sonnet-5 rather than reusing a number you had for an older model. If you are trying to model total cost of ownership for support specifically, the AI support agent cost breakdown is a better starting point than raw per-token math, because most of the cost of a support agent is never the model.
What changed from Sonnet 4.6
If you are upgrading an existing integration rather than starting fresh, four things are worth knowing before you flip the model string:
- Thinking works differently. The old fixed
budget_tokenscontrol is gone on Sonnet 5. Omitting the thinking setting now runs adaptive thinking automatically, where before it ran with thinking off. If you never touched it, your requests will quietly start reasoning more (and using more of your output budget), so givemax_tokensa little headroom. - Effort is your main dial. Keep
highas the default and reach forxhighon the hardest agentic runs. Lower it tomediumorlowfor cheap, latency-sensitive tasks like ticket tagging or intent classification. - The tokenizer shift is real. As above, re-baseline your token counts. This is the single most common way a migration surprises a finance team.
- Vision got sharper. High-resolution image input is automatic. Handy if you triage tickets that arrive as screenshots.
None of this is dramatic if you already run on the Claude API. It is a model-string swap plus a re-tune, not a rewrite. The Claude developer platform keeps the same request shape it had for the Opus 4.x family.
What Sonnet 5 means if you run a support team
Here is where a cheaper, smarter model gets genuinely interesting, and genuinely misleading.
Every time a strong model launches, a wave of teams thinks the same thought: the model is this good and this cheap now, we should just build our own support bot on the API and skip the vendor. I get it. As someone who ships this kind of code, wiring up a Sonnet 5 call that answers a support question is a satisfying afternoon.
The trap is that the model call is the easy 20%. Everything that makes an AI safe to point at real customers sits below the waterline, and none of it comes in the API response.

I am not guessing at this. I have watched customers leave to build in-house on the Claude API directly, and the pattern is consistent: the demo works in a week, and then the long tail of retrieval, hallucination control, routing, and escalation eats the next six months. One engineering lead who chose to buy instead of build put it plainly:
"We could try to write our own LLM application but we didn't want to invest our time into that. We wanted something that we would not have to maintain."
Karel, engineering lead at GENERAL BYTES
The scariest failure mode is not that a raw model gives a wrong answer. It is that it gives a confident wrong answer. In three-plus years of putting AI on live support queues, the worst pattern I have seen is a bot that sounds sure of itself and quietly tells a customer something false, or narrates work it never actually did. That is exactly why any serious rollout should be simulated against your historical tickets first, so you see the accuracy and coverage numbers before a real customer does, not after. A model benchmark tells you the engine is fast; it tells you nothing about how your specific bot behaves on your specific tickets.
So the honest read on Sonnet 5 for support: it makes the engine cheaper and better, which is great, and it changes almost nothing about the hard 80%. Whether you build or buy, budget your time for the parts the API does not ship, routing, guardrails, escalation to humans, and testing, because that is where customer trust is actually won or lost.
Try eesel
If the honest conclusion is "I want Sonnet-5-class quality on my tickets without building the other 80%," that is exactly the gap eesel fills. It works like a new support hire that plugs into Zendesk, Freshdesk, Gorgias, Help Scout, or Intercom in a few minutes and already knows your help center and past tickets.
The part that matters most given everything above: eesel lets you simulate on thousands of your real historical tickets before going live, so you see resolution and coverage numbers up front instead of finding out on a live customer. Confidence-based routing keeps the AI on the tickets it can handle and hands the rest to a human, which is the guardrail that turns a clever model into a trustworthy teammate. That is not a benchmark eesel is chasing; it is why teams like Gridwise resolved 73% of tier-1 requests in their first month.

Pricing is usage-based at about $0.40 per ticket handled, with no per-seat fees and no platform minimum, and you can try eesel free. Whatever model sits underneath, whether it is Sonnet 5 today or its successor next year, the work around it is what actually resolves the ticket.
Frequently Asked Questions
What is Claude Sonnet 5?
How much does Claude Sonnet 5 cost?
Is Claude Sonnet 5 better than Opus 4.8?
Can I build a customer support agent on Claude Sonnet 5?
What is the difference between Claude Sonnet 5 and Sonnet 4.6?
xhigh effort setting, upgrades to high-resolution vision, and uses a new tokenizer that counts roughly 30% more tokens for the same text. That last point matters for budgeting, so re-check your real per-conversation cost rather than reusing old estimates. More on model choice in the best AI chatbot guide.
Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.







