Why look past Claude Sonnet 5 at all?
Let me be fair to the incumbent first. Claude Sonnet 5 is very good. Anthropic launched it on 30 June 2026 as "our most agentic Sonnet yet," with a 1M-token context window, adaptive thinking on by default, and near-Opus quality on coding and agentic tasks at a mid-tier price. It's the day-one default across every Claude plan. For most people, it's a fine place to start.
So why shop around? A few real reasons keep coming up.
The first is cost math that isn't as clean as the sticker suggests. Sonnet 5 uses a new tokenizer that counts roughly 30% more tokens for the same text, so per-token price parity with the old Sonnet 4.6 doesn't mean per-request parity. And the value story has a genuine asterisk: Artificial Analysis measured Sonnet 5 at 53 on its Intelligence Index but noted that at standard, non-promotional pricing it can cost more per task than Opus 4.8, because higher-effort runs burn a lot of tokens. Artificial Analysis's own summary put it plainly:
"Claude Sonnet 5 achieves 53 on the Artificial Analysis Intelligence Index, but without promotional pricing will cost more per task than Opus 4.8."
The second is ecosystem lock-in. If your team already lives in Google Workspace or standardised on OpenAI, a same-quality model inside that ecosystem beats bolting on a second vendor. The third is open weights and data residency - some teams simply cannot send customer data to a US closed-API vendor, full stop. And the fourth is the plain reality that different models are just better at different jobs: Gemini is faster, the open-weight models are cheaper, and Opus and Fable go further on the hardest long-horizon work.
Here's roughly how the field sorts out once you plot it by cost and capability.
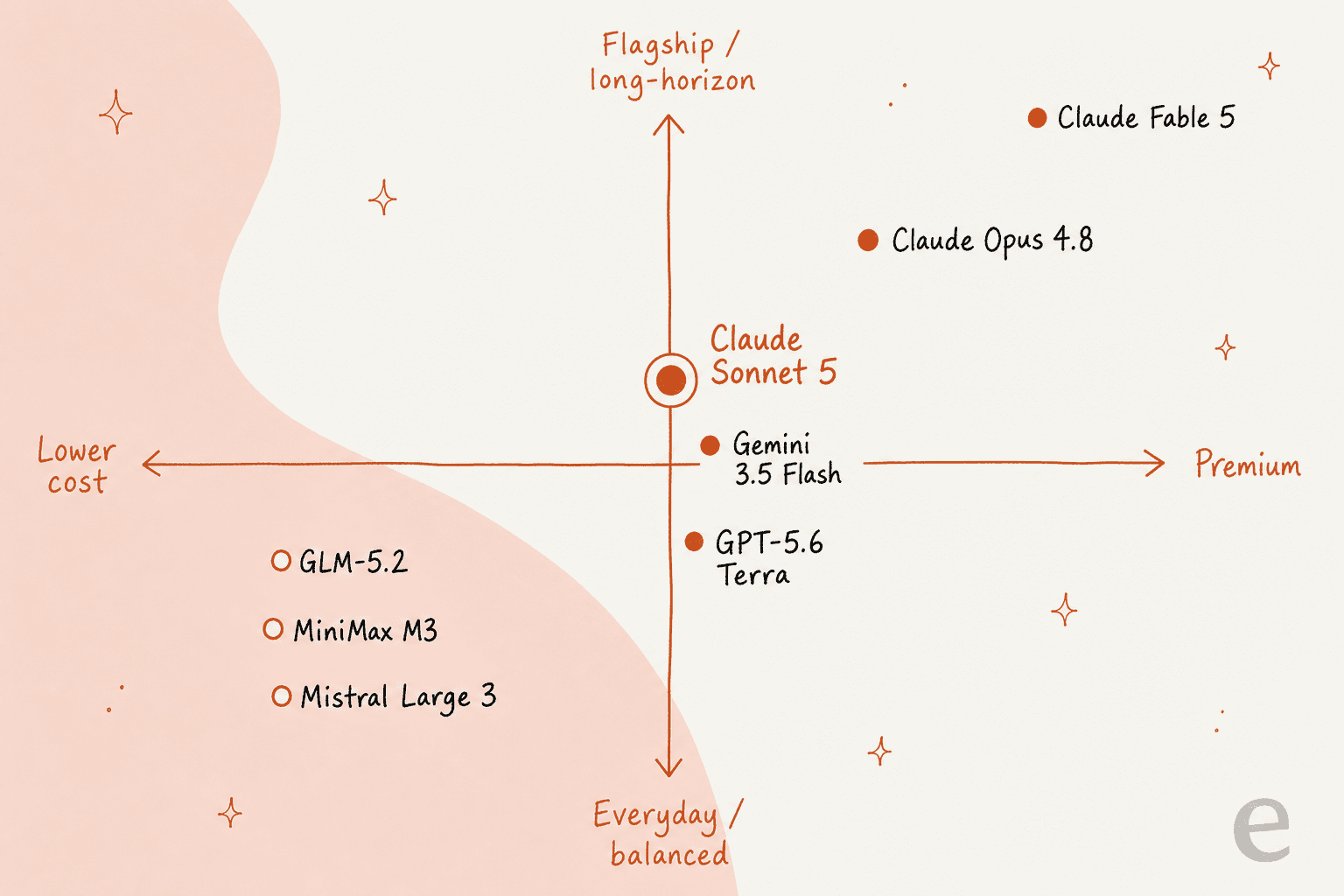
The alternatives at a glance
Before the deep dives, here's the whole field side by side. Prices are API rates per million tokens; "open weights" means you can download and self-host the model.
| Model | Best for | Access | Context window | API price (in / out) | Open weights |
|---|---|---|---|---|---|
| Claude Sonnet 5 (incumbent) | Balanced coding + agentic work | Closed API + Claude.ai | 1M | $3 / $15 ($2 / $10 intro) | No |
| GPT-5.6 (Terra) | OpenAI-native teams | API + Codex (preview) | Not yet disclosed | $2.50 / $15 | No |
| Gemini 3.5 Flash | Speed + Google ecosystem | API + Gemini app | 1M (Pro) / 128K (Flash) | $1.50 / $9 | No |
| Claude Opus 4.8 | A step up in the same family | Closed API + Claude.ai | 1M | $5 / $25 | No |
| Claude Fable 5 | Days-long autonomous agents | Closed API + Claude.ai | 1M | $10 / $50 | No |
| GLM-5.2 | Cheapest capable open model | Open weights + API | 1M | $1.40 / $4.40 | Yes (MIT) |
| Mistral Large 3 | EU data residency / self-host | Open weights + API | 256K | Open / varies | Yes |
| MiniMax M3 | Open-weight all-rounder | Open weights + API | 1M | Tiered (see below) | Yes |
A quick note on how I'd read this table: the "best for" column is doing more work than the price column. Almost every model here is capable enough for everyday coding and agentic tasks, so the deciding factor is usually your ecosystem, your data-residency rules, and whether you need to self-host, not a few dollars per million tokens.
If you want to shortcut straight to a pick, this little chooser walks the same logic I'd use.
1. GPT-5.6 (OpenAI)
Best for: teams already standardised on OpenAI who want the closest same-tier swap.
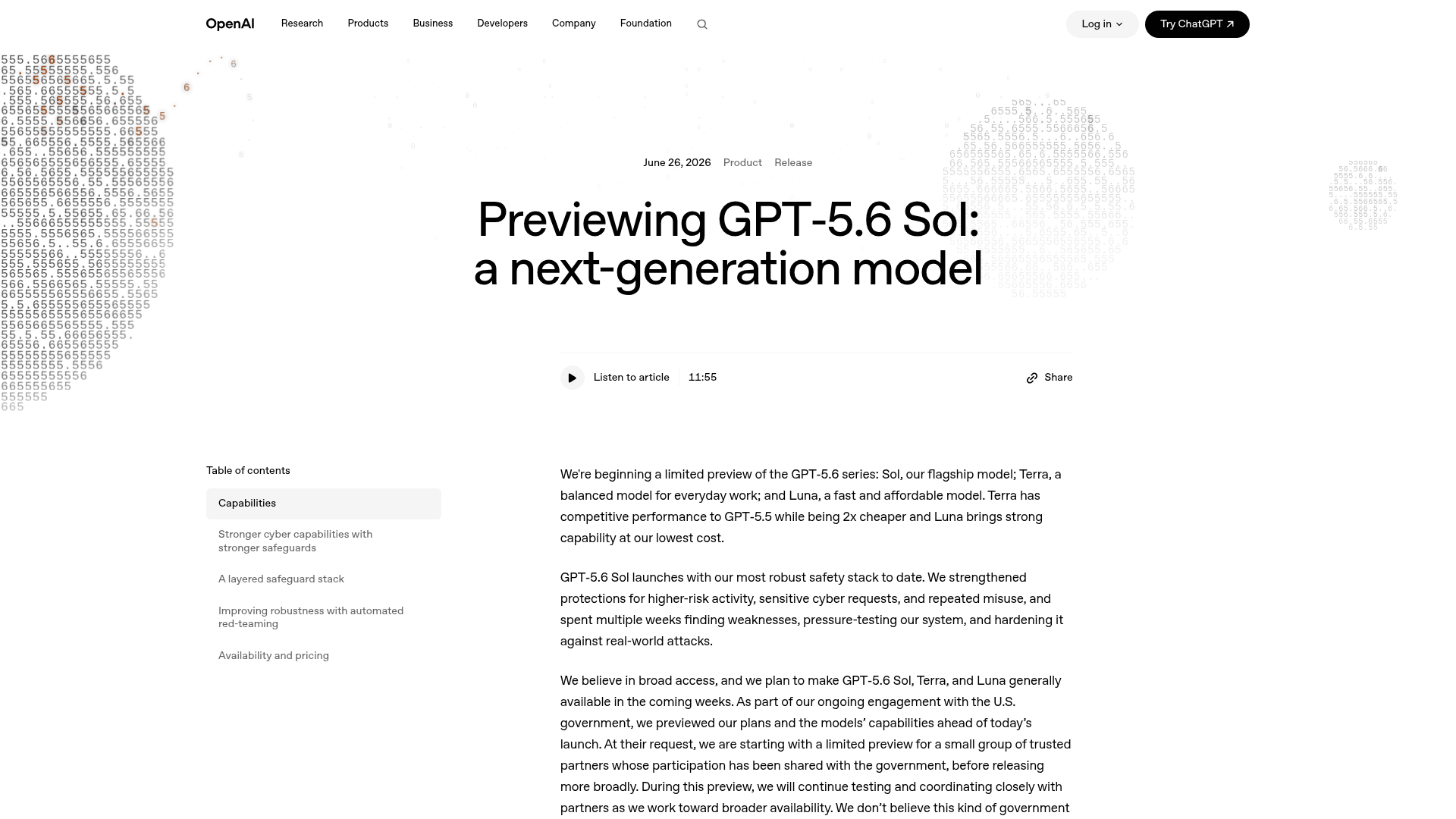
GPT-5.6 is OpenAI's next-generation family, previewed on 26 June 2026. The twist is that it isn't one model but three durable tiers: Sol (flagship), Terra (balanced), and Luna (fastest and cheapest). Terra is the one that maps most directly to Sonnet 5, at $2.50 input / $15 output per million tokens, with Luna undercutting everything at $1 / $6.
It also brings two new compute controls that echo Sonnet 5's effort dial: a max reasoning setting and an ultra multi-agent mode that spins up subagents. On OpenAI's own charts, Sol Ultra tops the Terminal-Bench 2.1 leaderboard at 91.9%.
The catch: during the preview, GPT-5.6 is reachable only via the API and Codex for a small set of vetted partners, not in ChatGPT, with no public waitlist. The gated, government-coordinated rollout is the loudest thing the community is talking about. So it's a real Sonnet 5 alternative on paper, but you may not be able to touch it yet.
Verdict: if you're OpenAI-native and can get preview access, Terra is the natural same-tier swap. If you can't, keep an eye on the GPT-5.6 review and check back at GA.
2. Google Gemini 3.5 Flash
Best for: teams that want raw speed and already live in the Google ecosystem.
Google Gemini's newest coding-and-agent model, Gemini 3.5 Flash, is the most direct speed-and-price rival to Sonnet 5. API pricing is $1.50 input / $9 output per million tokens, and it scores 76.2% on Terminal-bench 2.1 and 55.1% on SWE-Bench Pro on Google's own numbers. The headline users keep repeating is speed: one Reddit thread claims Gemini generates responses roughly twice as fast as Claude.
The real pull is the ecosystem. Gemini is baked into Search, Gmail, Docs, and Workspace, and it's natively multimodal with Imagen 4 images and Veo video. An applied-math student on Reddit summed up a common switch:
"As an applied math student, I've noticed Gemini is way better with math expressions. GPT makes dumb mistakes with operators and coefficients all the time."
The catch: the 1M-token context window is paid-only (the free tier's Flash runs a smaller window), and Gemini's own paying subscribers have been vocal about feature-parity bugs and context loss on long chats. For a support agent that needs to hold a long conversation, that memory wobble is worth testing before you commit.
Verdict: the best pick if speed and Google-native integration matter more than a few benchmark points. Fast, cheap, multimodal, with a slightly rougher edge on long-context reliability.
3. Claude Opus 4.8
Best for: when Sonnet 5's ceiling isn't quite enough and you want to stay in the same family.
The most under-rated "alternative" to Sonnet 5 is the model right above it. Claude Opus 4.8 is Anthropic's most capable Opus-tier model, released 28 May 2026, built for complex reasoning and long-horizon agentic coding. It runs the same 1M-token window at $5 / $25 per million tokens. Anthropic's own framing is that Sonnet 5's performance is "close to that of Opus 4.8, but at lower prices," so the honest read is: Sonnet 5 gets you most of the way, and Opus 4.8 is what you reach for on the hardest tasks.
One number worth flagging for anyone shipping code or customer-facing answers: Anthropic reports Opus 4.8 is around four times less likely than its predecessor to let flaws in its own code pass unremarked. That honesty improvement matters more for support than raw benchmark scores do.
The catch: it's genuinely pricier, and thanks to the tokenizer and effort dynamics, Sonnet 5 at high effort can occasionally cost as much per task anyway. It's a step up, not a free lunch.
Verdict: the cleanest upgrade path if you're already on Claude and just need more headroom. Same tooling, same API, more capability. See the Opus 4.8 for business breakdown for the full picture.
4. Claude Fable 5
Best for: days-long, autonomous agent runs that previous models couldn't sustain.
If Opus is a step up, Claude Fable 5 is the whole staircase. Launched 9 June 2026 as Anthropic's flagship "Mythos-class" model, it's built for days-long, complex, asynchronous tasks at $10 / $50 per million tokens, exactly double Opus 4.8. Stripe reportedly pointed it at a 50-million-line Ruby codebase and ran a migration across the whole thing in a day.
The most honest gauge of its power comes from Simon Willison, who tracked a full day of hands-on testing at $110.42 of token spend and called it "something of a beast. It's slow, expensive."
The catch: two, actually. Cost and quota burn are brutal - one user maxed a 5-hour limit in 20 minutes running 1,000 subagents. And there's a real trust wrinkle: Fable's safeguards can silently route flagged prompts to Opus 4.8 without telling you, which is not what you want in a predictable production pipeline.
Verdict: overkill for most Sonnet 5 use cases, and wildly so for support. Reach for it only when the task truly needs a model that can plan and self-check across hours.
5. GLM-5.2 (Z.ai)
Best for: the cheapest properly capable model, if you're comfortable with open weights.
This is the one that makes the value argument hardest to ignore. GLM-5.2 is Z.ai's flagship open-weights model, released 16 June 2026 under an unrestricted MIT license, with a stable 1M-token context window purpose-built for long-horizon coding. API pricing is $1.40 input / $4.40 output per million tokens - roughly one-sixth the cost of the closed frontier models.
And it isn't a toy. GLM-5.2 is the first open-weights model to cross 80% on Terminal-Bench (81.0), lands within a few points of Opus 4.8 on several coding benchmarks, and reportedly took #1 on Design Arena at ELO 1360. Artificial Analysis called it the leading open-weights model on its index.
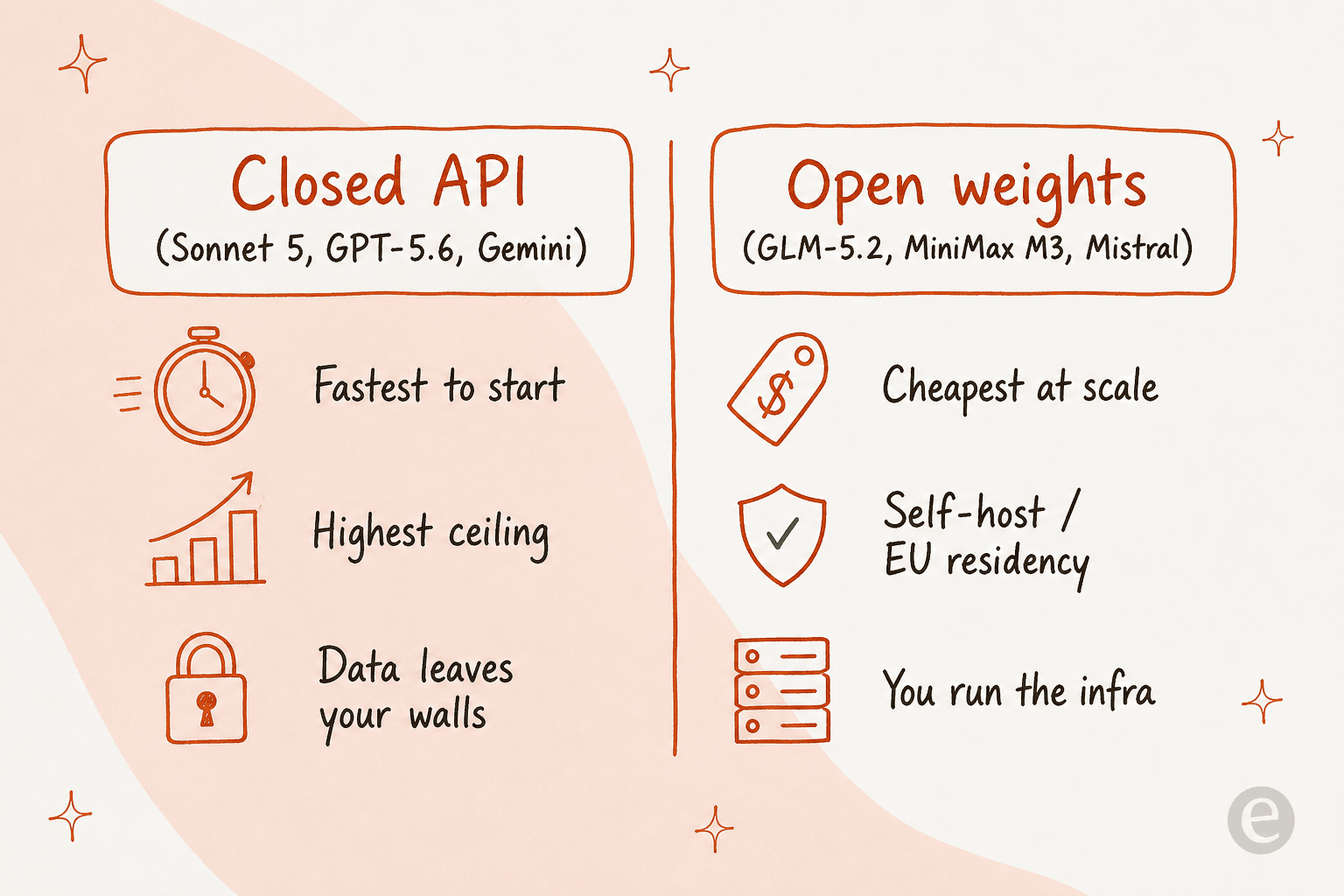
The catch: open weights mean you either self-host (and run the infra) or trust a non-US API vendor. Z.ai was added to the US Commerce Department Entity List in January 2025, which some enterprise buyers will care about a great deal and others not at all.
Verdict: the strongest value pick on this list. If your priority is cost-per-token and you can live with open-weight ops, GLM-5.2 is where I'd start. The GLM-5.2 for business rundown goes deeper.
6. Mistral Large 3
Best for: European teams and anyone who needs data to stay in-house or in-region.
Mistral AI is the European answer, and its pitch is "Frontier AI. In your hands." Mistral Large 3 is its open (675B-parameter, 41B active) flagship with a 256K context window, and the whole platform is built around self-hosted, EU-cloud, or major-cloud deployment. Its consumer and agent product, now rebranded from Le Chat to Vibe, leans on the same models. Named customers include AXA, Orange, BNP-adjacent finance, and the French Ministry of Defense.
The recurring praise from users is speed and the EU-privacy stance, with several explicitly willing to accept a capability trade-off "to keep the money in Europe."
The catch: the community is honest that the models trail the frontier on the hardest tasks. Reddit users call the large models "way, way behind Claude and ChatGPT for advanced stuff", and even positive G2 reviewers note it's "less refined than Claude." Consumer Trustpilot ratings sit around 2.3–2.5.
Verdict: the clear pick when data sovereignty is a hard requirement, not a nice-to-have. If it's not, one of the other options will likely give you more capability for the money.
7. MiniMax M3
Best for: an open-weight all-rounder that does coding, agents, and multimodal in one model.
MiniMax M3, released 1 June 2026, is a frontier coding and agentic model built on a novel sparse-attention architecture with a 1M-token context window. MiniMax's claim is that frontier coding, long context, and native multimodality "are now table stakes for closed-source frontier models," and that M3 is the first and only open-weight model to bring all three together.
Nicely for anyone evaluating a swap, M3 is callable through the Anthropic SDK (its recommended path) as well as the OpenAI SDK, and it's wired into Claude Code, Cursor, Cline, and most other coding harnesses. Its Token Plan runs $20, $50, and $120 per month for large monthly quotas, positioned as far more throughput per dollar than a comparable Claude subscription.
The catch: MiniMax doesn't publish exact per-token API rates on a primary page (they sit behind the billing UI), and pricing is tiered by input length above 512K tokens. So you'll need to model your own costs rather than quote a sticker.
Verdict: a strong open-weight all-rounder, especially if multimodal input matters. It's the most "batteries-included" of the open-weight options, though GLM-5.2 has the louder benchmark story.
The part that actually matters for customer support
Here's where I have to be straight with you, because I've watched teams make this mistake up close. If you're comparing Sonnet 5 alternatives to build customer support automation, you're optimising the easy 20%.
Every model on this list is smart enough to write a good support reply. What it isn't is a support agent. A support agent your customers can trust not to hallucinate needs retrieval from your docs and past tickets, confidence-based routing so it hands off when it's unsure, actions inside your helpdesk, clean escalation to humans, and - the step everyone skips - testing on real historical tickets before it goes live. The model is a component. The stack is the product.
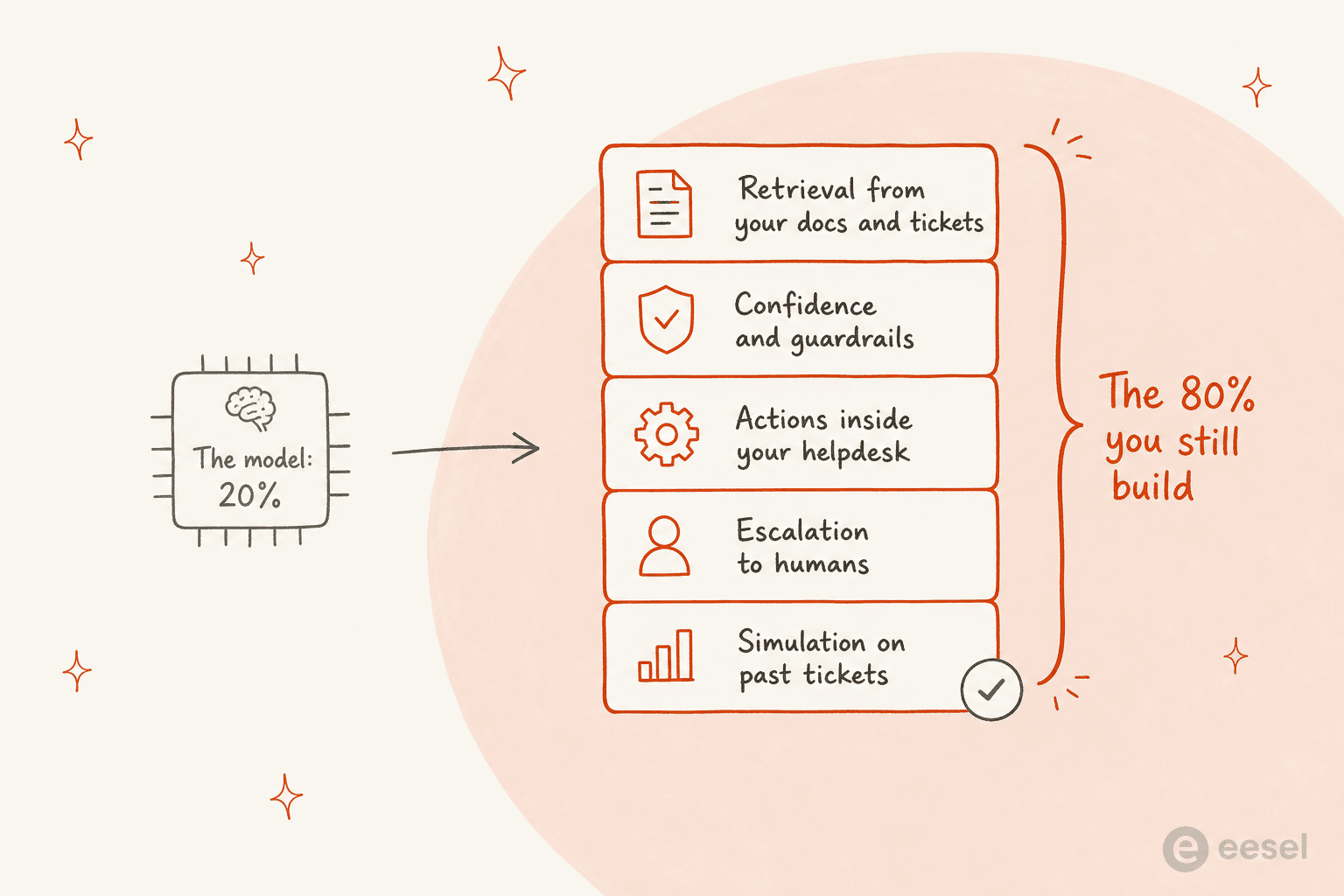
This is exactly why picking a model first is backwards for support. If you build directly on claude-sonnet-5 or GLM-5.2 or GPT-5.6, you end up rebuilding retrieval, guardrails, and evals by hand - and then you're locked to that model, so the day a cheaper or better alternative ships, you do it all again. The whole point of staying model-agnostic is that the model becomes a swappable part, not a foundation you pour concrete around.
Try eesel for AI support without betting on one model
If the reason you're comparing Claude Sonnet 5 alternatives is to put AI on your support queue, eesel is the layer that makes the model choice stop mattering. It plugs into your existing helpdesk, learns from your past tickets and docs, and stays model-agnostic underneath, so the frontier can keep leapfrogging itself without you re-architecting anything.
The differentiator I'd point to is the simulation mode: before a single reply reaches a customer, eesel replays your AI against thousands of your real historical tickets, so you see the resolution rate and the exact answers it would have sent. That's the test that separates a demo from something you'd trust on your live queue, and it's the same discipline we've leaned on running AI across thousands of real tickets for years. It's free to try, and it works like a new hire that already read your entire help center.

Whichever Claude Sonnet 5 alternative wins your benchmark, the work that earns customer trust lives around the model, not inside it. Pick the model that fits your budget and ecosystem, then put a real stack around it.