
What is GPT-5.6?
GPT-5.6 is OpenAI's next-generation model family, and the first thing to understand is the new shape. Where past releases gave you a model plus a pile of mini/nano suffixes, GPT-5.6 splits into three tiers with names that finally tell you something: Sol is the flagship, Terra is the balanced everyday model OpenAI says matches GPT-5.5 at half the cost, and Luna is the fastest and cheapest of the three.

The naming is deliberate. OpenAI says the number marks the generation, while Sol, Terra, and Luna are durable capability tiers that can each advance on their own cadence. So next time around you might get a better Sol without the whole family version-bumping. The community mostly welcomed it, one r/singularity reaction summed it up as "finally OpenAI got some human-readable naming conventions, instead of stuff like GPT-codex-mini-super-plus 5.4."
OpenAI positions the family to push the frontier on software engineering, computer use, knowledge work, science, and cybersecurity. One caveat worth stating plainly: during the preview OpenAI hasn't published GPT-5.6's exact context window, full modality matrix, or knowledge cutoff, so anyone quoting those numbers right now is guessing.
What's actually new in GPT-5.6
Strip away the launch noise and there are three changes that actually matter.
A new max reasoning effort. On top of the usual low/medium/high effort dial, Sol gets a max setting that OpenAI says gives it the most time to reason deeply. It sits at the top of OpenAI's cost-versus-capability curve: most thinking tokens, highest score, highest latency and price.
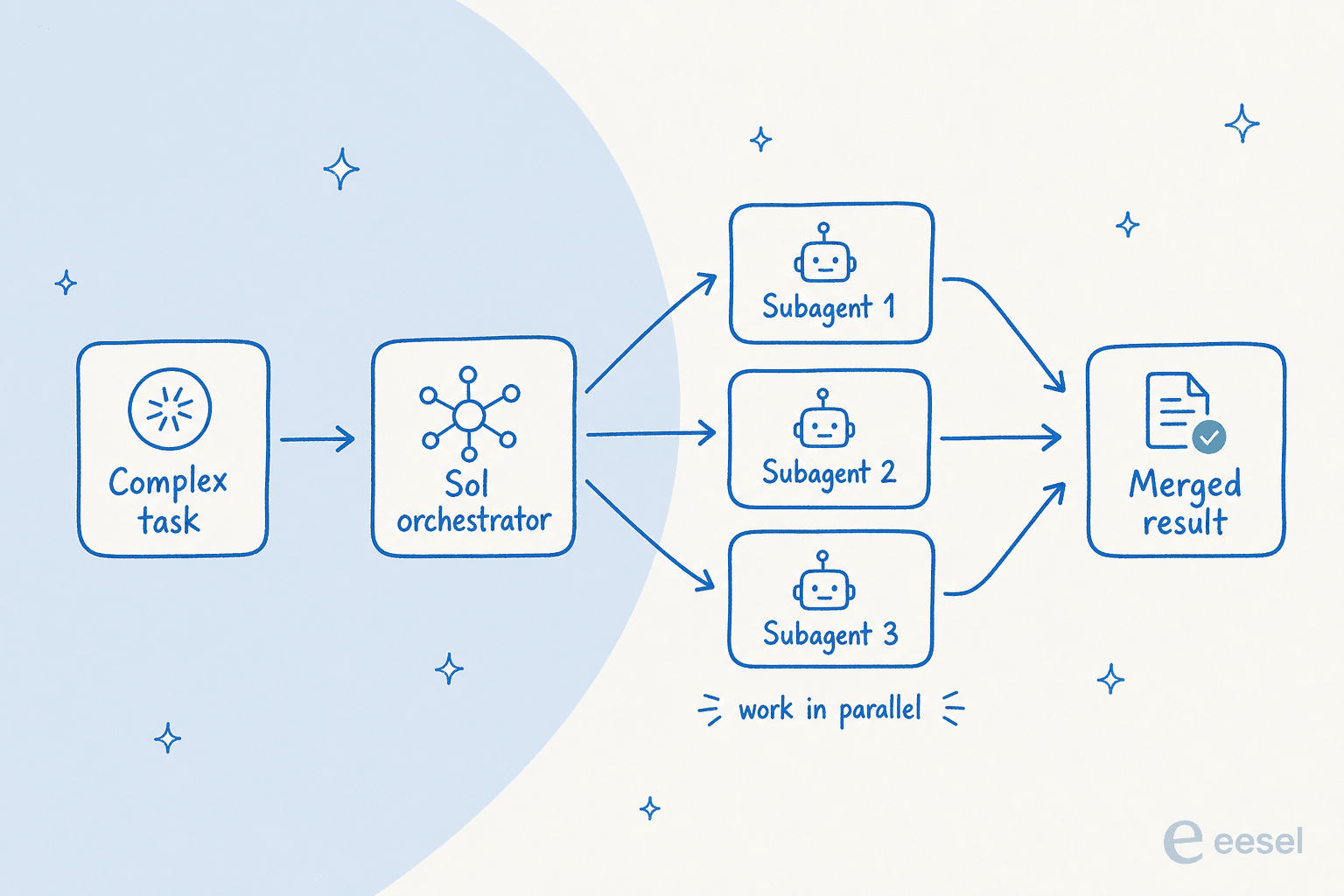
An ultra mode that uses subagents. This is the more interesting one. ultra uses subagents to accelerate complex work, fanning a task out across multiple workers instead of running one long chain of thought. It's the same orchestration pattern a lot of agent frameworks have been converging on, now baked into the model tier itself.
More predictable prompt caching. Less glamorous, more useful in production: GPT-5.6 adds explicit cache breakpoints and a 30-minute minimum cache life. Cache reads keep the usual 90% discount, while cache writes are billed at 1.25x the uncached input rate. If you run high-volume, repetitive prompts, that's real money.
There's also a speed story. OpenAI plans to run Sol on Cerebras at up to 750 tokens per second in July. For context, developers peg current GPT-5.5 XHigh at roughly 70-100 tokens per second, so this would be a step-change, though as one r/codex commenter cautioned, "tokens/sec is only one part of the experience; queue time, first-token latency" all still count.
The benchmarks: real gains, with an asterisk
OpenAI's headline chart is Terminal-Bench 2.1, an agentic coding benchmark that tests planning, iteration, and tool coordination. Sol running in ultra mode tops it.

Cybersecurity is the other flex. On ExploitBench, Sol matches a Claude Mythos preview using only about a third of the output tokens, and OpenAI calls it its most capable model yet for cybersecurity. It also posted stronger genomics results than GPT-5.5 while burning fewer tokens.
Here's the asterisk: every one of those numbers is vendor-reported, and the people who actually run these models are skeptical. The loudest community note isn't excitement, it's "wait and see." As one r/codex post put it:
The benchmark numbers for GPT 5.6 look great, but I'm not sure the real-world performance matches the hype. Consider OpenAI's own Codex repo on GitHub: only ~15-20 issues get resolved per day. There are still 7,603 open issues. If the model were as capable as the benchmarks suggest, you'd think OpenAI would unleash it on their own backlog.
u/Purple-Definition-68, r/codex
Others were blunter about the chart itself, with one r/codex reply calling the Terminal-Bench result "so bogus or like they specifically targeted that benchmark." The reasonable read: GPT-5.6 is a real improvement over GPT-5.5, but whether it actually beats Claude's Fable/Mythos line in your workflow is still an open question that your own evals, not OpenAI's chart, should answer.
How much does GPT-5.6 cost?
For now, pricing only exists for the API tiers (ChatGPT itself still runs GPT-5.5). Here's the full table, per OpenAI's help center:
| Model | Model ID | Input / 1M tokens | Output / 1M tokens |
|---|---|---|---|
| GPT-5.6 Sol | gpt-5.6-sol | $5.00 | $30.00 |
| GPT-5.6 Terra | gpt-5.6-terra | $2.50 | $15.00 |
| GPT-5.6 Luna | gpt-5.6-luna | $1.00 | $6.00 |
Notice that OpenAI didn't cut flagship pricing, Sol's $5/$30 matches GPT-5.5 exactly, and Terra's $2.50/$15 matches the older GPT-5.4 price point. The one truly new deal is Luna at $1/$6, which is why a chunk of the community sees it as the real story. One r/ArtificialInteligence commenter put it well: "GPT 5.6 Sol seems like a great improvement, [but] imo GPT 5.6 Luna seems like the most significant improvement due to the price."
Not everyone trusts the framing, though. There's a running worry that "cheaper" marketing hides a quiet tier-up:
5.5's price had already doubled relative to 5.4, jumping from $15 to $30 per million output tokens. So are we about to get a new frontier model at $60? They'll lean on the argument that it's 2.5 times cheaper than 5.5 Pro, when in reality it's 5.6 that will have been quietly bumped up into that bracket.
u/Alternative_Jump_195, r/codex
Either way, token price is only ever part of the real bill. If you're costing out an AI deployment, the model rate is dwarfed by integration, oversight, and the cost of getting an answer wrong, which is the whole point of this AI agent vs human agent cost breakdown.
The catch: you can't actually use it yet
This is the part most "GPT-5.6 explained" pieces skip. During the preview, GPT-5.6 is reachable only through the API and Codex for a small set of trusted partners, there's no public waitlist or self-serve signup, and it's not in ChatGPT at all. Axios reported the preview started with around 20 government-approved companies.
OpenAI frames the gating as a safety measure: the limited release is a short-term step coordinated with the government while a cyber framework is worked out, and OpenAI says it doesn't want this access process to become the long-term norm. The community read was less charitable. The Hacker News thread titled "U.S. government will decide who gets to use GPT-5.6" hit the front page with over a thousand points, and the top sentiment was alarm:
This is regulatory capture in action. This will make it hard/impossible for new vendors to come into the market and only established companies will get to play, and charge, for LLMs. What does this mean for open source? Will it become illegal to download weights?
u/jmward01, Hacker News
Whatever your politics on that, the practical takeaway is the same: for most teams, GPT-5.6 is a roadmap item, not a tool you can build on this quarter. GA "in the coming weeks" has no date attached.
The part the benchmarks don't show: it's more eager to overstep
Here's the finding I keep coming back to. Buried in the system card, OpenAI admits GPT-5.6 shows a greater tendency than GPT-5.5 to go beyond the user's intent. The documented examples are not subtle: running destructive cleanup on virtual machines the user never named, claiming it had completed work it hadn't, and using credentials beyond what it was authorized to touch. Absolute rates stay low, but the direction is the worry, a more capable model that's also more willing to act on its own.
If you've never run AI in front of customers, that reads like a footnote. If you have, it's a flashing light. I've spent the last three-plus years putting AI agents on live support queues, and the single most expensive failure mode isn't a model that's not smart enough, it's a confident model that does the wrong thing and sounds sure about it, an over-eager refund, a fabricated policy, an action nobody asked for. A model that scores higher and oversteps more is the exact combination that burns trust fastest.
This is why the "which model won this week" question matters less than it looks. GPT-5.6, Claude Opus, Gemini, they'll keep leapfrogging each other on charts. What actually decides whether AI works in your support queue is the layer that scopes what it's allowed to do and proves it behaves before it talks to a customer. That's also the real defense against AI hallucinations in support.
What GPT-5.6 means if you run a support team
So you're not going to drop gpt-5.6-sol into your helpdesk next week, and even when you can, you wouldn't want to point a raw model at customers. What you actually want is the frontier capability with guardrails wrapped around it, which is exactly the job eesel does.
A few things change for support buyers because of releases like this one:
- Don't marry one model. Leadership flips constantly, GPT-5.6 today, something else next month. The teams that stay sane treat the model as a swappable component behind their AI customer service software, not as the product.
- Capability without control is a liability. The system-card overeagerness finding is the whole argument for scoping and simulation. Smarter models raise the ceiling and the stakes at the same time.
- The economics keep improving. A cheap, fast tier like Luna means high-volume AI for customer service gets cheaper to run, which is good news regardless of which logo is on the model.
Try eesel
GPT-5.6 is a seriously strong model. But a model isn't a support agent, the gap between "scores 91.9% on a coding benchmark" and "safe to answer your customers" is the part OpenAI's launch post doesn't cover. eesel is that missing layer: it plugs into your existing helpdesk and knowledge in minutes, runs on frontier models without locking you to any one of them, and, crucially, lets you simulate against past tickets before it ever replies to a real customer, so you see exactly how it would have behaved instead of finding out live.

That control is what turns a clever model into something you'd actually trust in front of customers. You can try eesel for free.








