I run AI on real support queues for a living, so here's my honest read
I'll start somewhere most model explainers won't, because it's the bit that actually matters. I've spent years watching frontier models meet real, messy support queues, and the pattern never changes: the model is rarely the hard part.
A couple of numbers from our own deployments to ground that. One customer, Gridwise, saw eesel resolve 73% of their tier-1 requests in the first month, with results landing during a 7-day trial. Another, Smava, runs a fully automated Zendesk agent processing 100,000+ German-language tickets a month. None of that came from picking the cleverest model. It came from training on solved tickets, routing by confidence, and simulating on real history before going live.
So when a new Opus drops, the question I care about isn't "is it smarter on a benchmark." It's "does this change what I'd actually ship to a customer's inbox." Let's look at Opus 4.8 with that lens.
What is Claude Opus 4.8?
Claude Opus 4.8 is the latest model in Anthropic's Opus family, the high-capability tier of Claude. Anthropic released it on 28 May 2026 and frames it as a "more effective collaborator" that "builds on Opus 4.7 with improvements across benchmarks." In the API, you call it with the model ID claude-opus-4-8.
The headline specs are easy to summarise: a 1M-token context window at standard pricing, up to 128k tokens of output, and adaptive thinking that the model controls itself (there's no separate extended-thinking toggle to manage anymore). It reads text and images, handles 80-plus languages, and its training data runs to January 2026 (models overview).
Anthropic's own framing of the jump is refreshingly un-hyped. The announcement calls it a "modest but tangible improvement on its predecessor," which is also how the Hacker News thread titled it. If you remember the bigger generational jumps, this is not one of those. It's a polish-and-fix release, and that's fine, the fixes are the interesting part.
What's new in Opus 4.8
A few changes are worth knowing, especially if you're choosing a model to build on rather than just chatting with it.
Honesty got a real upgrade. Anthropic calls this "one of the most prominent improvements," and it's the one I'd actually pay for. Opus 4.8 is reported to be around four times less likely than 4.7 to let flaws in its own code pass unremarked, and it's more willing to flag uncertainty instead of confidently inventing an answer. For anyone deploying AI where a wrong answer has a cost, "tells you when it isn't sure" is worth more than another point on a coding benchmark.
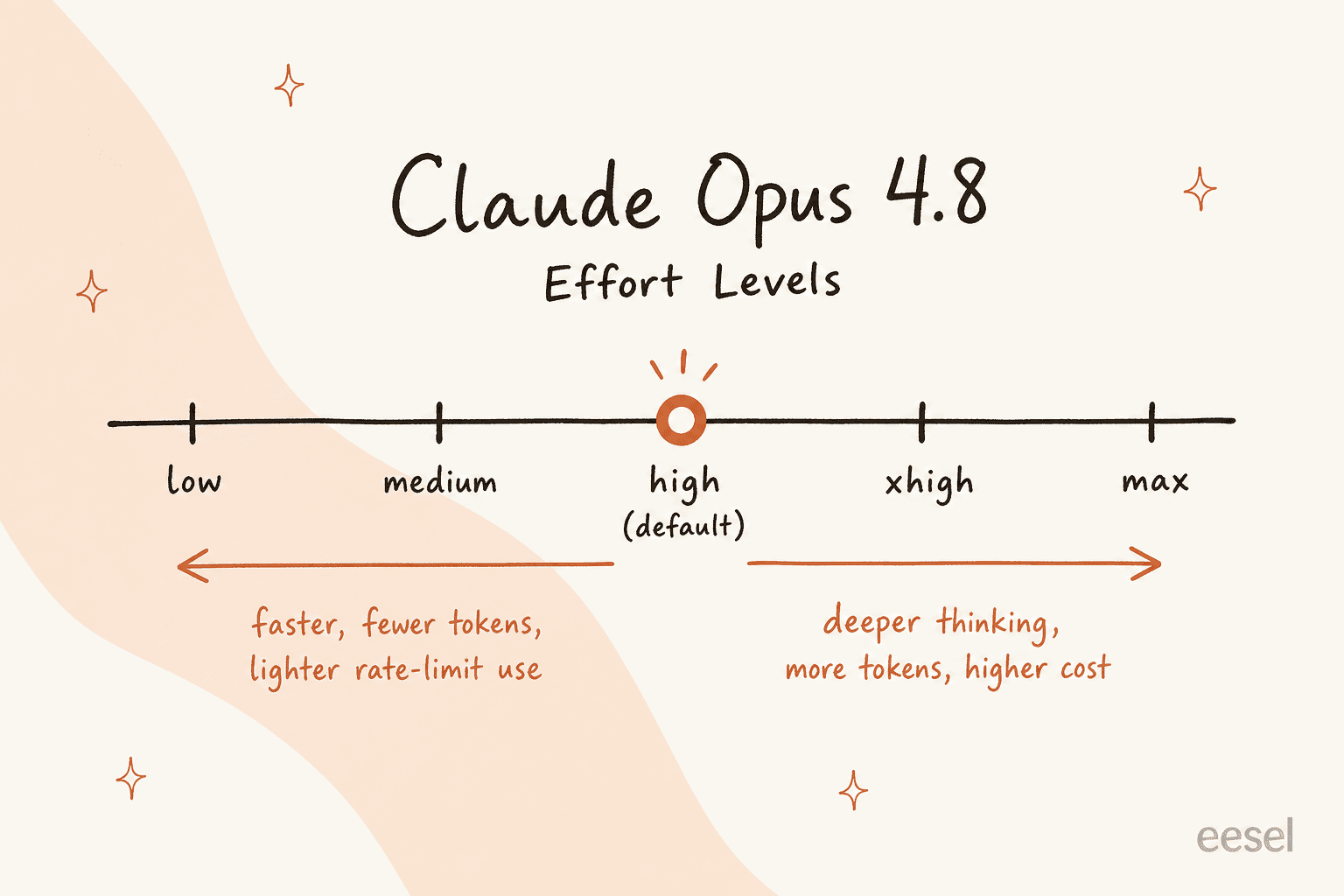
An effort control. There's now a dial that sets how hard the model works on a response, from low up to max (with xhigh slotted between high and max). It defaults to high. Crank it up for deeper reasoning, dial it down for speed and lighter usage. The trade-off is real and worth understanding before you wire it into anything.
Dynamic workflows in Claude Code. In Claude Code, Opus 4.8 can plan a job, fan out hundreds of parallel subagents in one session, then verify their output before reporting back, which is aimed at codebase-scale work like migrations across hundreds of thousands of lines. If you live in Claude Code subagents, this is the feature to try.
Mid-task system instructions. For developers, the Messages API now accepts system entries inside the messages array, so you can update instructions, permissions, or token budgets mid-run without breaking your prompt cache. Small change, genuinely handy if you're building agents.
A warmer voice. Early testers describe it as easier to collaborate with and better at holding context and style across a long session. The flip side shows up in the community reaction below.
Claude Opus 4.8 pricing and where it sits
Pricing is the easy part, because it didn't move. Opus 4.8 is $5 per million input tokens and $25 per million output tokens, exactly the same as Opus 4.7 (pricing page). There's also a fast mode that runs at 2.5x the speed and, per Anthropic, costs noticeably less than fast mode did on previous models.
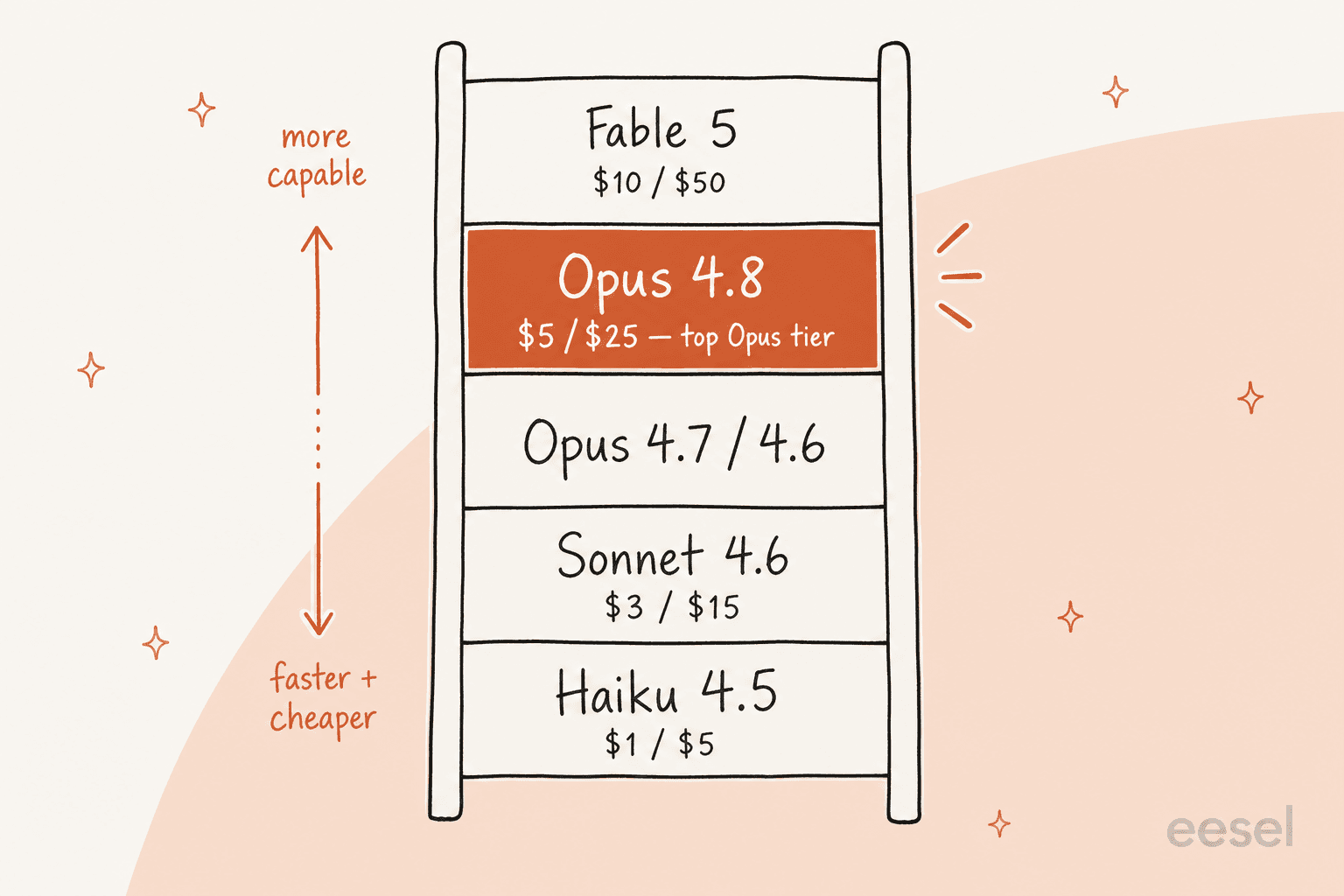
Here's the wider Claude lineup as it stands in mid-2026, which is the context you need to actually pick a model:
| Model | Input / output (per 1M tokens) | Context | Best for |
|---|---|---|---|
| Claude Fable 5 | $10 / $50 | 1M | Anthropic's most capable widely released model |
| Claude Opus 4.8 | $5 / $25 | 1M | Top Opus-tier; complex reasoning, long-horizon agents |
| Claude Opus 4.7 / 4.6 | $5 / $25 | 1M | The prior Opus generations |
| Claude Sonnet 4.6 | $3 / $15 | 1M | Best balance of speed and intelligence |
| Claude Haiku 4.5 | $1 / $5 | 200k | Fastest and cheapest, for high-volume simple tasks |
The thing to notice: Opus 4.8 is the strongest Opus-tier model, but it's no longer the top of the whole stack. About two weeks after it launched, Anthropic released Claude Fable 5 as its most capable widely available model, at double the price. So Opus 4.8 is the sensible high-capability default; Fable 5 is the "money is no object, give me the absolute best" option. We put the prior generation head to head with rivals in Gemini 3 Pro vs Claude Opus 4.6 if you want a sense of how Anthropic's models stack up.
One cost gotcha worth flagging, because it surprises people: Opus 4.7 and later use a new tokenizer that "may use up to 35% more tokens for the same fixed text." So even at an unchanged sticker price, your real cost-per-task can creep up versus an older model. That detail explains a lot of the community grumbling, which brings me to the next bit. (If pricing is your whole reason for reading, our Claude pricing guide goes tier by tier.)
What people are actually saying
The cleanest read of the community reaction is that Opus 4.8 is the fix for a 4.7 that people openly disliked. The "return to form" takes are everywhere, and they line up with our longer-running Claude review. One developer, a couple of hours into testing on r/ClaudeAI, put it well:
"4.8 is precise, thinks fast, and hasn't hallucinated anything. When it doesn't know something, it asks me directly instead of making something up. It feels like what 4.6 should have evolved into."
That matches Anthropic's honesty claims, and it's the single most repeated positive. But two honest tensions are worth airing, because they're the kind of thing a marketing page won't tell you.
First, it's hungry. The most common complaint is that Opus 4.8 chews through usage limits fast, partly thanks to that new tokenizer. As one user noted in a thread comparing it to GPT-5.5:
"Opus 4.8 is a beast, way better than 4.7 in execution but also in design I find, the real issue is tokens, it consume way more tokens and for the first time I reached a limit within my max subscription."
Second, the autonomy isn't magic. Power users running long, hard tasks report that Opus 4.8 still needs tight scoping, with one quant-systems architect noting that "to use Opus 4.8 effectively, the human still needs to think a lot. You need to define more, guide more, and maintain more of the context yourself." And the flip side of the celebrated honesty gains is that a vocal minority find it too cautious or apologetic for open-ended creative work. None of this is damning. It's just the calibrated picture: a strong, honest, token-hungry model that rewards clear instructions.
What a smarter model actually means for customer support
Here's where I get to the thing I actually know about. If you run a support team, the temptation when a model like Opus 4.8 lands is to think "great, AI support just got better." Sometimes. But the model is the engine, not the car, and it's worth being precise about what AI customer service software is really made of.
I've watched plenty of technically capable teams reach the same conclusion the hard way. We've seen customers leave to wire up the Claude API themselves, reasoning that if Opus is this good, they can just call it directly. A few months later, the maintenance reality sets in. One engineering lead who chose to buy instead summed up the calculation neatly: they could write their own LLM application, but they "didn't want to invest time into that," and wanted "something that we would not have to maintain."
That's because a production support agent is the model plus a lot of unglamorous scaffolding:
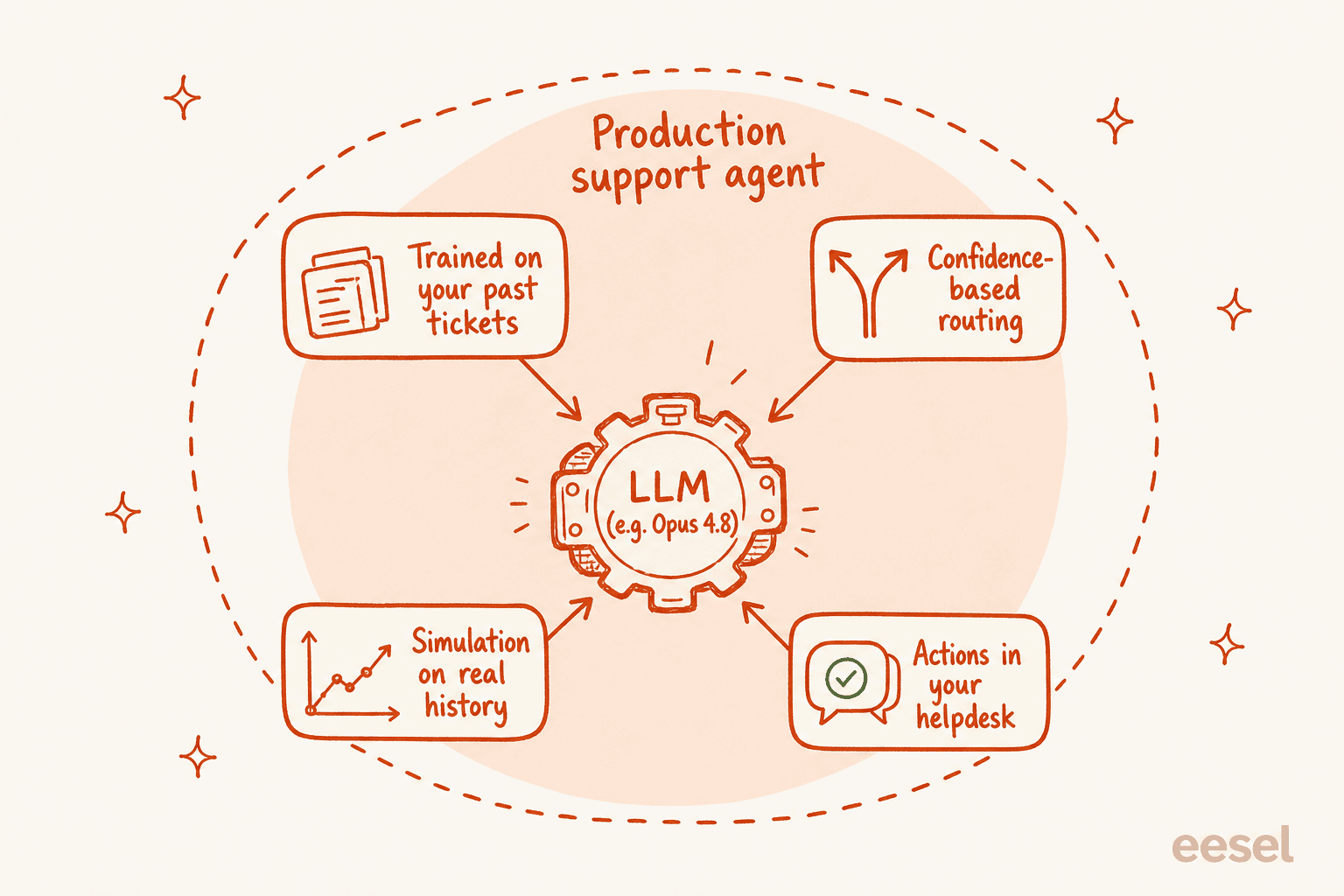
- Your knowledge, not the model's. Opus 4.8's January 2026 training cutoff knows nothing about your refund policy or last week's outage. A useful agent learns from your past tickets, help docs, and macros, not from general world knowledge.
- Confidence-based routing. The honesty gains in Opus 4.8 are real, but you still don't want a model deciding on its own when to reply live. You want it to draft when unsure and only auto-send when it's confident, which is a system-level guardrail, not a model setting.
- A way to test before it goes live. Before a single customer sees an AI reply, you want to run the thing against thousands of your real, resolved tickets and see exactly where it would have been right or wrong. Picking a newer model doesn't give you that; the simulation does.
- Actions, not just answers. Tagging, triaging, looking up an order, escalating cleanly to a human. That all lives in your helpdesk integrations, not in the raw model.
This is also why "which model is best" is the wrong question for support. We've found a well-built system on a mid-tier model usually beats a raw frontier model with no scaffolding, which is the whole point of our piece on which LLM is best for support use cases. Opus 4.8 being more honest is good news, it just doesn't change the shape of the work. If you're weighing building your own AI support versus buying a platform, the model is the cheap, easy part. The rest is the job.
Try eesel
If you've read this far, you're probably less interested in benchmark deltas and more interested in whether AI can safely take tickets off your team's plate. That's exactly what eesel AI does: it sits on top of frontier models like Claude (so you get the Opus-class reasoning without owning any of the plumbing), learns from your past tickets and help docs, routes by confidence so it only auto-replies when it's sure, and lets you simulate on your real ticket history before it ever talks to a customer. Pricing is usage-based with no per-seat fees, so a quieter month costs less rather than the same.

You can connect your helpdesk and have a simulation running in minutes. Try eesel and point it at your own tickets to see what it would actually resolve.
Frequently Asked Questions
What is Claude Opus 4.8?
How much does Claude Opus 4.8 cost?
What's the difference between Claude Opus 4.8 and Opus 4.7?
Is Claude Opus 4.8 good for customer support?
Should I build my own support AI on the Claude Opus 4.8 API?
Where does Claude Opus 4.8 sit in Anthropic's lineup?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.