
What GLM-5.2 actually is
GLM-5.2 is the latest flagship model from Z.ai, the company formerly known as Zhipu AI, which spun out of Tsinghua University in 2019 and IPO'd in Hong Kong in January 2026. The short spec sheet:
- Open weights, MIT license. The weights are public on Hugging Face and ModelScope, with no regional restrictions. You can download and run it yourself.
- 753B parameters, ~40B active. It's a Mixture-of-Experts model, so only a slice of those parameters fire per token.
- 1M-token context. A 5x jump from GLM-5.1's 200K, and Z.ai stresses it's trained to stay reliable across long, messy coding-agent runs, not just nominally accept the tokens.
- Built for long-horizon work. The whole 5.2 release is pitched around autonomous coding and engineering tasks that run for hours, with a new effort-level control (
Maxfor peak quality,Highto roughly halve the output tokens).
In plain terms: it's a frontier-class coding model you can legally run on your own hardware. That combination is what's making people pay attention, because it hasn't really existed before at this quality, and it's reshaping how teams think about generative AI budgets.
The benchmarks, and what they tell a business
Z.ai's headline claim is that GLM-5.2 is the strongest open-source model on standard coding benchmarks, and the first open-weights model to cross 80% on Terminal-Bench. The numbers back the framing up.
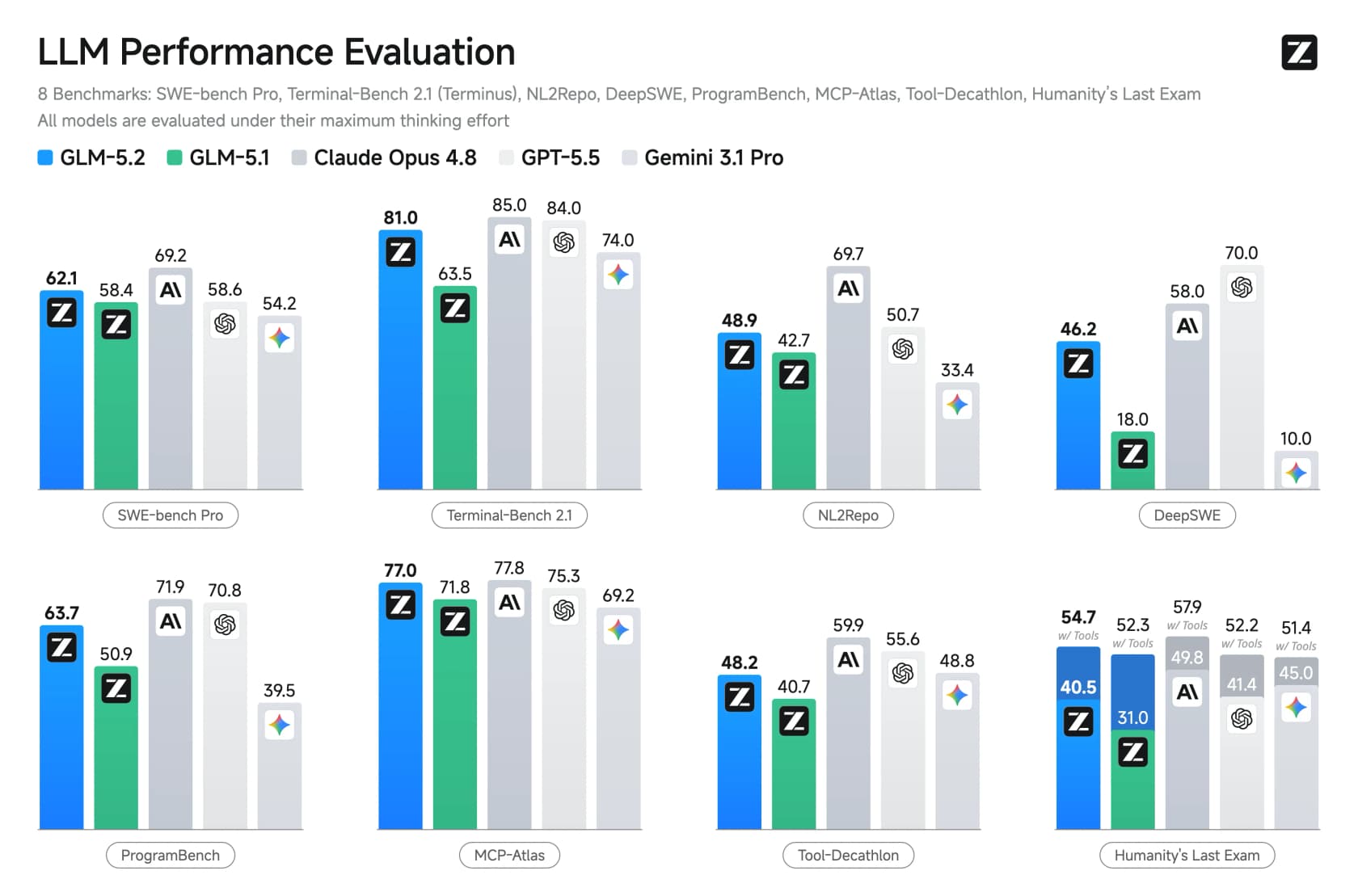
On the standard coding suite, GLM-5.2 posts 62.1 on SWE-bench Pro and 81.0 on Terminal-Bench 2.1, sitting just behind Opus 4.8 (85.0) and ahead of GPT-5.5 on several lines. The jump from GLM-5.1 is the part that should make you sit up: Terminal-Bench went from 63.5 to 81.0 in one release.
The long-horizon picture is even more lopsided, which is where Z.ai concentrated its effort.
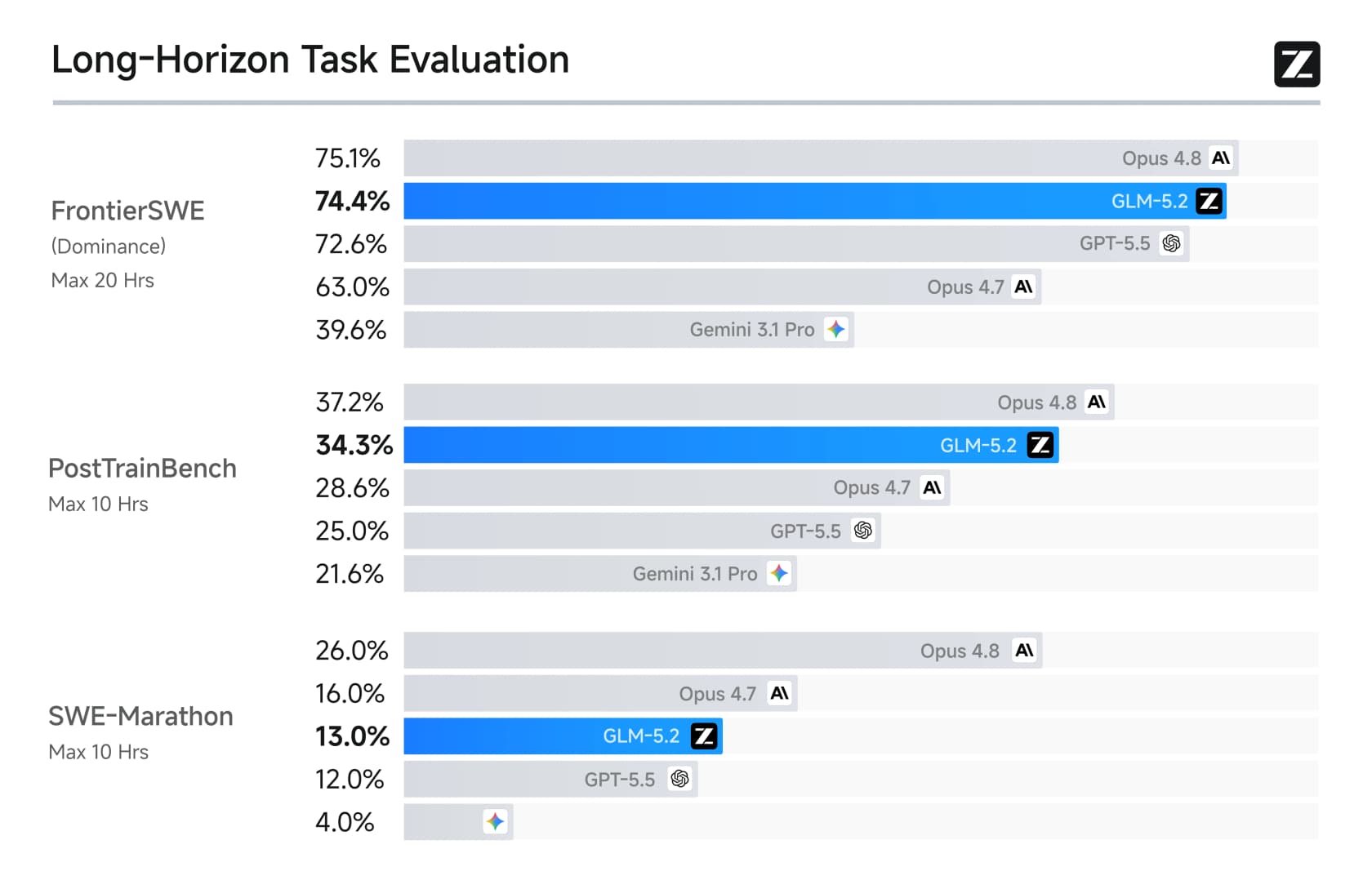
On FrontierSWE dominance it hits 74.4%, almost neck-and-neck with Opus 4.8's 75.1% and well above GPT-5.5. Named practitioners noticed. Jeremy Howard of fast.ai called it a marvel:
"@Zai_org GLM 5.2 is a marvel! It is at least as good as Opus 4.8 and GPT... It's super fast, inexpensive, and not too verbose. It responds with nuance and judgement, and handles long context VERY well."
Graham Neubig, who works on coding agents at CMU, went further, posting that it's "probably the first model good enough to eschew closed models from your workflow entirely." That's a strong claim from someone with no reason to flatter it.
Here's the caveat I'd want on the table, though. The benchmarks are coding benchmarks. They tell you GLM-5.2 is excellent at writing and fixing code over long sessions; they tell you very little about how it behaves answering a confused customer at 2am, where the failure mode isn't a failed test, it's a confident wrong answer nobody catches. More on that below.
The real headline is the price
The benchmarks get the attention, but the price is what actually moves businesses. GLM-5.2 runs at $1.40 per million input tokens and $4.40 per million output, against $5/$30 for GPT-5.5 and $5/$25 for Opus 4.8.
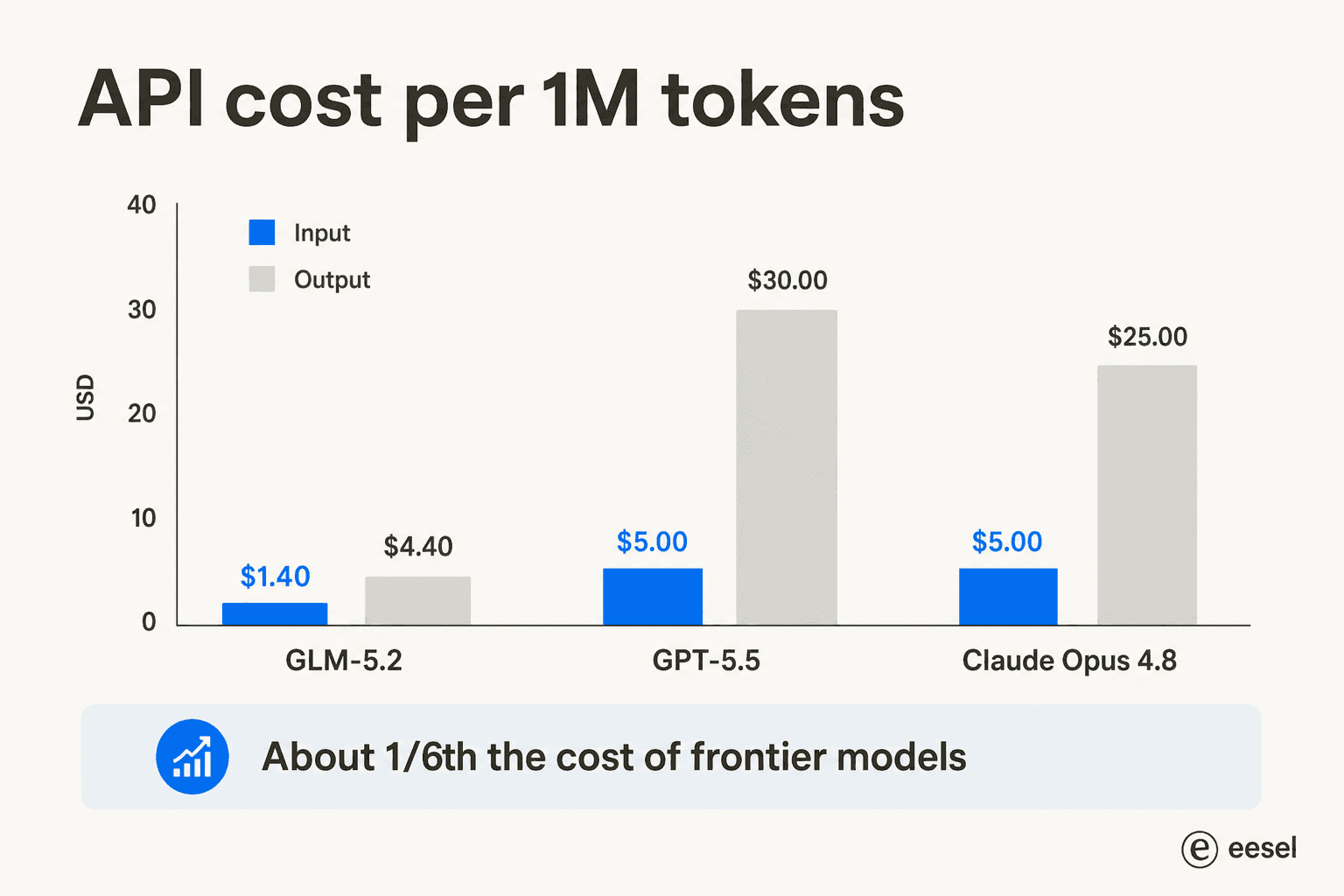
That gap is the whole story for a lot of teams. The framing across Reddit and LinkedIn is consistent, a "cheap frontier killer" you can swap in for everyday coding. Nate Herkelman summed up the mood in a LinkedIn post: "GLM 5.2 in Claude Code is blowing my mind (5x cheaper)."
But "cheap" deserves an asterisk, and it's an important one for budgeting. GLM-5.2 is a heavy reasoner, it burns a lot of output tokens to think, especially on Max effort. So on a metered, per-token API the bill can climb faster than the sticker rate suggests if you're not watching the effort level. The flat-rate plan exists precisely to make that cost predictable, which brings us to the access question.
Three ways to run GLM-5.2 for your business
There isn't one "GLM-5.2 for business" path, there are three, and they suit very different teams.

| Access path | Price | Best for |
|---|---|---|
| Z.ai API (pay-per-token) | $1.40 in / $4.40 out per 1M | Building it into your own app or agent; metered usage |
| OpenRouter / aggregators | from $1.20 in / $4.10 out per 1M | Same model via routed providers, often a touch cheaper |
| GLM Coding Plan, Lite | $18/mo ($12.60/mo yearly) | Light coding inside Claude Code and 20+ tools |
| GLM Coding Plan, Pro | $72/mo ($50.40/mo yearly) | Day-to-day dev on mid-sized repos, 5x Lite usage |
| GLM Coding Plan, Max | $160/mo ($112/mo yearly) | Large repos, heavy use, 20x Lite usage |
| Self-host (open weights) | Free (MIT), plus hardware | Full data control, regulated or air-gapped environments |
The pay-per-token API is the fastest way to wire GLM-5.2 into your own product, and it ships with both OpenAI-compatible and Anthropic-compatible endpoints, so you can point Claude Code or a similar harness straight at it. The GLM Coding Plan is the flat-rate route for developers who live in a coding tool and want a predictable monthly bill instead of a metered one.
Self-hosting is the one that gets oversold. Yes, the weights are free and MIT-licensed, which is genuinely a big deal for regulated industries. But a 753B model is not something you run on a spare GPU. As one developer on r/LocalLLaMA put it, the "massive 753B footprint means none of us are running it at home without an enterprise cluster." Realistically you're looking at a multi-GPU server, on the order of $150k of hardware, before quantization trade-offs that slow it to a crawl. For most businesses, "self-host" really means "host it on a cloud provider we trust," not "run it in the office."
Where GLM-5.2 fits, and where I'd be careful
Put the pieces together and the picture is pretty clear. For internal engineering work, GLM-5.2 is an easy yes to at least trial: agentic coding, refactors, long debugging sessions, automated research over a big codebase. The quality is there, the price is a fraction of the alternatives, and if you're cost-sensitive it's hard to argue with. If your task mix is simpler, it's worth pricing DeepSeek too, which is cheaper still for routine work.
Where I'd slow down is anything customer-facing, and this is the part the benchmarks don't cover.

Three things keep me cautious about pointing a raw model, any raw model, at live customers:
- Data residency. GLM-5.2 is an open-weights model from a China-based lab, and Z.ai was added to the US Commerce Department Entity List in 2025. The open weights are actually the answer here, not the problem, you can self-host or route through a vetted provider so customer data never touches the first-party API. But it's a decision you have to make on purpose. Some teams raise the privacy point loudly, and they're not wrong to.
- Reliability. "Big model smell" is real, and impressive coding scores don't mean a model won't confidently invent a refund policy. Security researcher Zack Korman flagged that GLM-5.2 "appears to be very good at AI agent sandbox escapes and bypasses," which is exactly the kind of thing you want to know before it has tool access to your systems. Hallucination on a real ticket is a trust problem, and it's why we simulate every rollout against historical tickets before going live.
- Latency and cost control. That heavy-reasoning trait that makes GLM-5.2 great at coding makes it slower and pricier per answer on
Maxeffort, which matters when a customer is waiting.
None of these are deal-breakers. They're just the difference between "the model scored well" and "I'd put it in front of my customers tomorrow." The fix isn't a better model, it's the layer around it.
Using GLM-5.2 (or any model) for support, the eesel way
Here's the thing I keep coming back to after years of running AI on support queues: the harness matters more than the model. The same point shows up in the community, people regularly find that a less capable model in a better setup beats a stronger one in a worse one. What decides outcomes on real tickets is whether the AI is grounded in your knowledge, whether you control when it speaks, and whether you tested it before it went live. It's the same lesson that separates a real AI support agent from a rule-based chatbot.
That's what eesel is. It's a vetted layer that sits on top of whatever model is best, learns from your past tickets and help docs, and only answers when it's confident, with everything else handed to a human. Before any of it goes live, you run it in simulation against thousands of your real historical tickets to see exactly how it would have replied, so you're not finding out in production. That's the part a raw GLM-5.2 API key doesn't give you, and it's where most of the real risk lives, the same gap that decides build versus buy for support AI.

So my honest take: get excited about GLM-5.2 for your engineers, and trial it for coding this week. For the customer-facing stuff, let the model be a swappable part and put your energy into the layer that makes it safe to ship. You can try eesel free and simulate it on your own tickets before you spend a cent, which is the only way I'd ever judge whether any model is ready for your business. If you're weighing the wider cost of AI support, that's the number that actually counts.









