What is DiffusionGemma?
DiffusionGemma is a model in Google's open Gemma family that generates text with a diffusion process rather than the autoregressive approach behind nearly every chatbot you've used. It was released by Google DeepMind on June 10, 2026 as an experimental open-weights model under Apache 2.0, with the official model card living on DeepMind's site.
Here's the headline spec sheet:
| Attribute | DiffusionGemma |
|---|---|
| Released | June 10, 2026 |
| Licence | Apache 2.0 (open weights) |
| Architecture | Built on Gemma 4, Mixture-of-Experts |
| Size | 25.2B total params, ~3.8B active per step ("26B A4B") |
| Generation | Denoises blocks of 256 tokens in parallel |
| Input / output | Multimodal in (text/image/video), text out |
| Speed | >1,000 tok/s on one H100, up to 4x faster than comparable AR models |
| Hardware | ~52GB VRAM at BF16, ~28GB at INT8, runnable from ~18GB quantised |
Most of those numbers come from MarkTechPost's launch coverage and the Spheron deployment guide, with the parallel-block detail from Digg's writeup. The "26B A4B" label is Google's shorthand: a 26B-class Mixture-of-Experts model that only fires about 3.8B parameters on any given step, which is part of why it's cheap to run fast.
The reason this is a big deal isn't the benchmark scores. It's that a frontier lab shipped a real, downloadable diffusion language model. For years, diffusion was the dominant method for images and video (think Midjourney, Sora) while text stubbornly stayed autoregressive, the same family that powers everyday assistants like ChatGPT and Claude. DiffusionGemma is one of the clearest signals yet that the text side is catching up.
How DiffusionGemma actually works
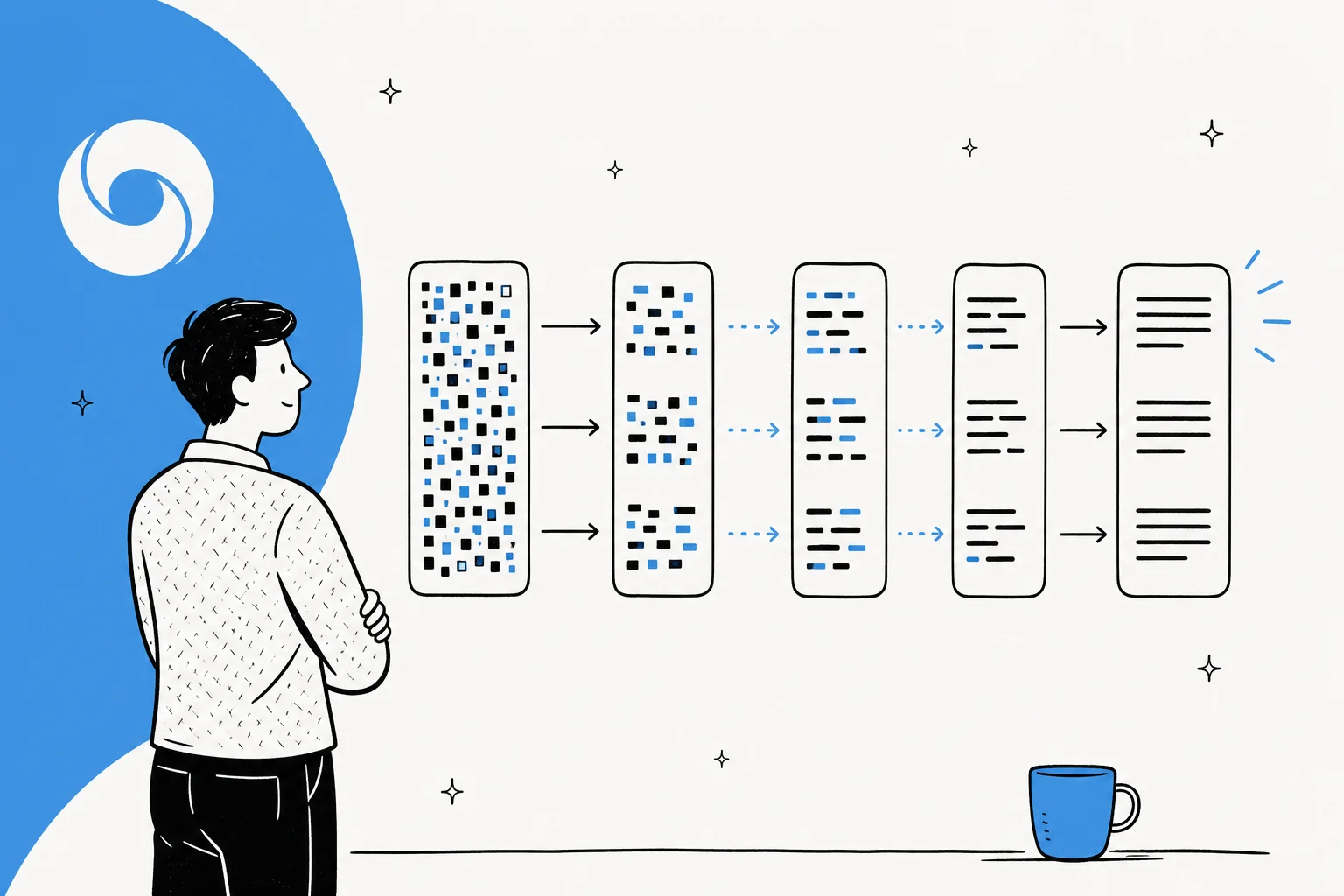
Standard large language models are autoregressive. As Inception Labs puts it, they "generate text left-to-right, one token at a time, where a token cannot be generated until all the text before it has been generated." Every word waits for the one before it, so a long answer means a long sequence of forward passes through billions of parameters. That's where the latency comes from.
Diffusion flips this. The dominant approach for text is masked diffusion: you start with a block of tokens that are all masked out, and a transformer predicts the unmasked versions, then refines its guess over a handful of passes. Google describes it as generating text "the way image diffusion works: rather than predicting text directly, the model learns to generate outputs by refining noise step-by-step, so it can iterate on a solution quickly and error-correct during generation."
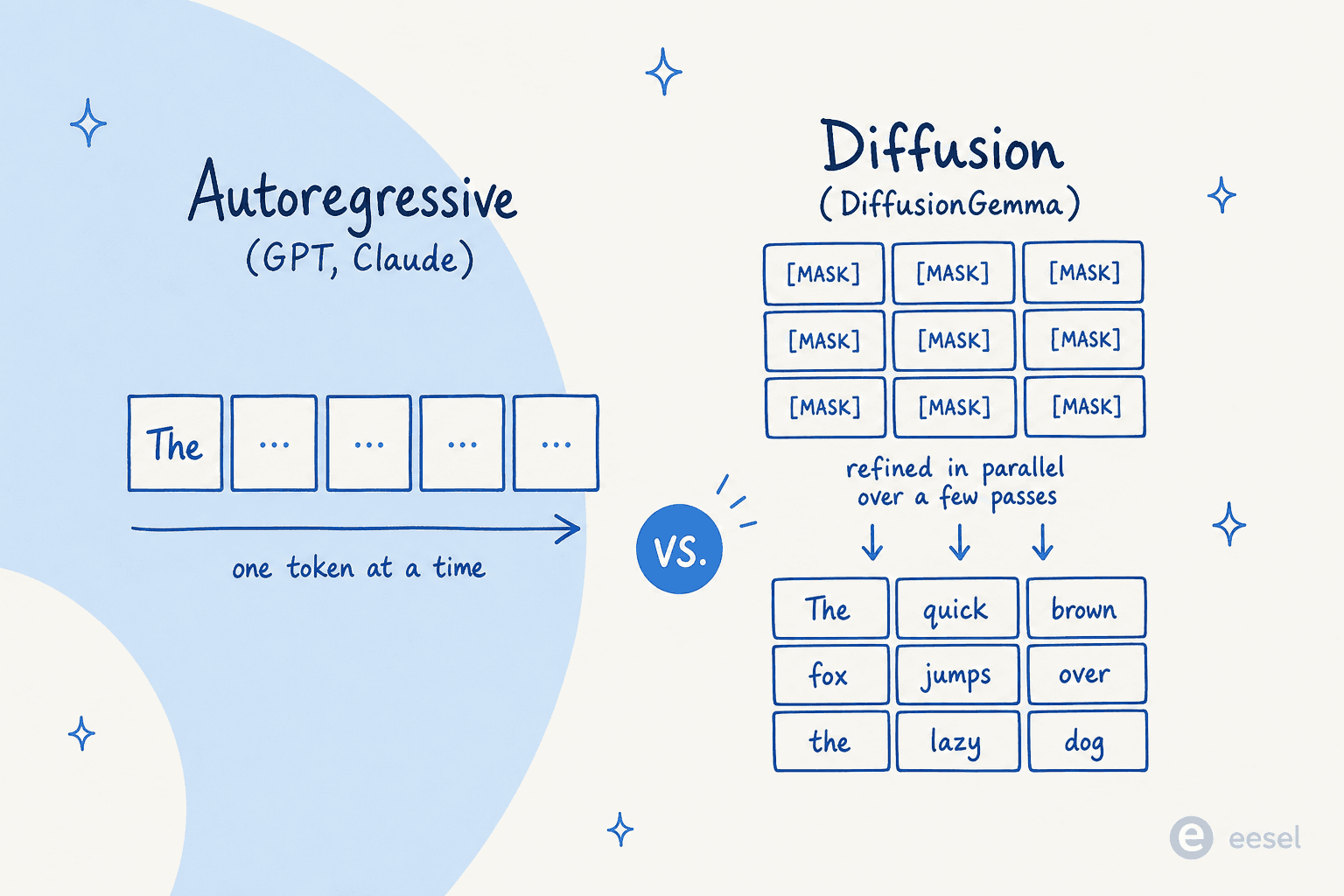
One clarification, because the name trips people up. Diffusion here doesn't replace the transformer; it replaces autoregression. As one widely-cited Hacker News comment from user synapsomorphy explained it:
"Diffusion isn't in place of transformers, it's in place of autoregression. Prior diffusion LLMs like Mercury still use a transformer, but there's no causal masking, so the entire input is processed all at once and the output generation is obviously different."
The practical upshots of generating in parallel are threefold: raw speed, the ability to error-correct mid-generation, and natural infilling (because the model can see context on both sides of a gap, it's good at editing the middle of a sequence, not just appending to the end). Andrej Karpathy flagged the novelty early, noting that diffusion "doesn't go left to right, but all at once. You start with noise and gradually denoise into a token stream."
DiffusionGemma vs Gemini Diffusion: don't conflate them
This one catches almost everyone, because Google shipped two text-diffusion things within about a year and gave them near-identical names.
Gemini Diffusion was shown at Google I/O in May 2025 as an experimental, waitlist-only model running on Google's infrastructure. You can't download it. DiffusionGemma, by contrast, is the open-weights one you can pull down and run yourself.
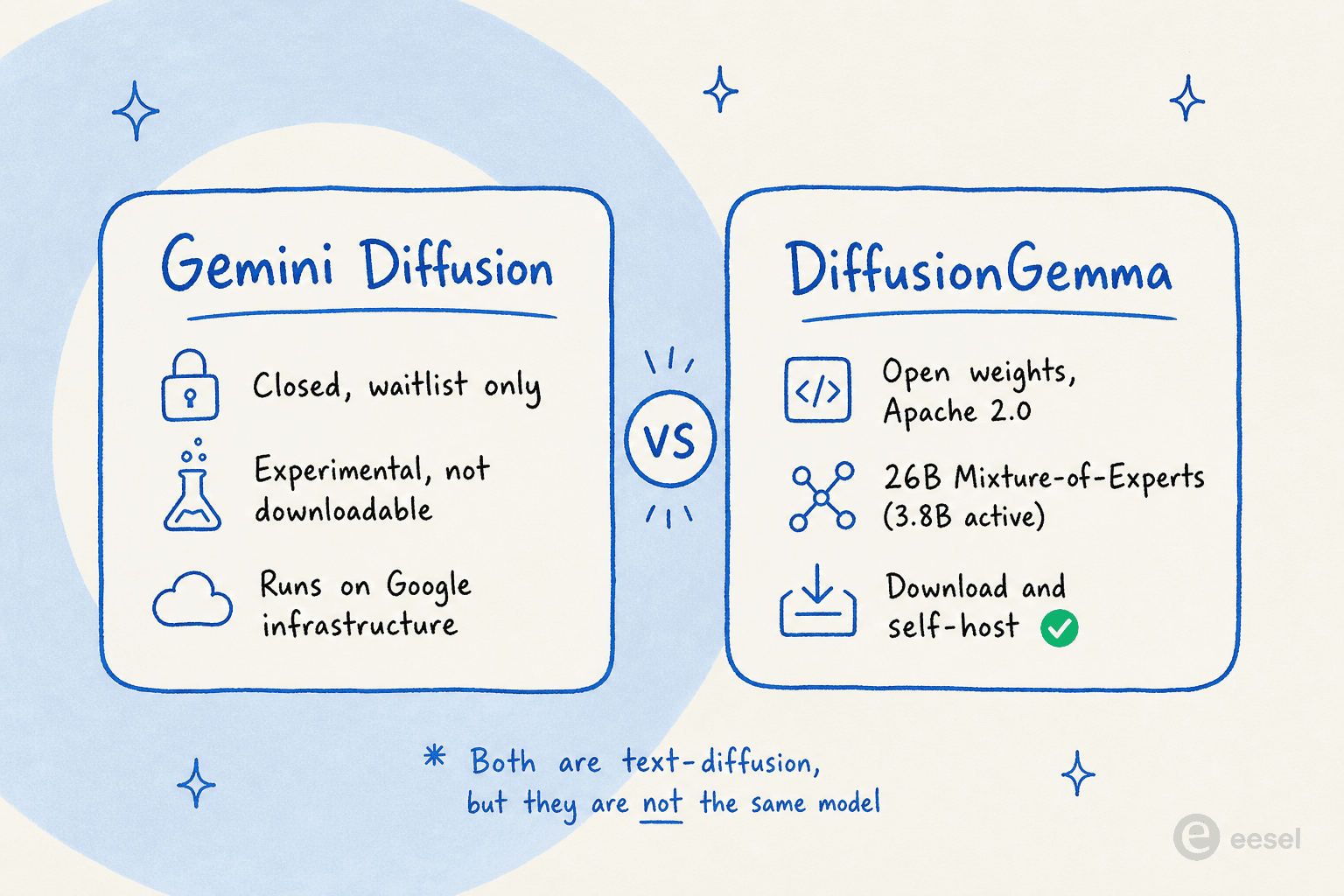
The fact that Google shipped both an experimental closed model and an open-weights release is itself the story: it's the strongest signal that diffusion language models are past the research-curiosity stage. When a frontier lab open-sources an architecture, it's betting other people will build on it.
The speed numbers (and why they're real-ish)
Speed is the entire pitch, so let's look at the numbers honestly. DiffusionGemma's >1,000 tok/s sits alongside its diffusion cousins, and the gap to autoregressive models is large:
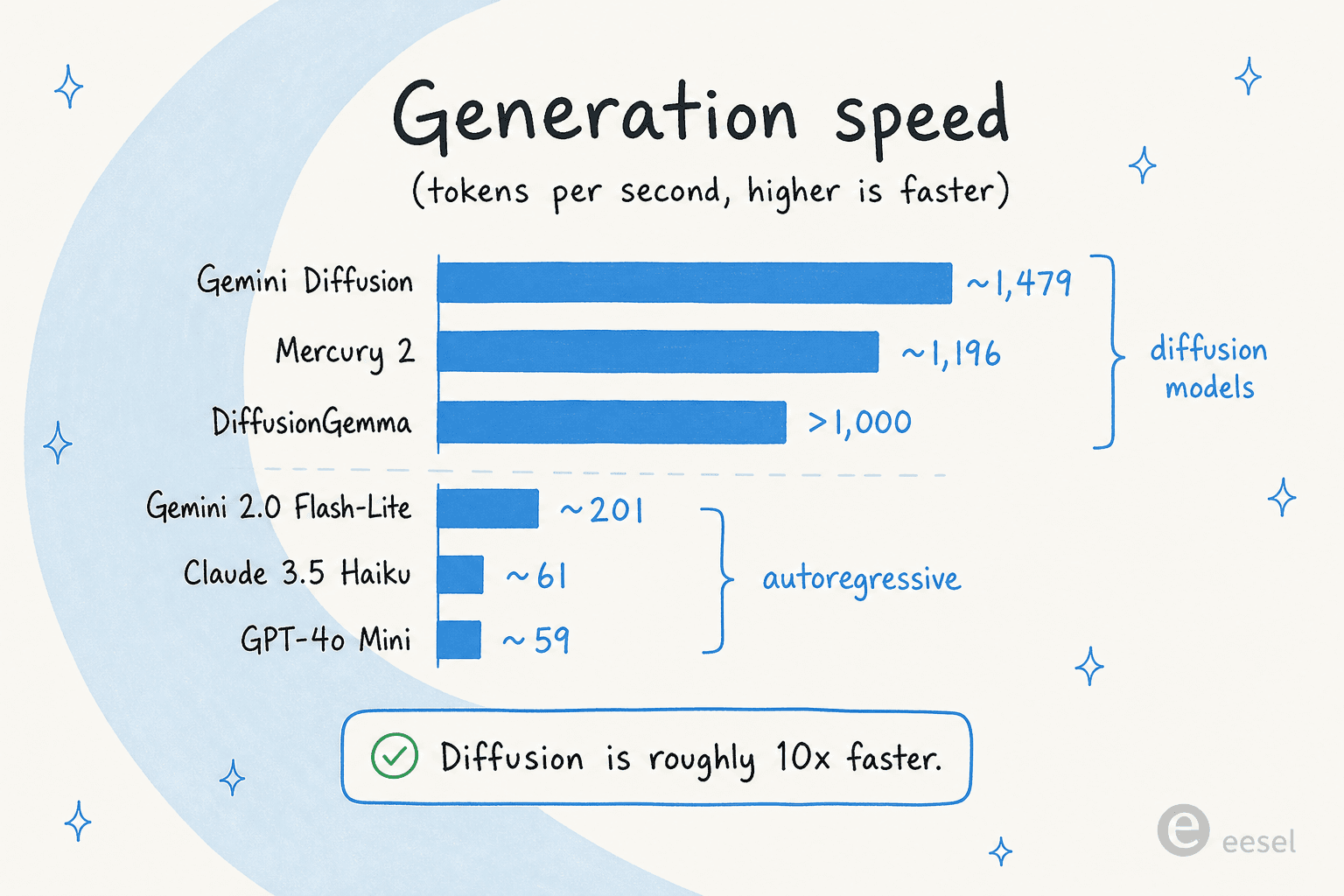
A few caveats keep this grounded. Almost every figure is measured on an NVIDIA H100, and most are vendor claims. The one independent yardstick in this space, Artificial Analysis, has corroborated the speed of Inception's Mercury models but not yet their quality. For DiffusionGemma specifically, the >1,000 tok/s and up-to-4x figures come from Google and partner write-ups like Yellow.com, not third-party benchmarks yet.
For comparison, the autoregressive models people actually use in production sit far lower on throughput: per Inception's own benchmarks, GPT-4o Mini runs around 59 tok/s and Claude 3.5 Haiku around 61, with speed-optimised Gemini 2.0 Flash-Lite at about 201. So the "roughly 10x faster" framing for diffusion holds, at least on paper.
Where it shines, and where it doesn't
The honest read is that diffusion really is faster on throughput-bound, parallelisable work, but autoregressive still wins for a lot of what production apps actually need. The best single source here is engineer Sean Goedecke's breakdown of diffusion's limitations, and it maps cleanly onto a decision.
Reach for diffusion when the job is high-volume and parallelisable: bulk summarisation, classification, reformatting, translation, or low-latency agent loops where a fast per-step response compounds. Code generation is a particularly good fit because diffusion's infilling nature matches how you edit code, generating the start and end of a block in the same pass.
Stick with autoregressive when you need short outputs (diffusion runs all its denoising passes regardless, so it does extra work to produce a six-token answer), long context windows (diffusion can't reuse the key-value cache as easily, so it recomputes attention over the whole context each pass), or hard chain-of-thought reasoning. On that last point, Goedecke makes the sharpest case:
"One reason to be broadly skeptical about the potential of diffusion models to reason is precisely that they do much less work per-token than autoregressive models do. That's just less space for the model to spend 'thinking.'"
Sean Goedecke, "Strengths and limitations of diffusion language models"
DiffusionGemma itself bears out the trade-off: it stays below standard Gemma 4 on every published benchmark. One engineer writing about production agent stacks put the historical knock on diffusion memorably, that early models "were fast in the way that a broken clock is fast, it doesn't matter how quickly you get the wrong answer" (dev.to). The quality gap is closing at small and mid scale, but it's still visible at the frontier.
The pragmatic move most teams will land on isn't replacement, it's routing: send simple, high-frequency steps (lookups, formatting, classification) to a fast diffusion model and reserve a frontier autoregressive model for deep reasoning. It's the same logic behind picking the right tool for a job rather than one AI helpdesk doing everything.
What DiffusionGemma means for customer support teams
Diffusion sounds perfect for support. Live chat and AI support agents are exactly the low-latency, user-facing case where the gap between a one-second and a several-second response decides whether the tool feels real-time or like "a service you wait on." For customer-facing copilots, sub-second response really can be the difference between adoption and abandonment.
But here's the thing we'd push back on: for a support team, the model architecture matters far less than the orchestration around it. Two caveats land directly on this use case.
First, real support answers lean on long context and retrieval, and long context is exactly diffusion's weak spot. A good answer isn't a from-scratch generation; it's a grounded answer over your knowledge base, ticket history, and policy docs. The retrieval and grounding matter more to answer quality than whether the final tokens came out left-to-right or in parallel, which is the heart of the RAG vs LLM question.
Second, quality and reliability beat raw speed for anything customer-facing. A faster model wired to stale knowledge or weak escalation rules just produces wrong answers faster. That's the broken-clock problem, applied to support.

So if you're a support leader reading about DiffusionGemma and wondering whether you need it: probably not directly. What you want is a platform that gets the grounding, guardrails, and helpdesk integrations right, and then quietly benefits from whatever model is fastest and best under the hood. Latency is one lever among many, and it's rarely the one holding your resolution rate back. The bigger question is usually the cost per ticket versus a human handling it.
Try eesel
eesel AI sells AI teammates that live inside your existing helpdesk (Zendesk, Freshdesk, HubSpot, Gorgias, Front) and handle tier-1 support by learning from your past tickets and help docs on day one. The reason it's relevant here: eesel is deliberately model-agnostic, so the architecture debate above is one you don't have to win. What it gets right is the orchestration that actually moves the numbers, like confidence-based routing that drafts instead of sending when it's unsure, and a simulation mode that runs against your past tickets so you can see coverage before going live. Gridwise saw 73% of tier-1 requests resolved in the first month, and pricing is usage-based from $0.40 per resolved ticket with no per-seat fees, so you pay for outcomes rather than GPU-hours.
Frequently Asked Questions
What is DiffusionGemma in simple terms?
Is DiffusionGemma the same as Gemini Diffusion?
How fast is DiffusionGemma compared to a normal LLM?
Can I use DiffusionGemma for customer support?
How much does DiffusionGemma cost to run?

Article by
Kira
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.







