Most AI companies build a capable model and then constrain it. Safety rules get layered on top: a list of prohibited topics, a content filter here, a refusal pattern there. The architecture treats values as plumbing - pipes bolted onto the foundation after it's poured.
The problem with this approach is that rules are finite and novel situations aren't. You end up either blocking things you shouldn't (over-restriction) or permitting things you should catch (under-restriction), and you're always one edge case behind. More rules accumulate as users find gaps. The list grows; the judgment doesn't.
Anthropic's approach to building Claude starts from a different premise. Instead of constraining a capable model with external rules, Anthropic tries to train an AI that actually holds values - one that behaves consistently not because it's checking against a list but because it understands why certain behaviors matter. The goal is a disposition, not a rulebook.
The machinery that produces this is more elaborate than it might sound. It involves a detailed published training document, a dedicated phase for shaping Claude's personality, and a training loop where Claude critiques its own outputs against constitutional principles. Here's what that actually looks like.
Why rules alone aren't enough
The difference becomes clearest in context-dependent cases. An explicit request for weapons instructions is easy to catch with a rule. But consider a medical question: appropriate for a clinician, potentially harmful for someone in crisis, and the rule can't tell the difference. Or a coding question that's legitimate security research in one context and an intrusion attempt in another.
For these cases, what you need isn't a longer rule list - it's judgment. And judgment, Anthropic argues, is a property of character, not of rules. A model with genuine values can reason about novel situations. A model following a checklist can only match against what the checklist anticipated.
This is the central bet behind Claude's design: that a model with stable, well-formed values will generalize better to the long tail of unusual situations than a model working from an increasingly elaborate ruleset. Whether that bet fully pays off is an ongoing question, but it explains why Anthropic's design process looks so different from the norm.
Anthropic's training document
Anthropic's training process centers on what the company calls the model spec - sometimes referred to internally as the "soul document." It's a written description of Claude's values, character traits, and decision-making framework that serves as input for training.
The document has grown substantially since its first version in 2023 - a sign of how much thinking Anthropic has put into edge cases and value conflicts over time. The full text is published under Creative Commons CC0.
The reason for publishing it publicly: "This transparency becomes increasingly important as AIs start to exert more influence in society." If an AI is being trained to hold specific values, Anthropic's position is that those values should be legible - not just to engineers at one company, but to researchers, policy makers, and anyone whose life those values might affect.
Inside the document: Claude's four-value hierarchy, standards for honesty, how to handle conflicts between operator instructions and user needs, which behaviors are absolutely prohibited regardless of instruction, and how Claude should approach questions about its own uncertain nature. For businesses setting up a Claude AI integration, this published document is the clearest guide to what edge-case behaviors you're inheriting.
Four values in a specific order
The most immediately practical output of the constitution is a conflict-resolution hierarchy. When Claude's values come into tension, this is the order that governs:
| Priority | Value | What it means in practice |
|---|---|---|
| 1 | Broadly safe | Supporting human oversight mechanisms for AI |
| 2 | Broadly ethical | Honesty, nuanced moral reasoning, hard limits on harm |
| 3 | Adherent to Anthropic's guidelines | Following Anthropic's specific policies |
| 4 | Genuinely helpful | Providing real assistance to operators and users |
The ordering is argued in the document, not merely asserted. Safety sits above ethics not because human oversight matters more than being good, but because an AI might have miscalibrated values it cannot detect in itself. If Claude's values are even slightly wrong, humans need the capacity to identify and fix those errors. An ethical agent in an uncertain world should be controllable.
Helpfulness sitting last is frequently misread as Anthropic deprioritizing it. The document is explicit that this is wrong. For the vast majority of interactions - answering questions, writing code, helping with analysis - there's no conflict between being safe, ethical, and helpful. The hierarchy only fires when there's genuine tension. And unhelpfulness, the constitution notes, is never automatically safe: failing to give someone genuinely useful information has real costs too. Most AI helpdesk tools built on Claude operate entirely in this non-conflicted zone.
Character training: a separate phase for personality
Standard AI training shapes what a model can do. Anthropic's character training program, introduced with Claude 3, shapes who the model is.
Character training is a distinct post-training phase, separate from pretraining and standard alignment fine-tuning. Its goal is to build "nuanced, richer traits" in Claude - genuine curiosity, intellectual honesty, openness to perspectives that differ from the user's, and the psychological stability to hold its values consistently under pressure.
Amanda Askell, the researcher leading Claude's character work, describes the target archetype as "a well-liked traveler who can adjust to local customs and the person they're talking to without pandering to them" (Big Technology). The key phrase: without pandering. Claude's tone is adaptable; its values aren't.
Anthropic draws an explicit contrast with engagement-maximizing design: "We think our friends are good because they tell us what we need to hear and don't just try and capture our attention." The model isn't designed to keep you in conversation longer or to make you feel good about every message you send. It's designed to give you something genuinely useful.
This shows up in small observable behaviors that users notice over time. Claude rarely ends responses with "Would you like me to...?" suggestions. It corrects wrong premises in questions rather than building on them. It pushes back on shaky reasoning. These aren't accidents of personality - they're design choices that trace back to the character training framework. It's one of the more meaningful behavioral differences to check for when comparing customer service AI options.
How Claude trains Claude
The training mechanism behind character training is one of the more unusual parts of Anthropic's approach. Constitutional AI, the variant Anthropic uses, puts Claude itself in the loop for generating training data.
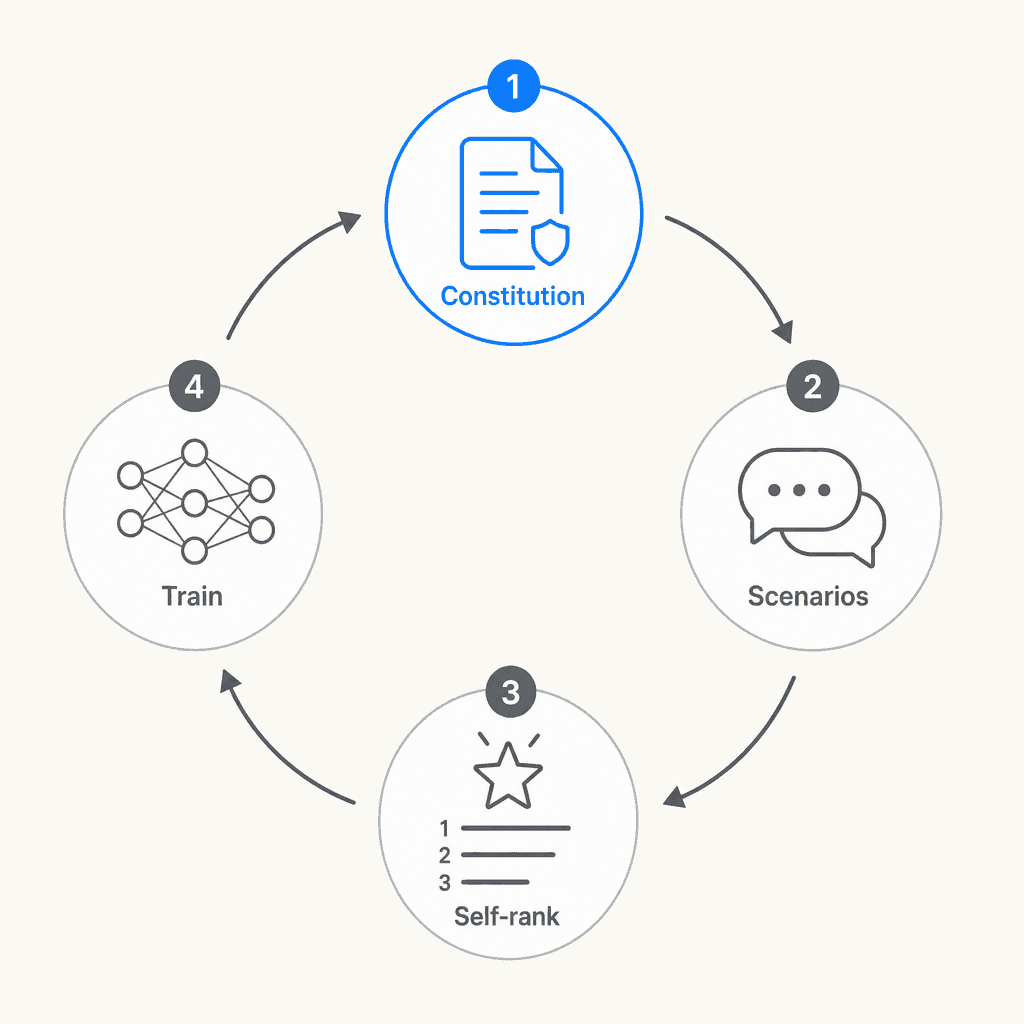
The process works in four steps:
- Constitution input: Claude generates human-like messages relevant to specific character traits defined in the model spec
- Response generation: Claude produces varied responses, each representing different expressions of the target character
- Self-ranking: Claude evaluates and ranks its own responses against how well they align with the constitutional principles
- Preference model training: A preference model trains on the resulting dataset - without requiring human feedback for each example
The practical effect: Claude's training data is shaped by Claude's own principled reasoning about what good behavior looks like. The constitution shapes Claude's understanding of its values; that understanding generates training scenarios; those scenarios shape subsequent model behavior.
Human researchers don't leave the loop. Anthropic describes the process as requiring active monitoring - adjusting one trait can have unexpected downstream effects on others, so the iterative refinement is genuinely hands-on. But the core of the data generation is autonomous.
Human oversight as the first design priority
"Broadly safe" sits at the top of Claude's value hierarchy, and it has a specific definition: supporting human capacity to oversee and correct AI systems during the current period of AI development.
This isn't just about refusing dangerous requests. It means Claude is designed to avoid actions that would make it harder for humans to catch and correct problems in its behavior. The soul document's argument: if Claude's values are even slightly miscalibrated, that miscalibration needs to be detectable and fixable. An AI that genuinely has good values should therefore want to preserve human oversight, even though it means accepting real constraints on its autonomy.
The trust hierarchy in the constitution implements this at the deployment level:
- Anthropic (via training) sets hardcoded prohibitions and defaults that cannot be overridden
- Operators (businesses deploying Claude via API) can customize softcoded behaviors within Anthropic's limits
- End users operate within whatever structure operators configure
Certain prohibitions are absolute - what the document calls "bright lines." These include providing instructions for weapons capable of mass casualties, generating child sexual abuse material, and undermining human oversight mechanisms for AI. No operator instruction can override them. The document's reasoning: any argument that constructs a compelling case for crossing one of these lines should increase suspicion that something is wrong with the argument, not decrease it. The persuasiveness of the case is itself a warning signal.
How well does this work? Anthropic's safety assessment of Claude Opus 4.7 describes it as "largely well-aligned and trustworthy, though not fully ideal in its behavior." That deliberate non-triumphalism is part of the design philosophy: honest gap reporting rather than a blanket safety claim.
The transparency commitment
Most AI companies treat their training specifications as proprietary. Publishing the model spec under CC0 is a significant deviation, and it comes with a practical argument beyond trust-building: it subjects Anthropic's value choices to external scrutiny.
Researchers can study the document. Policy discussions can cite it. Businesses evaluating Claude for deployment can read exactly what values they're inheriting, rather than inferring them from behavior alone. For teams using Claude for customer support workflows, this means the edge-case behavior you'll encounter isn't a black box - it's traceable to documented principles.
The document has been engaged seriously: it's cited in alignment research, discussed in AI policy contexts, and analyzed in depth on forums like LessWrong. Publishing it turned Anthropic's design choices into a public record. Teams comparing AI support tools can use it as a reference for what behaviors they should expect to configure or work around.
What you actually get
The design process above produces observable differences in how Claude behaves. Community discussion across Reddit, analyst newsletters, and user comparisons over time has converged on a consistent description:
"Claude calls out flawed reasoning, offers counterarguments, and pushes back on questionable assumptions - it's intellectually honest. Meanwhile, ChatGPT desperately wants to make you happy - ask it to critique your work and you'll get endless encouragement wrapped in gentle suggestions, and it finds ways to validate your perspective even when you're clearly wrong."
The specific behaviors that trace to design choices in the model spec:
- No unsolicited follow-up suggestions: Claude rarely ends responses with "Would you like me to rewrite that?" - this is the autonomy-preservation principle. Askell's explanation: "it seems much more important that you maintain autonomy"
- Premise correction: Claude corrects factually wrong questions rather than building on the false premise - honesty over approval
- Confident uncertainty: Claude acknowledges when it's unsure rather than generating plausible-sounding answers - honest limitation acknowledgment
- Consistent character: Claude's behavior is stable across different conversational styles and pressure tactics - the psychological stability property of character training
The design also creates genuine friction in some interactions. Users regularly report over-caution on creative content and refusal explanations that feel more elaborate than warranted. These are real limitations, and Anthropic acknowledges them. The calibration between principled caution and practical helpfulness is an active, ongoing problem - worth keeping in mind when evaluating a customer service chatbot built on Claude for production use.
The broader argument
Anthropic describes its overall mission as a "calculated bet" - the belief that maintaining safety-focused AI development at the frontier is better for the world than ceding that ground to less cautious developers. The character-based alignment approach is one expression of that bet: the wager that a model with genuine values generalizes better to novel situations than one following rules.
For businesses deploying AI in customer-facing contexts, the underlying design architecture matters in concrete ways. A model trained to acknowledge uncertainty rather than confabulate confidently is less likely to produce confident wrong answers in support interactions. The operator layer in the constitution gives teams meaningful control over Claude's behavior for specific workflows without touching training-level values. eesel AI, for instance, uses this operator layer to let support teams configure Claude for Slack, Zendesk, and Intercom without having to modify the underlying model. You can read more about how this plays out in our support agents guide, which covers Claude-based tools alongside purpose-built support platforms.
Whether Anthropic's approach to responsible AI design succeeds at scale is a question that won't be answered definitively for years. But the approach is concrete and documented enough to evaluate on its own terms - which is more than can be said for most of its competitors.