So what exactly is Gemma 4?
I build the AI agents at eesel, and I've spent the last few years watching open models go from "fun to tinker with" to "good enough to put in front of a paying customer." We run agents on live support queues every day; one customer, Smava, processes 100,000+ German-language tickets a month through an automated agent. So whenever Google ships a new open model, I read it through one lens: could you actually trust this to answer a customer without a human watching?
Gemma 4 is the most interesting answer to that question I've seen from an open model.
In plain terms, Gemma is Google DeepMind's line of open models, the smaller, downloadable cousins of the closed Gemini models. Gemma 4 is "built from the same world-class research and technology as Gemini 3 to maximize intelligence-per-parameter," per Google's launch post. The key word is open-weight: Google publishes the actual model files, so you can run them on your own laptop, server, or phone with no API call leaving your network.
It's also multimodal. Every model handles text and image input, the smaller ones add native audio, and the model card notes a training cutoff of January 2025 with support for over 140 languages. If you've read our explainer on RAG versus LLMs, Gemma 4 is the "LLM" half of that picture, the reasoning engine you'd point at your own knowledge.
The five sizes, and which one is for you
Gemma 4 isn't one model, it's five, sorted by where they're meant to run. This is the part worth understanding before anything else, because picking the wrong size is the most common mistake I see people make.
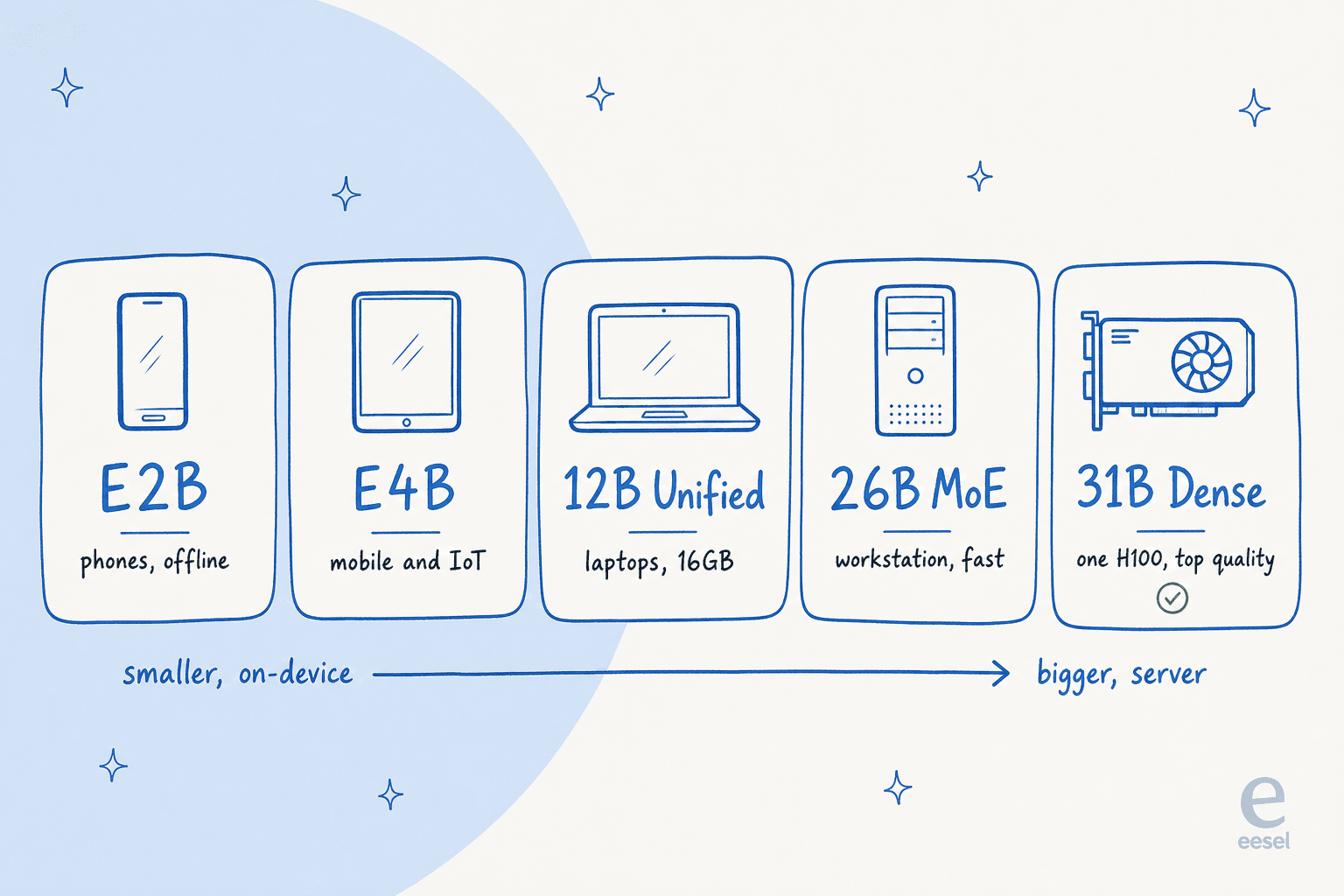
Here's the lineup, with the specs pulled straight from the model card:
| Model | Effective params | Context | Modalities | Runs on |
|---|---|---|---|---|
| E2B | 2.3B (5.1B with embeddings) | 128K | Text, image, audio | Phones, Raspberry Pi, edge |
| E4B | 4.5B (8B with embeddings) | 128K | Text, image, audio | High-end phones, IoT |
| 12B Unified | 11.95B | 256K | Text, image, audio | Laptops (~16GB) |
| 26B A4B (MoE) | 25.2B total, 3.8B active | 256K | Text, image | Workstation, latency-focused |
| 31B Dense | 30.7B | 256K | Text, image | Single 80GB H100, top quality |
The "E" in E2B and E4B stands for effective parameters. Those models use a trick called Per-Layer Embeddings to keep their memory footprint small, which is how a phone can run them offline with near-zero latency. Google built them with the Pixel team plus Qualcomm and MediaTek, so they're tuned for real mobile silicon, not just a demo.
The 12B Unified is the newcomer, added on June 3, 2026. It's the "laptop-ready" pick and Google's first mid-sized model with native audio input. The 31B Dense is the raw-quality flagship and the foundation everyone fine-tunes from.
The one in the middle, the 26B, is the most clever of the bunch. It deserves its own section.
How a 26B model keeps up with models 20x its size
The 26B is a Mixture-of-Experts (MoE) model, and understanding it is the single best way to grasp why Gemma 4 is a big deal.
A normal "dense" model fires every parameter for every token it processes. An MoE model splits its parameters into many small "experts" and, for each token, only switches on the handful it actually needs. Here's the shape of it:
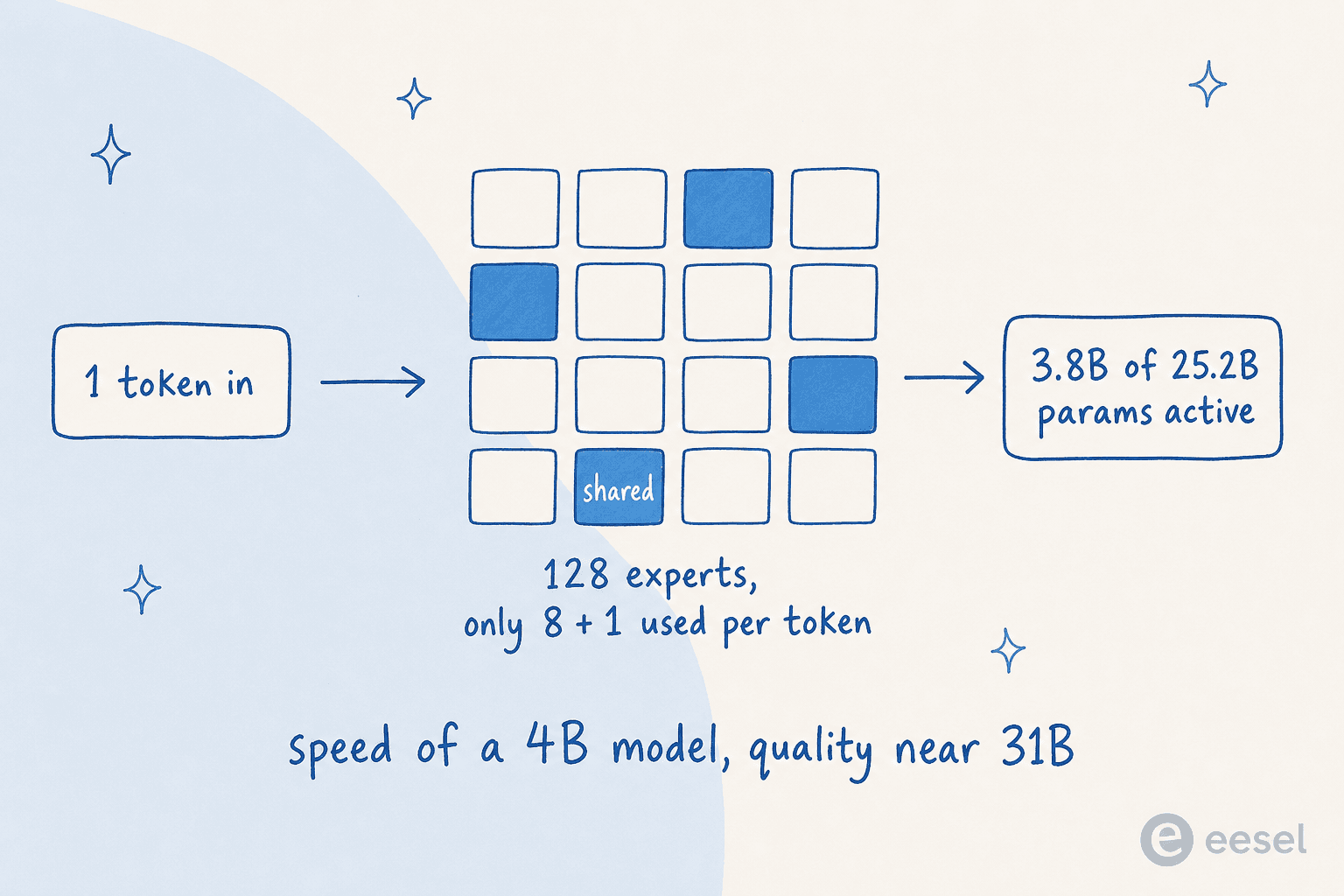
Gemma 4's 26B has 25.2B total parameters but only 3.8B active per token, routing through 8 of its 128 experts plus one shared expert. The practical result: it runs about as fast as a 4B dense model while answering closer to the quality of the 31B. (One caveat to keep in mind: all 25.2B parameters still have to be loaded into memory for routing, so MoE saves you compute, not RAM.)
Why does this matter? Because it breaks the old assumption that "smarter" means "bigger and slower." Look at where the medium Gemma 4 models land on Google's own performance-versus-size chart:
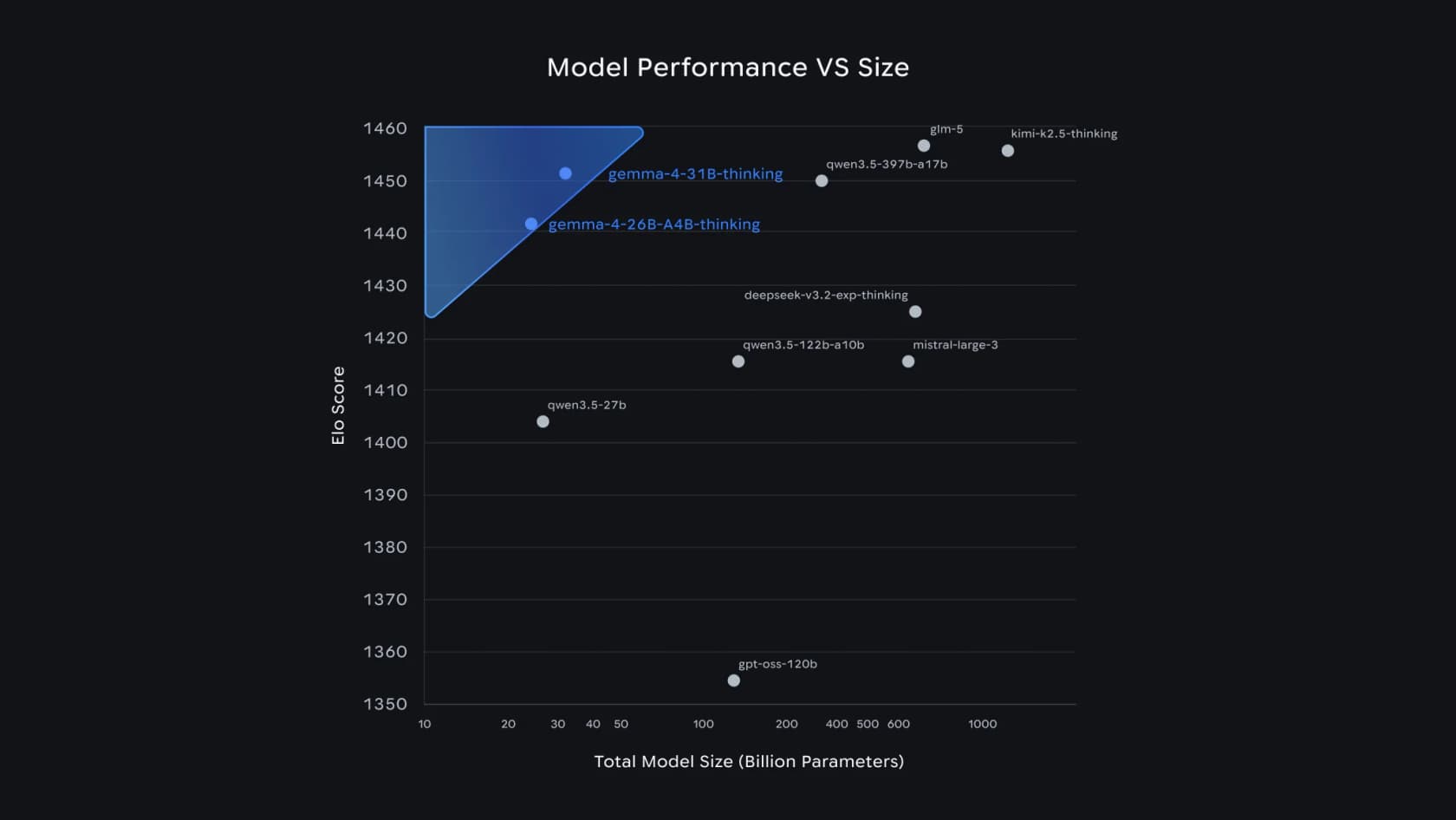
The 31B is the #3 open model on Arena AI's text leaderboard, and the 26B MoE takes #6, which is how Google can claim Gemma 4 "outcompetes models 20x its size." For a support team, the takeaway isn't the leaderboard rank, it's that this quality fits on a box you own.
What "open weights" actually means (and why the license changed)
People throw around "open" loosely, so let me be precise, because this is where Gemma 4 made its biggest move.
Previous Gemma models shipped under a custom "Gemma Terms of Use." Gemma 4 switched to a standard Apache 2.0 license. In Google's words, it's "commercially permissive," granting "complete control over your data, infrastructure, and models." Hugging Face's CEO Clément Delangue called the move "a huge milestone."
Here's the difference that license makes in practice:
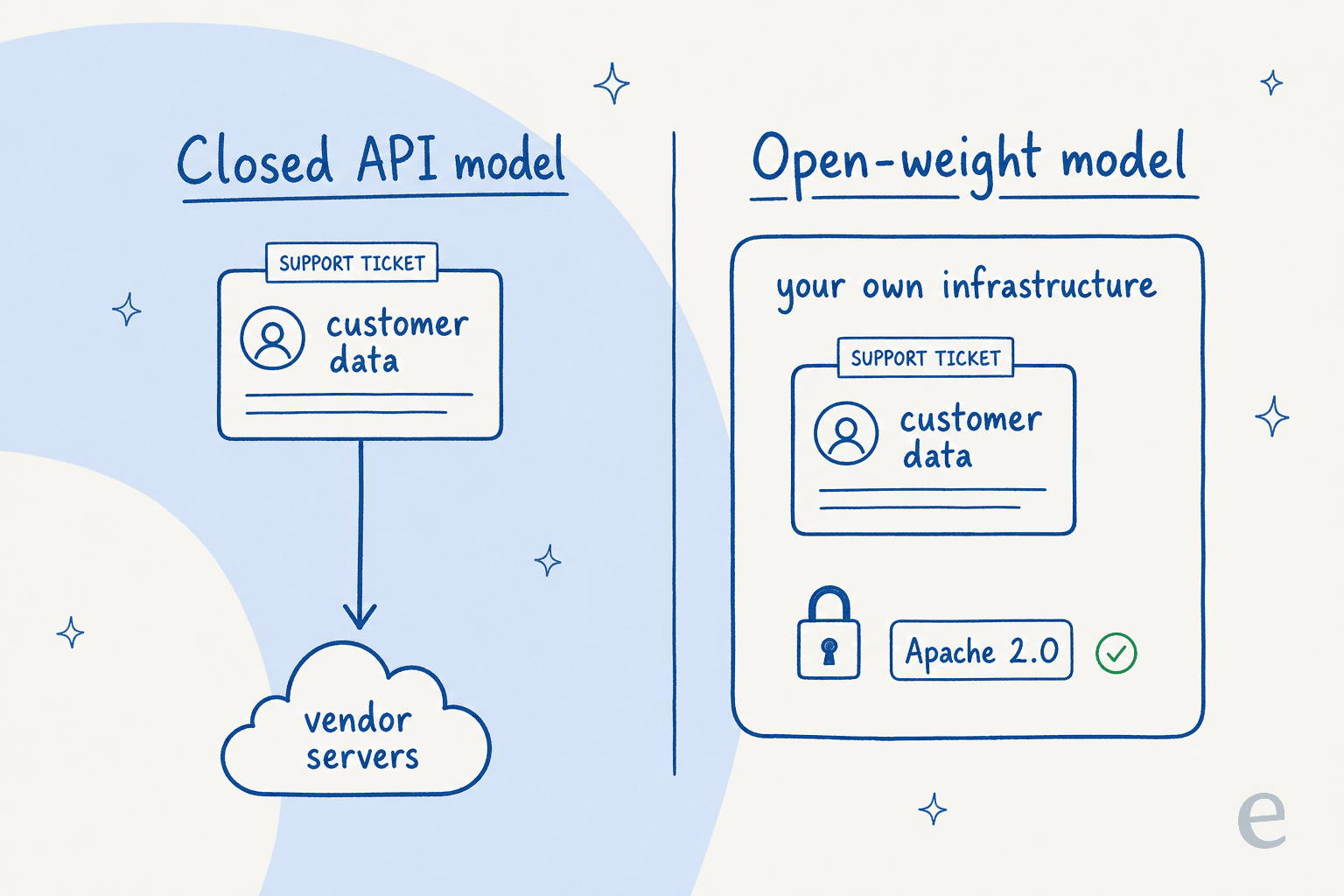
With a closed API model, every customer message you process is sent to a vendor's servers. With an open-weight model under Apache 2.0, you can run the whole thing inside your own infrastructure, on-premises or in your own cloud, and the data never leaves. For anyone in a regulated industry, that data-residency control is the entire reason to care about open models. It's the same reason people reach for open-source ticketing systems and open-source chatbot platforms.
To scale it, Google offers Gemma 4 across Vertex AI, Cloud Run, and GKE, and it works day-one with the tools self-hosters already use, like Ollama, llama.cpp, vLLM, and LM Studio.
The benchmarks, and where Gemma 4 actually shines
Numbers next. Google publishes a full benchmark table comparing the instruction-tuned Gemma 4 models against last generation's Gemma 3 27B:
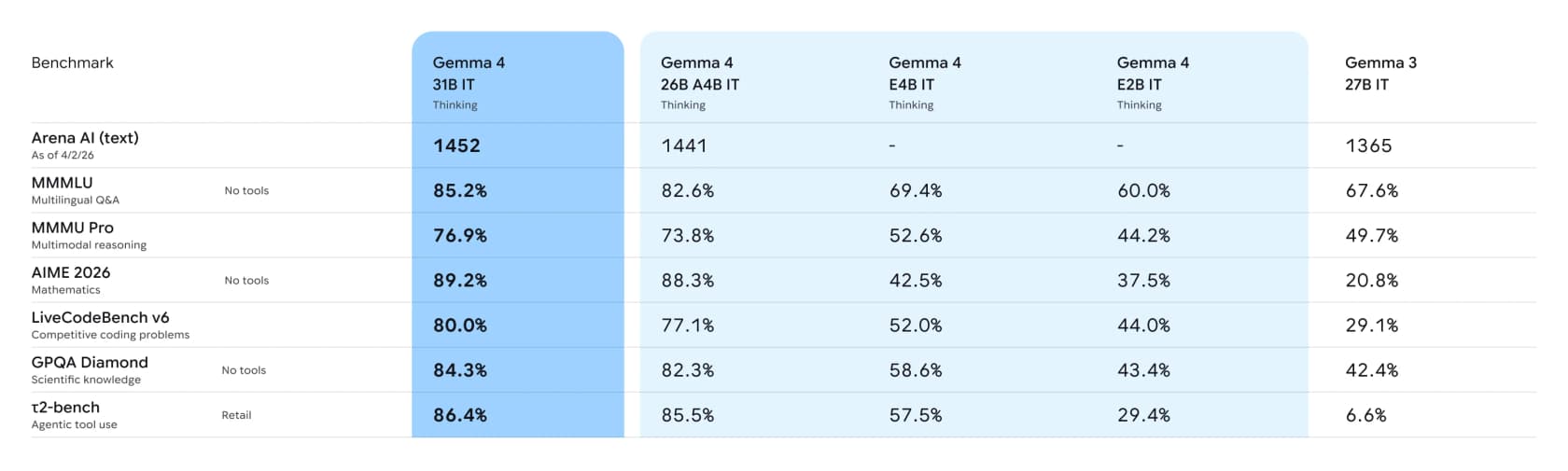
The one line I'd circle is agentic tool use. On the τ2-bench retail benchmark, which tests whether a model can actually call tools to complete a task, the 31B model scores 86.4% against Gemma 3's 6.6%. That's not an incremental bump, it's a generational leap, and it's the capability that turns a chatbot into something that can do work.
It holds up against the closed giants, too. On Arena Elo, the 31B's 1452 lands a hair behind models with 15-35x the parameters:
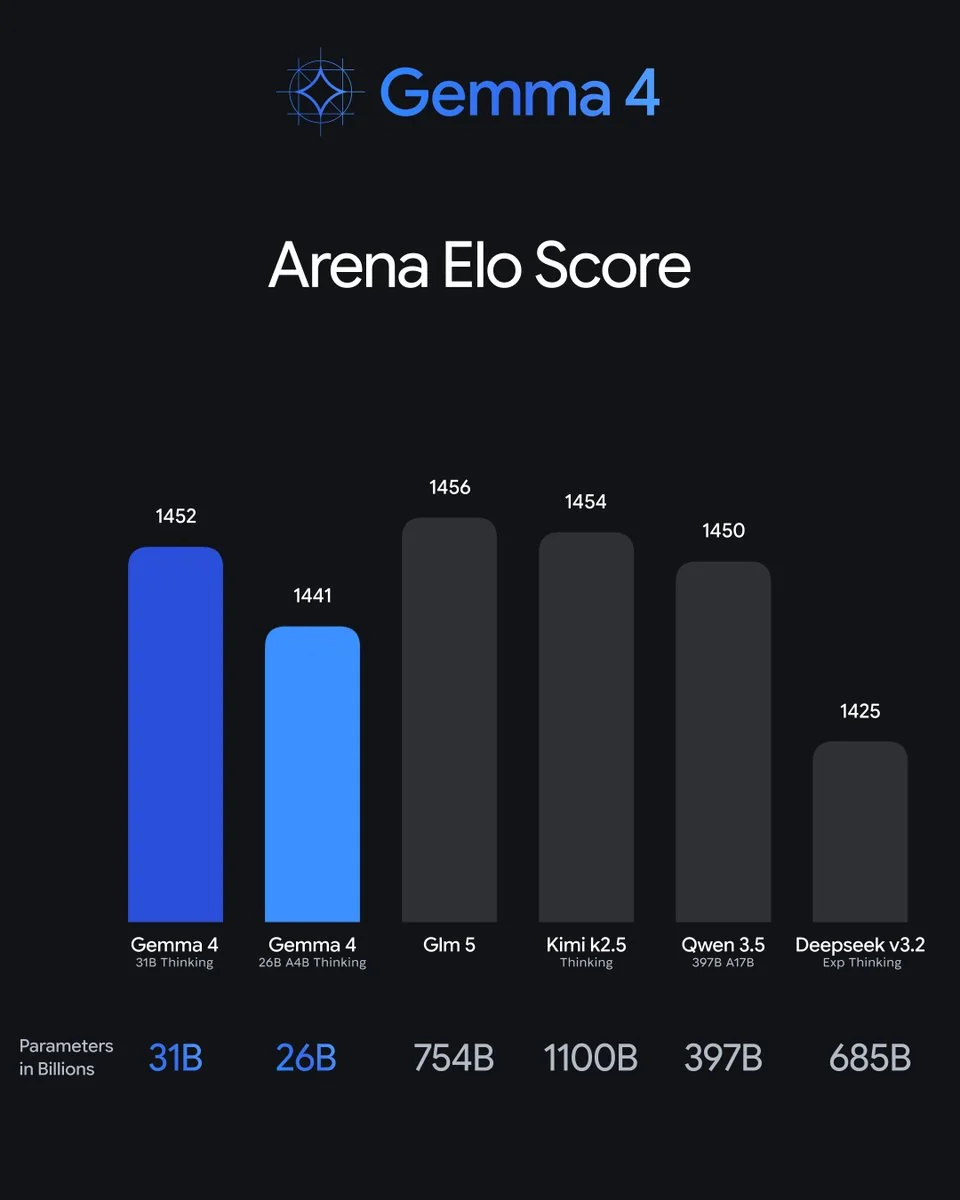
Architecturally, the interesting note from Sebastian Raschka's read is that Gemma 4 is "pretty much unchanged" from Gemma 3 under the hood, so the leap is "likely due to the training set and recipe." In other words, Google got this jump from better data, not a new architecture, which is a quietly impressive thing to pull off.
What it's actually like to run
Benchmarks are one thing. What do people who run Gemma 4 every day actually say? I went looking on the local-model communities, because that's where the unvarnished takes live.
The praise is consistent: it's fast, light on memory, and it doesn't ramble.
"Fast as F*** on a M4Max, and damn smart for its speed. Doesn't destroy your memory load. Doesn't reason for hours (and eat all of the token budget on reasoning) like Qwen does.. It's perfect for openclaw, hermes, claude code etc. I LOVE this model for local. It's my Go-to now."
That "doesn't reason for hours" point comes up again and again. A self-hoster running the 26B and 31B for a multimodal use case put real numbers on it, reporting roughly 149 tokens/sec on the 31B and 88 on the 26B, and adding that "the benchmarks don't really capture how little it yaps compared to larger ones."
But here's the honest limitation, and it's the reason I wouldn't hand raw Gemma 4 a live queue unsupervised:
"I agree it's much better at everything except at coding. [...] However it suffers heavily when weights or kv cache are any other quant but native."
So the community read nets out like this: Gemma 4 is an excellent chat and instruction-following model that punches well above its weight, with two caveats, coding and agentic workflows are its weaker areas, and it degrades noticeably if you run it on anything other than its native quantization. Good to know before you pick it for a job.
What this means for customer support
Here's where it gets practical for anyone running a support team. An open model like Gemma 4 is a fantastic ingredient. It is not, on its own, a support agent.
A raw model has no idea what your refund policy is, can't see your past tickets, and isn't connected to your helpdesk. Drop it in front of customers unsupervised and you get exactly the failure mode we've spent years engineering against: a confident-sounding bot that quietly gives the wrong answer. The model is the engine; the actual product is everything around it, the knowledge, the safe routing, the connection to your tools, and the ability to test it before it goes live.
That gap is the whole reason platforms like ours exist. The open-weight movement gives you control over the model layer, but most support teams don't want to also become an ML ops team. The better answer for most people is to get the data-control and learning benefits without hand-rolling the infrastructure, which is the line I'd draw between a model and an AI customer service platform.
Try eesel for AI support
If reading about Gemma 4 got you thinking "I want AI answering my tickets, but on my terms," that's the exact problem eesel is built for.
eesel's AI helpdesk agent plugs into the tools you already run, Zendesk, Freshdesk, Gorgias, Slack, and 100+ others, and learns from your past tickets and help docs on day one, so years of history becomes knowledge immediately. The part that maps directly to the "could you trust it?" question I opened with: you can simulate the agent against thousands of your historical tickets to see exactly how it would have answered, before a single customer sees it. That's how Gridwise got to 73% of tier-1 requests resolved in its first month.

It's usage-based, starting at $0.40 per ticket with no per-seat fees, and you can start with $50 of free usage and no credit card. Whether the model under the hood is Gemma 4 or anything else, the thing you actually want is an agent you can trust on your queue. Try eesel and see how it handles yours.
Frequently Asked Questions
What is Gemma 4?
Is Gemma 4 free to use?
What are the Gemma 4 model sizes?
Can Gemma 4 run on a laptop or phone?
Is Gemma 4 good for customer support?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.