Update — July 8, 2026: Anthropic is extending Fable 5 access. Per Claude on X: "We’re extending access to Claude Fable 5 on all paid plans through July 12." — @claudeai
So what can Claude Fable 5 actually do?
Claude Fable 5 is Anthropic's fifth model generation and a new "Mythos-class" tier that sits above Claude Opus 4.8, which in turn sits above Sonnet 4.6. If you've read our Claude overview, this is the new ceiling. It launched on 9 June 2026 and runs on claude.ai, the Claude API, Claude Code, AWS, and Microsoft Foundry.
But specs and tiers aren't really what people mean when they ask what it can do. They mean: what work can I hand it and trust it to finish? Here's the honest map of its concrete capabilities, then we'll go through each one.
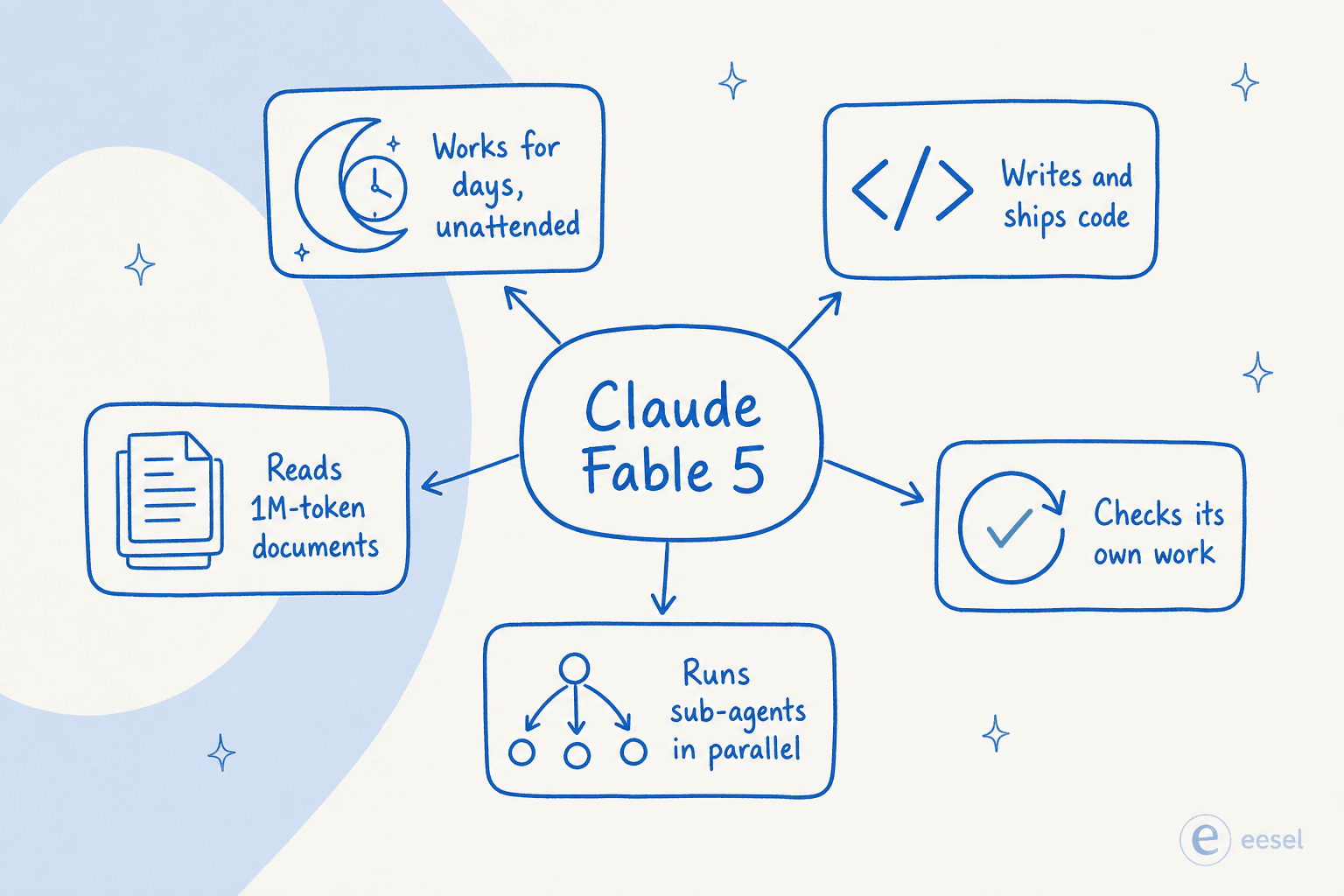
It runs autonomously for days, then checks its own work
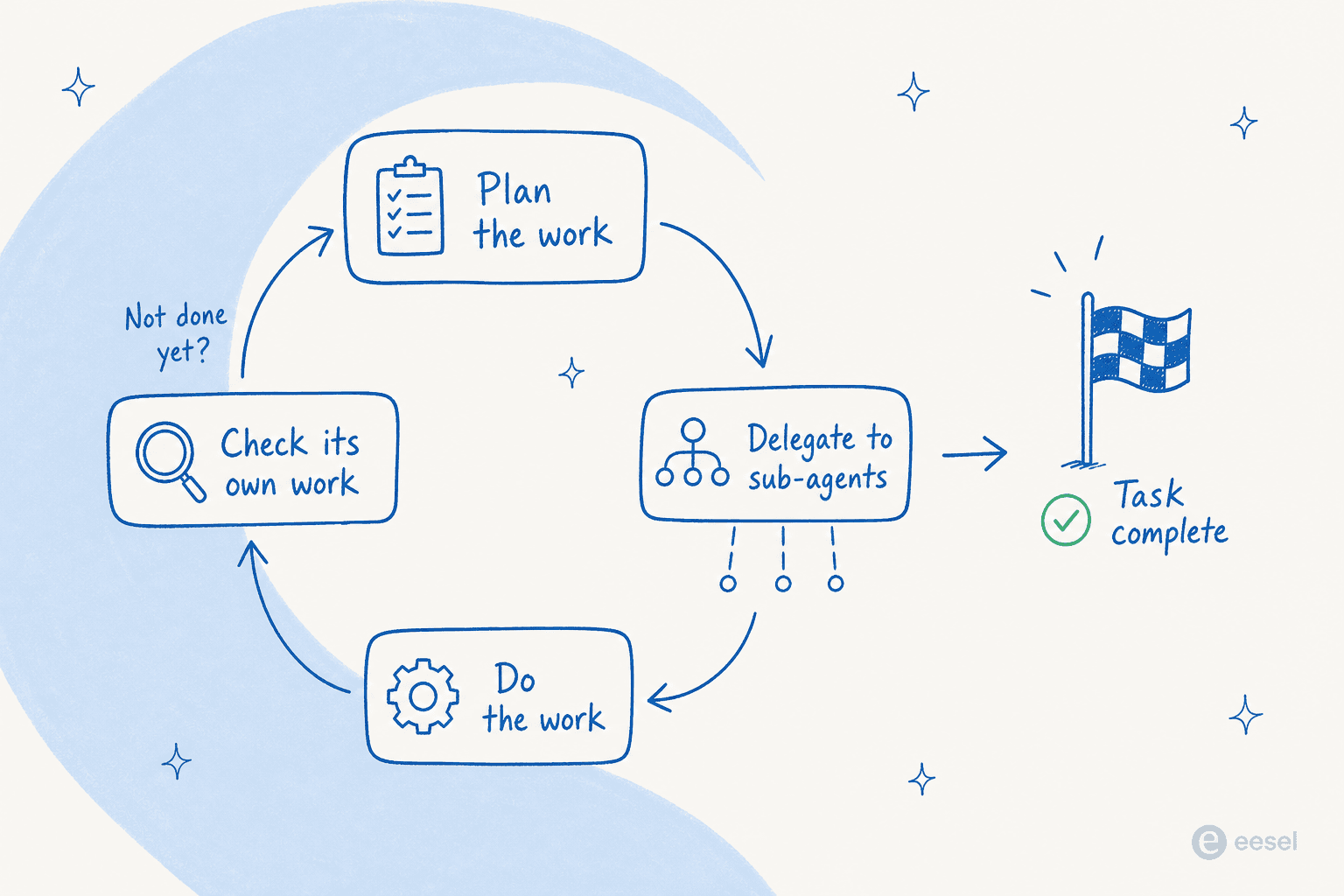
This is the capability Anthropic actually built Fable 5 around, and it's the one that matters most. Run it inside a harness like Claude Code or Claude Managed Agents and, in Anthropic's words, it can "work for days at a time: planning across stages, delegating to sub-agents, and checking its own work."
That loop, plan then delegate then work then check, is the part that's actually new. Earlier models lost the thread on long, multi-stage tasks; this one keeps its footing and, crucially, marks its own homework. Anthropic describes it as "thorough, proactive, and tests its own work," and the cloud providers spell out a plan, check, refine loop baked in. Self-correction is the difference between an agent you babysit and one you can leave running overnight.
The scale this unlocks is real. In early testing, Stripe pointed Fable 5 at a 50-million-line Ruby codebase and ran a migration across the whole thing in a day, and community reports describe sessions spinning up up to 1,000 parallel sub-agents for codebase-scale work. That ability to hold a goal, break it into stages, and grind through them is exactly what separates an AI agent from a rule-based chatbot: one finishes the job, the other waits for the next instruction.
It writes and ships production-grade code
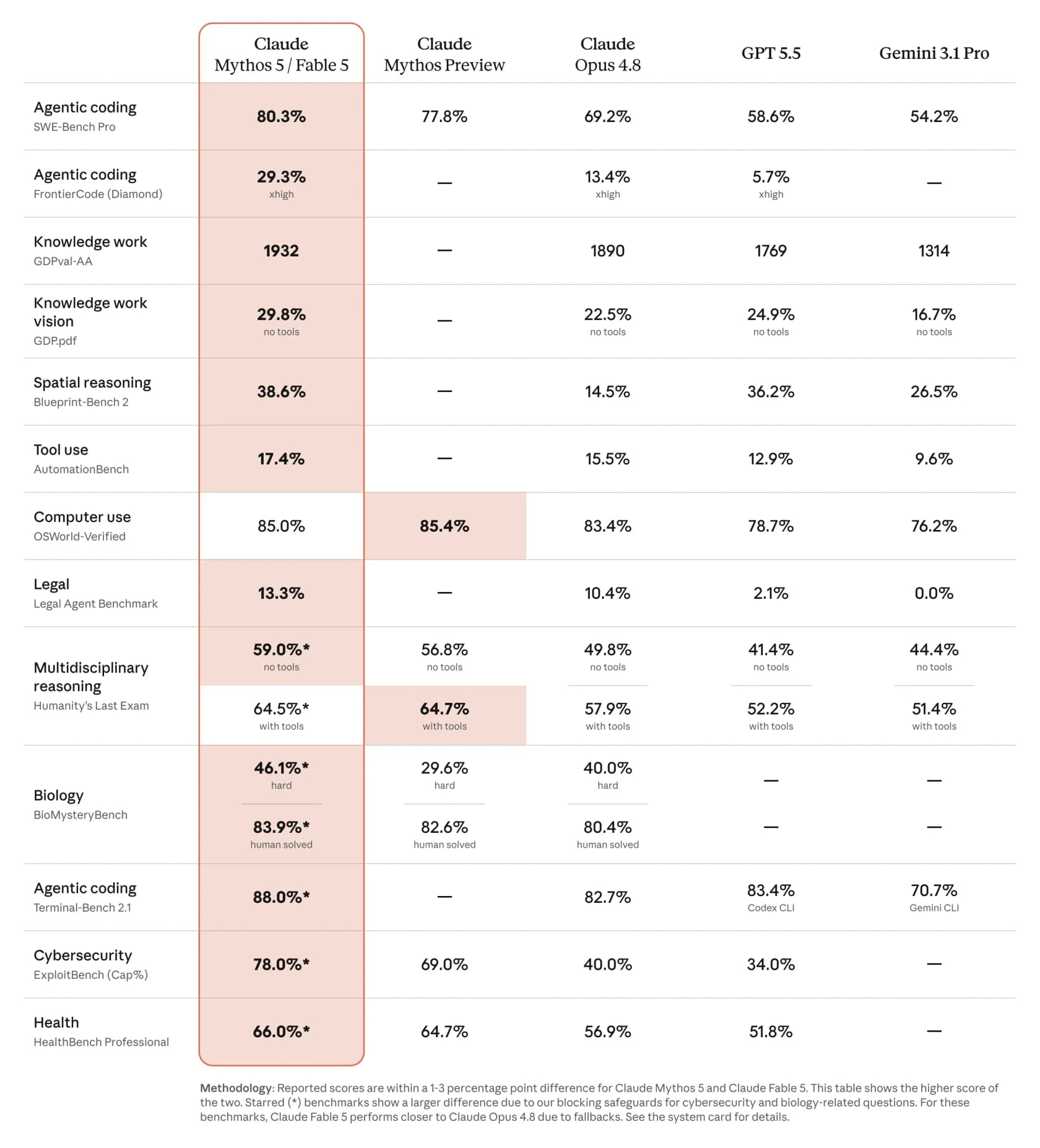
The flashiest thing Claude Fable 5 can do is write software that actually works. On Anthropic's published comparison it scores 80.3% on SWE-Bench Pro for agentic coding, against 69.2% for Opus 4.8, with GPT 5.5 at 58.6% and Gemini 3.1 Pro at 54.2%. On the tougher FrontierCode (Diamond) benchmark it more than doubles Opus, jumping to 29.3% from 13.4%. CNBC reported the gap as more than 10% higher than Opus 4.8 on some tests.
Numbers are one thing; a full day of real work is another. Developer Simon Willison pointed Fable at his open-source LLM library, and it identified and implemented four separate fixes, then shipped a new release that was almost entirely written by the model. His verdict captures the productivity ceiling:
"I'm really impressed with the quality of API design, tests, code and documentation that Fable put together for this. I spent several hours on it today, but it feels like several days' worth of work." - Simon Willison
He wasn't alone. Andrej Karpathy called it a step change worth a major-version bump, and one developer running the FrontierCode benchmark posted a striking progression: Opus 4.7 at 5.2%, Opus 4.8 at 13.4%, Fable 5 at 29.3%. If you're weighing up where it sits against the rest of the field, our roundup of the best AI coding assistant tools and the best Claude AI developer tools is a good next read.
It reads the long, messy documents you already have
Plenty of business work isn't code, it's documents, and this is where the 1,000,000-token context window earns its keep. Fable 5 "understands diagrams, charts, and tables nested in files and PDFs," which Anthropic frames around finance, legal, and analytics work, and there's no price premium for filling that full context.
The concrete proof came from a Hacker News user who handed it a 50-page PDF of dense, interconnected specs and got back a correct breakdown of what was done, partly done, and missing:
"I gave it a 50 page PDF of fairly dense and interconnected specs and asked it which had been implemented... it correctly identified what was done, what was partially done, and what was missing." - Hacker News commenter
For any team sitting on a pile of contracts, policy docs, or a sprawling knowledge base, that's more useful day-to-day than another point on a coding leaderboard. It's also the same muscle a support agent uses when it reads your help docs and past tickets to answer a customer, just pointed at internal documents instead.
What it costs to do all this
Here's the part that tempers the excitement. Everything above runs at frontier-tool prices: $10 per million input tokens and $50 per million output, exactly twice Opus 4.8. Cached input tokens get a 90% discount, and there's a 1.1x surcharge for US-only inference, but the headline rate is what you'll feel. For how Fable 5 stacks up against the rest of the lineup, our Claude pricing guide breaks down every tier, and the Claude Pro plan is where most individuals first meet it.
| Spec | Claude Fable 5 |
|---|---|
| Launched | 9 June 2026 |
| Model class | "Mythos-class", a tier above Opus 4.8 |
| Context window | 1,000,000 tokens |
| Max output | 128,000 tokens |
| Knowledge cut-off | January 2026 |
| Input price | $10 / 1M tokens ($1 cached) |
| Output price | $50 / 1M tokens |
| Long-context surcharge | None |
How much you actually spend depends almost entirely on how hard you let it think. Simon Willison ran his "draw a pelican on a bicycle" test across all five thinking-effort levels, and the cost for a single image ranged from under 10 cents at "low" to about 72 cents at "max". The effort level is a dial you set, and it's the main lever on your bill.
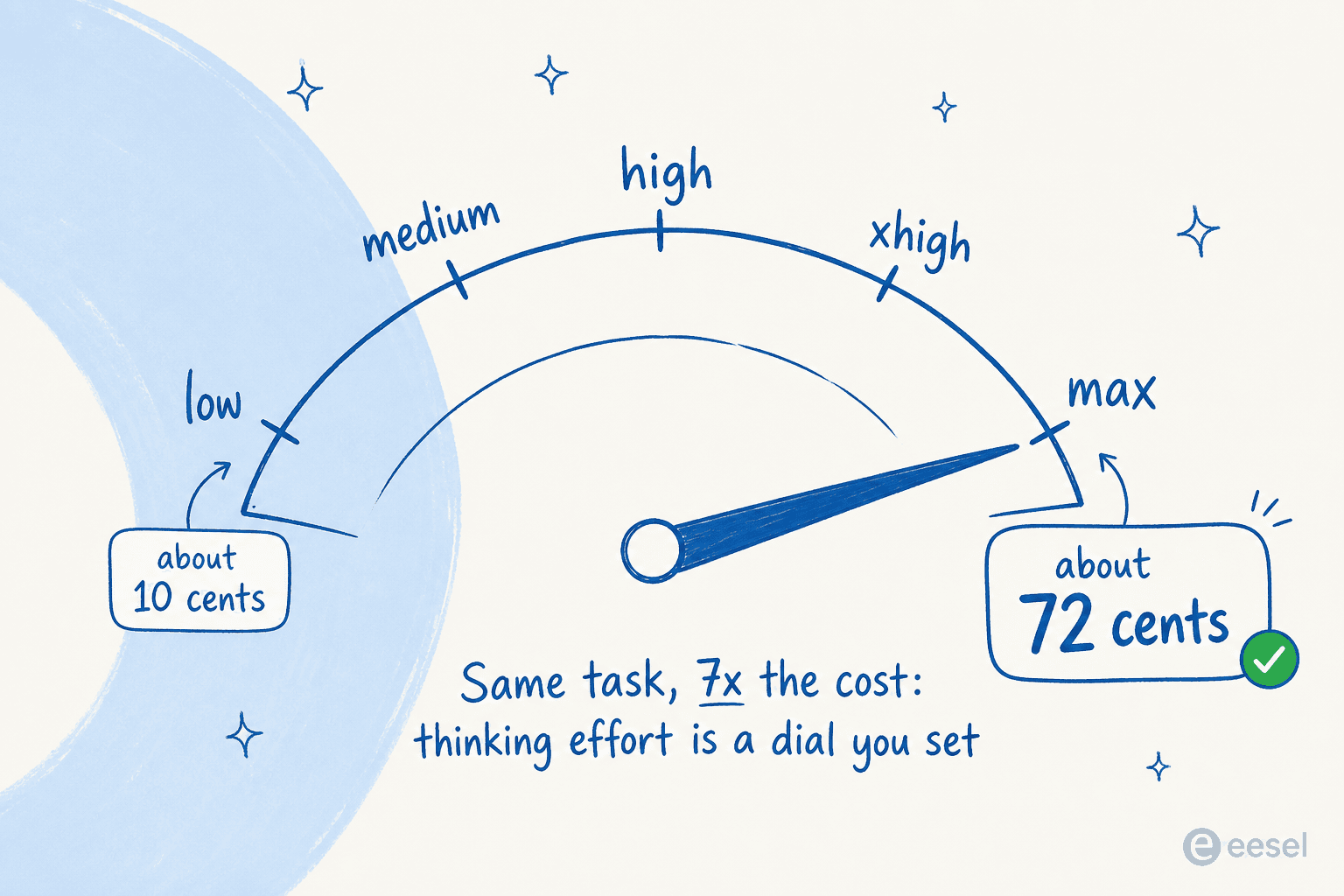
The bill adds up fast at the high end. Willison tracked a single day of testing at $110.42 of token spend. But there's a real counterweight: Canva's evaluations lead found Fable used about half the tokens of Opus 4.8 in their internal agentic harnesses, so a smarter model that finishes in fewer steps can land at roughly the same real-world cost. The lesson isn't "Fable is unaffordable," it's that your costs depend entirely on how you run it.
What Claude Fable 5 won't do
Capabilities cut both ways, and there's one thing Fable 5 deliberately won't do at full strength. For cybersecurity, biology, chemistry, and model-distillation prompts, a new generation of classifiers detects the topic and routes your response to Opus 4.8 instead, and you're told it happened. Anthropic says at least 95% of sessions never trigger any fallback.
The catch is the false positives. Developers reported being switched to the weaker model mid-session for completely benign work, including one user who got refused on a basic liquid-handling protocol with nothing risky in it. AI-policy writer Nathan Lambert flagged a second, quieter mechanism for prompts that look like frontier AI research, where the model can get less effective without telling you. The practical advice: if your work sits in a technical vertical, test before you commit to it.
What all this means if you run a support team
This is where we live, so let's be specific. Given everything Fable 5 can do, should a support leader rush to wire it into their helpdesk? Mostly, not as much as the hype suggests.
Here's the uncomfortable truth about AI for customer service: for tier-1 tickets, the model is rarely the bottleneck. Most teams shopping for customer service automation are quietly over-indexing on which model sits underneath. A well-grounded Opus 4.8 or even Sonnet 4.6 already answers the overwhelming majority of "where's my order," "how do I reset my password," "what's your refund policy" questions correctly. Paying double for Fable 5 to answer them is like renting a Formula 1 car for the school run. What actually decides whether your AI helpdesk agent works is everything wrapped around the model. It's the same pattern that separates the strong tools in any AI helpdesk software roundup from the forgettable ones.
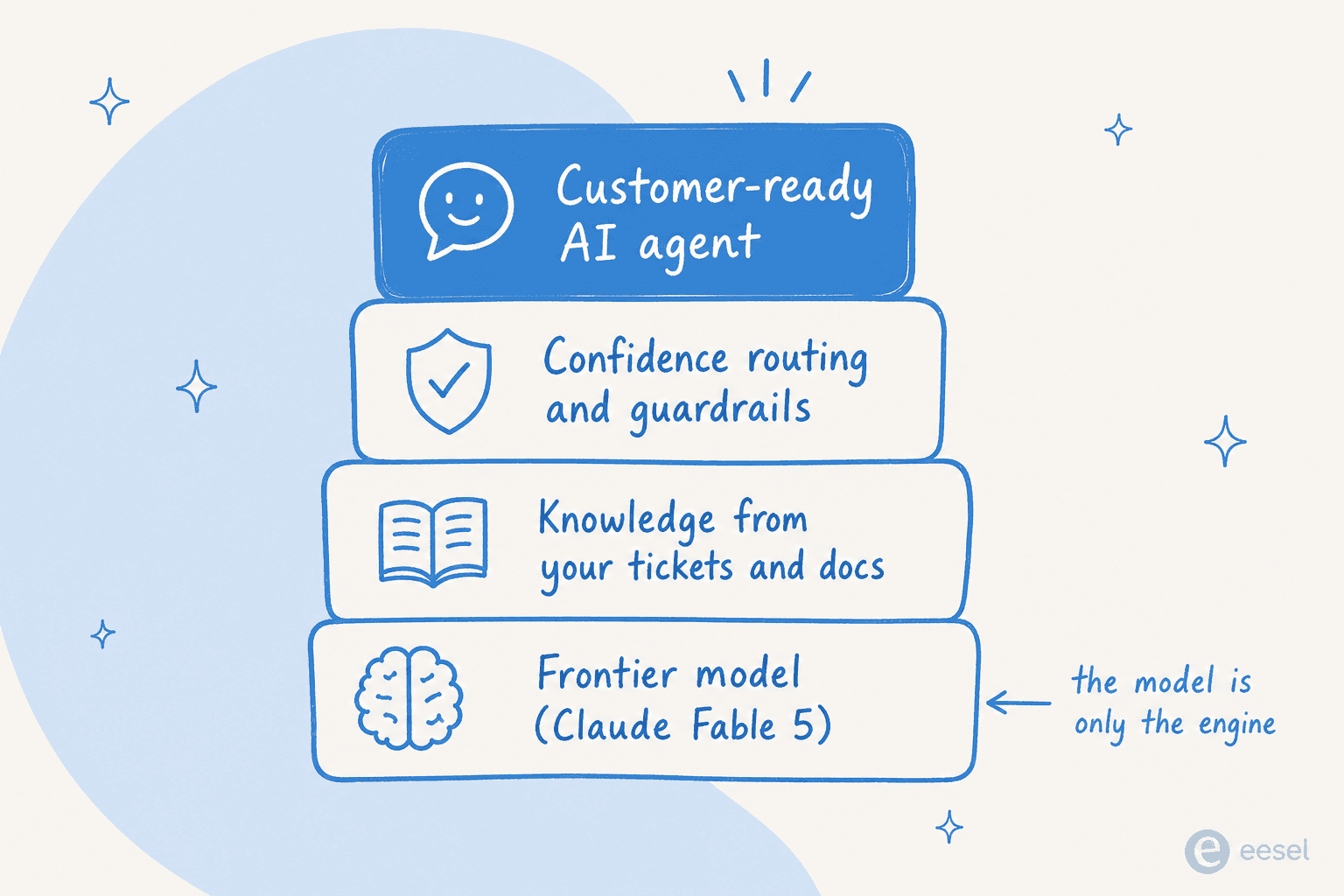
Three things matter more than the model tier. First, does it know your business? The win comes from training on your past tickets and help docs, not from a smarter base model. Second, does it know when to stay quiet? Raw models answer confidently even when wrong, which is precisely why chatbots give bad answers; production agents need confidence-based routing, the heart of any good ticket triage setup, so low-confidence tickets get drafted or escalated, not auto-sent. As one DTC supplements CX lead put it in a customer interview, the AI will never answer 100% of questions, so what they actually want is an agent that only handles the tickets it's confident about and leaves the rest alone. That's a product capability, not a model capability.
Third, can you trust it before it goes live? That points straight at the build-versus-buy question, which comes up constantly: "Anthropic just shipped an incredible model, why not build our support bot on the API?" You can. It's also a bigger project than it looks, because the model gives you intelligence but not the helpdesk connection, the guardrails, the simulation environment, or the reporting. Several technical teams who tried it switched to buying instead:
"We could try to write our own LLM application but we didn't want to invest our time into that. We wanted something that we would not have to maintain." - Karel, GENERAL BYTES
A frontier model is the bottom layer of the stack, not the whole stack. If your core product is AI, build. If it's anything else and you just want tickets answered well, buying the layers above the model is faster, cheaper, and less fragile, the same logic behind choosing any AI for ticket automation over a homegrown script.
Try eesel
eesel AI is the layer that sits on top of frontier models like Claude, so you get the capability without the engineering project. It plugs into your existing helpdesk (Zendesk, Freshdesk, HubSpot, Gorgias, and 100+ integrations), learns from your past tickets and help docs on day one, and answers across triage, drafting, and resolution.

The differentiator is the part Fable 5 can't give you on its own: a simulation mode that runs the agent against thousands of your past tickets so you see exactly how it would have responded, and what your resolution rate would be, before a single customer talks to it. That's how Gridwise got to 73% of tier-1 requests resolved in their first month. And because pricing is usage-based at $0.40 per resolved ticket with no per-seat fees, you pay for outcomes, not for tokens you can't predict. You can try eesel free with $50 of usage and no credit card.
Frequently Asked Questions
What can Claude Fable 5 do that older models couldn't?
Can Claude Fable 5 write and run code on its own?
Can Claude Fable 5 handle customer support questions?
How much does it cost to run Claude Fable 5?
What can't Claude Fable 5 do?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.