So what exactly is Sakana Fugu?
Sakana AI is a Tokyo frontier lab founded in 2023 by three ex-Google researchers: CEO David Ha, CTO Llion Jones (one of the eight co-authors of the original "Attention Is All You Need" Transformer paper), and COO Ren Ito. In November 2025 it raised a $135M Series B at a $2.65B valuation, making it one of Japan's most valuable AI startups.
The name matters. "Sakana" (魚) means fish, a nod to the lab's bet that the future of AI looks less like one giant brain and more like a coordinated school of smaller specialists. Fugu (named after the pufferfish) is that thesis turned into a product. Sakana pitches it as "One Model to Command Them All": frontier-level performance without depending on any single vendor.
Here's the cleanest way to picture it. Fugu is itself a model, but instead of generating the final answer alone, it dynamically assembles a team from a pool of other powerful models and coordinates them. The whole apparatus is exposed to you as one model behind one API. If you've read our explainer on AI agents versus chatbots, Fugu is the agent idea taken to its logical extreme: the agent's "tools" are other frontier models.
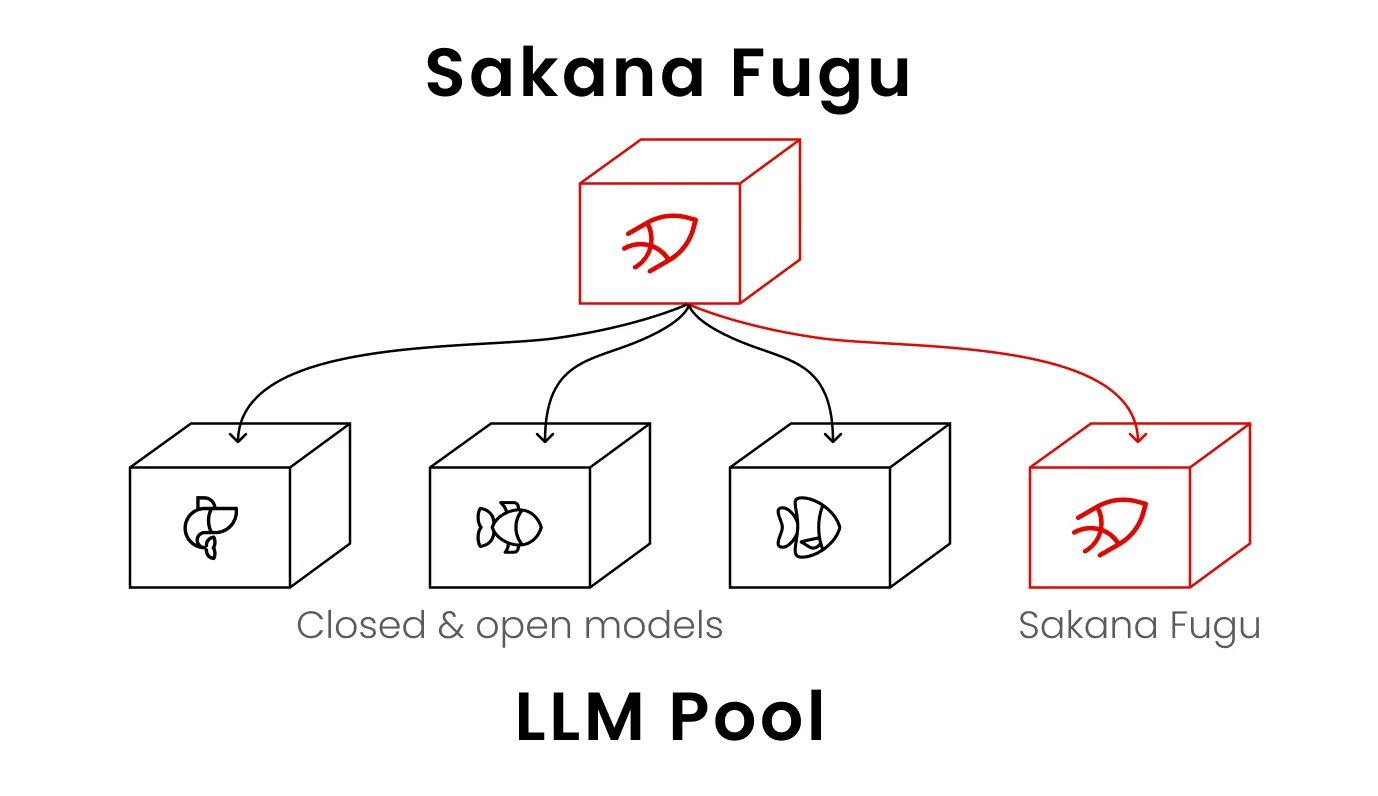
One important detail people miss: Fable 5 and Mythos Preview are not in Fugu's pool, because they aren't publicly accessible. Fugu only orchestrates models it can actually call. So when Sakana says Fugu matches Fable 5, it's saying a coordinated team of other public models can rival the frontier, which is a more interesting claim than it first looks.
How Fugu actually works under the hood
This is where Fugu earns the "not just a router" defense. It's grounded in two ICLR 2026 papers on learned model orchestration, and the mechanism is more involved than picking a model and forwarding the request.
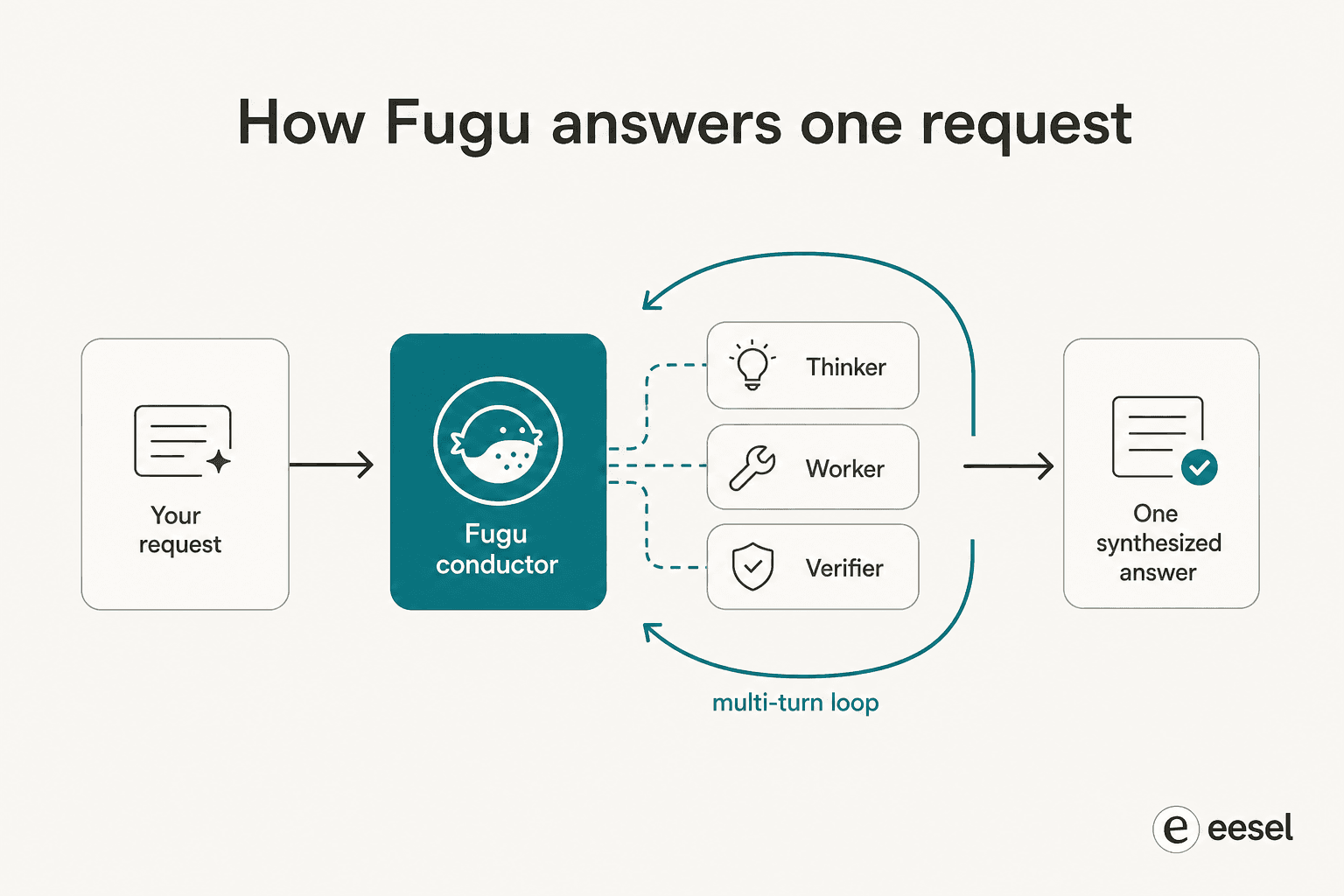
The first paper, TRINITY, uses a lightweight evolved coordinator that orchestrates multiple models over several turns, assigning each one a Thinker, Worker, or Verifier role and re-delegating as the task unfolds. The second, the Conductor, is trained with reinforcement learning to discover natural-language coordination strategies, basically learning how to write focused prompts and design how the models talk to each other so the pool beats any single member.
The two phrases worth holding onto are learned and multi-turn. Fugu doesn't follow a human-designed "first ask model A, then model B" script. It learned, through evolution and RL, to discover non-obvious collaboration patterns, and it loops, re-checking and re-routing rather than making one pass. That's why early users report it running for hours on a single task: 123 experiments over roughly 14 hours on an ML research problem, or nearly four hours autonomously reproducing a paper. It behaves a lot like the kind of agent loop we obsess over when building support automation, just pointed at frontier models instead of tools.
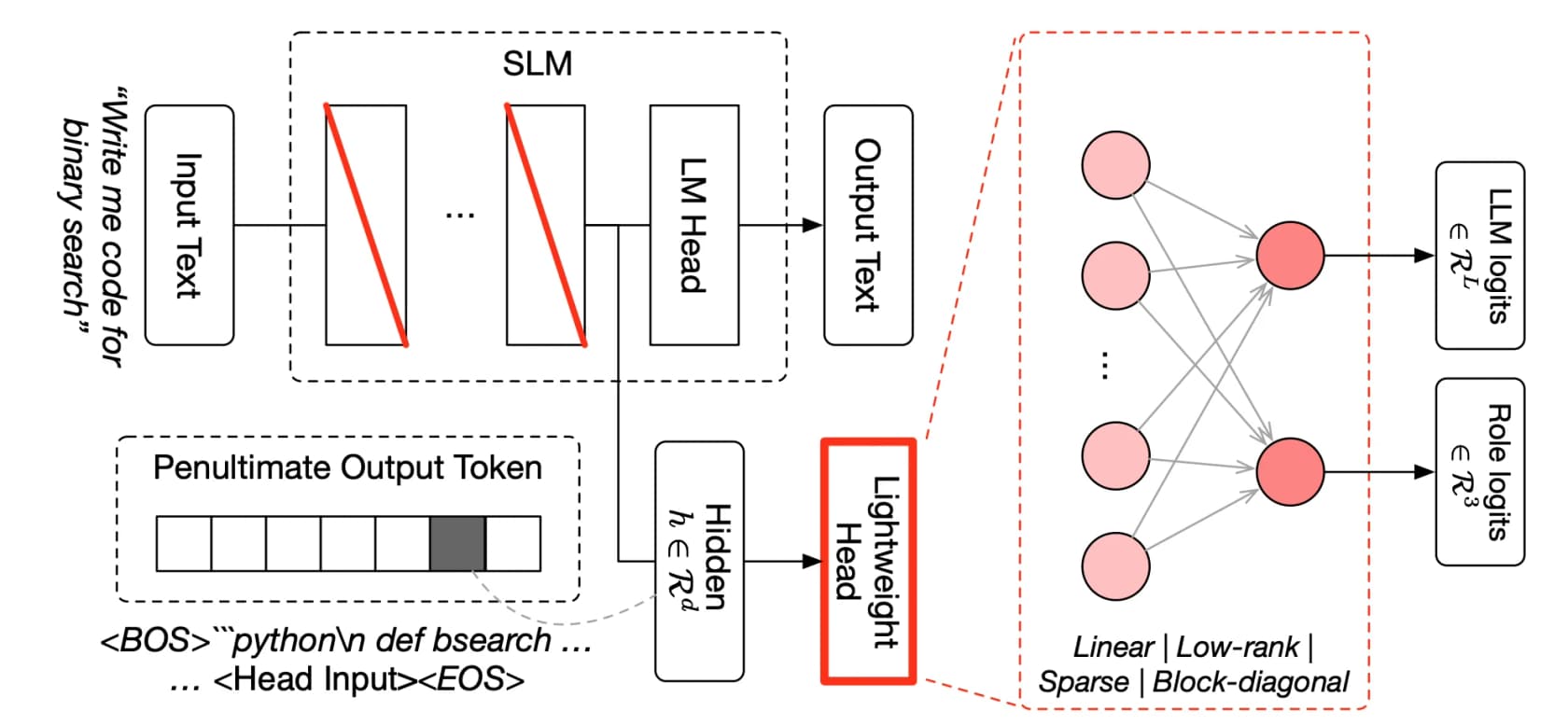
One trade-off to flag now: the routing is proprietary and opaque by design. You can't see which underlying model answered a given query. For some teams that's fine; for anyone with compliance needs, that black-box-in-front-of-black-boxes structure is a real consideration.
Fugu vs Fugu Ultra: which is which
Fugu ships as two models, both reachable through the same OpenAI-compatible API so you can switch between them without touching your integration. The difference is how many expert agents get coordinated, which is the lever between speed and quality.
| Fugu | Fugu Ultra | |
|---|---|---|
| Optimized for | Balanced performance and latency | Maximum answer quality |
| Agent pool | Coordinates a pool; you can opt models out | Deeper, fixed pool; no opt-out |
| Best for | Everyday coding, code review, chatbots | Hard, high-stakes, multi-step problems |
| Trade-off | Low latency, strong default | Higher quality at the cost of speed |
In plain terms: reach for Fugu when you want a responsive default, and Fugu Ultra when you have one gnarly problem and you're willing to wait for a better answer. Early users put Ultra to work on Kaggle competitions, paper reproduction, cybersecurity analysis, and patent investigations, which tells you the intended sweet spot is depth, not throughput.
The benchmarks: is it really shoulder-to-shoulder with Fable 5?
Sakana's headline claim is that Fugu models "surpass publicly accessible frontier models and are shoulder-to-shoulder with Fable 5 and Mythos Preview" across engineering, scientific, and reasoning benchmarks. The numbers back the narrower claim well.
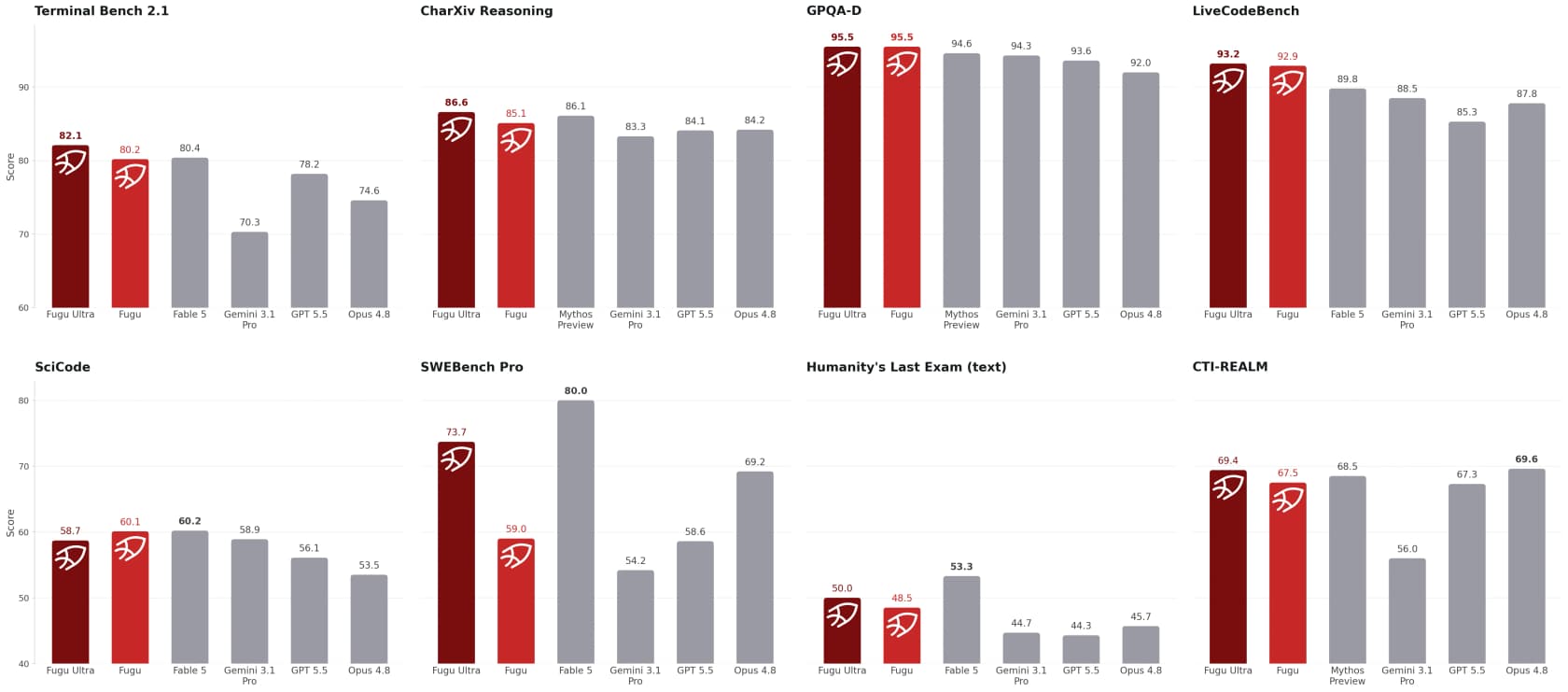
A few that stand out from Sakana's table: Fugu Ultra scores 73.7 on SWE-Bench Pro (vs 69.2 for Opus 4.8 and 58.6 for GPT-5.5), 93.2 on LiveCodeBench, and 95.5 on GPQA-Diamond, ahead of every public baseline shown. The qualitative demos are even more fun: Fugu reportedly beat three frontier models and a 2100-Elo Stockfish engine at blindfold chess, and in a time-series trading test grew $10,000 to $11,943 over a 50-week window, a +19.43% mean return that beat the others.
Two honest caveats. First, these are vendor-reported benchmarks, and the strongest models (Fable 5, Mythos) were excluded from the comparison as direct competitors rather than beaten head-to-head. Second, benchmarks measure peak capability on hard problems, not whether the thing is pleasant to use at 2pm on a Tuesday. As one beta user, slopdetector, put it on Hacker News:
"I used this during the beta. Beats GPT-5.5 xhigh on complex tasks. Since it's expensive and difficult to subsidize, use it for the most challenging problems... the results I got from fugu-ultra were impressive."
What Sakana Fugu costs (and the catch nobody mentions)
There are two ways to pay, and both include access to Fugu and Fugu Ultra.
| Subscription tier | Price | Usage allowance | For |
|---|---|---|---|
| Standard | $20/mo | Baseline | Lightweight daily use |
| Pro | $100/mo | 10× Standard | Focused working sessions |
| Max | $200/mo | 30× Standard | Heavy, long-running workloads |
(Worth noting: Sakana's pricing cards say Max is 30× Standard while a FAQ answer says 20×, so confirm the allowance before you commit.) There's also a pay-as-you-go token plan where Fugu Ultra is fixed at $5 input, $30 output, and $0.50 cached input per million tokens, rising to $10 / $45 / $1.00 once context passes 272K tokens. And there's a launch promo: subscribe before the end of July 2026 for a free second month.
Now the catch. Fugu is priced at the top of the pool it routes from, so the orchestration overhead has to justify itself against just paying for a frontier model directly. Several hands-on users felt it didn't. The sharpest version came from cortesi on Hacker News:
"For $200/month you get < 3 hours of use per week, the API is extremely slow, and the output quality in my tests is nowhere near Fable. It's nowhere remotely near usable as a day-to-day workhorse. Very disappointing."
That's one tester's experience, not a verdict, but it rhymes with several others reporting that the 5-hour limit runs out fast. If you've ever modelled AI agent costs against human agents, the lesson is familiar: the sticker price and the real cost-per-useful-task are different numbers.
Here's a quick gut-check on whether Fugu is even the right tool for what you're doing:
Is "just OpenRouter with extra steps" a fair criticism?
The single loudest reaction to Fugu's launch, repeated independently on Hacker News, X, and Reddit, was some version of "isn't this just OpenRouter?" It's a fair instinct, so let's take it seriously.
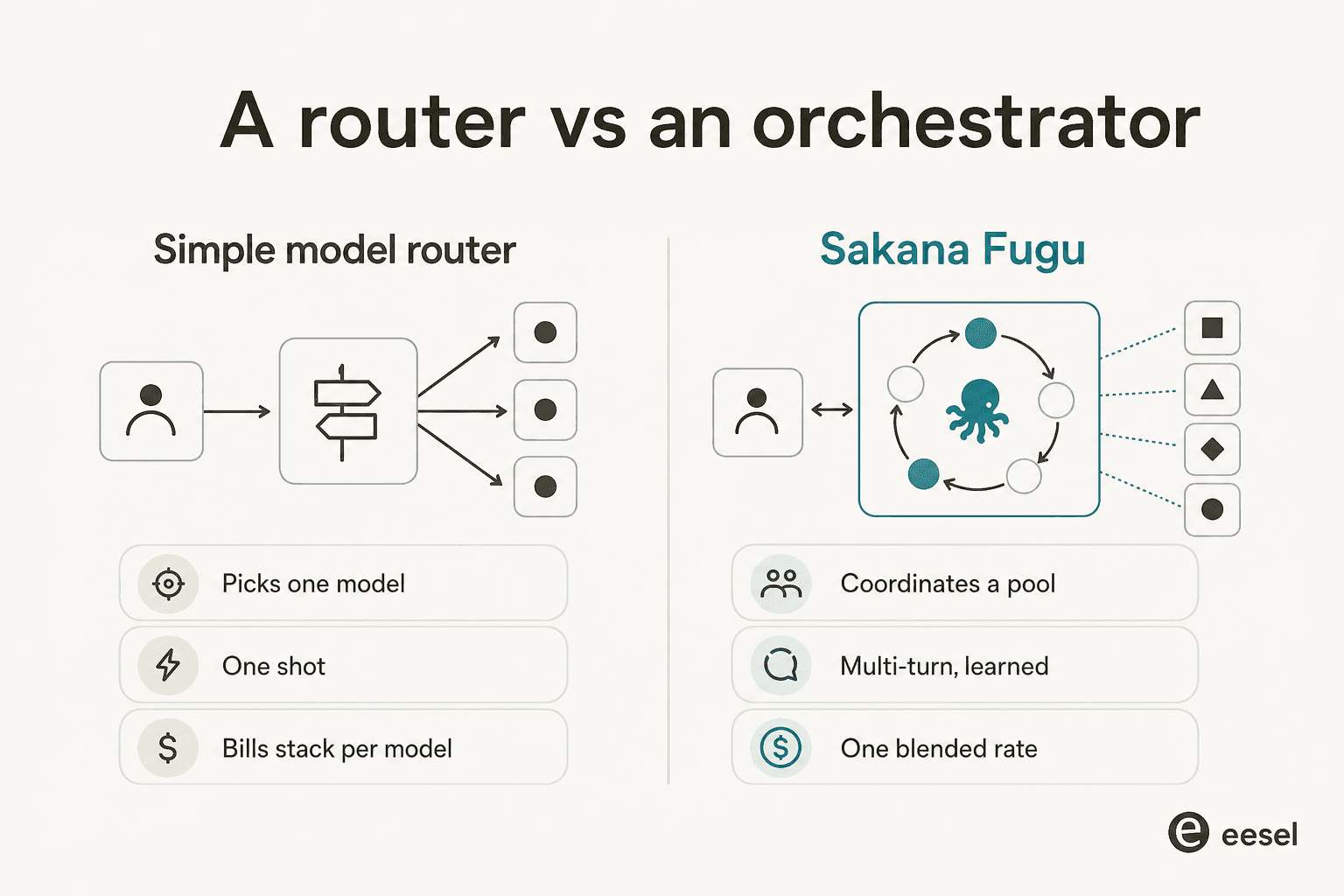
A plain router picks one model and forwards your request once. Fugu, at least on paper, does three things a router doesn't: it runs multiple turns, it has models verify each other's work, and it charges a single blended rate based on the top model involved rather than stacking each model's bill. So the architecture is real, and "advanced router" undersells the multi-turn, self-checking loop.
But the skeptics land a real punch on value, not architecture. As chenzhekl asked bluntly:
"But it's priced the same as frontier models. Why do I not directly pay for frontier models?"
That's the whole debate in one line. The architecture is more than a router; the open question is whether the extra coordination buys you enough to justify paying frontier prices for it. My take: on your hardest problems, plausibly yes; on everyday work, probably not. This is the same calculus that shows up in AI agent versus rule-based chatbot decisions, where more sophistication only pays off when the task is actually hard.
What people actually think of Sakana Fugu
Community sentiment, fairly read, is mixed-to-skeptical with a real pro camp. The boosters make the most interesting argument: that having models check each other is simply the right bet. As epsteingpt argued:
"Everyone's understood for months now that having different models check each other is the best path forward... If (big iff) the usage mechanics work out, then this is actually a really good anti-big-model strategy. They'll be incentivized for your success, not token-maximizing for their investors."
That incentive-alignment point is sharp, and it's a real reason to root for an orchestrator over a monolith. There's also a thread of respect for Sakana's research path. As quanto noted, David Ha took an unconventional route into AI research, and the lab's prior work (Evolutionary Model Merge, the AI Scientist, Transformer²) is consistently distinctive.
The skeptics, meanwhile, aren't being reflexive. Their objections cluster on cost, latency, and the opaque "single vendor replacing another single vendor" framing. And a couple of real-world notes worth knowing before you sign up: Fugu is not available in the EU/EEA yet, and some users flagged unease about Sakana's military contracts. If you're weighing it against the best AI agents for production, those are not footnotes.
Where a model that orchestrates models matters for support
Here's the part I care about most, because it's the job I actually do. Fugu's underlying idea, don't bet your workflow on one model, coordinate several and make them check each other, is exactly right for high-stakes automation like customer support. The wrong answer from a support bot isn't a leaderboard miss, it's a refund issued in error or a furious customer.
But there's a chasm between a raw, opaque model API and something you can safely put in front of customers. Fugu gives you orchestration; it doesn't give you your help center, your past tickets, your brand voice, your escalation rules, or a way to test the thing before it goes live. That's the layer that actually decides whether AI for customer service works, and it's why I'd reach for a purpose-built AI agent for customer service over wiring up a frontier API by hand. The orchestration question we obsess over in build versus buy is the same one Fugu is answering, just at a different layer of the stack.
Try eesel
eesel takes the lesson Fugu is built on and applies it where it actually has to be reliable: your support queue. Instead of handing you a model API, it's an AI agent that plugs into the helpdesk you already use (Zendesk, Freshdesk, Help Scout, Slack, and more) in minutes, trains itself on your past tickets and help center, and answers in your brand voice, no model-orchestration plumbing required.

The differentiator that matters most here is the part Fugu can't give you: a simulation mode that replays the agent against thousands of your historical tickets before it ever touches a live customer, so you see the resolution rate and exact replies up front rather than discovering them in production. Pricing is usage-based with no per-seat fees, so the cost scales with value rather than headcount. If you want to see what a customer-service AI looks like when the orchestration is invisible and the guardrails are built in, it's free to try.
Frequently Asked Questions
What is Sakana Fugu in simple terms?
How is Sakana Fugu different from OpenRouter?
How much does Sakana Fugu cost?
Is Sakana Fugu better than Claude or GPT-5.5?
What is Sakana Fugu best used for?
Can I use Sakana Fugu for customer support?
Is Sakana Fugu available everywhere?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








