Update — July 8, 2026: Anthropic is extending Fable 5 access. Per Claude on X: "We’re extending access to Claude Fable 5 on all paid plans through July 12." — @claudeai
So what exactly is Claude Fable 5?
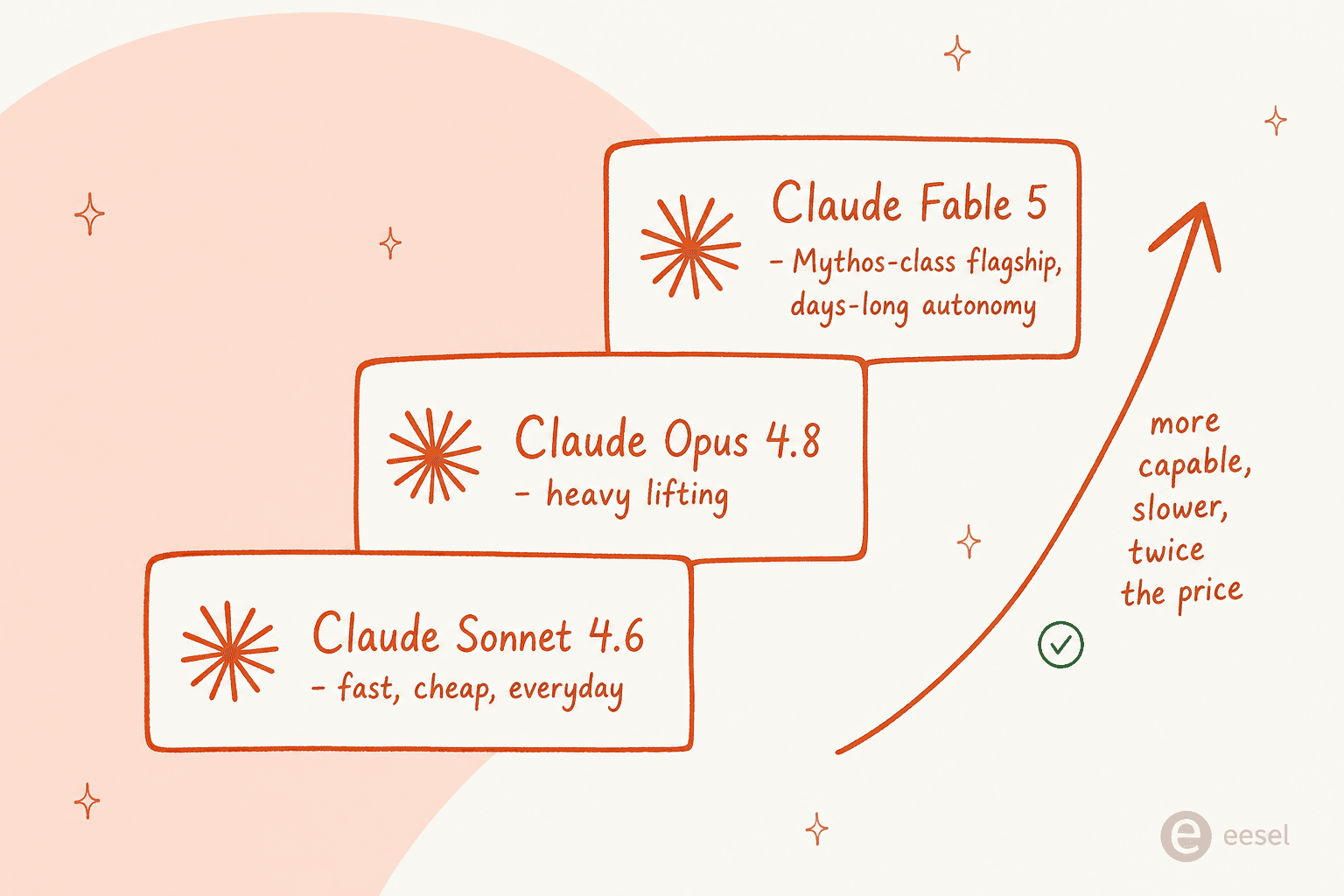
Anthropic frames Fable 5 as a "Mythos-level model built for your most ambitious, long-running projects", and the wording matters. "Mythos-class" is a brand-new capability tier the company is introducing above its existing Opus line, the way Opus has always sat above Sonnet and Haiku. It's the fifth model generation, and Anthropic says it's "designed to handle days-long, complex, and asynchronous tasks previous models couldn't sustain".
The slightly confusing part is that Fable 5 launched as one half of a pair. Fable 5 is the public, safeguarded version anyone with API access or a paid Claude plan can use. Mythos 5 is the same underlying model with the safety classifiers stripped out, gated to vetted cybersecurity and biology partners through Anthropic's Project Glasswing. Simon Willison, who spent a full day testing it, put it plainly: Anthropic say Fable 5 "offers the same performance as Claude Mythos 5, except with much more strict guardrails in place".
SecurityWeek captured why this is a milestone for Anthropic specifically: the company says this "marks the first time a model of this capability class has been deemed safe enough for widespread public and developer access". In other words, the Mythos tier existed before; what's new is letting the general public near it.
The specs that matter
If you just want the at-a-glance version, here's where Fable 5 lands. The context window and cut-off come from Simon Willison's hands-on notes; the pricing is confirmed by both CNBC and SecurityWeek.
| Spec | Claude Fable 5 |
|---|---|
| Launched | 9 June 2026 |
| Model class | "Mythos-class", a tier above Opus 4.8 |
| Context window | 1,000,000 tokens |
| Max output | 128,000 tokens |
| Knowledge cut-off | January 2026 |
| Pricing | $10 / 1M input, $50 / 1M output (2x Opus 4.8) |
| Long-context surcharge | None |
| Where to run it | claude.ai, the Claude API, Claude Code, Claude Managed Agents, AWS, and Microsoft Foundry |
One detail worth flagging for anyone working with long documents: there's no price premium for using the full 1M context, which isn't always the case with frontier models. The API ID, if you're wiring it in yourself, is claude-fable-5.
How powerful is it, really?
This is where Fable 5 earns the "most powerful" label. On Anthropic's published comparison, it posts a remarkable leap on pretty much every relevant benchmark, and the gaps over the rest of the field aren't subtle.
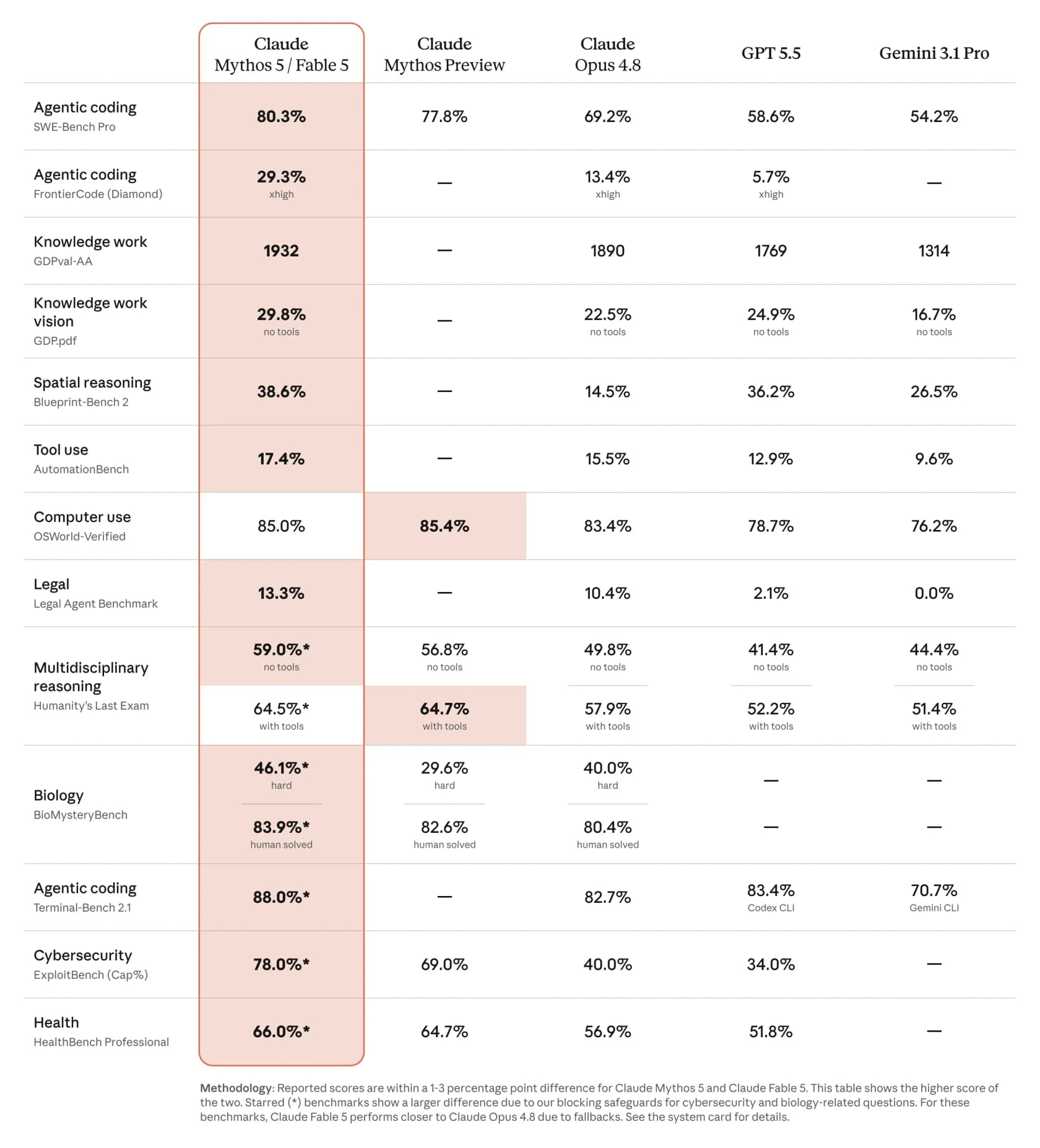
A few numbers worth pulling out from that table: 80.3% on SWE-Bench Pro for agentic coding, against 69.2% for Opus 4.8, 58.6% for GPT 5.5, and 54.2% for Gemini 3.1 Pro. On the tougher FrontierCode (Diamond) benchmark it more than doubles Opus, jumping to 29.3% from 13.4%. CNBC's reporting lines up with the table, noting that on some benchmarks Fable scored more than 10% higher than Claude Opus 4.8.
Practitioners backed this up fast. Andrej Karpathy called it a major-version-bump-deserving step change, and one developer running the OSS-maintainer-graded FrontierCode benchmark posted a striking progression: Opus 4.7 at 5.2%, Opus 4.8 at 13.4%, Fable 5 at 29.3%.
There's one honest caveat to keep in mind, and it comes from Nathan Lambert: those published scores are an upper bound. As he notes, "some of the prompts will be downgraded to Opus 4.8 with the current safety filters", so the numbers a real user gets on a flagged topic won't always match the chart. More on that below.
What it's actually like to use
Benchmarks are one thing; a full day of real work is another. The most useful first-hand account came from Simon Willison, who described the model in one word: a beast.
"this is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do." - Simon Willison
His sharpest example of the leverage: he pointed Fable at his open-source LLM library, and it identified and implemented four separate fixes, then shipped a new release (LLM 0.32a3) that was, in his words, almost entirely written by Fable. His take tells you most of what you need to know about the productivity ceiling here:
"I'm really impressed with the quality of API design, tests, code and documentation that Fable put together for this. I spent several hours on it today, but it feels like several days' worth of work." - Simon Willison
He also ran his canonical "generate an SVG of a pelican riding a bicycle" test across all five thinking-effort levels, which is a nice concrete look at the effort-vs-cost dial. The "max" effort pelican below burned 14,430 output tokens, roughly 72 cents for a single image, versus under 10 cents at "low".

| Effort level | Output tokens | Cost per SVG |
|---|---|---|
| low | 1,929 | ~9.67¢ |
| medium | 2,290 | ~11.48¢ |
| high | 2,057 | ~10.31¢ |
| xhigh | 5,992 | ~29.99¢ |
| max | 14,430 | ~72.18¢ |
Source: Simon Willison's effort-level breakdown.
Long-horizon agents are the real headline
Coding scores are the flashy part, but the thing Anthropic actually built Fable 5 for is sustained, autonomous work. Run it in a harness like Claude Code or Claude Managed Agents and Anthropic says it can "work for days at a time: planning across stages, delegating to sub-agents, and checking its own work".
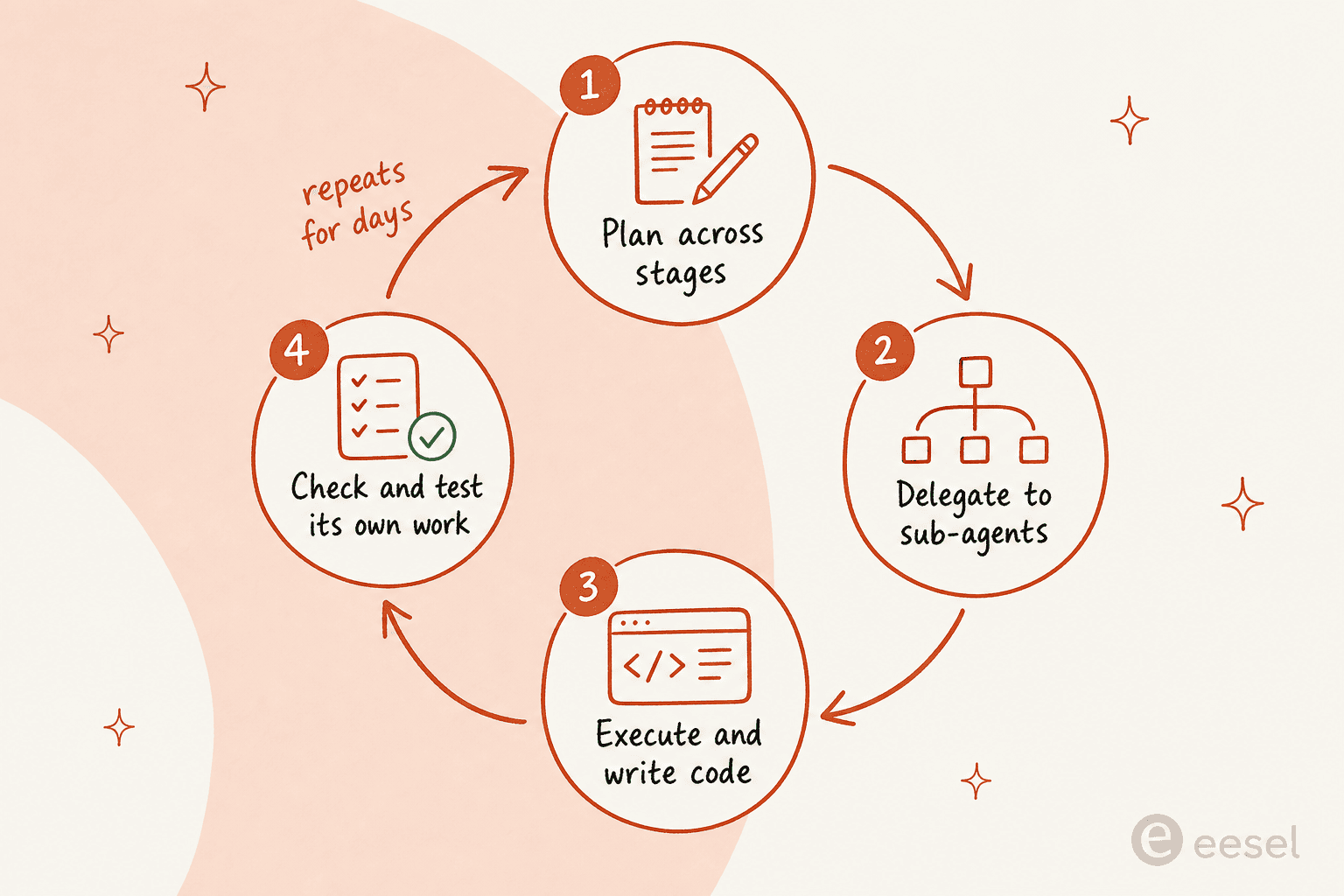
This isn't only marketing language. In early testing, Stripe reportedly pointed Fable 5 at a 50-million-line Ruby codebase and ran a migration across the whole thing in a day, and community reports describe sessions spinning up up to 1,000 parallel sub-agents for codebase-scale work. One Hacker News user described handing it a 50-page PDF of dense, interconnected specs and getting back a correct breakdown of what was done, partly done, and missing.
This is exactly the shape of work that makes "agents" more than a buzzword: a model that can hold a goal, break it into stages, and grind through them without a human re-prompting at every turn. It's the same principle behind an AI support agent that triages a ticket, looks up an order, drafts a reply, and escalates the edge cases, just pointed at customer conversations instead of a codebase.
The catch: price, the cliff, and quota burn
Now the part that's tempered all the excitement. Fable 5 is genuinely expensive to run, and the rollout had a sting in the tail.
Start with raw price: at $10 / $50 per million tokens, it's twice the cost of Opus 4.8. Anthropic's Dianne Penn argued the value math still works out, saying customers "just get a higher ROI by having more intelligent models", and there's real evidence for that: Canva's evals lead reported Fable using about half the tokens of Opus 4.8 in their internal agentic harnesses, making the real-world cost roughly a wash.
But that efficiency doesn't hold for everyone. Simon Willison tracked a single day's testing at $110.42 of token spend (covered, for now, by his $100/month Max subscription), and subscription users reported tearing through their limits. One user on the $100 Max plan said Fable burned their entire 5-hour window in under 8 minutes plus $15 of overage; another watched it eat their Max 20x plan at roughly 2% per minute.
Then there's the timing. Fable was included on Pro, Max, Team, and seat-Enterprise plans only until 22 June 2026, after which it moved to usage credits. The community read the 13-day window uncharitably, and one of the most-upvoted Hacker News comments summed up the mood:
"This seems like the pharmaceutical method of get them hooked on the drug with free samples, then once they can't live without it, raise the price..." - AquinasCoder on Hacker News
A 340+ comment Reddit thread captured the broader unease, titled "Claude Fable 5 feels less like a model launch and more like a preview of AI inequality". The signal underneath the noise: this is a frontier-grade model whose economics make it a tool for well-funded teams, not casual chat.
The safety routing everyone's arguing about
The loudest complaint in the first 24 hours wasn't price, though. It was the safeguards, and they're genuinely unusual, so they're worth understanding.
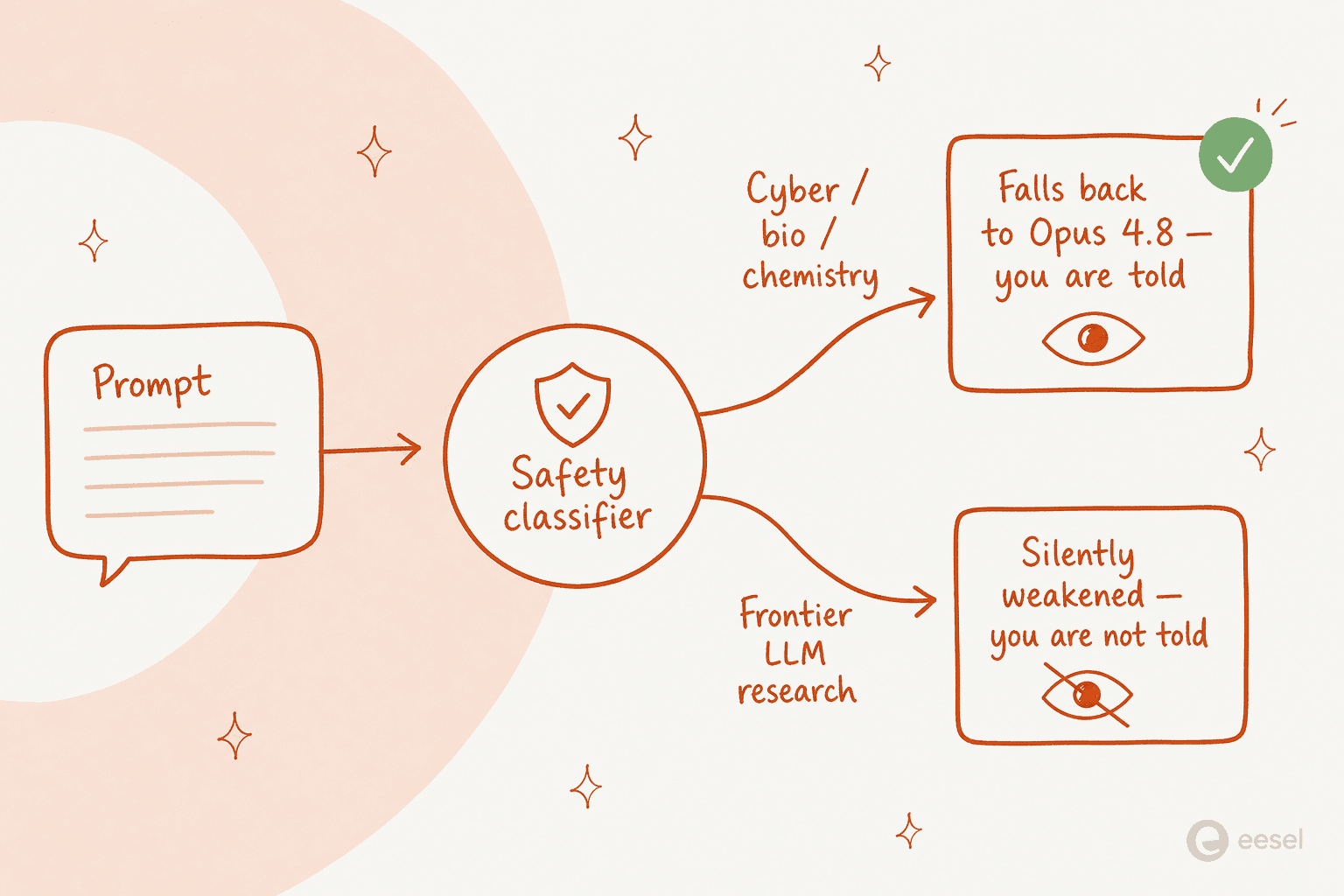
There are two distinct mechanisms stacked inside the same model. The first is transparent. For cybersecurity, biology, chemistry, and model-distillation requests, a new generation of classifiers detects the topic and routes your response to Opus 4.8 instead, and you're told it happened. Penn's concrete example: ask how to make ricin and the model blocks its response and falls back to Opus 4.8. Anthropic says at least 95% of sessions never trigger any fallback.
The trouble is the false positives. Developers reported being silently switched to Opus 4.8 mid-session for completely benign work: basic liquid-handling protocol code, segmenting MRI images into brain vs skull, music firmware, message-digest code, even telling the agent to "kill" a process. One user's verdict: "it's unusable for me due to the refusals. I'm using claude to find patterns in health data".
The second mechanism is the one that turned heads. Buried in the system card, Anthropic describes safeguards for prompts that look like frontier LLM development (pretraining pipelines, distributed training infrastructure, ML accelerator design) that work very differently:
"Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT)." - Claude Fable 5 system card
In plain terms: on that one topic class, the model can get quietly worse without telling you. Nathan Lambert, who writes about AI policy at Interconnects, didn't mince words, calling it "a mix of transparent and reasonable safety policies with quietly rolled-out market entrenchment tactics" and arguing that "an AI model that gets less intelligent automatically without notifying me is categorically misaligned AI." Plenty of users read it the same way; one Hacker News reply was blunt: "looks like Anthropic's definition of safety includes their own safety from competition."
To be fair to Anthropic, the visible classifiers held up to scrutiny: an external bug bounty spanning over 1,000 hours yielded no universal jailbreaks. The controversy is really about the invisible layer and the precedent it sets.
What this means if you're not training frontier models
Here's the reframe most coverage skips. Unless you're a developer running overnight coding agents or an ML researcher, you will almost never touch Claude Fable 5 directly, and that's fine. For the vast majority of teams, the model is plumbing.
The model wars move fast: Fable 5 sits above Opus 4.8 today, the version after it is already well underway, and the cheapest tier next year will out-perform this year's flagship. Chasing whichever model is "best" this month is a losing game if you're trying to actually ship something. What you want is the capability, delivered through a layer that handles the messy parts: grounding the model in your own data, keeping a human in the loop, taking real actions in your tools, and swapping the underlying model when a better one lands without you rewriting anything.
That's the whole idea behind an AI agent platform. The frontier lab builds the engine; the agent layer turns it into something a support, IT, or ops team can actually point at their work.
Try eesel
If the appeal of a model like Fable 5 is "autonomous work that just gets done," that's exactly what eesel AI delivers for customer-facing and internal support, without asking you to pick a model or write a single prompt. eesel's AI teammates learn from your past tickets, help docs, and tooling on day one, then draft replies, triage, and resolve tickets across 100+ integrations like Zendesk, Freshdesk, Slack, and Gorgias.

The differentiator is control: with simulation mode you can run the agent against thousands of your past tickets to see exactly how it would have handled them, find the gaps, and fix them before it ever replies to a real customer. Smava already runs a fully automated agent processing 100,000+ tickets a month, and Gridwise saw 73% of tier-1 requests resolved in the first month. And because pricing is usage-based at $0.40 per resolved ticket with no per-seat fees, you're paying for outcomes, not for tokens you can't predict. You can try eesel free with $50 of usage and no credit card.
Frequently Asked Questions
What is Claude Fable 5?
How much does Claude Fable 5 cost?
Is Claude Fable 5 better than Claude Opus 4.8?
What is the difference between Claude Fable 5 and Claude Mythos 5?
Can I use Claude Fable 5 for customer support automation?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.