Claude Sonnet 5 pricing at a glance
Anthropic launched Claude Sonnet 5 on 30 June 2026 as the mid-tier ("Sonnet-class") model, and the headline it leads with is value: near-Opus quality on coding and agentic work at Sonnet cost. Here is the number everyone comes for.
| Period | Input / MTok | Output / MTok |
|---|---|---|
| Introductory (through 31 Aug 2026) | $2 | $10 |
| Standard (from 1 Sep 2026) | $3 | $15 |
The standard $3/$15 rate is identical to Sonnet 4.6 (and 4.5, and Sonnet 4 before it). Anthropic set the introductory discount deliberately, so that migrating to Sonnet 5 stays "roughly cost-neutral" while the discount is live, despite the new tokenizer. More on why that caveat matters below.
For context on where this sits, Sonnet 5 is the everyday default: it is the default model for Free and Pro plans on Claude.ai, and it is also available to Max, Team, and Enterprise users, plus Claude Code and Cowork. So for most people, "which Claude am I using" is now Sonnet 5 unless they switch.
The full Claude Sonnet 5 pricing table
The base rate is only the start. Prompt caching and batch processing change the real per-request math a lot, especially for a support workload that reuses the same knowledge base context on every ticket.
| Rate category | Intro (through 31 Aug 2026) | Standard (from 1 Sep 2026) |
|---|---|---|
| Base input | $2 / MTok | $3 / MTok |
| 5-minute cache write | $2.50 / MTok | $3.75 / MTok |
| 1-hour cache write | $4 / MTok | $6 / MTok |
| Cache hits & refreshes (read) | $0.20 / MTok | $0.30 / MTok |
| Output | $10 / MTok | $15 / MTok |
| Batch API input (50% off) | $1 / MTok | $1.50 / MTok |
| Batch API output (50% off) | $5 / MTok | $7.50 / MTok |
All figures are from Anthropic's own pricing docs. The cache multipliers are consistent across models: a 5-minute write is 1.25x the base input rate, a 1-hour write is 2x, and a cache read is 0.1x. Anthropic's product page cites "up to 90% cost savings with prompt caching and 50% cost savings with batch processing." A couple of modifiers stack on top: US-only inference (inference_geo: "us") adds a 1.1x multiplier on all token categories, and the full 1M-token window is billed at the standard per-token rate with no long-context surcharge.
How Sonnet 5 pricing compares across the Claude 5 family
The point of Sonnet 5 is the price-to-capability ratio, so it only makes sense next to the rest of the lineup. Here is where the standard rates land.
| Model | Input / MTok | Output / MTok | Context |
|---|---|---|---|
| Claude Fable 5 | $10 | $50 | 1M |
| Claude Mythos 5 | $10 | $50 | 1M |
| Claude Opus 4.8 | $5 | $25 | 1M |
| Claude Sonnet 5 | $3 ($2 intro) | $15 ($10 intro) | 1M |
| Claude Sonnet 4.6 | $3 | $15 | 1M |
| Claude Haiku 4.5 | $1 | $5 | 200K |
The reason the mid-tier price is interesting is that Sonnet 5's quality is not mid-tier. Anthropic's own benchmark table puts it a step below Opus 4.8 but a clear jump over Sonnet 4.6, at 40% of Opus's output price.
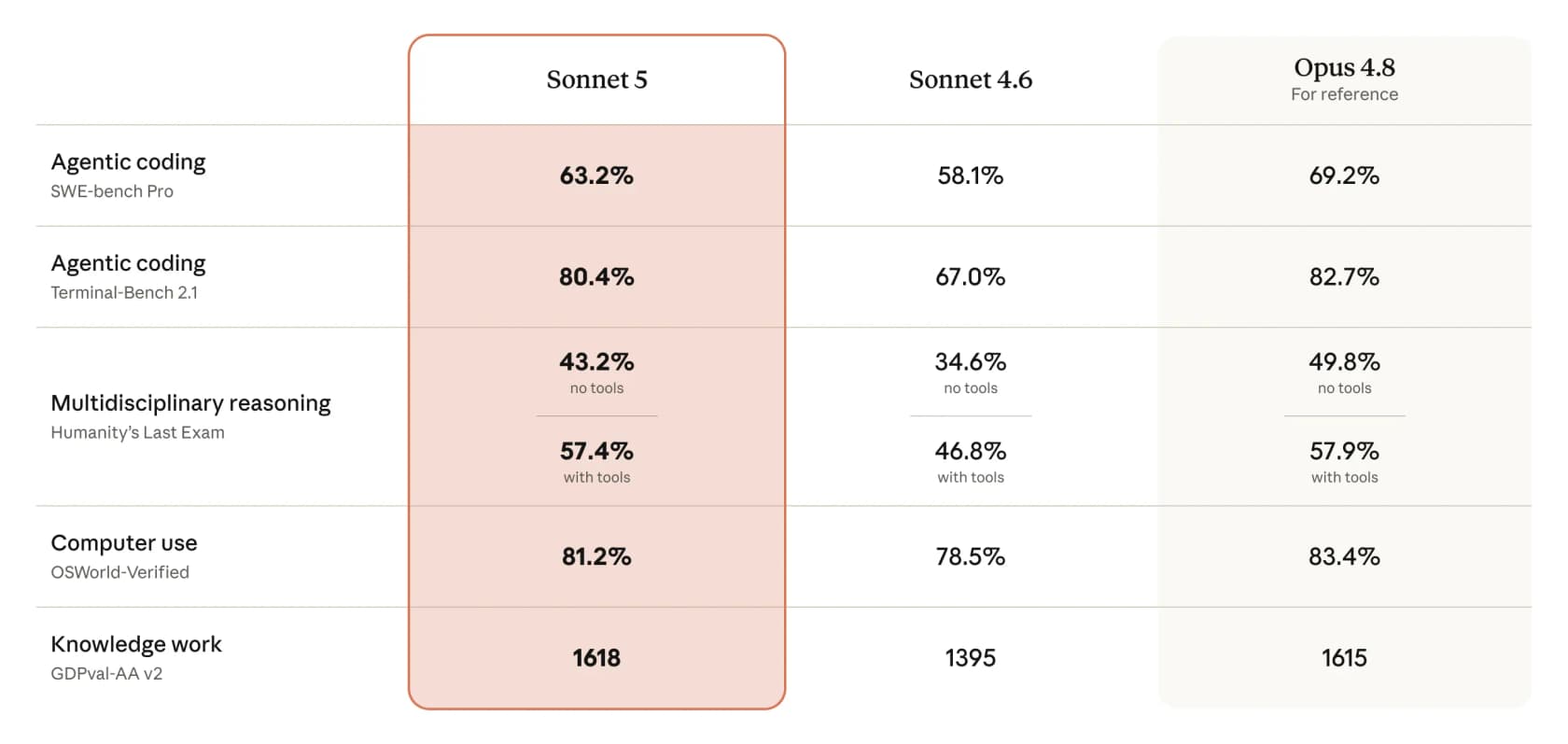
On SWE-bench Pro agentic coding, Sonnet 5 scores 63.2% versus Sonnet 4.6's 58.1% and Opus 4.8's 69.2%. On OSWorld-Verified computer use it hits 81.2%, within striking distance of Opus 4.8's 83.4%. Anthropic's framing is that Sonnet 5 "covers a much wider range of cost-performance options than Opus 4.8" and its higher-effort runs "can match Opus 4.8 on some tasks." That is the whole pitch: you dial effort up when you need it, and pay Sonnet rates the rest of the time.
The tokenizer catch: same price per token, bigger bill
Here is the line item most spend models miss. Sonnet 5 uses a new tokenizer (the same family introduced with Opus 4.7) that "produces approximately 30% more tokens for the same text." The launch post's footnote gives a finer range of roughly 1.0x to 1.35x depending on content type.
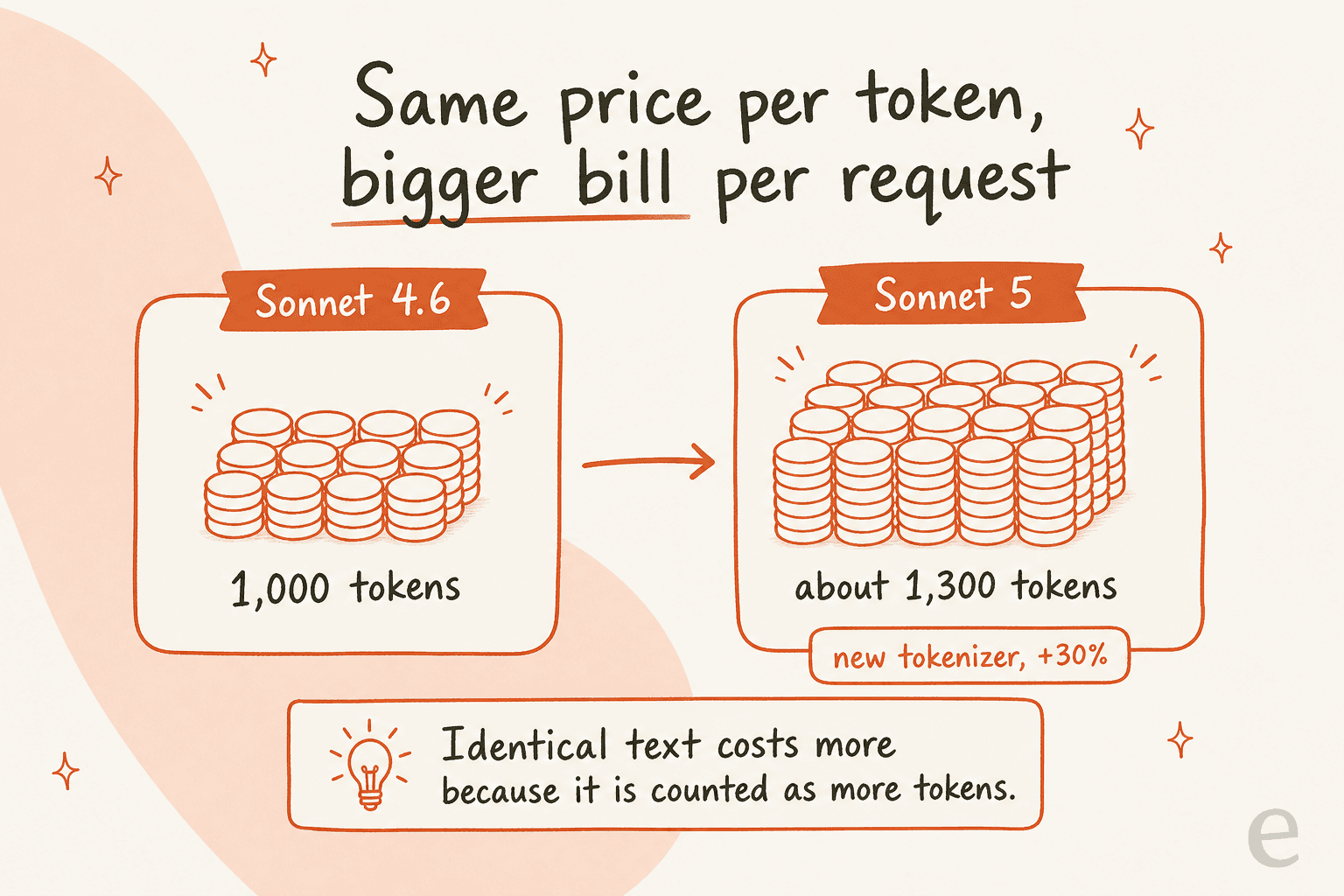
So the sticker price matches Sonnet 4.6, but per-token parity is not per-request parity. The exact same prompt and response get billed on more tokens. Anthropic designed the introductory discount to absorb this so the transition is "roughly cost-neutral" while it is active. Once standard pricing kicks in on 1 September 2026, that token inflation becomes a real cost increase per equivalent request versus Sonnet 4.6. If you are building a spend forecast, apply the ~1.0x to 1.35x token multiplier on top of the rate rather than comparing sticker $/MTok directly. This is exactly the kind of thing that quietly wrecks a naive cost-savings estimate.
The effort dial is your real cost lever
Sonnet 5's effort parameter (low / medium / high / xhigh / max) is the practical knob for cost. Higher effort means more thinking tokens, which means higher cost but higher capability. It defaults to high on the Claude API and Claude Code, and Sonnet 5 is the first Sonnet-tier model to get the new xhigh level.
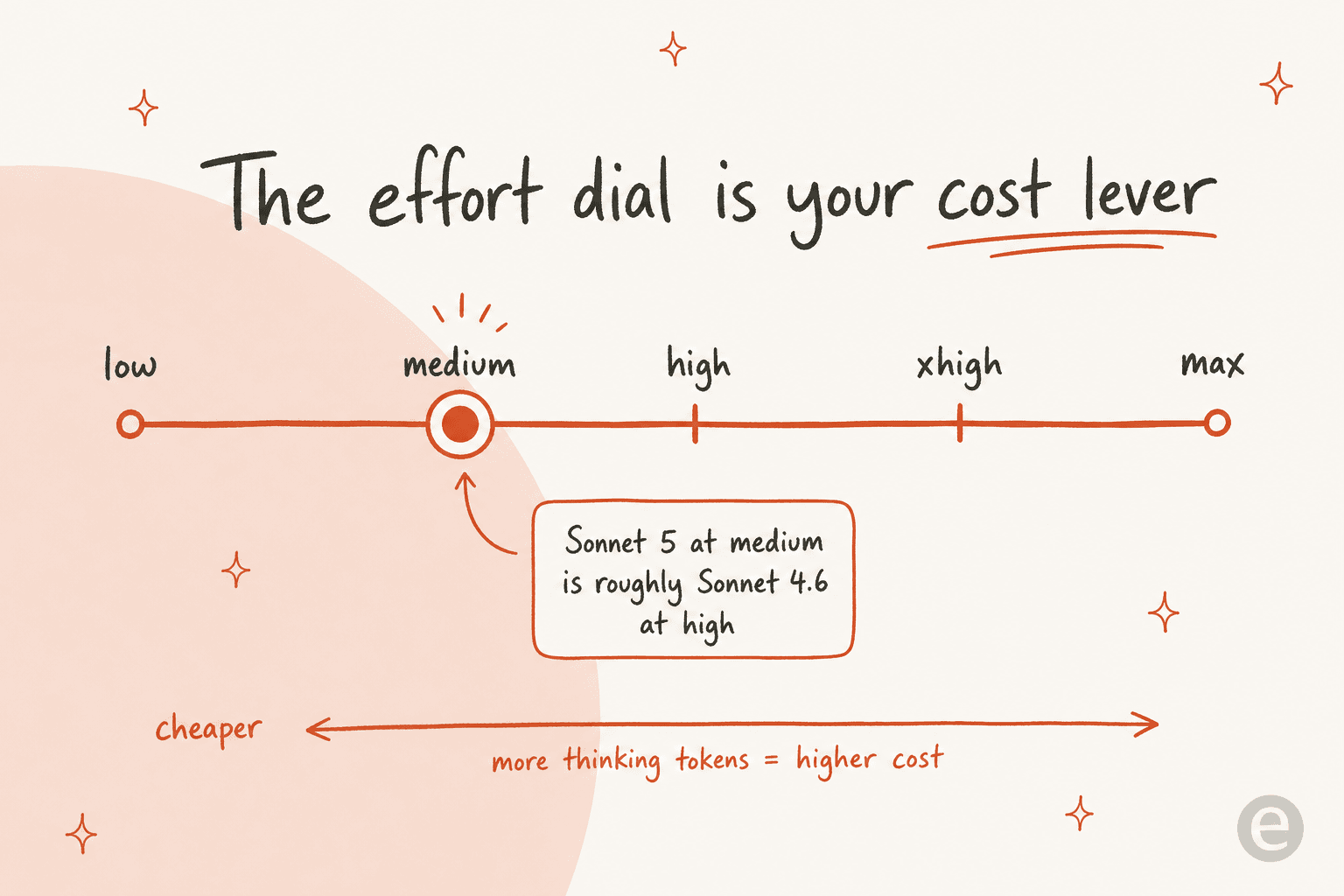
The efficiency mapping Anthropic gives is worth knowing before you set a default: Sonnet 5 at medium is roughly Sonnet 4.6 at high, and Sonnet 5 at high is roughly Sonnet 4.6 at max. In plain terms, you can often drop an effort level versus 4.6 and get the same result for fewer tokens. For a high-volume workload like automated ticket resolution, that dial is where your real monthly number is decided, not the headline rate. Anthropic even raised rate limits across Chat, Cowork, Claude Code, and the Platform specifically to accommodate higher-effort usage.
What Sonnet 5 actually costs per task
This is where the value story gets a useful argument attached to it. Anthropic and early boosters framed Sonnet 5 as "Opus-level work at Sonnet price," and on the sticker that is true. But the community pushed back fast, and the pushback is the genuinely useful part for a buyer.
Artificial Analysis, a named third-party benchmark aggregator, reported Sonnet 5 scoring 53 on its Intelligence Index and costing around $2.29 per task on that run, and noted that without the promotional pricing it can cost more per task than Opus 4.8 on that index, because higher-effort Sonnet 5 runs burn a lot of tokens.
Claude Sonnet 5 achieves 53 on the Artificial Analysis Intelligence Index, but without promotional pricing will cost more per task than Opus 4.8.
That is the same tokenizer-and-effort dynamic showing up in a real number. Not everyone agrees on the read, and named operators still like it for day-to-day work. Wade Foster, CEO of Zapier, put the practical case for it plainly.
Claude Sonnet 5 is live. It does Opus-level work at Sonnet-level pricing. Here's when to use it.
Both things are true, and the resolution is the effort dial. Run Sonnet 5 at low or medium effort and it is clearly cheaper per task than Opus 4.8 for most work. Crank it to xhigh or max on hard problems and the per-task cost can cross over. Verify the exact figures at the source before you cite them, but the shape of the trade is clear: sticker $/MTok is not the whole cost story, and for a cost comparison you need the tokens-per-task number too.
The pricing question that actually matters for support teams
Here is where I have to be blunt, because this is the mistake I watch teams make most. A cheaper, near-Opus model like Sonnet 5 makes "we'll just build our own support bot on the API" sound more tempting than it has in years. And the model really is cheap now. But the model was never the hard part.
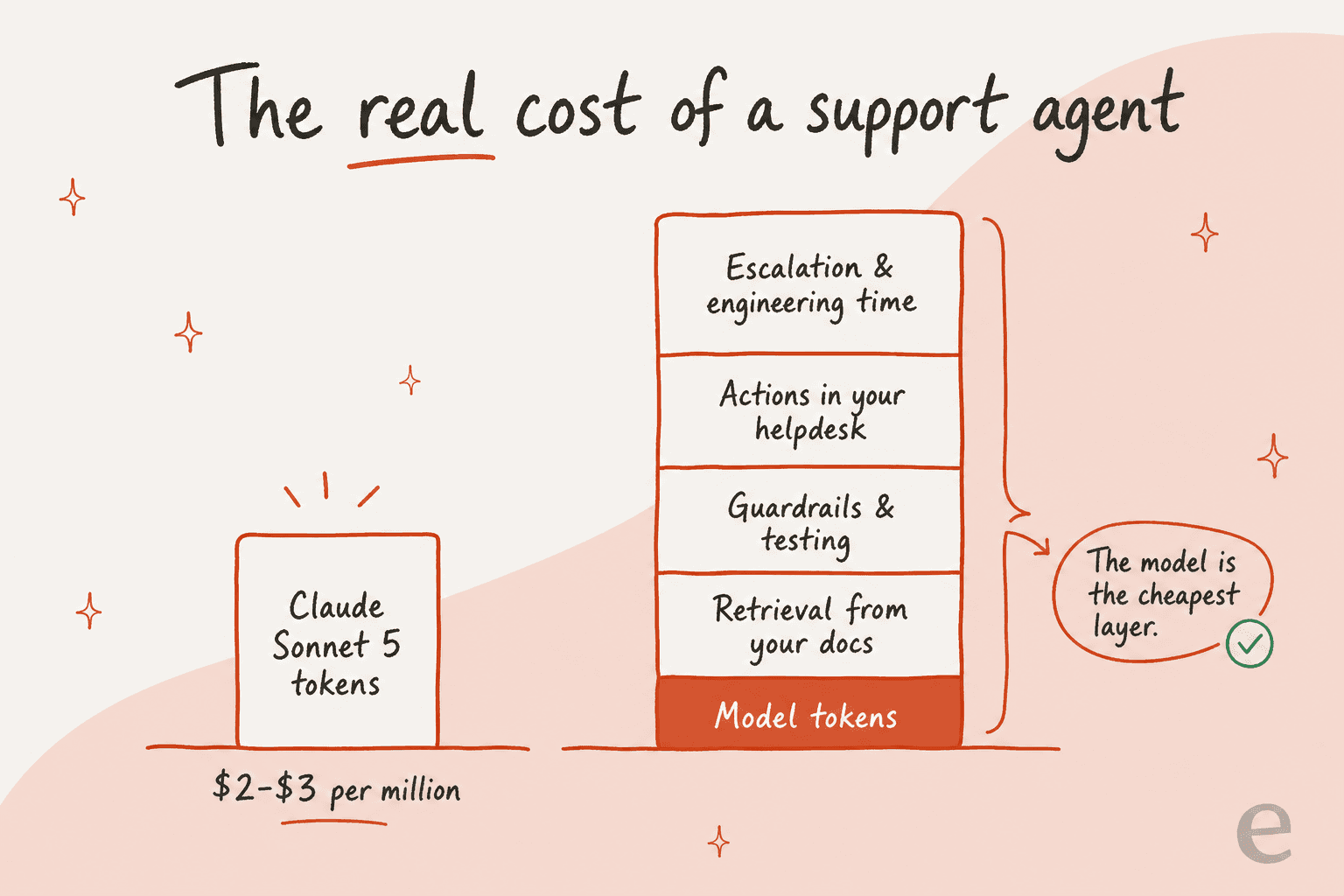
I have watched a confident-sounding bot quietly hand customers wrong answers, which is why every serious rollout now gets simulated against historical tickets before it ever touches a live queue. A support agent your customers can trust is retrieval over your docs and past tickets, confidence-based routing, real actions inside your helpdesk, clean escalation to humans, and testing. Sonnet 5 gives you a smart engine for pennies. It does not give you any of that 80%.
So the pricing question that matters is not "$2 or $3 per million tokens." It is the fully loaded cost per resolved ticket once you add the wrapper, and the engineering time to build and maintain it. That is the number that decides whether building beats buying, and it is almost always where the raw-API plan falls apart. If you want to sanity-check your own math, the guide on AI support agent cost and the ROI of AI customer service both work through it, and the wider AI for customer service roundup covers the buy side.
Try eesel
If you are pricing Sonnet 5 because you want an AI agent resolving tickets, eesel is the 80% the API rate does not include. It plugs into your existing helpdesk, learns from your past tickets and help center, and runs on usage-based pricing with no per-seat fees, so your cost tracks resolved tickets rather than a fixed license. The part I would flag most: before you go live, eesel simulates the agent against thousands of your real historical tickets so you see the resolution rate and the exact cost per ticket up front, instead of finding out in production.

It is free to try, and you can point it at your own docs in a few minutes to see what a real resolution rate looks like on your tickets, whichever Claude model runs underneath.