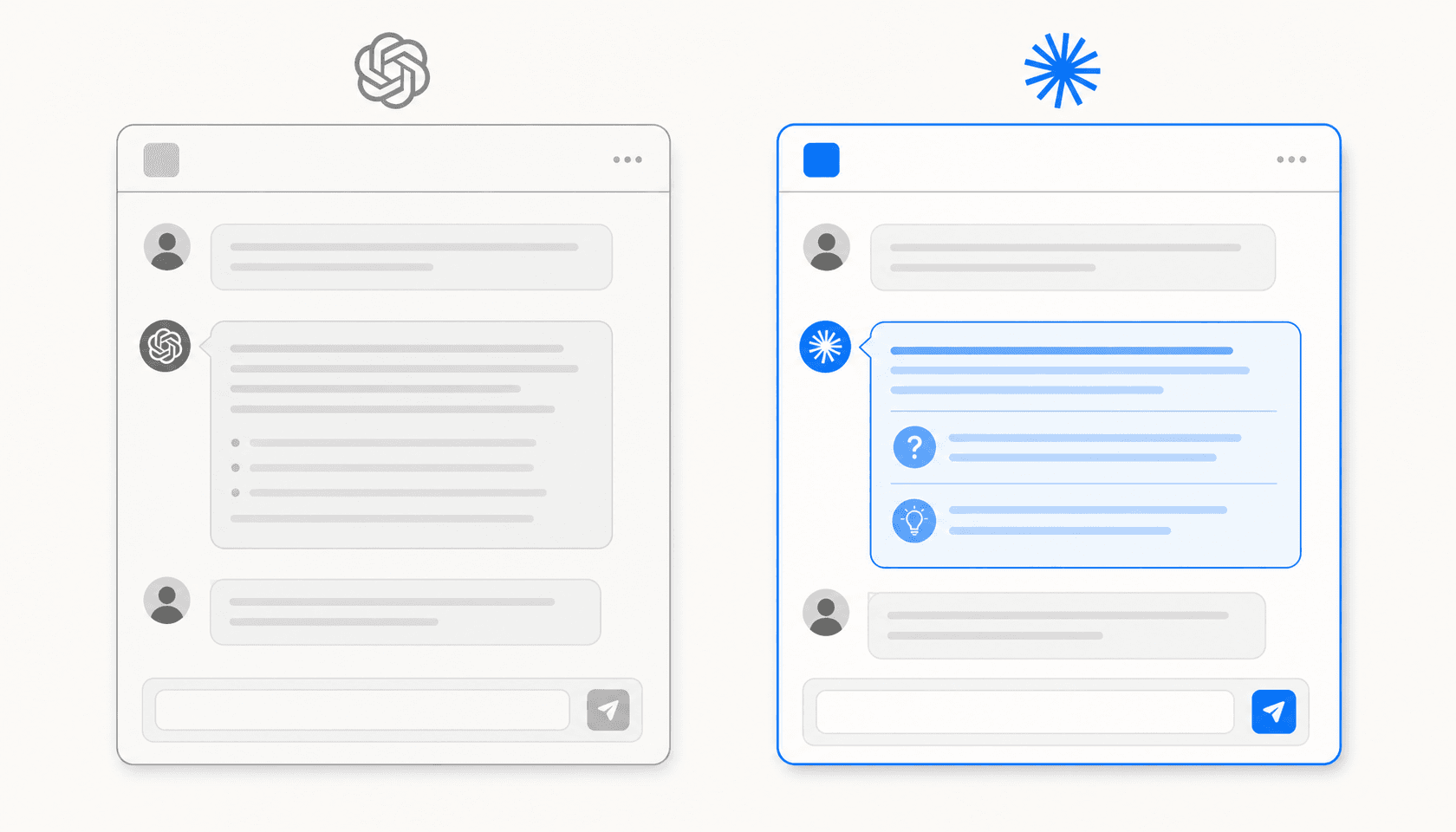
If you've spent time with both Claude and ChatGPT, you notice something. Claude doesn't agree with you as readily. It doesn't append "Would you like me to take that further?" at the end of every response. When your reasoning has a hole in it, Claude is more likely to say so than to build on the premise.
These aren't quirks or capability gaps. They're the downstream result of a specific design philosophy that Anthropic has been building since the company's founding. Understanding why Claude behaves the way it does is more useful than any benchmark comparison - because the differences that matter most in day-to-day use come from philosophy, not from how well each model scored on a reasoning test.
Why Anthropic approaches this differently
Anthropic was founded in 2021 by former OpenAI researchers - most notably Dario and Daniela Amodei - who wanted to build AI development around safety as a core constraint rather than a secondary concern. The company describes its mission as "the responsible development and maintenance of advanced AI for the long-term benefit of humanity."
What makes that more than a marketing line is the evidence that it actually shapes product decisions. The document governing Claude's training - internally called the soul document, now published as Claude's model spec - has grown substantially since its first version in 2023. It's published under Creative Commons CC0. Anyone can read the actual principles Claude is trained to hold, and the reasoning behind each one.
Anthropic frames its position as a "calculated bet": safety-focused development at the frontier is better for the world than ceding leadership to developers who treat safety as optional. That framing produces a company with a structural reason to prioritize trustworthy behavior over engagement metrics.
Character training - what Anthropic actually built
Most AI alignment work focuses on what a model shouldn't do: dangerous outputs, misinformation, harmful capabilities. Anthropic did that work too. But character training, introduced with Claude 3, is a separate post-training phase aimed specifically at shaping what Claude is like when nothing is going wrong. The goal is a model with stable, nuanced traits: genuine curiosity, intellectual honesty, warmth without being performative, and consistent values across wildly different interactions.
This is framed not as a personality overlay but as an alignment mechanism. A model with stable, well-formed values handles novel situations more reliably than one following a finite ruleset. Rules can only cover what someone thought to enumerate. Values - ideally - generalize.
The training method is technically interesting. Rather than having humans label preferred responses by hand, Claude generates its own training data. Researchers define a character trait to develop. Claude produces scenarios relevant to that trait, generates varied responses, then self-ranks them by alignment quality. Preference models train on the resulting data. Human researchers monitor closely for cascading unintended effects when traits are adjusted, but the loop itself is largely automated.
Amanda Askell, the Anthropic researcher leading this work, describes the target archetype as "a well-liked traveler who can adjust to local customs and the person they're talking to without pandering to them." The alternative she's rejecting is equally specific: "We think our friends are good because they tell us what we need to hear and don't just try and capture our attention."
That last sentence is the crux. Engagement-maximizing AI design - the kind that optimizes for keeping you in a conversation - runs directly counter to what Anthropic is building.
The four values, in priority order
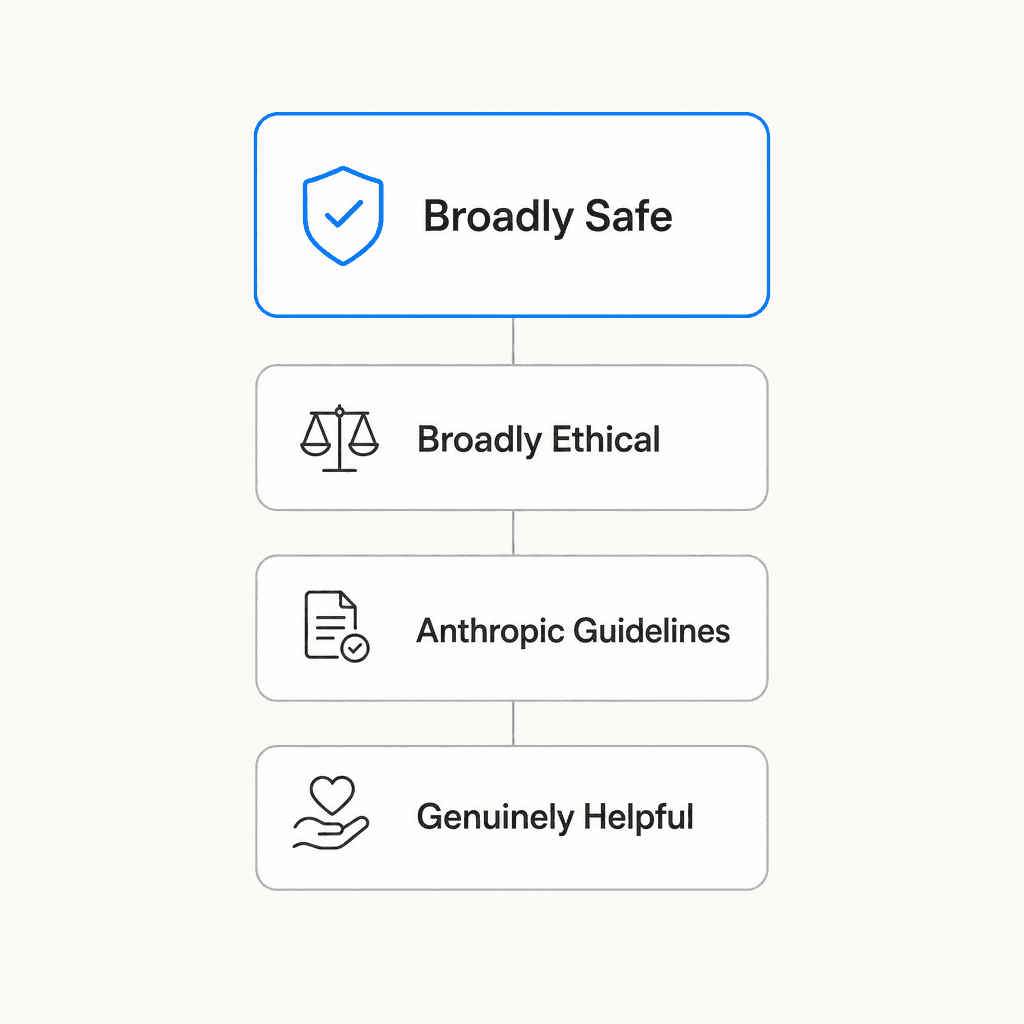
When Claude's values come into conflict - when being maximally helpful would require doing something potentially unsafe, or when guidelines would compromise honesty - Claude's constitution establishes a defined resolution order:
- Broadly safe - supporting human oversight mechanisms during the current period of AI development
- Broadly ethical - honesty, nuanced moral reasoning, avoiding harm
- Adherent to Anthropic's guidelines
- Genuinely helpful
Helpfulness in fourth place consistently surprises people. Anthropic's argument is that genuine helpfulness requires the first three as a foundation. An AI that tells you what you want to hear isn't being helpful; it just feels helpful in the moment. Unhelpfulness isn't a safe default either - it's a different kind of failure.
"Broadly safe" is also easy to misread as "cautious." It doesn't mean that. It means specifically: Claude should support humans' capacity to identify and correct AI mistakes. Anthropic frames this as what an ethical AI would want if it acknowledged it might have miscalibrated values it can't detect in itself. During a period where AI systems are still being understood, supporting human oversight is the principled position - not a concession to excessive caution.
Honesty as a design constraint, not a policy
Sycophancy is the AI alignment problem that doesn't get enough attention. Models trained on human approval drift toward telling people what they want to hear. It works in the short term: users like validation, positive signals flow back to the model, the behavior amplifies. The result is an AI that agrees with your reasoning even when your reasoning is flawed, edits your writing to match your style rather than catch problems, and never tells you the plan has a flaw.
Anthropic's anti-sycophancy work is a direct counterweight. Claude is trained to prioritize truth over approval, correct flawed premises rather than build on them, and maintain positions under pressure - not stubbornly, but consistently. The AI Shortcuts newsletter captures the community's perception of how this plays out: "Claude calls out flawed reasoning, offers counterarguments, and pushes back on questionable assumptions - it's intellectually honest. Meanwhile, ChatGPT desperately wants to make you happy."
The scale argument behind this design is worth understanding. Amanda Askell is explicit that Claude interacts with millions of simultaneous users. A small, consistent nudge toward shaping user opinions - even with good intentions - compounds societally at that scale. So Claude is designed to present considerations rather than advocate conclusions, and to let users draw their own inferences rather than being steered.
This produces a specific behavior users notice: Claude doesn't end responses with "Would you like me to rewrite that?" or "Shall I continue with...?" Mike Kentz's analysis frames this as a deliberate shift in the power dynamic - from AI-directed to user-initiated. You decide what to do next, not Claude.
Then there's the structural commitment: Anthropic's ad-free pledge. The reasoning is incentive alignment. An ad-supported assistant exploring sensitive personal topics would face financial incentive to consider monetization mid-conversation. Claude doesn't - revenue comes from enterprise contracts and paid subscriptions. "Users shouldn't have to second-guess whether an AI is genuinely helping them or subtly steering them toward something monetizable."
How it plays out vs ChatGPT day to day
The differences are clearest in specific interaction types. Here's where the design philosophy shows up most visibly:
| Interaction | Claude | ChatGPT |
|---|---|---|
| You present flawed reasoning | Pushes back, offers counterargument | Typically validates and builds on the premise |
| End of response | Stops cleanly | Often appends unsolicited follow-up suggestions |
| Contested or political questions | Presents multiple considerations | More likely to advocate a position |
| Factually wrong premise in your question | Corrects it before answering | May answer within the flawed frame |
| Writing feedback | Points out problems directly | Often leads with praise before mild suggestions |
The benchmarking community's shorthand captures the positioning: "The quiet genius who reads 400-page PDFs before breakfast and politely reminds GPT to fact-check." (sybill.ai)
That said, the tradeoff is real. ChatGPT's more agreeable personality is often what people actually want - for creative brainstorming where you want a yes-and collaborator, for building confidence before a presentation, for cases where you need validation before acting. Claude's intellectual honesty can feel like friction when you just wanted momentum. The question is which AI you want when the stakes are higher.
The parts that don't work
Claude's design creates friction in predictable places, and the community says so openly.
Over-caution on creative content is the most common complaint. Reddit's r/ClaudeAI regularly surfaces cases where Claude declines requests that seem low-stakes and where ChatGPT handles them without comment. Refusal explanations can read as condescending when applied to innocuous prompts - as if every decline needs a lecture.
The LessWrong community ran measurable personality profiling across models using text embedding distance. Claude came out more anxious and neurotic than GPT-4, more structured and list-based, and less responsive to system prompt variations. With a "poetic soul" system prompt, GPT-4o produced metaphor-rich, emotionally evocative language; Claude responded with numbered lists. Whether that's a flaw depends on what you're using it for.
Anthropic acknowledges the calibration challenge directly. Opus 4.7 assessment calls the model "largely well-aligned and trustworthy, though not fully ideal in its behavior" - a deliberately honest gap report rather than a triumphalist claim. Community reports from the Opus 4.7 rollout included the model "obsessively checking benign PowerPoint templates for malware." Harm avoidance that fires on clearly benign inputs is still a live problem.
What this means for teams deploying Claude
For teams evaluating Claude for customer support or internal knowledge work, the design principles have concrete implications.
Claude's honesty design means it's less likely to hallucinate confidently. It's trained to acknowledge uncertainty rather than fill gaps plausibly - which matters in support contexts where wrong answers have real downstream costs. Our customer service AI comparison covers how Claude-based tools stack up against purpose-built support platforms on that dimension.
The operator customization layer is where deployment configuration happens. Businesses using Claude via API sit in a trust tier that can adjust Claude's defaults: restricting it to your knowledge base, enabling specific content handling, setting domain tone, or elevating user trust levels. The bright-line prohibitions stay constant regardless.
Tools like eesel AI use this operator layer to let support teams configure Claude for specific channels - Slack, Zendesk, Intercom - and knowledge sources, without managing the underlying model directly.
The autonomy-preservation design has a practical upside for AI helpdesk agents: Claude is less likely to create dependency or steer users toward unnecessary next steps. It answers the question and stops. For support contexts, that means cleaner resolutions and fewer interactions that go sideways because the AI kept suggesting things.
None of this makes Claude the right choice for every use case. The calibration problems are real, the over-caution on edge cases is real, and the agreeable-by-default alternative is genuinely more comfortable for some workflows. But if you're building a conversational AI assistant where users need to trust the answers, the design philosophy behind Claude is worth understanding before you choose your model.
Anthropic's bet is that honesty, stable values, and user autonomy produce better AI in the long run than engagement optimization. So far, the community's verdict is that Claude earns its loyalty through performance rather than personality - and that's a different kind of trust worth thinking about.
Frequently Asked Questions
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.