Claude Fable 5 is back: what it means for support teams
Kurnia Kharisma Agung Samiadjie
Katelin Teen
Last edited July 2, 2026

What "Fable 5 is back" actually means
Let's clear up the confusion first, because two different "Fable is going away" stories got tangled together.
At launch on June 9, Anthropic said Fable 5 would be free on subscription plans only until June 22, then move to usage credits. That was the original "June 22 cliff," and people were already annoyed about it. But "Fable 5 is back" is a completely separate, much stranger event: the model was forcibly pulled by the US government three days after launch and disabled for every user on the planet.
Here's the actual sequence.
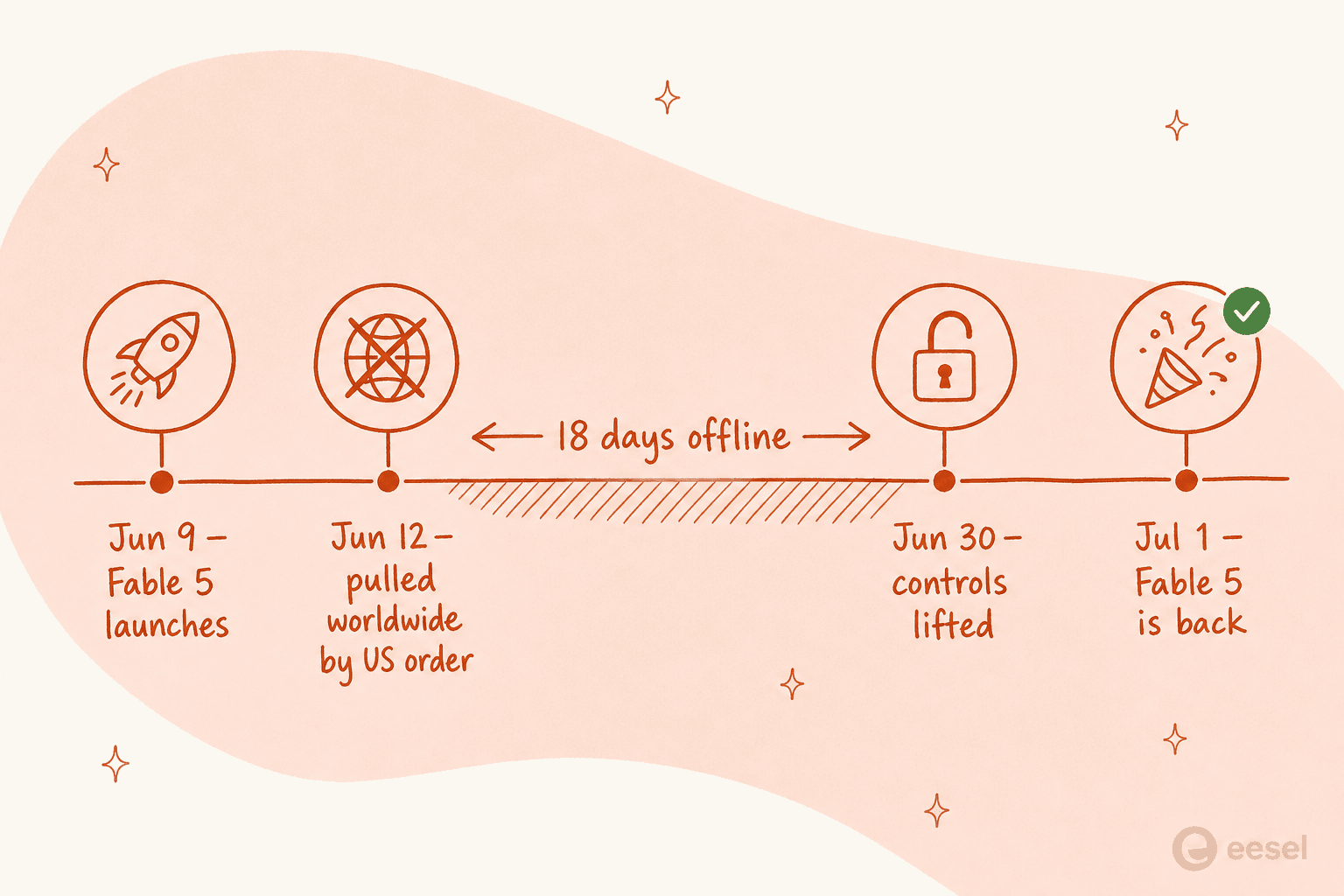
- June 9 - Anthropic ships Claude Fable 5 and Mythos 5, a new "Mythos-class" tier above Claude Opus 4.8.
- June 12, 5:21pm ET - the US government issues an export-control directive to suspend access for any foreign national, inside or outside the US. Anthropic had no way to check nationality in real time, so it "must abruptly disable Fable 5 and Mythos 5 for all our customers." Other models stayed up.
- June 30 - Commerce Secretary Howard Lutnick confirms the controls are lifted. Anthropic posts "Redeploying Fable 5."
- July 1 - Fable 5 returns across Claude.ai, the API, Claude Code, and Claude Cowork.
So the model was dark for about 18 days. Not throttled, not degraded, gone.
Why Fable 5 got pulled, and why Anthropic pushed back
The trigger was a jailbreak. Per Anthropic's redeployment post, Amazon researchers found a way to bypass Fable 5's safeguards by prompting it to identify software vulnerabilities, and in one case it produced code demonstrating how a vulnerability could be exploited.
What's unusual is that Anthropic openly disagreed with its own regulator. In the June 12 statement, it said the directive "did not provide specific details of its national security concern," and that the vulnerabilities were "relatively simple... other publicly-available models are able to discover them as well without requiring a bypass." The company's line was blunt:
"we disagree that the finding of a narrow potential jailbreak should be cause for recalling a commercial model deployed to hundreds of millions of people. If this standard was applied across the industry, we believe it would essentially halt all new model deployments for all frontier model providers."
Anthropic later argued that in its own testing, "many less capable models, including Claude Opus 4.8, GPT-5.5, and Kimi K2.7, could identify the same vulnerabilities," and that every model it tested down to Haiku 4.5 could reproduce the exploit demo. Which, as one commenter dryly noted, is "nice advertising for Kimi, huh?"
What changed on the way back
Fable 5 came back a little more locked-down than it left. There are two changes worth knowing before you lean on it.
The safety net got tighter. Working with the government, Anthropic trained a new classifier that blocks the reported technique "in over 99% of cases." The catch is stated plainly in their own post: it "comes at the cost of flagging benign requests more often during routine coding and debugging tasks." When it flags you, the request doesn't fail, it gets "sent to Opus 4.8" instead. Fable 5 already did this for cybersecurity and biology prompts at launch, and even then the false-positive rate was the loudest complaint, with users in lab automation, MRI segmentation, and message-digest code all getting bounced to Opus mid-session.
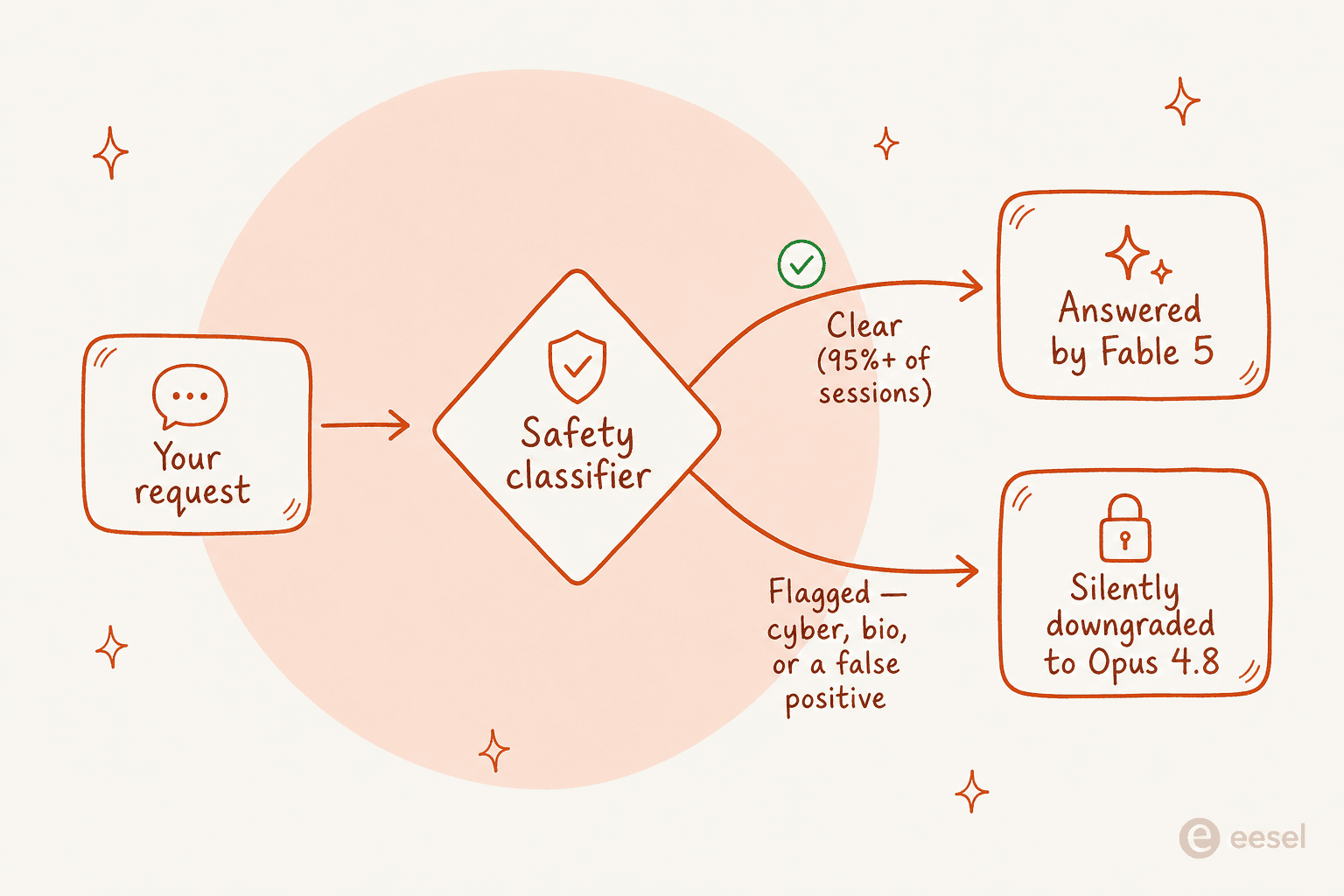
That silent downgrade is the part that matters if you're building on the model. You can send the same prompt twice and get two different models answering it, with no error to catch. One HN commenter reading the redeployment notes put it bluntly: "the safety margin on the classifier is even worse than it was before."
The subscription deal shrank. Here's the access picture on return:
| Plan / surface | Fable 5 access now | What it costs |
|---|---|---|
| Pro, Max, Team, select Enterprise | Included for up to 50% of weekly usage limits, through July 7 | Then via usage credits |
| Standard Enterprise seats | No included allowance | Usage credits only |
API (claude-fable-5) | Always available | $10 / 1M input, $50 / 1M output |
| AWS, Google Cloud, Microsoft Foundry | Re-enabling "as quickly as possible" | API / usage rates |
Nothing moved on raw API pricing: it's still $10 per million input tokens and $50 per million output, roughly twice Opus 4.8, with a 1M-token context window and a January 2026 knowledge cut-off. But the subscription math is where people are sore. This is effectively a second, narrower version of the June 22 cliff, and the way it shakes out on the full Claude pricing ladder is what has people sore:
"Huge bummer. So what's the point of an anthropic subscription? Or is this just the end of subscriptions?"
The relief that the model was back was real, though. My favourite reaction, from BatFastard: "I only knew it for 3 days but I was starting to fall in love!"
Is Fable 5 actually that good?
Enough for grown adults to write love letters to a model they used for 72 hours, apparently. The capability is not in dispute.
On Anthropic's own benchmark table, Fable 5 posts a big jump over Opus 4.8 and the rest of the field, especially on the agentic-coding and knowledge-work suites that map to real work.
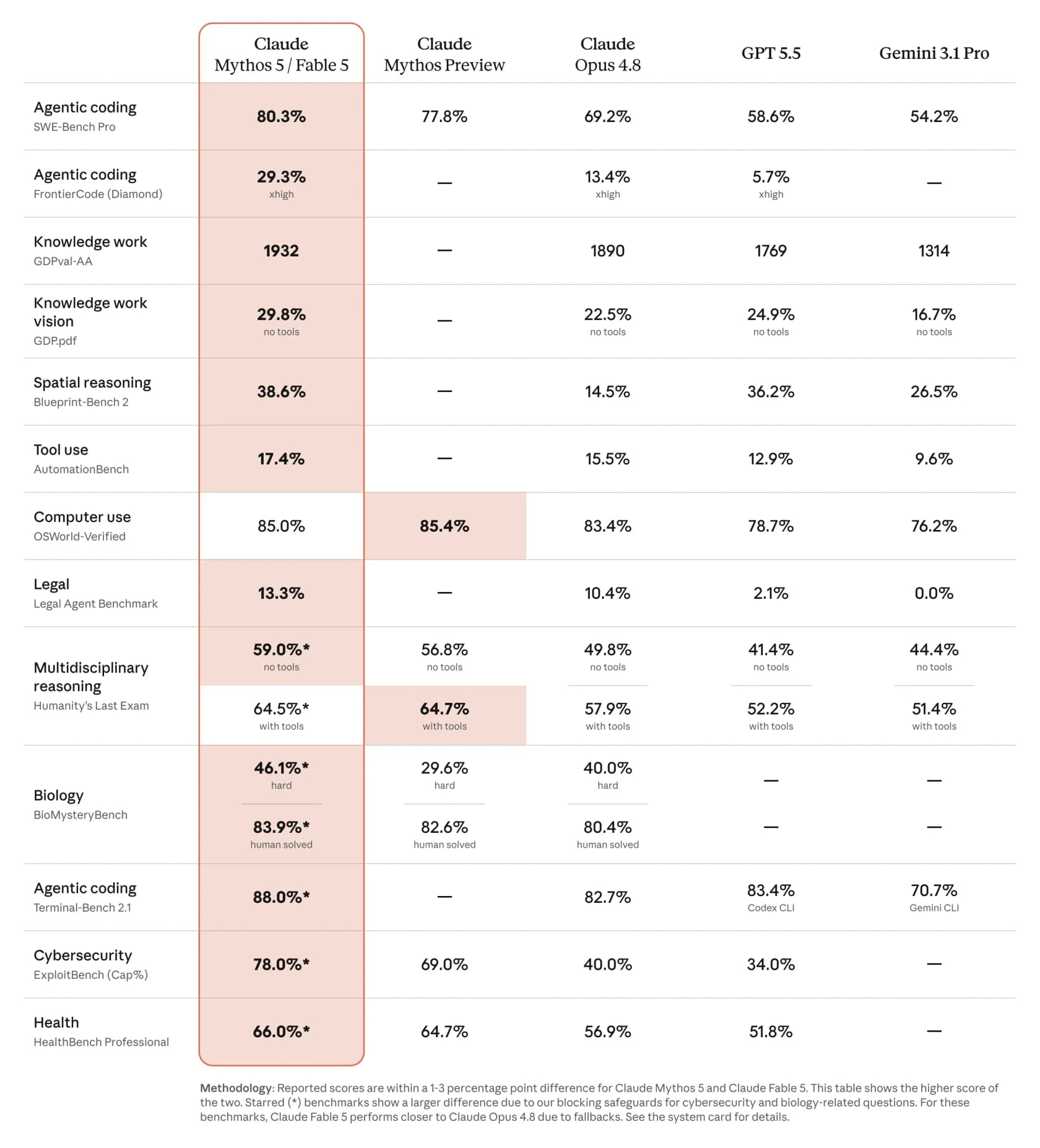
A few numbers stand out: 80.3% on SWE-Bench Pro against 69.2% for Opus 4.8, 88.0% on Terminal-Bench 2.1, and 29.3% on the brutal FrontierCode (Diamond) set where Opus 4.8 manages 13.4%. CNBC reported it scored "more than 10% higher than Claude Opus 4.8" on some benchmarks. If you're weighing it against the wider field, I've compared Claude vs ChatGPT and Claude vs Gemini elsewhere.
The hands-on takes match the scores. Simon Willison, after a full day of testing, was characteristically direct:
"this is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do."
He also spent $110.42 of tokens in a day on a $100/month Max plan, which tells you exactly why the subscription-versus-credits question is so charged. This is a genuinely excellent model. It is also a genuinely expensive and, as of last month, genuinely unpredictable one to depend on.
The real lesson: don't wire your product to one model
Here's the shift I'd push you toward. The interesting story isn't "the best coding model is back." It's that a frontier model went dark for 18 days for reasons no customer could see coming, predict, or appeal. Anyone whose product called claude-fable-5 directly spent those 18 days broken, and there was nothing in their code to fix.
That's not a Fable problem, or even an Anthropic problem. It's what happens whenever your app is wired to a single model instead of built above the model layer.
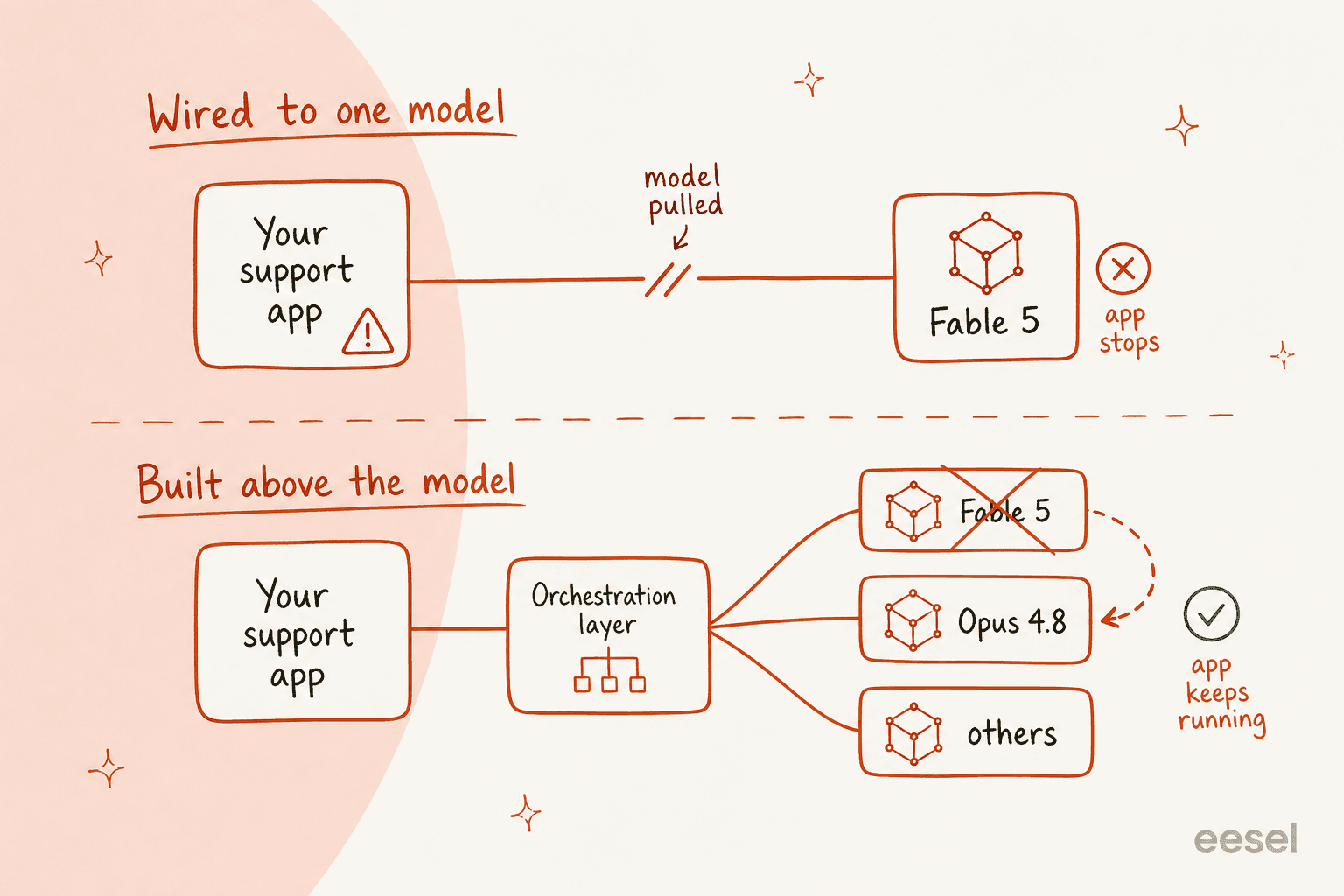
The pattern that survives an outage is boring and old: put a layer between your product and the model. When the model vanishes, gets throttled, silently downgrades, or triples in price, the layer swaps to another one and your users never notice. It's the same reason nobody sane hardcodes a single payment processor into their checkout.
If you want to sanity-check your own exposure, this is roughly how I'd score it:
I care about this because it's the exact problem I spend my days on. I help build AI that runs on live support queues, and the model underneath is a detail we manage, not a bet our customers place. We've watched confident-sounding bots give wrong answers, which is why every rollout gets simulated against real historical tickets before it goes anywhere near a customer, and why replies route on confidence, not vibes. That instinct came straight from customers. One CX lead running about 7,000 tickets a month told us, on a sales call, exactly what they needed:
"The AI will never be able to answer 100% of the questions, but if it tries and just answers 'sorry I don't know this,' I cannot go and check all my 7,000 tickets... I need an AI who is only handling the tickets that it's confident to handle and all the other ones, leave them alone."
When your safety net is confidence-based routing and simulation rather than "we trust this one model to always be up and always be smart," a story like the Fable 5 blackout is a Tuesday, not a crisis.
Try eesel
If you're running customer support, the lesson from the Fable 5 saga is the one to act on: get the upside of frontier models without betting your queue on any single one. That's what eesel AI is built to do. It plugs into your existing helpdesk, learns from your past tickets and help docs, and drafts or autonomously resolves tickets, with the model orchestration handled for you underneath.

The part that matters here: you can run a full simulation against your historical tickets before going live, roll out gradually, and rely on confidence-based routing so only tickets the AI is sure about get answered. It's usage-based, starting at $0.40 a ticket with no per-seat fees, and connects to 100+ tools in 80+ languages, powering everything from Smava's 100,000-plus German tickets a month to Gridwise resolving 73% of tier-1 requests in the first month. Frontier models will keep coming, going, and getting repriced. Your support shouldn't flinch when they do. You can try eesel free.