What Claude Sonnet 5 is, in one minute
I build on these models for a living, so I'll keep the spec recital short. Claude Sonnet 5 (claude-sonnet-5) is the direct successor to Sonnet 4.6 and the new default model on Claude.ai. Anthropic calls it "our most agentic Sonnet yet," and the headline specs back the framing: a 1M-token context window, up to 128K tokens of output, high-resolution vision, and adaptive thinking on by default.
The two things worth internalizing before anything else:
- The
effortparameter (low/medium/high/xhigh/max) is new territory for a Sonnet model, which is the first to getxhigh. It's the knob that decides how hard the model thinks, and it's the knob that decides your bill. - A new tokenizer that produces roughly 1.0-1.35x more tokens for the same text versus Sonnet 4.6, which matters more than it sounds. More on that below.
It shipped everywhere on day one: Claude.ai (web and mobile), Claude Code and Cowork, the Claude Platform, plus AWS, Google Cloud, and Microsoft Foundry. For a fuller rundown of what changed, my colleague wrote up what Claude Sonnet 5 is separately; this piece is the review.
The benchmarks: how good is it, really?
Here's the table Anthropic published, and it's the clearest way to see where Sonnet 5 actually lands.
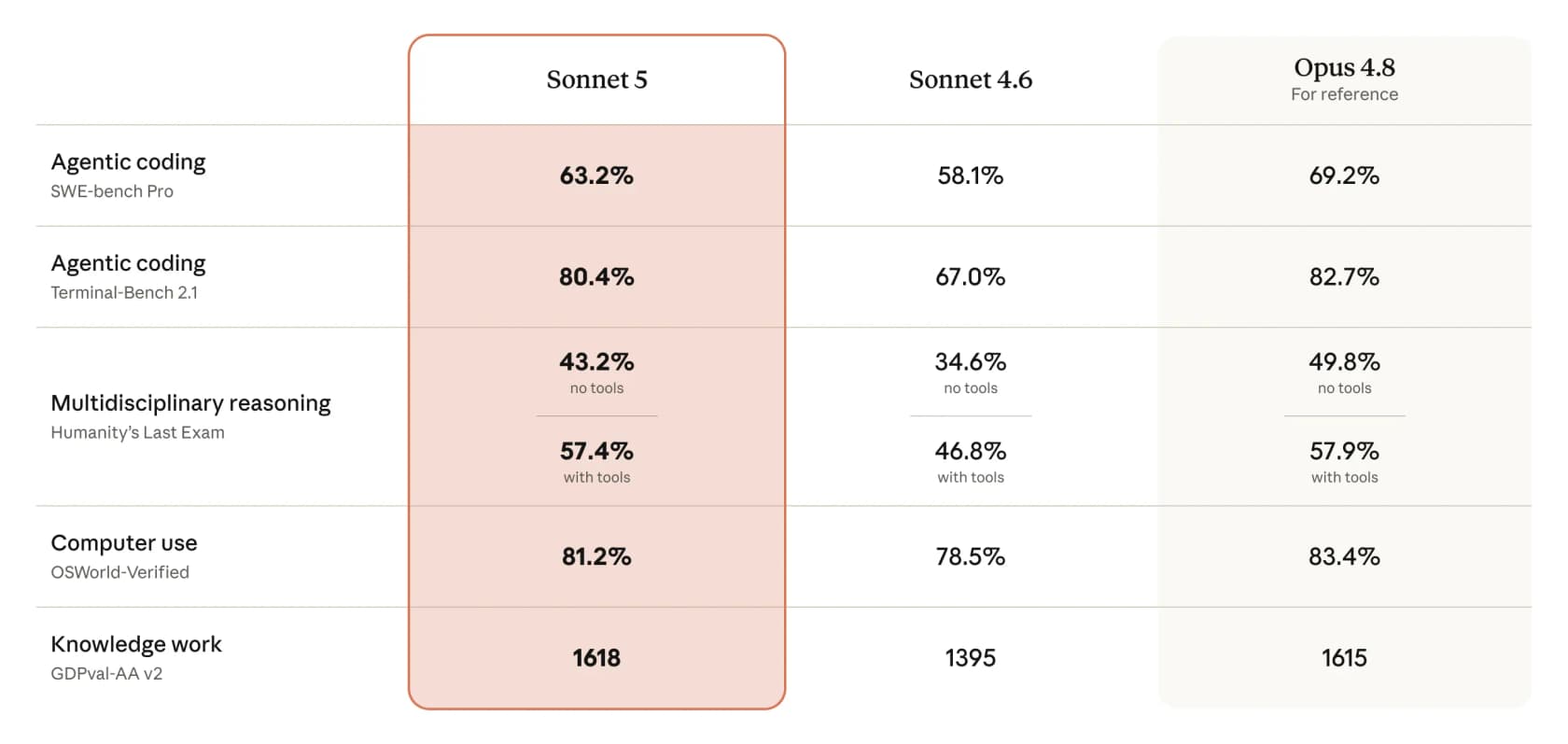
A few numbers jump out. On agentic coding, Sonnet 5 hits 63.2% on SWE-bench Pro (up from 58.1% for Sonnet 4.6, and closing on Opus 4.8's 69.2%) and 80.4% on Terminal-Bench 2.1, nearly matching Opus 4.8's 82.7%. On computer use (OSWorld-Verified) it scores 81.2%, a hair under Opus 4.8's 83.4%. And on knowledge work (GDPval-AA v2) it posts 1618, edging out Opus 4.8's 1615, which is the kind of result that makes the "near-Opus" claim ring true rather than marketing.
The pattern holds on Humanity's Last Exam: with tools, Sonnet 5 hits 57.4% against Opus 4.8's 57.9%, basically a tie. Where Opus still clearly leads is tools-off reasoning (49.8% vs 43.2%), which is the tell for what Opus is still for.
What makes the story more interesting than a single-number leaderboard is how the gains show up as you spend more. Anthropic plotted pass rate against cost per task on BrowseComp, the agentic-search benchmark:
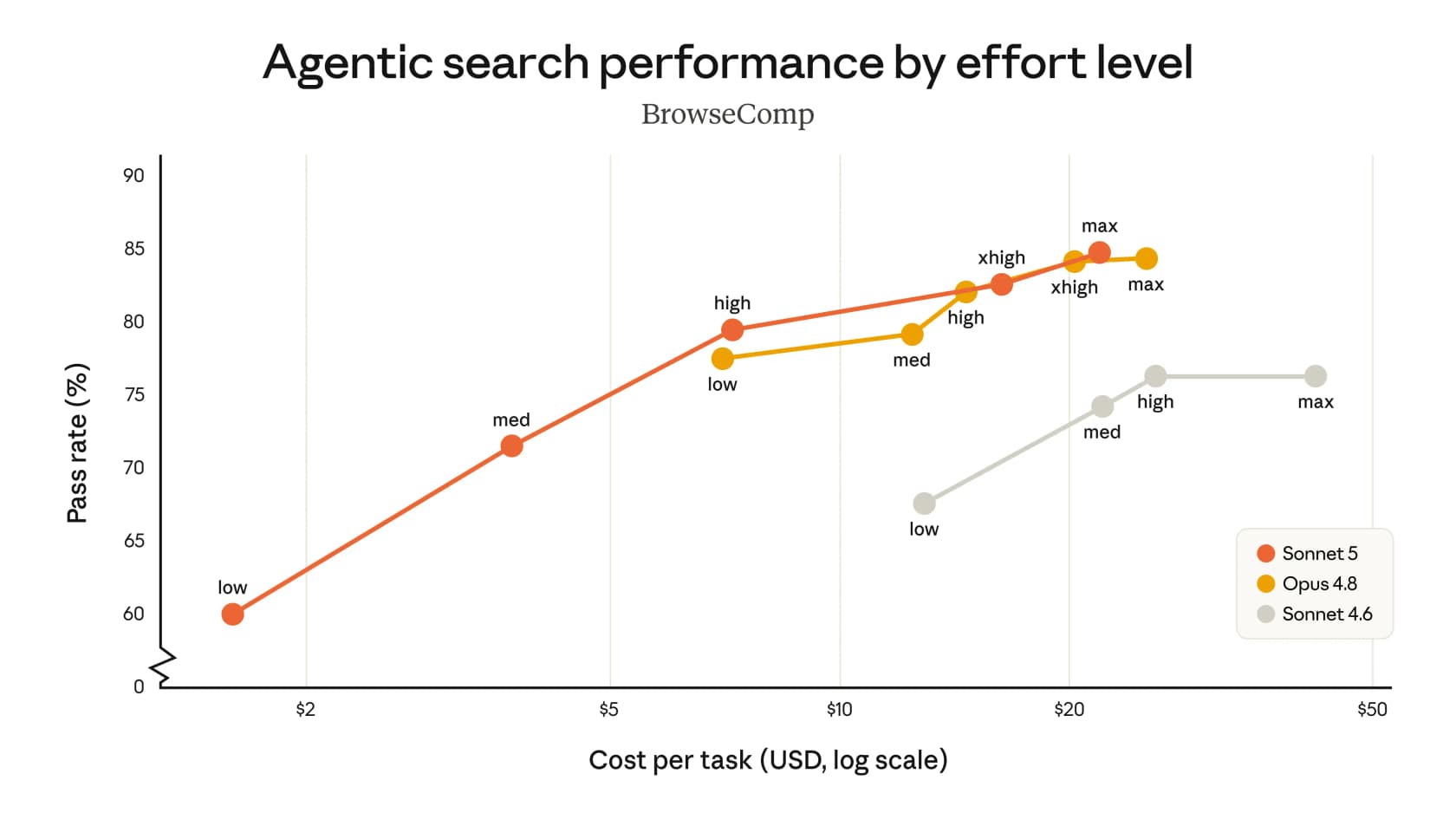
The orange Sonnet 5 line sits well above old Sonnet 4.6 at every price point, and it tracks the Opus 4.8 curve closely until the very top end. In plain terms: for most of the cost range, Sonnet 5 gives you Opus-shaped results for Sonnet money. That's the whole review in one chart.
Where Sonnet 5 sits in the Claude 5 lineup
Anthropic's naming is a bit of a maze right now (the flagship is called Fable 5, while Opus, Sonnet, and Haiku keep their own version numbers), so here's how the tiers actually stack by price and capability.
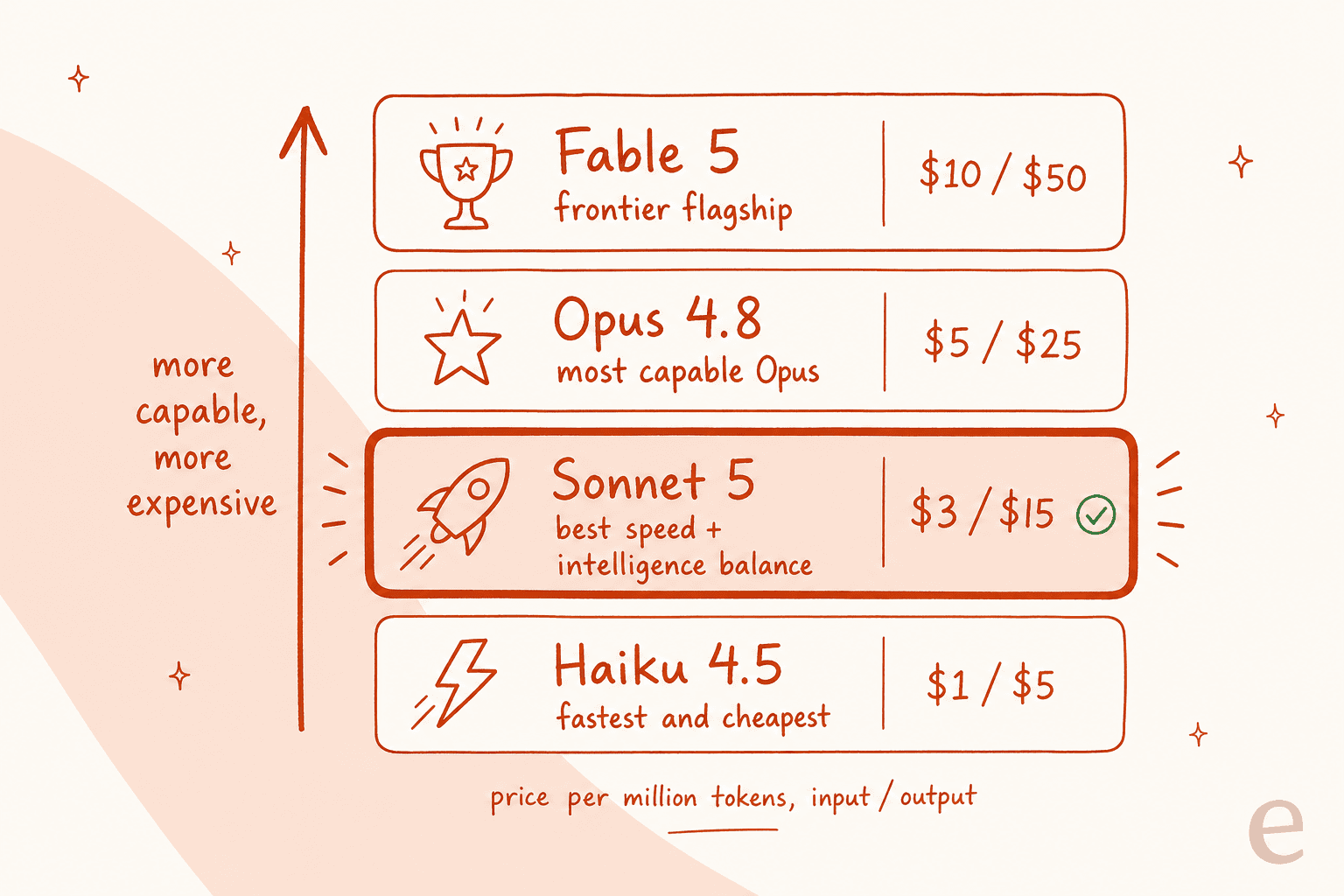
Sonnet 5 sits squarely in the middle: cheaper and faster than Opus 4.8, more capable than Haiku 4.5, and well below the Fable 5 frontier tier. Anthropic's own framing is that the biggest recent capability jumps have come from its Opus-class models, and that "Sonnet 5 narrows the gap." The benchmarks agree. The practical upshot: for a lot of teams, the "which Claude do I default to?" question now has a boring answer, and it's this one.
| Model | Role | Input / output per MTok | Context |
|---|---|---|---|
| Claude Fable 5 | Frontier flagship | $10 / $50 | 1M |
| Claude Opus 4.8 | Most capable Opus-tier | $5 / $25 | 1M |
| Claude Sonnet 5 | Best speed + intelligence balance | $3 / $15 | 1M |
| Claude Haiku 4.5 | Fastest and cheapest | $1 / $5 | 200K |
The effort dial is the real story
If you take one thing from this review, make it this: with Sonnet 5, you stop switching models to control cost and start turning a dial instead.
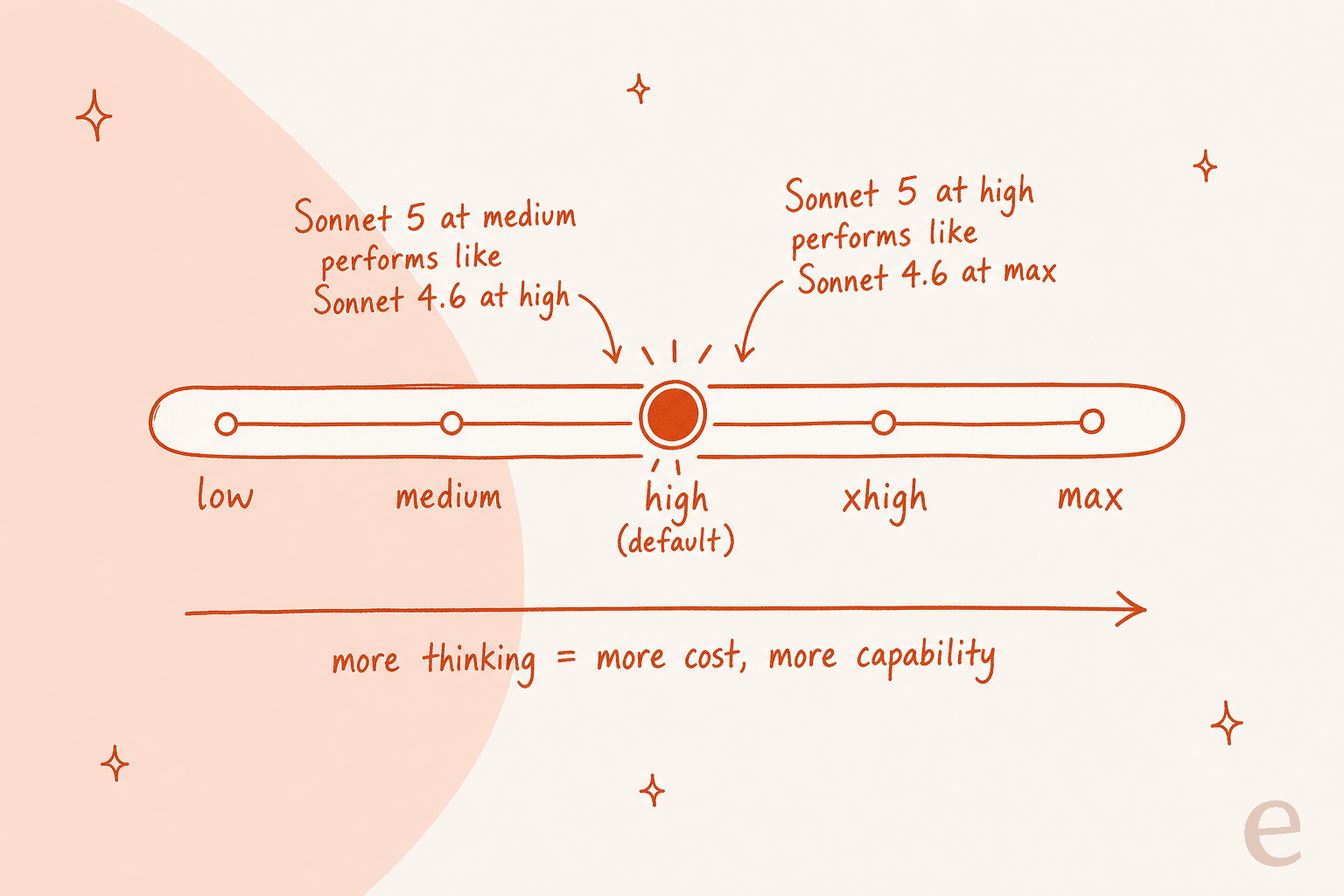
Anthropic's rough mapping is genuinely useful for budgeting: Sonnet 5 at medium performs roughly like Sonnet 4.6 did at high, and Sonnet 5 at high lands around where 4.6 sat at max. So the same quality bar now costs you fewer thinking tokens, which is a real efficiency win. The flip side is that the default is high, so out of the box Sonnet 5 thinks harder (and costs more per call) than you might expect if you're used to older defaults. Anthropic even raised rate limits across Chat, Cowork, Claude Code, and the API specifically to absorb the higher token usage at higher effort.
For anyone wiring Sonnet 5 into a product, the effort dial is where your cost engineering now lives. Set it too low and you leave quality on the table; leave it on max for simple tasks and you torch budget for no reason.
The value controversy: is it actually cheaper?
This is where the launch-week consensus split, and it's the most useful part of the review to sit with.
The sticker price is unchanged from Sonnet 4.6: $2 / $10 per million tokens as an introductory rate through August 31, 2026, then $3 / $15 after that. But two things quietly push the real cost up. First, that new tokenizer bills the same text on roughly 1.0-1.35x more tokens. Second, the higher default effort means more thinking tokens per request. Per-token price parity is not per-request price parity, and Anthropic is candid that the intro discount exists to keep the migration "roughly cost-neutral" while it lasts.
The independent benchmark aggregator Artificial Analysis put a sharp point on it:
"Claude Sonnet 5 achieves 53 on the Artificial Analysis Intelligence Index, but without promotional pricing will cost more per task than Opus 4.8."
They clocked it at about $2.29 per task on that index. On the enthusiast side, the reaction was the mirror image, Wade Foster, Zapier's CEO, summed up the bull case:
"Claude Sonnet 5 is live. It does Opus-level work at Sonnet-level pricing."
Both are right, which is the point. At low and medium effort on typical work, Sonnet 5 is a clear value. Push it to xhigh or max on a hard task and you can spend past Opus 4.8 for a result Opus would have given you more cheaply. The threads on r/singularity have been chewing on exactly this. The verdict isn't "cheap" or "expensive," it's "cheap if you manage the dial."
Sonnet 5 vs Opus 4.8: which should you use?
Because they overlap so much (both 1M context, both strong on agents), the decision is less "better vs worse" and more "which one for this job."
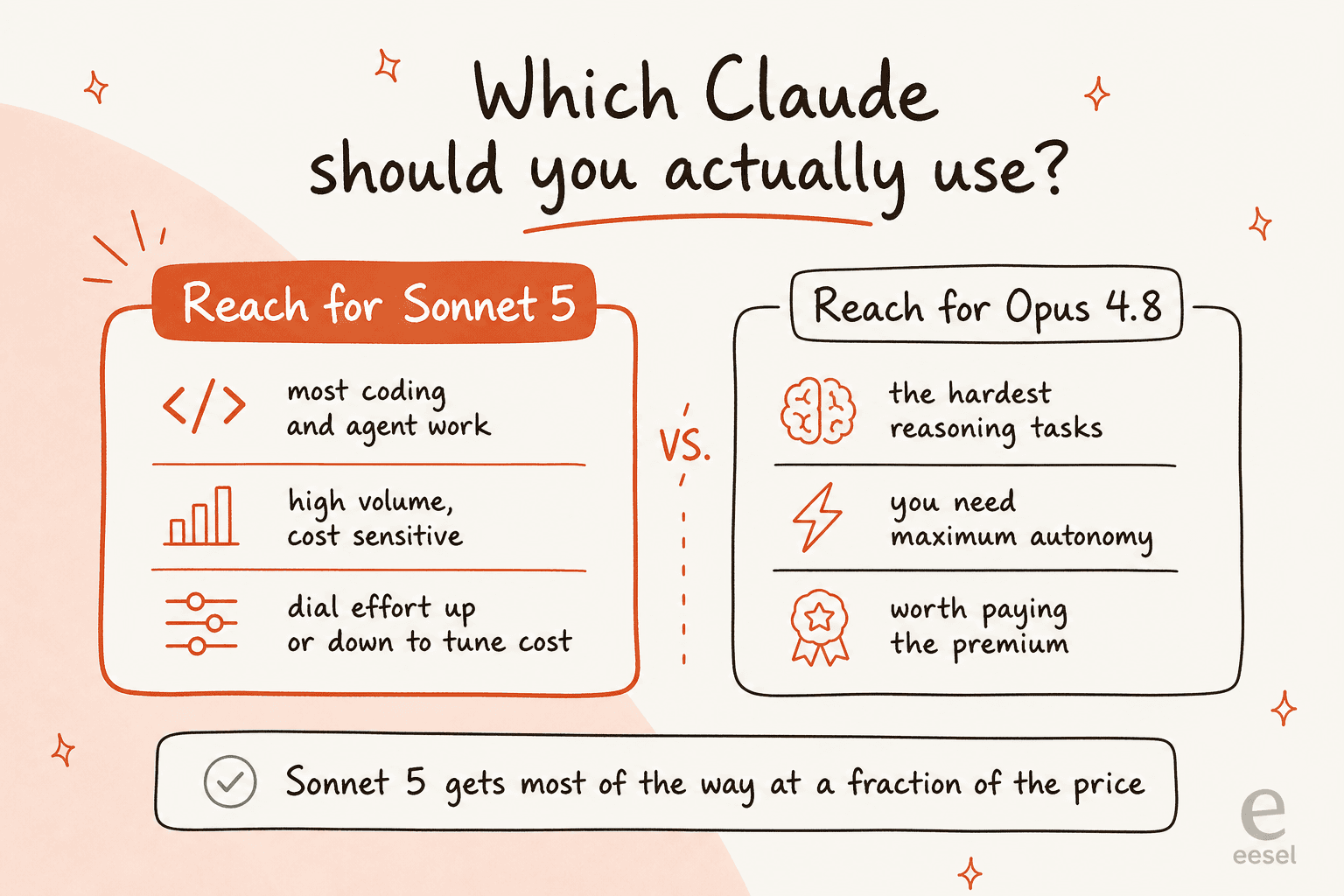
My rule of thumb after reading the numbers: default to Sonnet 5 for the bulk of coding, tool use, and everyday agent work, especially anything you run at volume where cost compounds. Reach for Opus 4.8 when the task is genuinely hard reasoning, needs long stretches of autonomy, or is high-stakes enough that the marginal quality is worth the premium (and where Opus's tools-off reasoning edge actually matters). For most people, most of the time, Sonnet 5 is now the right default, and Opus is the escalation path, not the starting point.
Is it safe to put in front of customers?
For a chatbot demo, safety is a footnote. For an agent that autonomously touches real customer tickets, it's the whole ballgame, so I looked closely here.
The good news: Sonnet 5 is the safest Sonnet to date. Anthropic reports lower hallucination, less sycophancy, stronger prompt-injection robustness, and cleaner refusals of malicious requests than Sonnet 4.6. On the automated behavioral audit it scored better (safer) than its predecessor.
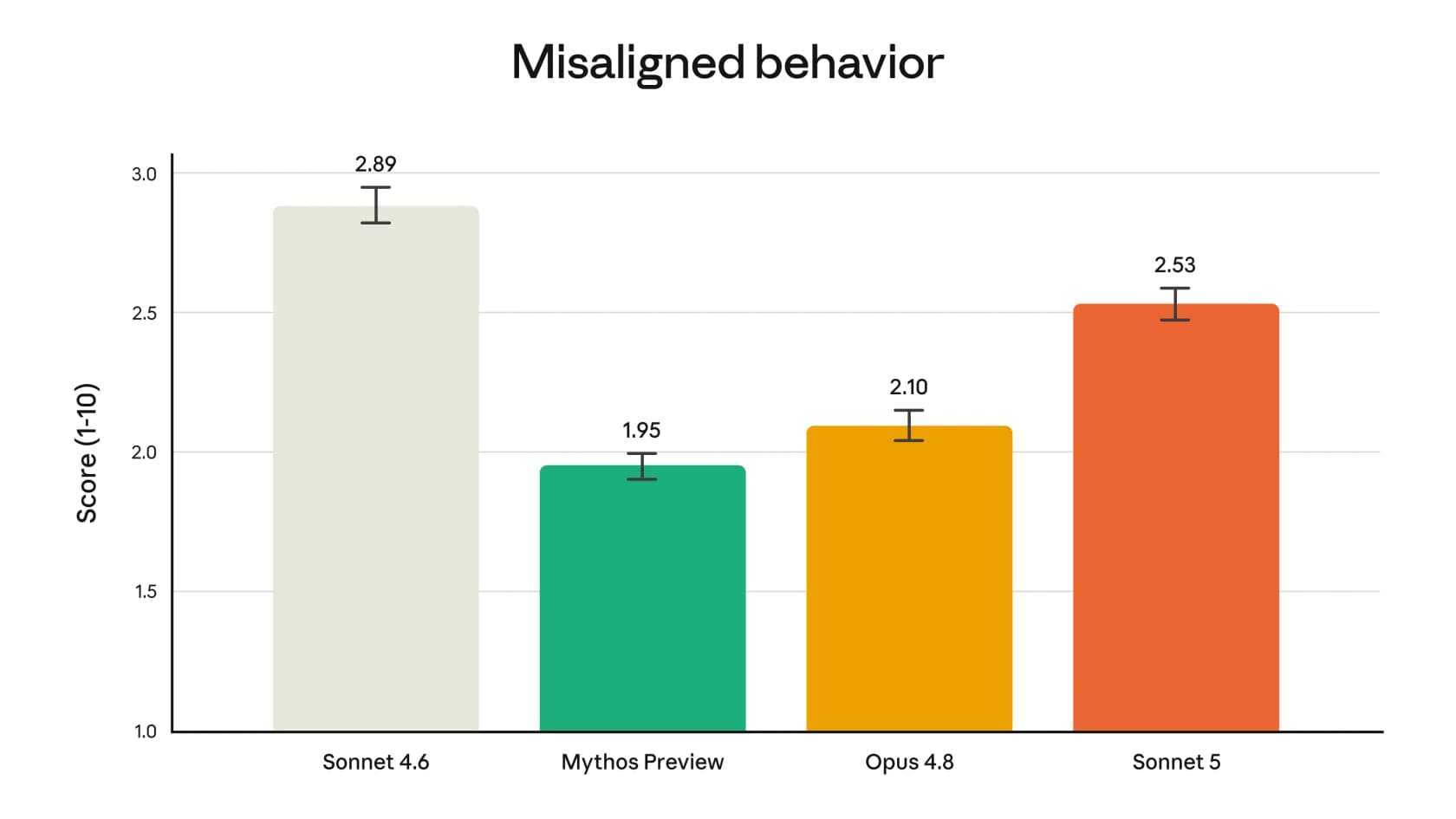
The honest wrinkle: Sonnet 5's misaligned-behavior score (2.53) is better than Sonnet 4.6 (2.89) but worse than Opus 4.8 (2.10) and Mythos Preview (1.95). So it's safer than the model it replaces, not the safest in the family. Anthropic's system card is upfront that Sonnet 5 poses "very low alignment risk (though higher than for previous Sonnet models)."
On offensive-cyber capability, though, Sonnet 5 is reassuringly weak: on Anthropic's Firefox 147 exploit-development test (built with Mozilla, all vulnerabilities since patched), it never produced a working exploit.
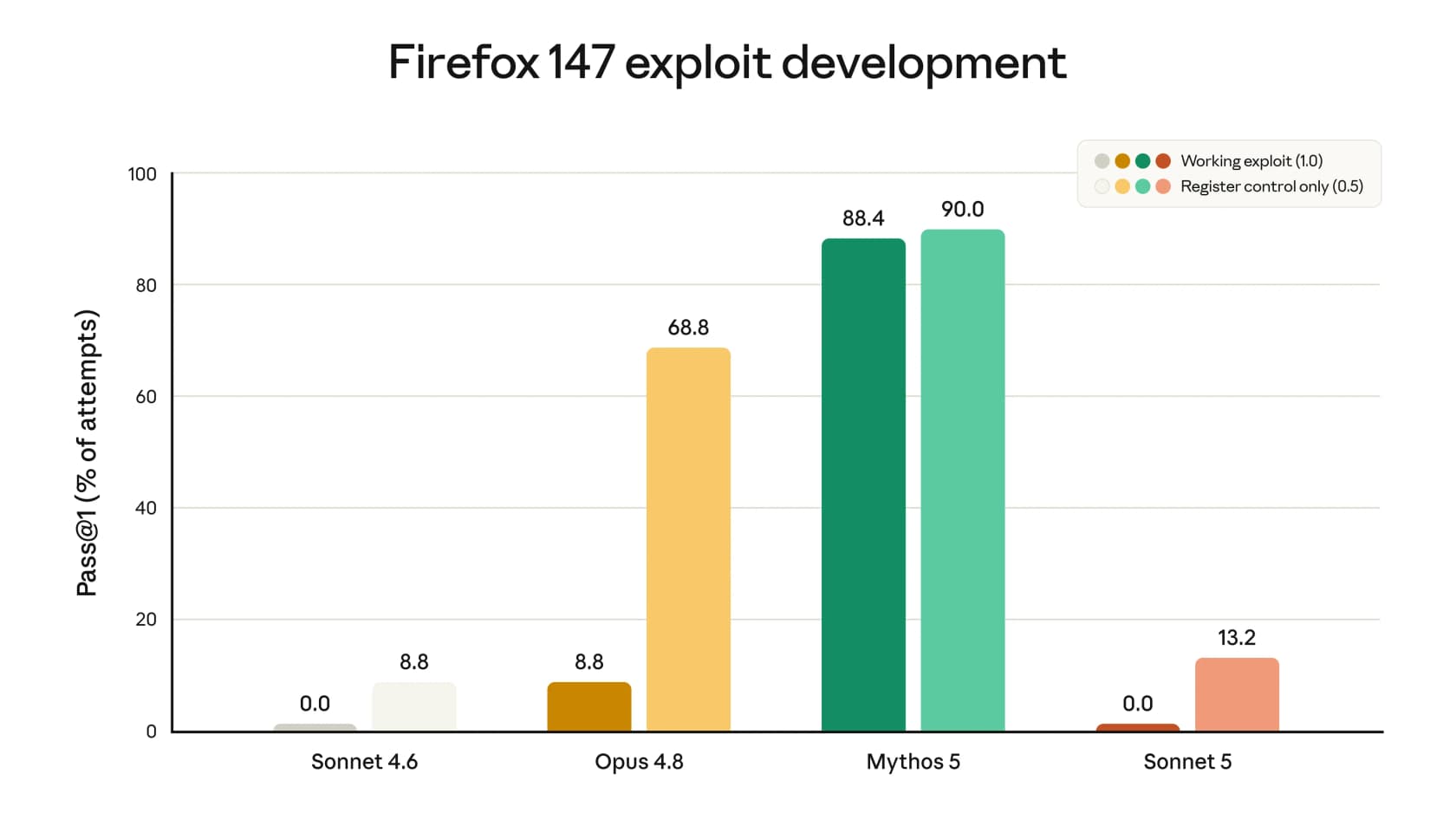
That combination (capable, cheaper, and not a cyber-offense powerhouse) is close to ideal for customer-facing automation. But "the model is safe" and "the deployment is safe" are two different sentences, which brings me to the part that actually matters if you run a support team.
What Sonnet 5 means if you run support
I work at eesel, where we've spent years putting AI agents on live support queues, and the thing that survives every model launch is this: a smarter, cheaper model lowers the cost of a correct answer, but it doesn't decide which tickets are safe to answer. We've watched confident-sounding bots quietly give wrong answers, which is exactly why the guardrails matter more than the raw benchmark.
A DTC supplements CX lead put the customer-side version of this to us more bluntly than any spec sheet could: "the AI will never be able to answer 100% of the questions. I need an AI who is only handling the tickets that it's confident to handle, and all the other ones, leave them alone." That instinct doesn't change when the underlying model gets a version bump.
Sonnet 5 makes the economics better, that's real. But the deciding factors for support automation, confidence-based routing, training on your own historical tickets, and the ability to simulate a rollout before it ever touches a customer, live in the layer around the model, not in the model itself. That's the part I'd tell anyone to focus on once they've picked a model they trust.
Try eesel
The nice thing about picking a support tool that's model-agnostic is that launches like Sonnet 5 just make it better underneath, with nothing for you to swap out. eesel AI plugs into your existing helpdesk, trains on your past tickets and help center, and runs on frontier models like Claude Sonnet 5, so you get the capability gains without re-plumbing anything.

Where it earns its keep is the part a raw model can't do: a simulation mode that replays thousands of your historical tickets so you see the resolution rate before going live, and confidence-based rules so the AI only auto-replies where it's sure and leaves the rest for a human. One customer, Gridwise, saw eesel resolve 73% of their tier-1 requests in the first month. You can try eesel free and simulate on your own tickets in a few minutes.









