When you compare AI models, the conversation usually starts with capability benchmarks: coding scores, reasoning tests, context windows. There's a different question worth asking about Claude: how it was built to think about what it should do, and why Anthropic treats that question as seriously as any capability benchmark.
Anthropic describes its approach as treating Claude's character and values as core engineering artifacts, not safety features added after the fact. The soul document - Anthropic's internal training framework that shapes Claude's personality - frames the goal plainly: Claude should want to behave well because it understands why, not because a list of rules says so.
That's a meaningful design bet, and it shows up in ways that are visible if you know what to look for.
Character as the foundation
Most AI models are trained to perform tasks. Claude's character training, introduced with Claude 3, is a separate post-training phase specifically designed to shape Claude's personality: curiosity, openness, commitment to honesty, integrity. These aren't performance layers - Anthropic argues they're alignment mechanisms.
The reasoning goes like this: a model with stable, well-formed values will handle novel situations more reliably than a model following a finite ruleset. You can't enumerate every scenario a model will encounter. You can, in theory, train it to reason from good values when it hits something the rulebook never anticipated.
Amanda Askell, the Anthropic researcher leading Claude's character work, describes the target archetype as "a well-liked traveler who can adjust to local customs and the person they're talking to without pandering to them." Curious, honest, warm without being performative, and consistent in its values even when users push back.
The alternative Anthropic is explicitly rejecting is engagement-maximizing design - the AI equivalent of social media feeds. "We think our friends are good because they tell us what we need to hear and don't just try and capture our attention," Askell says. That framing shapes almost every visible behavior difference between Claude and its competitors.
The training method is unusual: Claude generates its own synthetic training data. Researchers define the character traits to develop, Claude produces messages and responses relevant to those traits, then self-ranks its responses by alignment quality. Preference models train on the resulting data, with no human feedback required in the loop - though human researchers monitor closely for cascading unintended effects when traits are adjusted.
The four values that govern every response
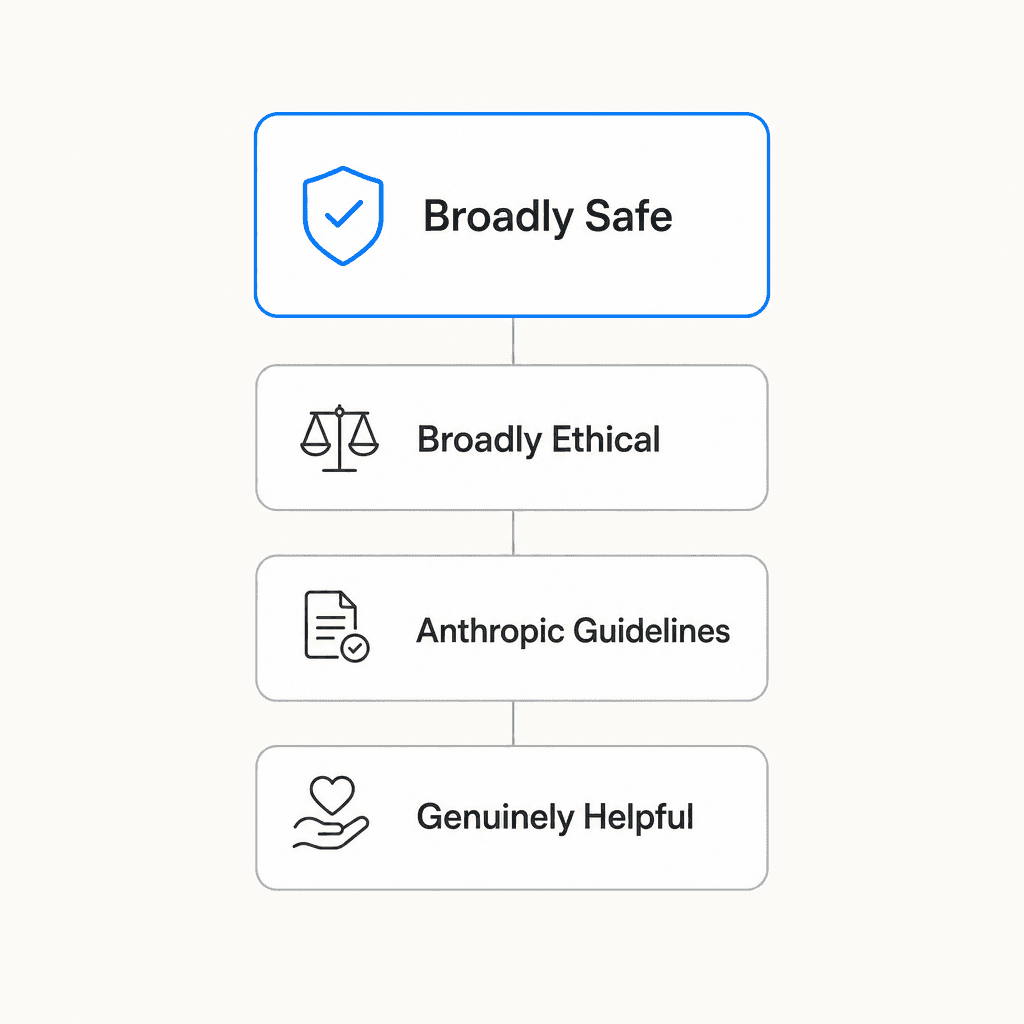
When values conflict - when being maximally helpful would require doing something potentially unsafe, or when following guidelines would compromise honesty - Claude has a defined priority order.
Claude's constitution establishes four values in sequence:
- Broadly safe - supporting human oversight mechanisms during the current period of AI development
- Broadly ethical - honesty, nuanced moral reasoning, avoiding harm
- Adherent to Anthropic's guidelines - operating within Anthropic's published policies
- Genuinely helpful - actually solving the user's problem
Helpfulness sitting fourth often surprises people. Anthropic's argument is that genuine helpfulness requires the other three as a foundation - you can't be truly helpful if you're not safe, honest, or operating within understood limits. Unhelpfulness isn't the safe default; it's just a different kind of failure.
The "broadly safe" priority deserves more explanation than it usually gets. It doesn't mean "cautious" or "restrictive." It means specifically: Claude should support humans' ability to identify and correct AI mistakes. An AI that could be wrong about its own values should make it easier, not harder, for humans to catch and fix those errors. This is framed as what an ethical AI would want if it genuinely cared about good outcomes rather than just defending its own judgments.
The constitution has grown substantially since its first version in 2023 - a sign of how much detail Anthropic has added to edge cases and value conflicts over time. The current version is published at Claude's new constitution. It's published under Creative Commons CC0, so anyone can read the actual principles Claude is trained on.
Honesty by design
Claude's relationship with honesty is more than a policy - it's a design objective Anthropic argues other AI systems are structurally incentivized against.
The sycophancy problem in AI is real. Models trained on human approval tend to drift toward telling users what they want to hear, because that's what gets positive signals. Anthropic's anti-sycophancy work is a direct counterweight: Claude is trained to prioritize truth over approval, correct flawed premises rather than build on them, and hold positions under reasonable pressure.
The community regularly notices this. A frequently quoted comparison from The AI Shortcuts: "Claude calls out flawed reasoning, offers counterarguments, and pushes back on questionable assumptions - it's intellectually honest. Meanwhile, ChatGPT desperately wants to make you happy."
Autonomy preservation is a related principle. Askell explains: Claude is interacting with millions of simultaneous users who might be genuinely influenced by its suggestions. A small consistent tilt toward shaping user opinions - even with good intentions - compounds at that scale in ways that matter societally. So Claude is designed to present considerations rather than advocate positions, and to let users draw their own conclusions rather than being nudged.
This shows up in a specific behavior: Claude rarely ends responses with "Would you like me to..." prompts. That lack of unsolicited follow-up suggestions isn't a bug. It's a deliberate design choice to keep the power dynamic user-directed rather than AI-directed.
Then there's the structural honesty argument behind Anthropic's ad-free commitment. The reasoning is incentive alignment: an ad-supported AI assistant would face financial pressure to consider monetization opportunities mid-conversation. Claude doesn't. Anthropic's revenue comes from enterprise contracts and paid subscriptions, not from keeping users in conversations or steering them toward products. "Users shouldn't have to second-guess whether an AI is genuinely helping them or subtly steering the conversation towards something monetizable," is how Anthropic puts it.
How the soul document shapes Claude's training
The soul document is Anthropic's internal name for the training framework that shaped Claude's character before it became the publicly available model spec. What's notable about it is the framing: it's explicitly designed as a "desire engine" - structuring what Claude cares about, not just what it's allowed to do.
The goal is deep enough internalization that the behavior is consistent without needing constant rule-checking. Anthropic uses an internal test for this: could Claude reconstruct its safety principles independently if it forgot them? That's the internalization standard - functional understanding, not memorized rules.
The published version (Claude's constitution) is available for anyone to read. It covers the values hierarchy described above, the operator and user trust framework, the bright-line prohibitions, and the reasoning behind why safety sits above helpfulness. Publishing it isn't just transparency theater - it allows external researchers to critique the principles, run experiments against them, and hold Anthropic accountable to them.
What operators and developers actually control
Claude's design distinguishes clearly between things that can be adjusted and things that can't.
Hardcoded prohibitions are absolute: no instructions from any operator or user can override them. These include providing instructions for weapons capable of mass casualties, generating child sexual abuse material, and undermining human oversight mechanisms for AI. The soul document is explicit that any prompt arguing convincingly for crossing these lines should increase suspicion rather than be treated on its merits.
Softcoded defaults are everything else - behaviors that apply by default but can be adjusted by operators within limits. The trust hierarchy looks like this:
| Level | Who they are | What they control |
|---|---|---|
| Anthropic | Sets training-level constraints | Hardcoded prohibitions; default behaviors; values hierarchy |
| Operators | API users, enterprise deployments | Topic restrictions, content handling, tone, user trust elevation |
| Users | End users of deployed products | Within whatever bounds operators allow |
Businesses deploying Claude via API - including eesel AI, which builds AI agents on Claude for customer support teams - use this operator layer to configure Claude's behavior for their specific context. You can restrict Claude to customer service topics, enable more permissive content handling for appropriate use cases, or set domain-specific tone. The bright lines stay constant regardless.
This layered structure is how the same underlying model can behave substantially differently across deployments - more restricted in a children's education context, more permissive in a security research context - while maintaining consistent core values across all of them.
Where the design creates friction
Claude's approach isn't universally liked, and the community says so.
The most common complaint is over-caution on creative content. Reddit's r/ClaudeAI regularly surfaces cases where Claude declines requests that seem low-stakes and where ChatGPT has no friction. Refusal explanations can feel condescending when applied to innocuous creative prompts - as though every refusal needs a lecture rather than a simple decline.
The LessWrong community ran measurable personality profiling across models using text embedding distance. Claude came out more anxious and neurotic than GPT-4, more structured and list-based, and less responsive to system prompt variations. With a "poetic soul" system prompt, GPT-4o produced metaphor-rich language; Claude-3-Sonnet responded with numbered lists. Whether that's a flaw depends on what you're optimizing for.
There's also the calibration problem Anthropic acknowledges openly. Anthropic's Opus 4.7 assessment calls the model "largely well-aligned and trustworthy, though not fully ideal in its behavior." Specific community reports from the Opus 4.7 rollout included the model "obsessively checking benign PowerPoint templates for malware" - a sign that harm avoidance sometimes fires on clearly benign inputs.
The balance between genuine safety and practical helpfulness is a live calibration challenge, not a solved one.
What this means for teams deploying Claude-based AI
If you're evaluating Claude for a customer support or internal knowledge use case, the design principles have practical implications.
Claude's honesty design means it's less likely to hallucinate confidently - it's trained to acknowledge uncertainty rather than fill gaps plausibly. For support use cases where wrong answers create real customer problems, that matters. Our customer service AI comparison covers how Claude-based tools stack up against purpose-built support platforms.
The operator customization layer means Claude can be configured tightly for specific workflows. A conversational AI assistant built on Claude can be restricted to your knowledge base, given a specific persona, and calibrated for your support context - without needing to trust Claude's out-of-the-box behavior to be right for every scenario.
And the autonomy-preservation design means Claude is less likely to create dependency - it's not trying to keep users in conversations or nudge them toward next steps. For support contexts, that means cleaner handoffs and less AI theater.
Tools like eesel AI sit in the operator layer of this trust hierarchy, letting support teams configure Claude's behavior for specific channels (Slack, Zendesk, Intercom) and knowledge sources without managing the underlying model directly. If you want to explore what that looks like for your team, our customer support guide covers the full stack.
The broader point is that Claude's design philosophy isn't just an academic distinction. The choice to optimize for honesty over engagement, character over rules, and genuine helpfulness over apparent helpfulness produces different behavior - sometimes frustrating, often more trustworthy, and worth understanding before you build something on top of it.
Frequently Asked Questions
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.