
What is MiniMax M3?
MiniMax M3 is a general-purpose large language model that MiniMax describes as "a frontier coding and agentic model built on a novel attention architecture (MSA) with 1M context." It supersedes the earlier M2 line (M2, M2.1, M2.5, M2.7), which all stay available, and it is the first MiniMax model trained to be multimodal from the very first step, so it takes image and video input and can even operate a desktop computer.
MiniMax itself is a Chinese AI lab whose tagline is "Intelligence with everyone," with a lineup that runs well beyond text into video (Hailuo), speech, and music. M3 is the text and agent flagship of that lineup. If you have been following the wave of strong models coming out of China, M3 sits in the same conversation as Qwen and Kimi K2.5, and it is one of the more interesting open-weight launches of the year.
The official launch made the pitch plainly on MiniMax's X account:
"Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities... Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1... MiniMax Sparse Attention scales context to 1M... Natively Multimodal from Step Zero"
One naming note before we go further: there is no model literally called "MiniMax 3." The official name is MiniMax M3, and that is what this guide covers.
How MiniMax M3 works: sparse attention and a 1M-token window
The most interesting thing about M3 is not a benchmark, it is the architecture that lets it read a million tokens without the cost exploding. This is the bit I find genuinely clever, so let me unpack how it works.
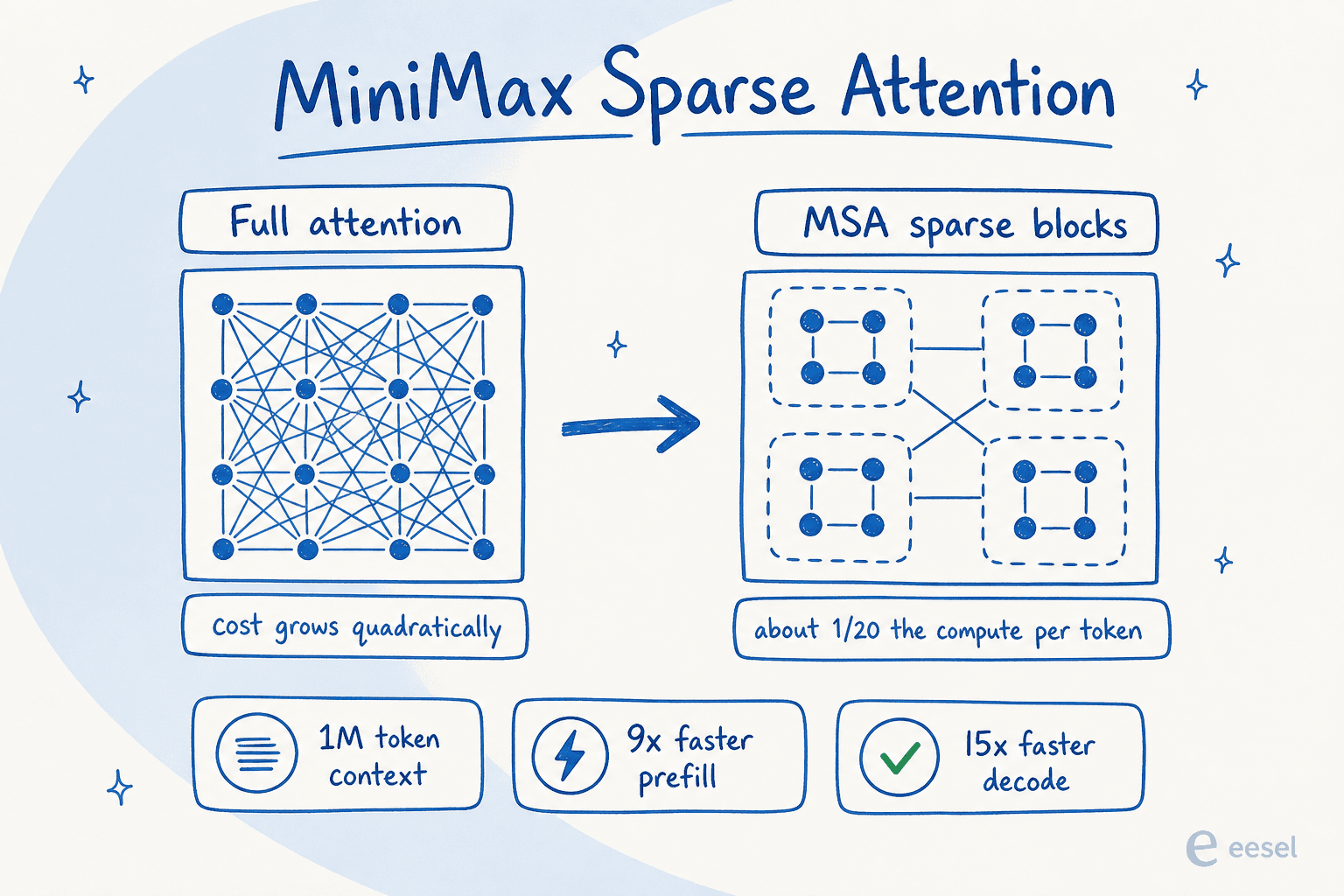
Under the hood, M3 is a Mixture-of-Experts model with around 428B total parameters and roughly 23B activated per token, so it only ever runs a fraction of itself on any given request. On top of that sits the real headline: MiniMax Sparse Attention (MSA), a new attention design that partitions the context into blocks and only attends to the relevant ones instead of comparing every token to every other token.
That matters because normal attention gets quadratically more expensive as the context grows, which is why long context windows are usually slow and pricey. MiniMax reports that MSA cuts per-token compute to about 1/20, with more than 9x faster prefilling and 15x faster decoding at a 1M context compared with M2, while matching full attention on most capabilities in their ablations. The result is a 1,000,000 token context window (with a guaranteed minimum of 512K), up from 204,800 on the M2 line.
A few other things worth knowing about how M3 behaves:
- Thinking modes. A
thinkingparameter lets you set reasoning toenabled,adaptive(the model decides), ordisabledfor low latency, and both modes share the same pricing. - Native multimodality. Because it was trained on interleaved text, image, and video "from Step 0," M3 fuses the modalities more deeply than a model with vision bolted on afterwards.
- Built for long-horizon work. In MiniMax's own demos, M3 ran autonomously for nearly 12 hours to reproduce a research paper, and spent about 24 hours optimizing a CUDA kernel across 147 benchmark submissions and 1,959 tool calls.
The full method is in the M3 technical report if you want the depth.
How good is MiniMax M3? The benchmarks
MiniMax positions M3 as reaching the frontier on software engineering and terminal execution, and benchmarks it against closed models like GPT-5.5, Gemini 3.1 Pro, and Claude Opus. Here are the published scores from the announcement:
| Benchmark | What it measures | MiniMax M3 |
|---|---|---|
| SWE-Bench Pro | Real-world software fixes | 59.0% |
| Terminal-Bench 2.1 | Command-line agentic tasks | 66.0% |
| MCP Atlas | Tool use over the agent protocol | 74.2% |
| SWE-fficiency | Efficient code changes | 34.8% |
| KernelBench Hard | GPU kernel optimization | 28.8% |
| PostTrainBench | Training models autonomously | 37.1 (#3) |
| Video-MME (512 frames) | Video understanding | 84.6 |
A bit of honesty about what these mean. On the autonomous model-training benchmark PostTrainBench, M3 came third overall, slightly behind Claude Opus 4.7 (42.4) and GPT-5.5 (39.3) but ahead of everything else. That is the pattern across the board: M3 is excellent for an open-weight model and competitive on coding, but it is not topping the closed frontier. The earlier M2 family had already pushed open-weight scores higher on independent indexes, and M3 is a clear step up from there.
If you want the wider context for how these models stack up, our guides on Claude alternatives and Gemini alternatives cover the closed-model side of the comparison.
How much does MiniMax M3 cost?
This is where M3 gets its reputation. The pricing is the reason developers keep mentioning it.
MiniMax sells M3 two ways. The first is a subscription Token Plan, updated at launch across three tiers, where text, image, speech, and music all draw from one shared usage pool:
| Token Plan | Price / month | Approx. M3 tokens / month |
|---|---|---|
| Plus | $20 | ~1.7B tokens |
| Max | $50 | ~5.1B tokens |
| Ultra | $120 | ~9.8B tokens |
MiniMax frames the entry tier as "$20 = 10x Claude Pro" on throughput, which is marketing, but it tells you the angle: maximum tokens per dollar. It is the same low-cost positioning you see from Qwen pricing and the rest of the open-weight pack.
The second way is the pay-as-you-go API, priced by input length. Calls under 512K input tokens get the standard rate; anything above that is billed at a higher long-context rate for full-repo and ultra-long-document work. Thinking on or off costs the same, and a priority service tier is available for latency-sensitive workloads. Developers on r/LLMDevs report the launch per-token rate at $0.60 / $2.40 per million up to 512K, which puts it, in their words, in "Deepseek territory."
The other half of the cost story is the license. M3 is open-weight under the MiniMax Community License: free for non-commercial use, with commercial use requiring a visible "Built with MiniMax M3" credit and, above $20M/year in revenue, prior written authorization. So it is open-weight, not open source, a distinction the community is quick to point out. For a pure cost comparison against other paid options, our list of cheap AI tools and the Kimi K2.5 pricing guide are useful reference points.
What developers actually say about MiniMax M3
The published benchmarks only tell you so much. The more useful signal comes from developers running M3 on real work, and the verdict is consistent: a strong value pick, not a frontier replacement.
The clearest version of the value case actually comes from someone who switched to the M2.7 predecessor, on r/openclaw:
"claude is a slightly better model. better reasoning, better depth on hard problems. that's just how it is. but minimax m2.7 delivers exceptionally well for what i actually use it for, at a fraction of the cost... sometimes good enough is actually great when it's reliable and affordable."
On M3 specifically, a developer on r/opencode put it like this after trying the other Chinese models first:
"I started using Kimi 2.6, then GLM 51, then DeepSeek4. But now after trying minimax m3 I am really impressed. It seems to think very deeply and really do a good job following directions... It seems to have flown a lot under the radar."
That roughly maps to where M3 lands in the market: open weights, near Sonnet-class capability, at value-tier pricing.
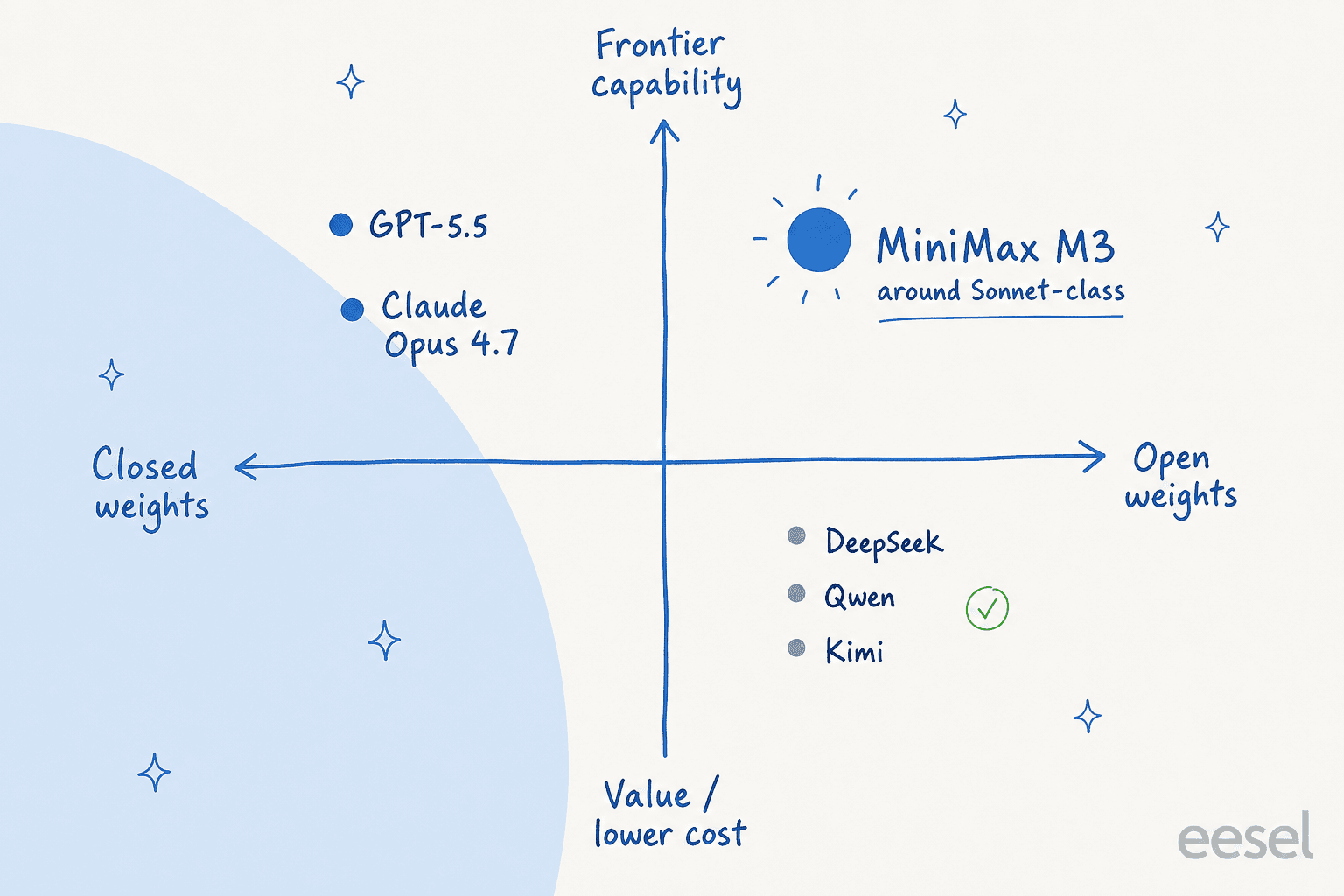
It is not all praise, though, and the criticism is worth taking seriously if you are thinking about production. The most common complaint is reliability under pressure. One tester on r/hermesagent found M3 erratic:
"I feel like it is much more chaotic and verbose, as well as hallucinations being more common. Now it just suddenly keeps stopping mid action... Right now I wouldn't use it in production."
There is also a recurring data-retention worry about the hosted API, with users noting they could not find a clear opt-out of prompt data being used for training. That is exactly the kind of thing that matters more for customer data than for a hobby project, and it is a big reason the self-hosting crowd likes that the weights are on Hugging Face at all.
The catch: a great model still isn't a support agent
Here is the reframe I want you to walk away with, because it is the thing people miss when a shiny new model launches. A model like M3 is a fantastic engine. But an engine is not a car, and a raw model is not a customer support agent.
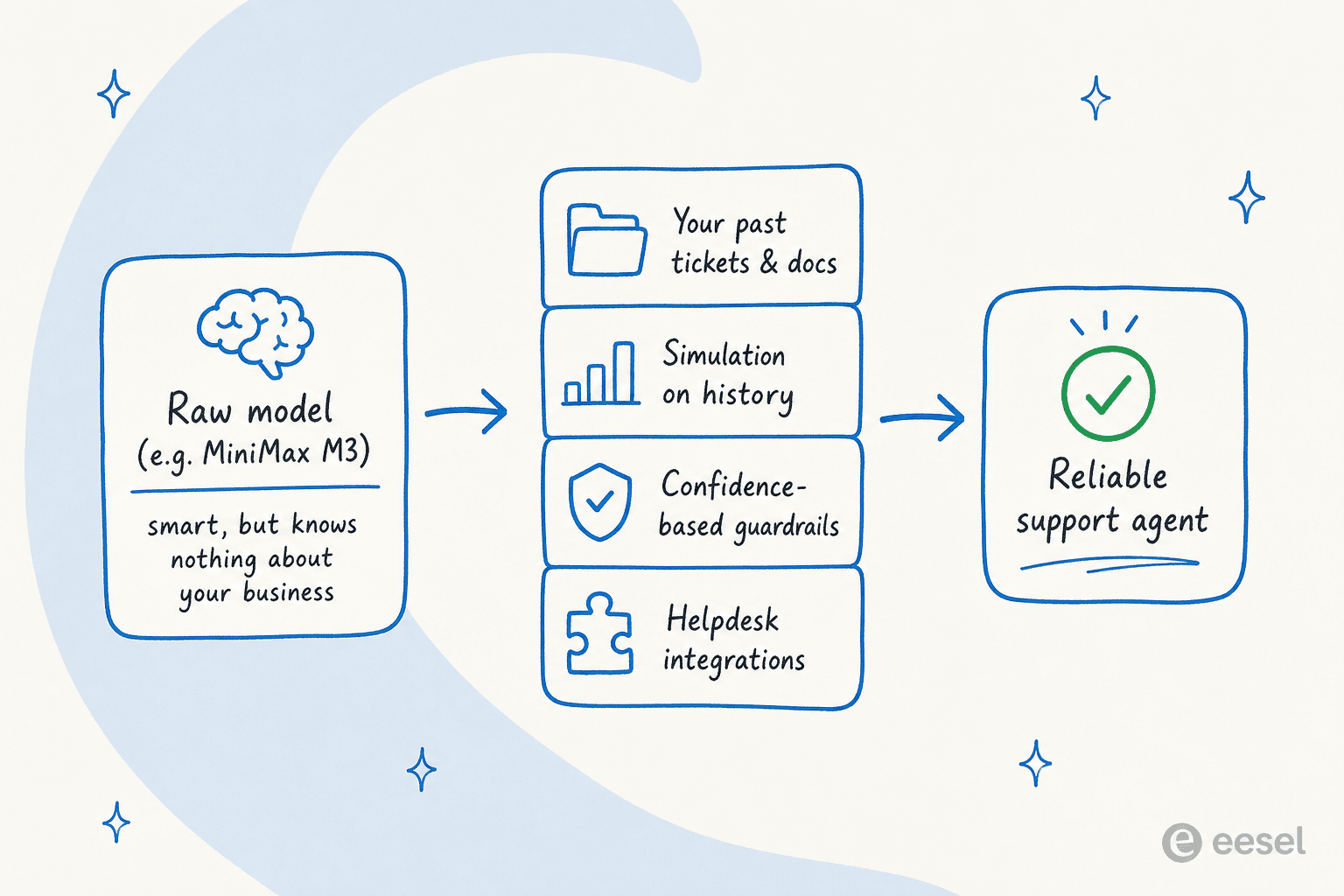
I have spent the last few years at eesel watching what happens when you point a language model at a live support queue, and the failure mode is always the same: the model sounds confident and gets the specifics wrong, because it does not know your refund policy, your last 50,000 resolved tickets, or which answer is safe to send without a human reading it first. The smartest model on the leaderboard still hallucinates your shipping cut-off if nobody taught it. That is why every eesel rollout runs in simulation against historical tickets before it ever replies to a customer.
So the relevant questions for support are not "what did M3 score on SWE-Bench." They are: can it learn from my actual tickets and docs, can I test it safely before it goes live, and what stops it from confidently sending a wrong answer? Those are product questions, not model questions, and they are the ones our roundup of the best AI for customer service is built around.
The same point shows up whenever a chatbot answers incorrectly, and it is why the cost of an AI agent versus a human depends far more on how reliably it resolves tickets than on the per-token price of the model.
eesel: the layer that turns a model into a support teammate
This is exactly the gap eesel is built to close. Instead of asking you to pick a model and pray, eesel sits on top of your helpdesk as an AI teammate that learns from your past tickets, help docs, and tools on day one, then drafts, triages, and resolves tier-1 work with the guardrails that make it safe to leave running.

The concrete differentiator is simulation mode: you run the agent against thousands of your real past tickets, see exactly what it would have answered and where the gaps are, fill them, and only then go live, with confidence-based routing keeping low-confidence replies as drafts instead of sends. That is how teams like Smava run a fully automated Zendesk agent on 100,000+ German tickets a month, and how Gridwise hit 73% tier-1 resolution in its first month. It connects to 100+ integrations, answers in 80+ languages, and runs on usage-based pricing at $0.40 per ticket with no per-seat fees.
If you came here choosing a model for support, the better starting point is the layer, not the leaderboard. You can Try eesel free, no credit card, and watch it resolve your own tickets in simulation before it touches a single customer. It is the same lesson behind every customer service AI rollout I have seen work: the model is interchangeable, the reliability is not.
Frequently Asked Questions
What is MiniMax M3 in simple terms?
Is MiniMax M3 actually open source?
How much does MiniMax M3 cost?
Is MiniMax M3 good for coding?
Can I use MiniMax M3 for customer support?
How does MiniMax M3 handle a 1 million token context?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.







