
What is a diffusion-based AI model?
A diffusion model is a generative model that learns to build data by reversing a gradual noising process. The idea comes from physics: you define a chain of steps that slowly add random noise to real data, then train a network to reverse that process and reconstruct samples from the noise. The foundational work is Sohl-Dickstein et al. (2015) and the 2020 paper on denoising diffusion probabilistic models.
There are two halves. In the forward process, you take a real image and add a little Gaussian noise over and over until it becomes pure static. That part needs no learning; its only job is to manufacture training pairs. In the reverse process, a neural network learns to undo one step of noise at a time. At generation time you start from random noise and run the network repeatedly, each pass stripping away a bit more until a coherent result emerges.
Here is the intuition that makes it click. Imagine filming an ice sculpture melting into a puddle, then running the film backwards: starting from a shapeless puddle and, frame by frame, refreezing it into the sculpture. Because the model works on the whole canvas at every step, it can keep fixing earlier mistakes as it goes.
This is the technique that powers most modern image, video, and audio generation. Diffusion sits behind Sora, Midjourney, and Riffusion, along with DALL-E 2, Imagen, and Stable Diffusion. The throughline: they all start from noise and iteratively denoise toward a result, guided by your prompt.
How autoregressive LLMs generate text
To see why diffusion is a big deal for text, you need the contrast. Almost every large language model you have used, including ChatGPT, Claude, Gemini, and Llama, is an autoregressive model. It generates text left to right, one token at a time, and a token cannot be produced until everything before it exists.
Two consequences fall out of that design, and both matter for the comparison:
- Latency is sequential. Producing each token requires a full forward pass through billions of parameters, so long outputs (think long reasoning traces) directly inflate how long you wait and how much you pay.
- There is no going back. Once a token is out, it is fixed. The model cannot revise an earlier word in light of a later one. This unidirectional habit is blamed for quirks like the reversal curse, where a model knows "A is B" but stumbles on "B is A".
The upside is that variable-length output is easy: the model just emits an end-of-sequence token whenever it is done. That flexibility is one reason autoregression has stayed dominant for text.
How diffusion language models generate text differently
Diffusion language models (dLLMs) port the image recipe to text. Instead of pixels-from-noise, they do tokens-from-masks. Google DeepMind describes it plainly: rather than predicting text directly, the model learns to generate outputs by refining noise step by step, so it can iterate on a solution quickly and error-correct during generation.
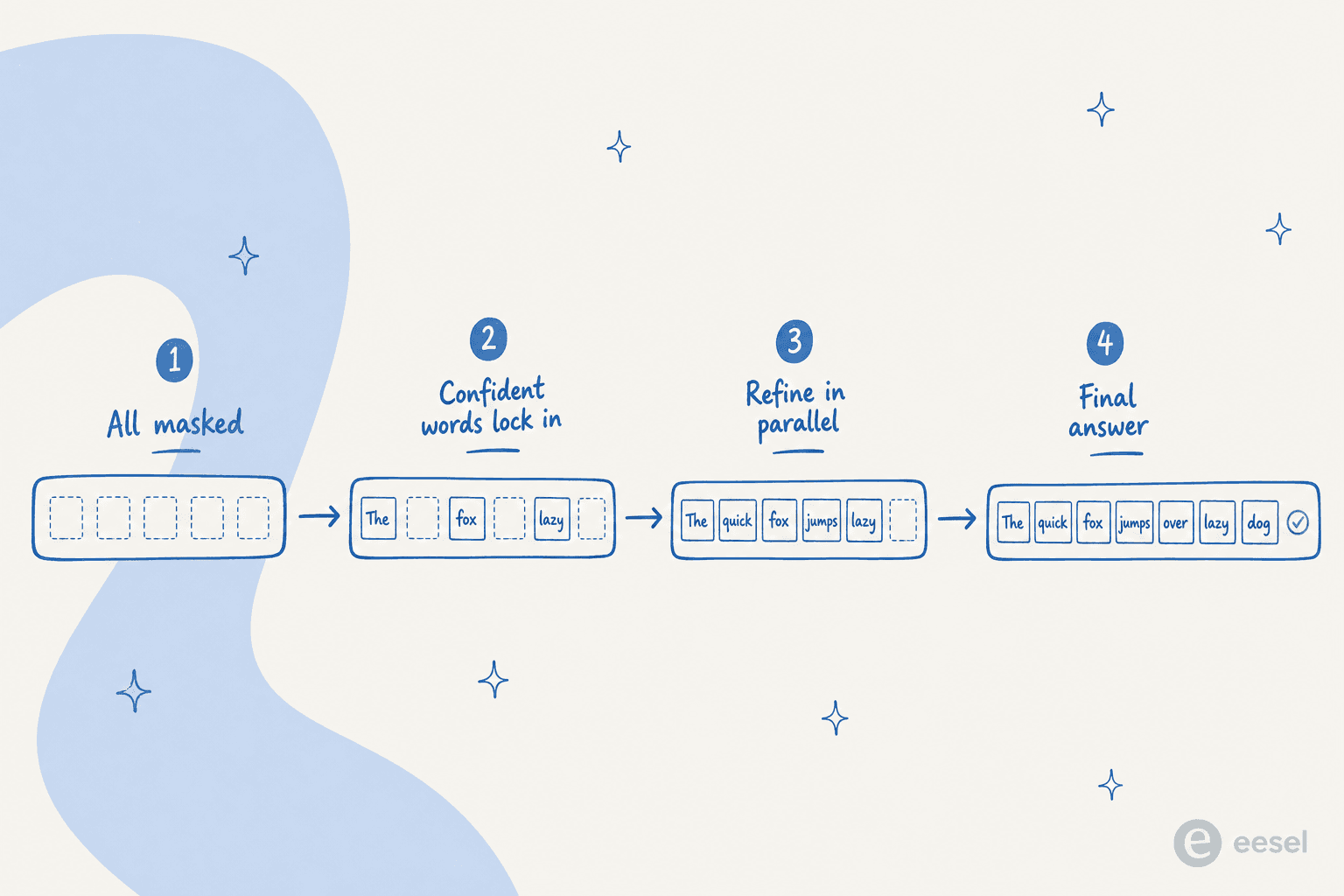
The dominant approach for text is masked diffusion. In LLaDA, an 8B open diffusion model, the forward process masks tokens and the reverse process uses a transformer "mask predictor" to fill in all the masked tokens at once, simulating diffusion from fully masked back to fully written. An earlier line, Diffusion-LM, used continuous diffusion over word vectors instead.
The headline difference is parallel decoding. A dLLM generates tokens in parallel rather than one at a time, and the underlying transformer can modify multiple tokens at once to globally improve the answer. Because the formulation is non-autoregressive, it also allows any-order generation: the model can lock in the words it is confident about anywhere in the sequence first, then fill in the rest.
One of the clearest explanations actually came from a developer on Hacker News, cutting through the "diffusion replaces transformers" confusion:
"Despite the name, diffusion LMs have little to do with image diffusion and are much closer to BERT and old good masked language modeling... in order to generate something from scratch, you start by feeding the model all [MASK]s... in 10 steps you'll have generated a whole sequence." nvtop, in the Gemini Diffusion discussion on Hacker News
That parallel, bidirectional view is also why a diffusion model can see context on both sides of a gap. LLaDA, for instance, beats GPT-4o on a reversal-poem-completion task, overcoming the reversal curse that trips up left-to-right models.
Autoregressive vs diffusion: the core difference
If you remember one picture from this post, make it this one. Autoregressive models build a sentence like a relay race, each word handing off to the next. Diffusion models build it like developing a Polaroid, the whole image surfacing at once and sharpening with each pass.
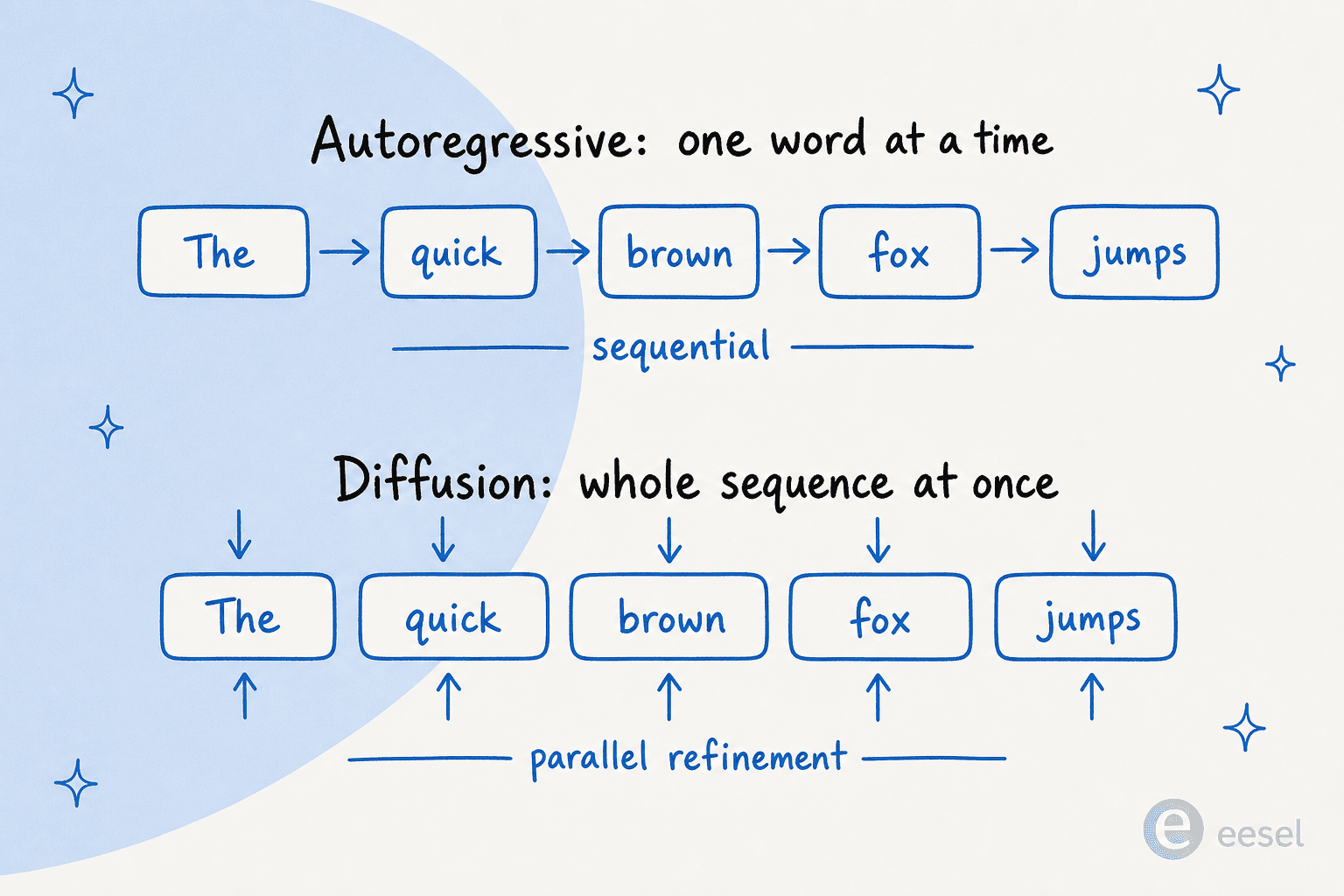
Here is how the two stack up on the dimensions a buyer actually cares about:
| Dimension | Autoregressive (GPT, Claude, Gemini) | Diffusion (Mercury, Gemini Diffusion) |
|---|---|---|
| Generation order | Left to right, one token at a time | Whole sequence in parallel, any order |
| Speed | Tens to ~200 tokens/sec | ~1,000 to ~1,500 tokens/sec |
| Can revise earlier tokens? | No, once emitted it is fixed | Yes, across denoising passes |
| Editing and infilling | Awkward (append-only) | Natural (conditions on both sides) |
| Hard reasoning | Stronger today | Trails, especially at frontier scale |
| Long context | More efficient (reuses KV cache) | Weaker (recomputes attention each pass) |
| Output length | Variable, flexible | Often fixed-length blocks |
| Ecosystem maturity | Five years of tooling | Early, fast-moving |
Note the symmetry: diffusion's wins (speed, revision, infilling) and its losses (reasoning depth, long context, maturity) both trace back to the same root cause. Working on the whole sequence in parallel is what makes it fast and editable, and also what makes long context and step-by-step reasoning harder.
The speed payoff, and the catch
The speed numbers are genuinely striking, and they are not all marketing. Developer and LLM blogger Simon Willison got off the Gemini Diffusion waitlist and tried it:
"The key feature then is speed. I made it through the waitlist and tried it out just now and wow, they are not kidding about it being fast." Simon Willison, first impressions of Gemini Diffusion
Here is how throughput compares across a few models, with the autoregressive baselines for context:
| Model | Type | Throughput (tokens/sec) | Source |
|---|---|---|---|
| Gemini Diffusion | Diffusion | ~1,479 (excl. overhead) | Vendor |
| Mercury 2 (Inception) | Diffusion | ~1,196 peak | Artificial Analysis |
| Mercury Coder Mini | Diffusion | 1,109 | Vendor, AA-corroborated |
| Gemini 2.0 Flash-Lite | Autoregressive | ~201 | Per Inception |
| Claude 4.5 Haiku | Autoregressive | ~89 | Per Inception |
| GPT-5 Mini | Autoregressive | ~71 | Per Inception |
Two things to keep honest here. First, most throughput figures are measured on an NVIDIA H100 and many are vendor claims; Artificial Analysis is the main independent source, and it has corroborated Mercury's speed but not yet its quality. Second, the speed advantage is real but conditional. High-quality generation usually needs many denoising steps, and naively cutting steps degrades quality sharply, so the speed has to be spent carefully.
And the quality gap is still visible, especially on hard tasks. Gemini Diffusion scores 40.4% versus 56.5% on GPQA Diamond, and 69.1% versus 79.0% on Global MMLU against Flash-Lite, even though it leads on some code and math benchmarks. The honest read from an engineer who works on production agent stacks is worth quoting, because it names the historical problem directly:
"[Earlier diffusion LMs] were fast in the way that a broken clock is fast
it doesn't matter how quickly you get the wrong answer." vainkop, "Mercury 2 and the End of Autoregressive Monopoly"
His verdict for teams today is measured: this is a "follow closely and prepare to move fast" moment, not a "rewrite your agent stack immediately" one.
The models leading the charge
The space went from research curiosity to shipping products fast. The funding signal is loud: Inception Labs, founded by Stanford's Stefano Ermon, raised $50M in November 2025 from a strategic list that includes Nvidia, Microsoft's M12, Databricks, and Snowflake, plus angels Andrew Ng and Andrej Karpathy. When the infrastructure players bet, they think the speed is serveable.
| Model | Who | Status | What stands out |
|---|---|---|---|
| Mercury / Mercury 2 | Inception Labs | API live, $0.25 / $0.75 per 1M tokens | First commercial diffusion LLM; ~1,196 tok/s |
| Gemini Diffusion | Google DeepMind | Experimental, waitlist | ~Gemini 2.0 Flash-Lite quality at several times the speed |
| DiffusionGemma | Google DeepMind | Open weights (Apache 2.0), June 2026 | 26B mixture-of-experts; >1,000 tok/s, below Gemma 4 on quality |
| LLaDA 8B | ML-GSAI (research) | Open weights | MMLU 65.9, roughly matching Llama3 8B |
| Dream 7B | HKU NLP + Huawei | Open weights | Dominates planning tasks (Sudoku 81.0 vs Qwen's 21.0) |
A quick clarification, because the names are confusingly similar: "Gemini Diffusion" (closed, waitlist) and "DiffusionGemma" (open weights) are two different Google releases. The first is an experimental hosted model shown at Google I/O 2025; the second is a downloadable 26B model released on June 10, 2026 under Apache 2.0, which generates by denoising blocks of 256 tokens in parallel and stays below standard Gemma 4 on every published benchmark. Speed for quality, openly traded.
The recurring pattern across all of these: a 10x-plus throughput advantage that narrows the quality gap at small and mid scale (LLaDA roughly matching Llama3 8B, Mercury competitive on code) but still shows at the frontier. The primary use case today is code generation and low-latency, agentic loops, where parallel decoding's speed compounds.
Why diffusion-based AI models matter for businesses
Speed is not a vanity metric once you put a model inside a product. The clearest framing comes from production experience: latency in autoregressive systems compounds in chains.
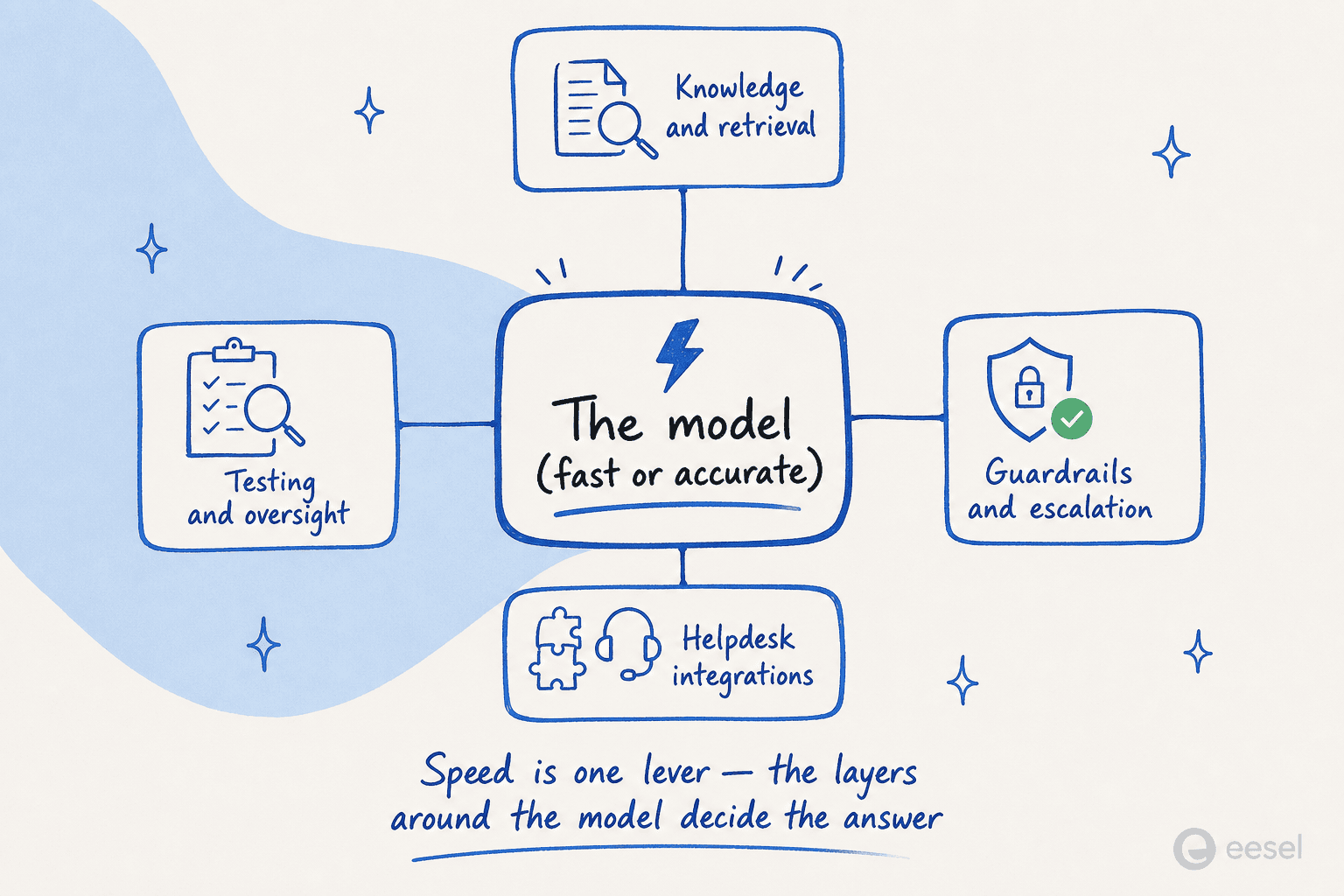
As one engineer described it, a single agent step that calls the model three times (reason, plan, act) is three sequential passes; chain a few of those together and you are at seven or eight seconds, which is "not a real-time agent, that's a slow batch job". Faster per-step generation makes deeper AI agent chains affordable. The same piece notes teams currently cap chain depth at three to five steps to stay under their SLA; with diffusion-speed inference, ten-step chains start to look viable.
A few concrete places the speed pays off:
- Real-time chat and copilots. Sub-second responses are, as that engineer puts it, "the difference between adoption and abandonment" for an assistant layer in a SaaS product.
- High-volume batch text. Summarization, classification, reformatting, and translation are throughput-bound and parallelizable, which is exactly where diffusion shines.
- Coding assistants. Diffusion's infilling nature fits code edits, generating the start and end of a block in the same pass and editing the middle.
Then there is cost. Faster generation on the same hardware means lower inference cost per token, and Inception's co-founder argues the approach "performs more computation per unit of memory transferred," which opens new ways of reducing AI inference costs on older hardware. For teams running hundreds of thousands of agent calls a day, that compounds. Mercury 2's public pricing of $0.25 per million input tokens and $0.75 per million output is genuinely cheap.
But here is the part most coverage skips. For most production apps, autoregressive models remain the default, and for good reason: they handle long context more efficiently, they reason more deeply (diffusion does less work per token, so there is less room to "think"), and they have five years of tooling behind them. The pragmatic move is not replacement but routing: send the simple, high-frequency steps (lookup, format, classify) to a fast diffusion model, and reserve frontier autoregressive models for the deep reasoning. Compare that to the economics of AI agents versus human agents and the appeal is obvious: do more of the cheap work cheaply.
What it means for AI customer support
Customer support looks like the perfect diffusion use case at first glance. Live chat and AI support agents are exactly the low-latency, user-facing scenario where the one-second-versus-several-seconds gap decides whether the experience feels responsive or sluggish. A faster model should mean snappier replies in your AI chatbot.
The reframe worth sitting with: for a support team, the model architecture matters far less than the orchestration around it. A real support answer is almost never a from-scratch generation. It is a grounded answer over your knowledge base, ticket history, and policy docs. That puts diffusion's weakness, long context handling, squarely in the path of the support use case, and it means retrieval quality, knowledge freshness, and guardrails drive the answer far more than whether the final tokens were emitted left-to-right or in parallel.
Put bluntly: a faster model wired to stale knowledge or weak escalation rules just produces wrong answers faster. The broken-clock problem, applied to support. That is also why AI chatbot problems so rarely come down to the base model and so often come down to grounding, testing, and the metrics you actually track.
The genuinely useful advice, then, is to stay model-agnostic. Pick a layer that lets the underlying model improve underneath you, whether that is a faster diffusion model next year or a smarter autoregressive one. The teams who will benefit most from diffusion are the ones who built on solid orchestration first and treated the model as a swappable component.
Try eesel
This is exactly how eesel AI is built. Rather than betting on one model architecture, eesel is the orchestration layer: it learns from your past tickets, help docs, and tooling on day one, then drafts replies, triages, and escalates across the helpdesk you already use, with confidence-based routing so low-confidence answers stay as drafts rather than going live.

The differentiator that matters for this topic: a simulation mode that runs the agent against your past tickets so you can see coverage and fix gaps before going live, which is how you stop a fast model from confidently shipping wrong answers. It runs across 100+ integrations and 80+ languages, so whatever model is fastest or smartest next year, your support setup keeps working. You can try eesel free, no credit card needed.
Frequently Asked Questions
What is a diffusion-based AI model in simple terms?
How are diffusion language models different from autoregressive LLMs like GPT or Claude?
Are diffusion-based AI models actually faster than normal LLMs?
Should my business switch to a diffusion language model?
Does the model architecture matter for AI customer support?

Article by
Kira
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.







