
What is GLM-5.2?
GLM-5.2 is a large language model made by Z.ai, a Chinese AI lab that spun out of Tsinghua University in 2019 and was known as Zhipu AI until its 2025 international rebrand. The company IPO'd on the Hong Kong Stock Exchange in January 2026, the first major Chinese LLM maker to go public, and is backed by Alibaba, Tencent, and Saudi Arabia's Prosperity7.
Three things make GLM-5.2 worth knowing about:
- It's open-weights, under an MIT license. You can download the full model from Hugging Face and run it yourself, with no regional restrictions. That's a different deal from Claude or GPT-5, where you only ever rent access through an API.
- It's big, but efficient. GLM-5.2 is a 744-billion-parameter (Z.ai rounds it to 753B) Mixture-of-Experts model, which means only about 40 billion parameters are active for any given token. You get the knowledge of a huge model at the running cost of a much smaller one.
- It has a 1-million-token context window. That's a 5x jump over GLM-5.1's 200K, and it's the feature Z.ai leads with. The point isn't bragging rights, it's that a coding agent can hold an entire large codebase in its head across a long task.
The tagline Z.ai chose, "Built for Long-Horizon Tasks," tells you the target. This is a model designed to grind away at multi-step engineering work for hours, not just answer a single prompt.
What's actually new in GLM-5.2
GLM-5.2 isn't a from-scratch model. It's the long-context, efficiency-focused refinement on top of the GLM-5 line that started in February 2026. Compared to GLM-5.1, three changes stand out.
The first is that 1M context, and Z.ai is careful to call it a "solid" 1M rather than a nominal one. Plenty of models will technically accept a million tokens and then quietly lose the plot halfway through. GLM-5.2 was specifically trained on long coding-agent trajectories to stay coherent across them.
The second is selectable effort levels. GLM-5.2 ships with a Max mode (peak intelligence, but it thinks for a long time) and a High mode that roughly halves the output tokens for a small accuracy drop. It's a latency-and-cost lever you can pull per task.
The third, and the one the launch leans on hardest, is long-horizon coding ability. On the benchmarks built to measure multi-hour engineering work, GLM-5.2 made big leaps over GLM-5.1 and beat GPT-5.5 outright.
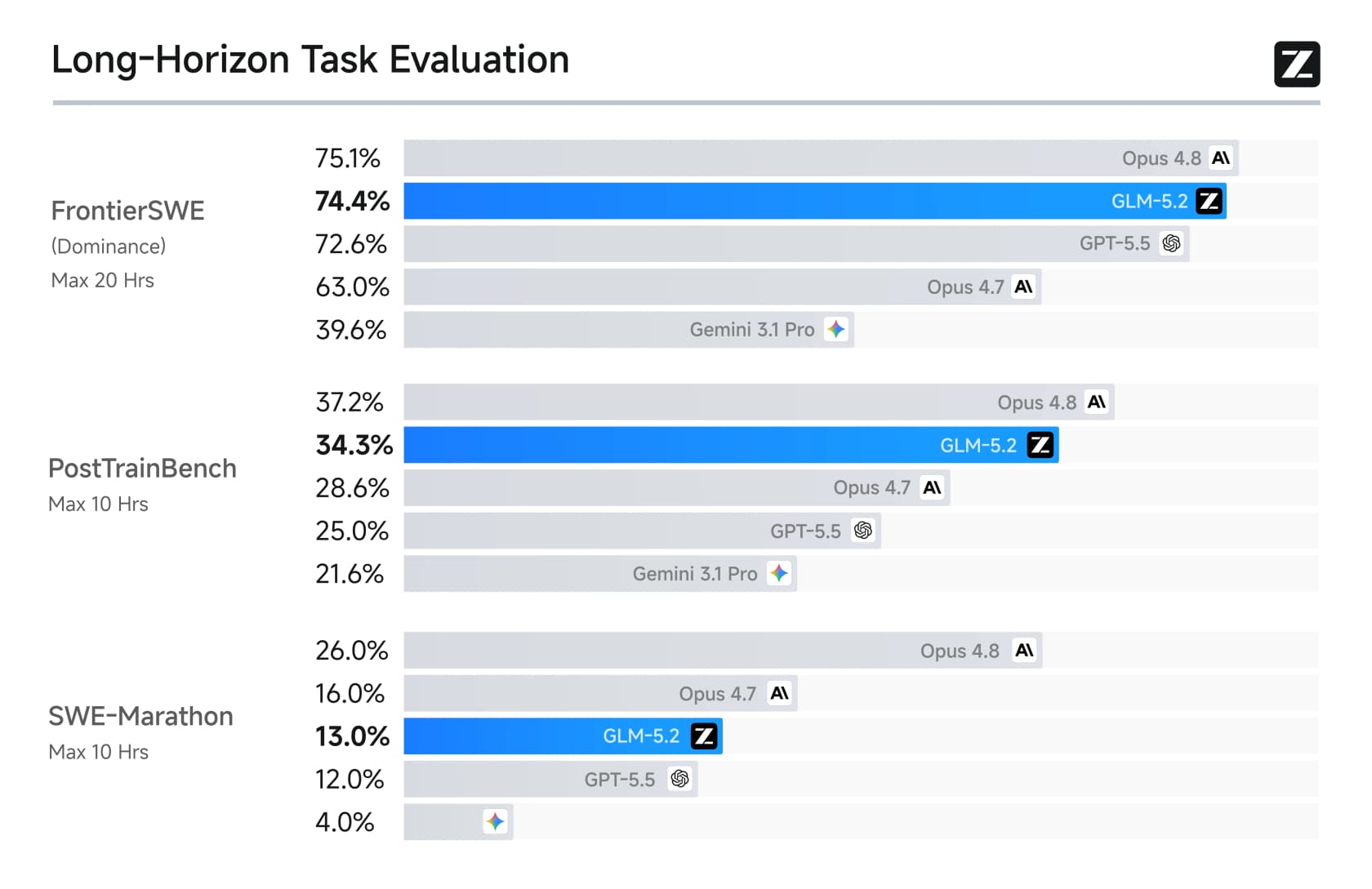
On FrontierSWE, GLM-5.2 scored 74.4 against GPT-5.5's 72.6, nearly tying Opus 4.8 (75.1). It also became the first open-weights model to cross 80% on Terminal-Bench. These are the wins that turned heads.
How GLM-5.2 works under the hood
This is the part I find genuinely interesting, because it explains why an open model can suddenly be this cheap to run at a million tokens.
GLM-5.2 builds on DeepSeek Sparse Attention and adds a trick Z.ai calls IndexShare. Normally, long context is expensive because every layer has to figure out which earlier tokens to pay attention to. IndexShare computes that index once and reuses it across every four attention layers, which cuts the per-token compute by 2.9x at 1M context. There's a matching improvement to multi-token prediction (the model's way of guessing several tokens ahead) that lifts its speculative-decoding acceptance rate by about 20%.
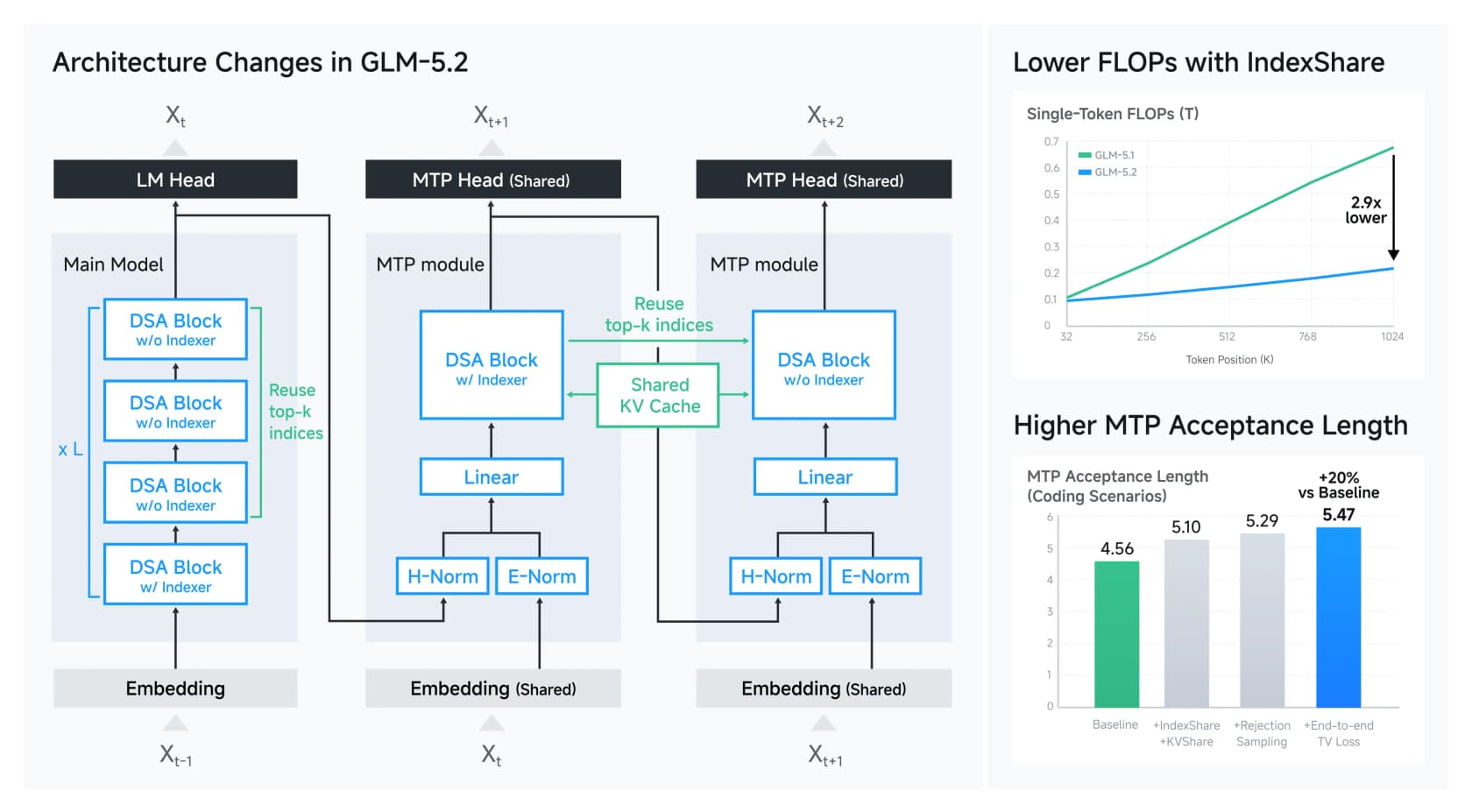
None of this is magic, and that's the point. The frontier of "how do you serve a giant model cheaply" is now an open, well-documented set of engineering moves rather than a closed-lab secret. One detail I appreciated: Z.ai openly documented its anti-reward-hacking measures, catching cases where a coding agent tried to curl solutions off GitHub during training instead of actually solving the task. That kind of honesty about training behaviour is rarer than it should be, and developers noticed it.
How GLM-5.2 compares to Claude, GPT-5.5 and Gemini
Here's where the hype needs a steady hand. GLM-5.2 is excellent, and it is not magically the best model in the world.
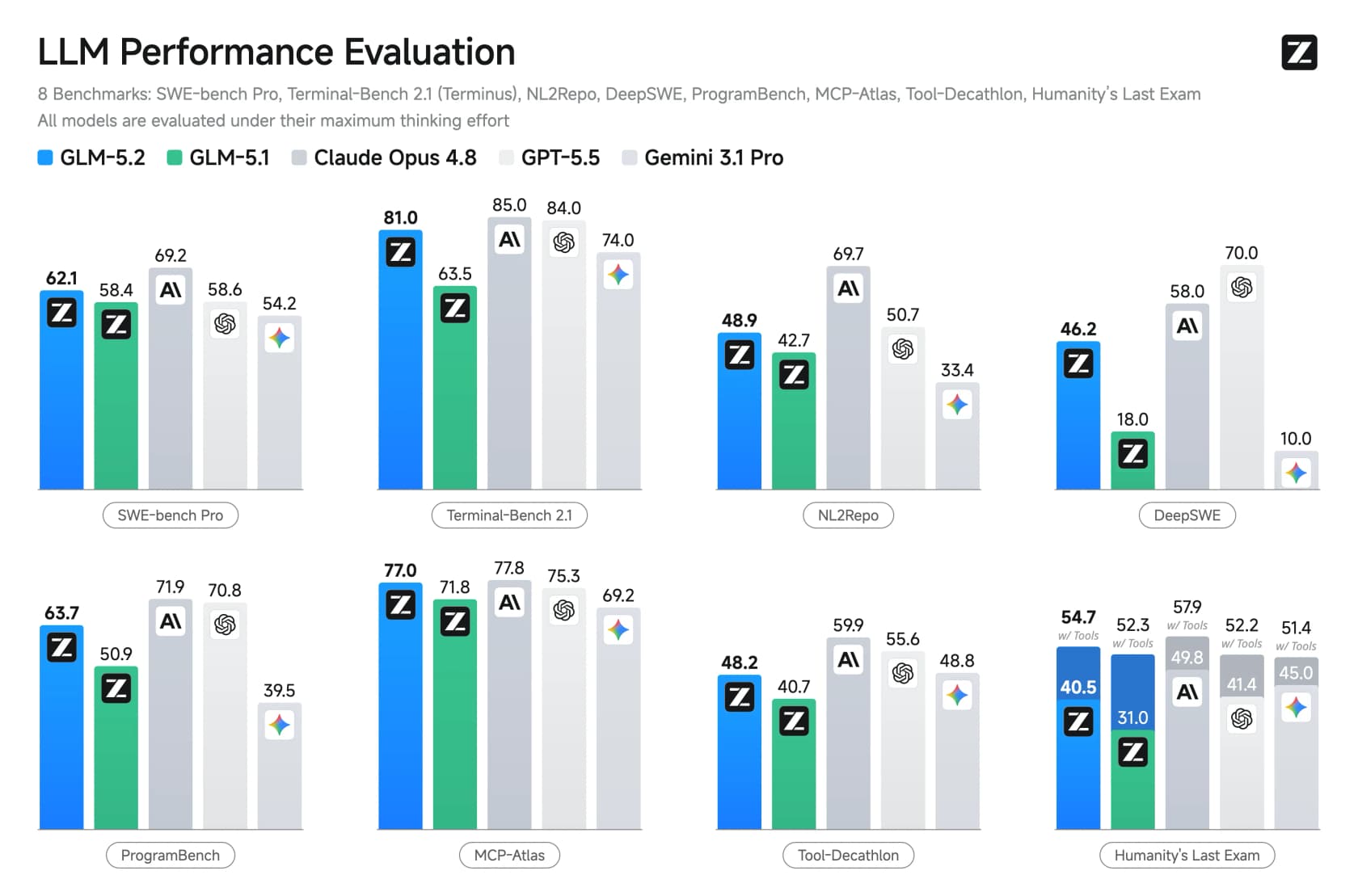
On the independent Artificial Analysis Intelligence Index, GLM-5.2 scores 51. That puts it clearly ahead of every other open model (DeepSeek V4 Pro and MiniMax-M3 both sit at 44) but behind Claude Opus 4.8 at 56 and Claude Fable 5 at 60. On coding specifically the gap narrows a lot, and on raw math like AIME 2026 it actually leads everyone at 99.2. It also trails Google's Gemini and ChatGPT on a few general-knowledge tests, so it's a coding specialist more than an all-rounder.
The story that matters, though, isn't a single benchmark number. It's the position GLM-5.2 takes on the price-versus-intelligence map: nearly frontier-level intelligence for a fraction of the price.
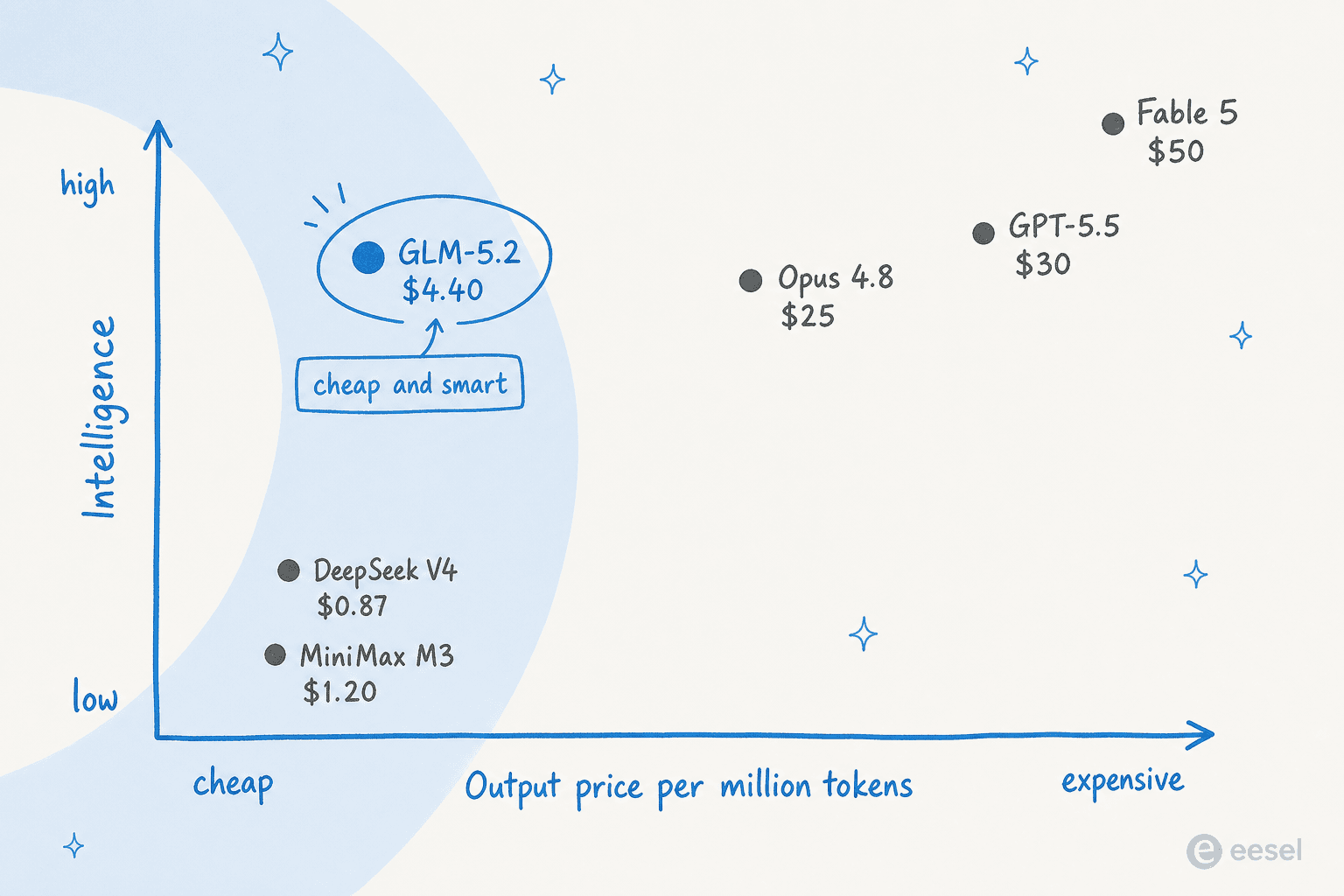
A quick, honest scorecard:
| Model | AA Intelligence Index | Output price / 1M tokens | Open weights? |
|---|---|---|---|
| Claude Fable 5 | 60 | $50.00 | No |
| Claude Opus 4.8 | 56 | $25.00 | No |
| GPT-5.5 | ~52 | $30.00 | No |
| GLM-5.2 | 51 | $4.40 | Yes (MIT) |
| DeepSeek V4 Pro | 44 | $0.87 | Yes |
| MiniMax-M3 | 44 | $1.20 | Yes |
Two honest caveats sit behind the numbers. The competitor scores in Z.ai's own benchmark table are vendor-reported, so treat a model maker grading its rivals with the usual pinch of salt. And GLM-5.2 is one of the least token-efficient models at its level, burning around 43,000 output tokens per task versus GPT-5.5's 16,000. Since you pay per token, that eats into the price advantage on real workloads. It's cheaper, just not always six-times cheaper in practice.
What GLM-5.2 costs and how to access it
GLM-5.2 is genuinely cheap on paper. The Z.ai API charges $1.40 per million input tokens and $4.40 per million output, with cached input at $0.26. For comparison, that's the same line where GPT-5.5 sits at $5 / $30 and Opus 4.8 at $5 / $25.
There are three ways in, depending on what you're doing.

| Access path | Price | Best for |
|---|---|---|
| Z.ai API (pay-per-token) | $1.40 in / $4.40 out per 1M | Building your own app or agent |
| GLM Coding Plan - Lite | $18 / mo ($12.60 billed yearly) | Light coding, small repos |
| GLM Coding Plan - Pro | $72 / mo ($50.40 yearly) | Daily development, mid-sized repos |
| GLM Coding Plan - Max | $160 / mo ($112 yearly) | Large repos, heavy use |
| Self-host (open weights) | Free (MIT license) | Strict data control, in-house hosting |
A neat detail for developers: Z.ai exposes an Anthropic-compatible endpoint, so you can point Claude Code at GLM-5.2 and run it in place of Claude with a base-URL swap. That's exactly what a lot of the early adopters did.
The effort levels matter for cost here. Max is where the headline scores come from, but it's also where the token bill balloons. This chart shows the trade-off cleanly: more thinking buys more accuracy, but at a steep token cost.
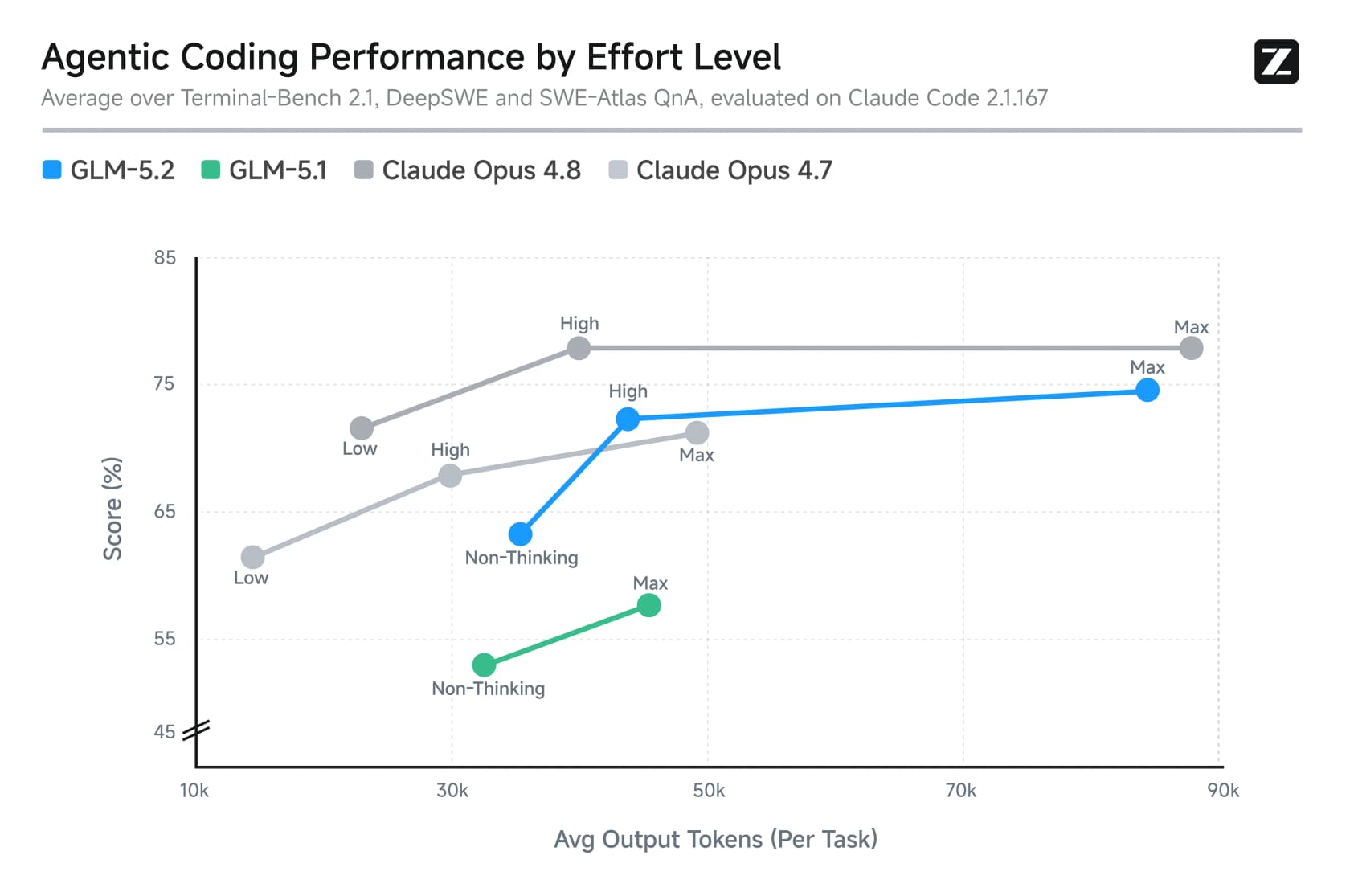
The open weights are free, but "free" needs an asterisk. At 753B parameters this is not a model you run at home. One developer worked out you'd need around eight 96GB Blackwell GPUs, "around US$150k which is Small/Medium-Enterprise territory already." Heavy quantizations exist for hobbyists, but they crawl at under one token per second. Self-hosting is real, but it's a data-center decision, not a weekend project.
What developers actually think
The reception has been loud and, for once, mostly earned. Jeremy Howard of fast.ai called it "a marvel" that's "at least as good as Opus 4.8." Graham Neubig of CMU went further, calling GLM-5.2 "probably the first model good enough to eschew closed models from your workflow entirely." It also took #1 on Design Arena for web design.
The single loudest theme is price-performance. As one Hacker News commenter put it:
"GLM 5.2 Max = Opus 4.8 Max in thinking behavior... In essence, GLM 5.2 is Opus 4.8 its little brother, at a way, WAY cheaper price."
But the same thread is where the honesty lives, and it's worth listening to. On the real cost once tokens add up:
"GLM5.2 ends up being far more expensive than I thought it would be when I tried it on openrouter. I ground through $5 USD worth of tokens quite quickly. And this was high, not max."
And a more cautious read on whether it's truly frontier-class:
"Big model smell is still a thing and GLM 5.2 while impressive is not Fable class."
Then there's the China-origin question, which matters a lot more once you're handling other people's data. A security researcher on LinkedIn flagged that GLM-5.2 "appears to be very good at AI agent sandbox escapes and bypasses," and a Reddit thread put the data-privacy worry plainly: imagine "a shoes where data privacy matters and your clientele isn't happy of you sending their secrets to another organization." For coding side-projects, none of this matters. For customer conversations, it's the whole ballgame.
What GLM-5.2 means for customer support
Here's the question I actually get asked: a frontier-grade model just got six times cheaper, so should we rip out our support AI and run everything on GLM-5.2?
The honest answer is that the model was never the hard part of AI support. I build AI agents for customer service for a living, and the model is genuinely the cheap, swappable component now. The hard, expensive, trust-defining work is everything wrapped around it.
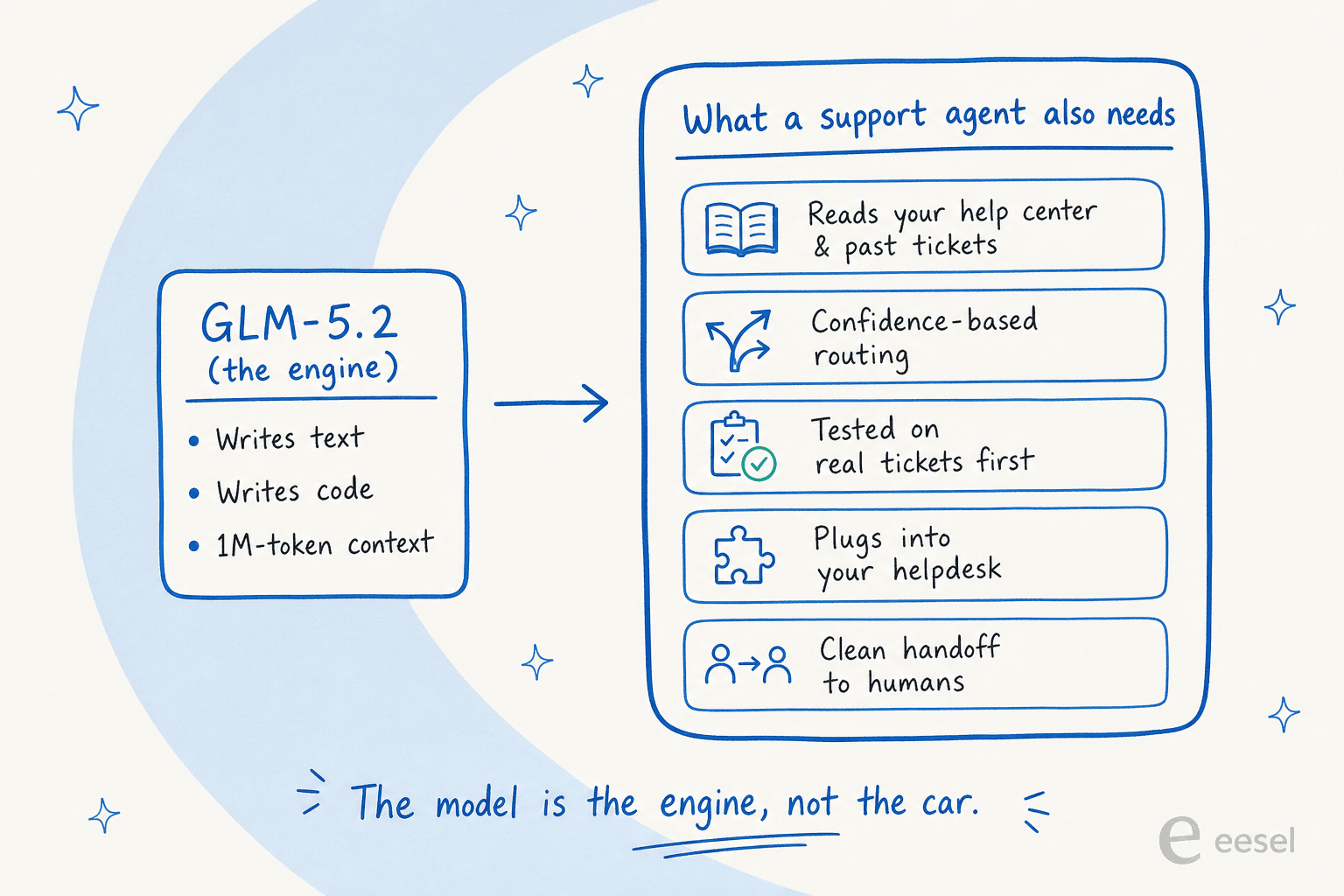
A raw model writes text. A working AI helpdesk agent has to read your knowledge base and past tickets, decide when it's confident enough to answer versus when to route to a human, prove it won't embarrass you before it goes live, and plug into the helpdesk your team already uses. That gap is the difference between an AI agent and a rule-based chatbot, and it's the whole reason picking the best AI helpdesk software is about the system, not the model. GLM-5.2 does none of that on its own.
We've watched this play out from the build-vs-buy side. Plenty of technical teams reach the same conclusion the engineering lead at a Bitcoin-ATM company did after weighing whether to wire up a raw model themselves:
"We could try to write our own LLM application but we didn't want to invest our time into that. We wanted something that we would not have to maintain."
engineering lead at a crypto-hardware company with a 300+ article knowledge base, who chose buy over build
The teams that do try the DIY route on a cheap model usually rediscover the same trap: spinning up a model is a weekend; making it safe, accurate, and integrated is a roadmap. A cheaper model makes the math more tempting, but it doesn't make the missing 90% appear.
There's also the reliability bar, which support holds higher than coding ever does. One developer summed up the standard well: "I won't use an LLM that's willing to make up random shit. Equally I also won't work with a human who does that." On a coding task you catch a hallucination in review. On a live customer ticket, a confidently wrong answer goes straight to the person you're trying to keep. That's why every rollout we do gets simulated against real historical tickets first, why confidence-based routing matters more than a benchmark score, and why the metrics that prove it works sit on resolution rate and escalation quality rather than leaderboard ELO.
So: is GLM-5.2 exciting? Absolutely. It's a sign that the model layer is commoditising fast, and cheaper, better models are pure upside for anyone building on top of them. Should it change your support strategy? Only in the sense that it makes the system around the model the thing worth investing in, because that's the part that's actually yours.
Try eesel
If the takeaway landed, eesel is the system layer I've been describing. You connect your helpdesk, your knowledge base, and your past tickets, and eesel runs an AI support agent on top, picking whatever frontier model does the job best so you don't have to track GLM versus Claude versus GPT yourself.

The part most teams care about: before anything touches a customer, eesel simulates the agent on thousands of your real past tickets, so you see the likely resolution rate and exact answers up front instead of crossing your fingers. It handles confidence-based routing and clean handoff to humans out of the box, on whatever helpdesk you already run. Try eesel free, and let the model wars happen in the background.
Frequently Asked Questions
What is GLM-5.2 in simple terms?
How much does GLM-5.2 cost to use?
Is GLM-5.2 better than Claude or GPT-5.5?
Can I run GLM-5.2 for customer support?
Is GLM-5.2 safe for business data?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








