
Resumo
A gestão de escalações de IA é a parte de um lançamento de suporte com IA que decide o que a IA não toca. Faça isso certo e a IA vai silenciosamente limpar a carga repetitiva de nível 1 enquanto sua equipe só vê os tickets que genuinamente precisam de uma pessoa. Faça errado e você ou vai afogar os agentes em rascunhos ruins de IA ou vai deixar um bot com som confiante adivinhar durante uma disputa de reembolso.
Três coisas fazem funcionar: um limiar de confiança para que a IA só responda o que tem certeza, um conjunto claro de gatilhos de escalação (o cliente pede um humano, tom irritado, reembolsos, faturamento, segurança da conta) e uma transferência quente que passa todo o contexto para que o humano não comece do zero. A ordem importa: deflita o que puder, escale o que não puder, e nunca deixe a IA inventar uma resposta para evitar a transferência.
Trabalho na fila de suporte da eesel todos os dias, então este é o fluxo de trabalho em que vivo. Abaixo está como pensamos sobre escalação, os gatilhos que configuraríamos e como montá-lo sem perder o histórico de tickets.
O que a gestão de escalações realmente significa quando a IA está no processo
Durante anos, "escalação" significava que um agente de nível 1 sinalizava um ticket para o nível 2 ou um gerente. A forma era humano para humano. Uma vez que um agente de IA fica na frente da fila, a escalação ganha um novo primeiro passo: a IA decidindo se responde de forma alguma ou passa o ticket para uma pessoa.
Essa decisão é todo o jogo. Um agente de IA que escala facilmente demais é apenas uma camada de roteamento cara que irrita os clientes com "deixe-me buscar alguém para você." Um que escala raramente demais começa a inventar respostas, e uma resposta errada em uma pergunta de faturamento custa muito mais do que uma resposta lenta. O trabalho da gestão de escalações de IA é ajustar essa linha: lidar com tudo que a IA consegue resolver bem e encaminhar limpiamente todo o resto para um humano com contexto suficiente para que a transferência pareça perfeita para o cliente.
Fica bem ao lado de duas coisas sobre as quais escrevemos bastante: triagem de tickets, que é a IA lendo e classificando um ticket recebido, e roteamento de tickets, que é enviá-lo para o lugar certo. A escalação é a decisão específica de roteamento que traz um humano.
A razão honesta pela qual as equipes erram nisso
Aqui está a experiência que moldou como construímos isso. Vimos um bot com som confiante entregar silenciosamente a resposta errada para um cliente, completamente certo de si mesmo, em um tom que tornava o erro difícil de detectar. Esse é o modo de falha que realmente assusta os líderes de suporte, e é por isso que agora simulamos cada lançamento contra os tickets históricos reais de uma empresa antes de uma única resposta ao vivo sair. Você vê exatamente onde a IA teria adivinhado, e você corrige as lacunas antes que um cliente as sinta.
Os compradores com quem converso sentem isso no estômago antes de conseguir nomear. Um líder de CX em uma marca DTC de suplementos com cerca de 7.000 tickets do Gorgias por mês colocou toda a tese em uma frase: "A IA nunca vai conseguir responder 100% das perguntas... Preciso de uma IA que só lide com os tickets em que está confiante e todos os outros, deixe-os em paz." Isso não é um pedido de funcionalidade. Essa é toda a tarefa da gestão de escalações, dita em voz alta.
O erro que a maioria das equipes comete é tratar a escalação como uma reflexão tardia, algo que você adiciona depois que a IA está "funcionando." Na realidade, é o que torna seguro ativar a IA. Então vamos começar com a parte que todos subestimam: saber quando transferir.
Quando um agente de IA deve escalar?
Não há uma única regra. Há um conjunto de gatilhos, e a arte está em decidir quais deles acionam uma transferência no seu contexto. Esses são os seis que configuraríamos em quase qualquer fila.
- O cliente pede um humano. Não negociável, e o que as equipes esquecem de tornar instantâneo. No momento em que alguém digita "posso falar com uma pessoa?", a IA deve transferir sem resistência.
- A confiança da IA é baixa. Se o modelo não tem certeza, não deve adivinhar. Este é o limiar de confiança fazendo seu trabalho, e é o gatilho mais importante de todos.
- O tom fica irritado ou chateado. Um cliente que escala raramente é o momento para deixar uma IA praticar empatia. Encaminhe para alguém que possa ler a situação.
- O tópico é de alto risco. Reembolsos, disputas de faturamento, qualquer coisa legal, qualquer coisa relacionada a uma solicitação de segurança de conta. Esses são tickets onde uma resposta errada tem consequências reais, então pertencem a um humano por padrão.
- Um SLA está prestes a ser violado. Se um ticket ficou esperando e um prazo se aproxima, a escalação baseada em SLA deve colocá-lo na visão de um humano antes que o tempo acabe.
- A IA já tentou e falhou. Se duas tentativas não resolveram, uma terceira também não vai. Transfira em vez de entrar em loop.
Alguns desses são baseados em regras e outros são decisões de julgamento, o que explica por que o próximo ponto é tão importante. Você não pode escrever uma instrução if para "o cliente parece chateado." Você precisa que a IA avalie sua própria certeza.
Como funciona o roteamento baseado em confiança
Este é o motor por trás da gestão de escalações, e vale a pena entender mesmo que você nunca toque nas configurações. Antes de a IA enviar qualquer coisa, ela avalia o quanto tem certeza da resposta. Essa pontuação decide o caminho.
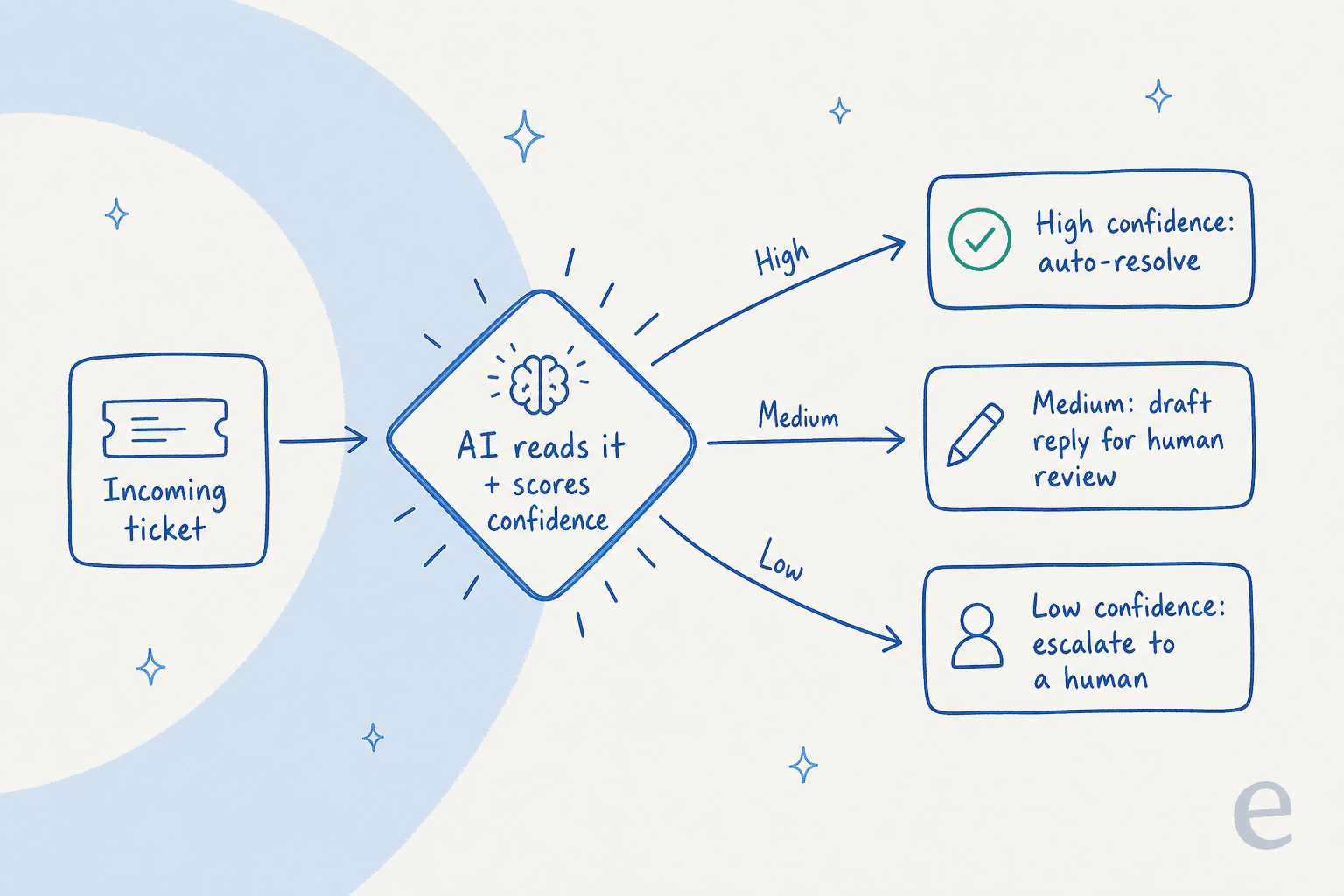
Alta confiança resolve por conta própria. Confiança média rascunha uma resposta e a deixa como nota interna para um humano aprovar, que é o padrão de assistência ao agente. Baixa confiança aciona a transferência. A beleza disso é que mapeia de forma limpa para o quão cauteloso você quer ser: um fintech regulado pode colocar a barra alta e deixar quase tudo apenas como rascunho, enquanto uma equipe de e-commerce de alto volume pode deixar a IA resolver as perguntas sobre status do pedido que responde corretamente milhares de vezes por dia.
O que você está realmente ajustando é a lacuna entre a deflexão de tickets e o excesso de alcance. Defina o limiar muito baixo e a IA deflite coisas que não deveria. Defina muito alto e você comprou um auto-responder caro que escala tudo. O número certo não é um palpite, que é o argumento inteiro para a simulação: execute a IA contra seus últimos milhares de tickets, veja a taxa de resolução prevista em cada limiar e escolha a linha que mantém a qualidade onde você precisa.
É aqui também que as mensagens de fallback ganham seu lugar. Quando a confiança cai e uma transferência não é imediata, um bom fallback ganha tempo com elegância em vez de deixar o cliente olhando para um carregador. O comportamento de timeout e fallback é a rede de segurança embaixo de todo o fluxo.
Como é uma transferência limpa de verdade
Decidir escalar é metade do trabalho. A outra metade é como você transfere, e é aqui que a maioria das configurações falha silenciosamente. Uma transferência fria joga o cliente de volta ao início da fila e faz com que ele reexplique tudo. Uma transferência quente carrega toda a conversa consigo.
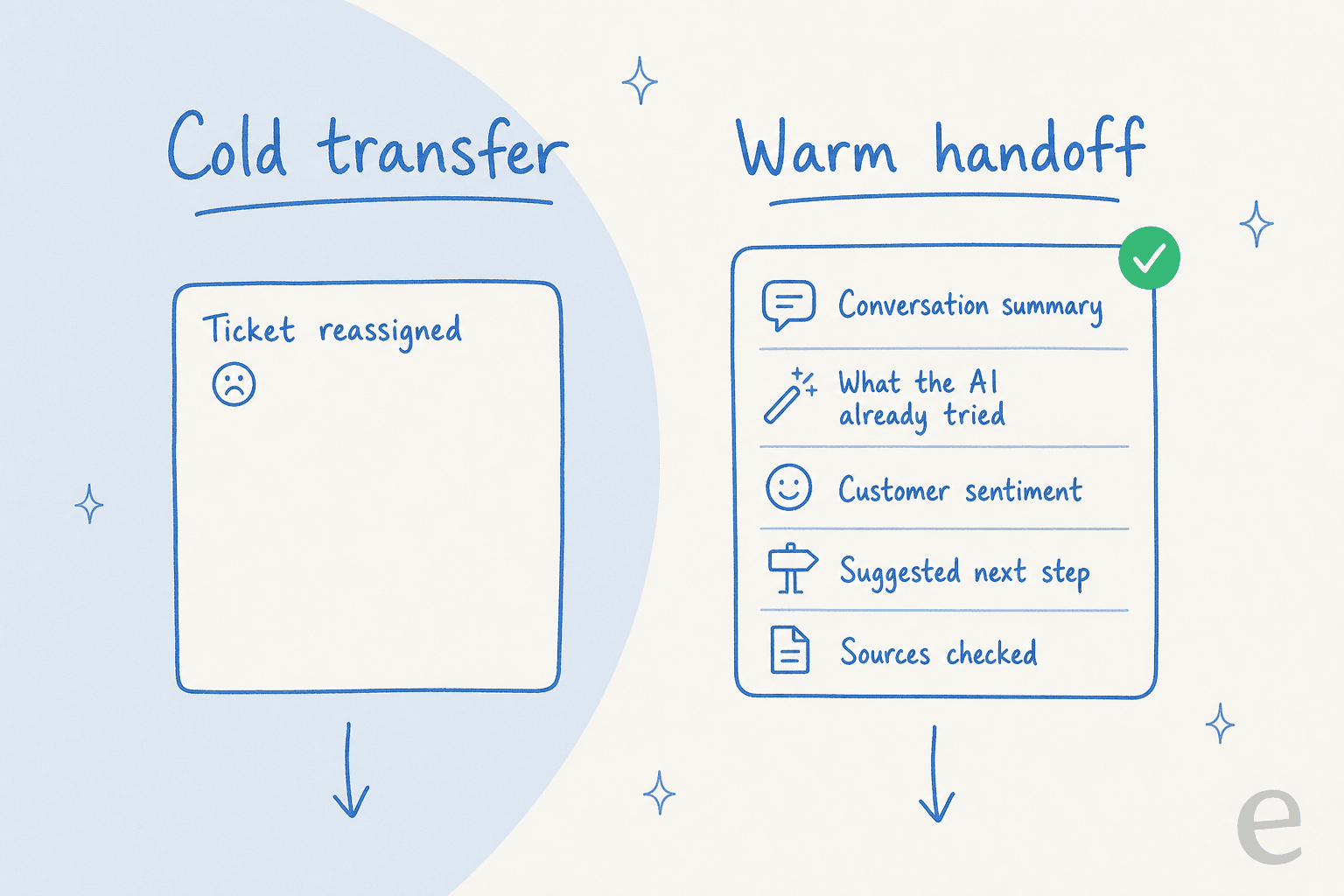
A diferença na experiência do cliente é como o dia e a noite. Bem feita, a transferência é invisível: o humano continua no meio do fio, já sabe o que foi dito e simplesmente segue em frente. Aqui está um exemplo real do chat do site de um cliente. Um usuário final no chat de uma ferramenta de SEO fez duas perguntas de como fazer, obteve respostas limpas de autoatendimento e depois digitou "Posso falar com um humano?" A IA transferiu no instante em que foi perguntada, com o fio completo anexado. Dois desviados, um escalado, zero atrito. Isso é deflexão e autoatendimento e transferência de conversa funcionando como um único movimento.
A mecânica importa aqui, e vale a pena acertar por plataforma. As mensagens de transferência de bot para agente, preservar o contexto de transferência e saber se você está roteando para um especialista ou um gerente mudam como o agente receptor experimenta. No Gorgias, por exemplo, há uma forma específica de controlar a experiência de transferência no chat para que a transição seja lida como suave.
Um detalhe que as equipes ignoram: onde o humano é notificado. Se seus agentes vivem no Slack, a transferência deve notificá-los lá com contexto, não apenas reatribuir silenciosamente um ticket que eles precisariam ir buscar.
Mantenha o cliente informado enquanto espera
A escalação nem sempre é imediata. Às vezes o humano precisa contatar um terceiro, esperar por um parceiro de pagamento ou verificar uma conta. A lacuna entre "transferido" e "resolvido" é onde os clientes ficam ansiosos e reabrem tickets, o que piora a fila.
Há um padrão interessante para isso que nem sequer precisa de uma base de conhecimento. Um fintech com o qual trabalhamos, com cerca de 7.000 a 8.000 tickets escalados por mês, usa a IA para manter os tickets escalados quentes: ela envia atualizações tranquilizadoras enquanto a equipe aguarda parceiros externos, para que o cliente sempre saiba que seu ticket está ativo. A IA não está resolvendo nada ali. Está gerenciando a espera, que é uma parte da gestão de escalações que quase ninguém planeja.
Como configurar a gestão de escalações de IA
Você não precisa de um motor de regras nem de um projeto de seis semanas. Aqui está a ordem em que realmente faríamos isso.

- Conecte seu helpdesk e conhecimento. Aponte a IA para seus tickets passados, documentos de ajuda e macros. Anos de tickets resolvidos se tornam conhecimento no primeiro dia, o que permite à IA julgar a confiança em primeiro lugar. O eesel funciona no Zendesk, Freshdesk, Gorgias, Front, Help Scout, HubSpot e Jira para mesas de suporte internas.
- Decida o que a IA nunca toca. Exclua as categorias que você quer manter humanas por padrão. Um líder de suporte com quem conversei disse claramente: "Há certos tickets que não quero que passem pela IA." Isso é uma configuração, não um compromisso.
- Defina seu limiar de confiança e gatilhos. Defina o que resolve automaticamente, o que cria rascunho para revisão e o que escala. É aqui que vivem as regras de escalação e o tratamento avançado de escalações.
- Simule antes de entrar em produção. Execute a IA contra milhares de seus tickets reais passados para ver exatamente o que teria resolvido, rascunhado e escalado, e com que qualidade. Corrija as lacunas, depois ative.
- Ajuste a partir do ciclo de feedback. Cada vez que um agente edita ou rejeita um rascunho, isso é um sinal. A IA deve aprender com isso para que a linha de transferência para um humano fique mais precisa com o tempo.
Você pode configurar a maior parte disso em linguagem natural em vez de um construtor de regras, que é a parte que surpreende as pessoas.

Os erros que eu observaria
Alguns padrões que vejo com frequência suficiente para destacar:
- Tratar a escalação como um fallback para um bot quebrado. Se a IA escala 80% dos tickets, o problema não é a escalação, é que a base de conhecimento é fraca. Primeiro corrija as lacunas de conhecimento.
- Transferências frias. Reatribuir um ticket sem contexto apenas move o trabalho, não o reduz. Sempre passe o fio.
- Sem lista de exclusão. Deixar a IA tentar com cada tipo de ticket, incluindo os que sempre deveriam ser humanos, é como você obtém o problema da resposta confiante-errada.
- Medir deflexão sem qualidade. Uma alta taxa de resolução não significa nada se as resoluções estiverem erradas. Observe ambas, e apoie-se em ferramentas de assistência ao agente enquanto constrói confiança.
Bem feita, a gestão de escalações é o que permite que você aumente a automação sem baixar a qualidade. Também é a resposta honesta para a questão de IA versus suporte humano: nunca foi um ou outro. A IA lida com volume, humanos lidam com julgamento, e a escalação é a costura entre eles.
Como prova de que pode funcionar em escala, uma empresa de análise de economia compartilhada no Zendesk cruzou a linha rapidamente:
"No primeiro mês, o eesel está resolvendo 73% dos nossos pedidos de nível 1. O eesel oferece fácil implementação e configuração do Zendesk. Nossa equipe implementou e obteve resultados rapidamente durante nosso teste de 7 dias."
Kim Simpson, Gridwise (agente de helpdesk eesel AI)
Os 73% que mantiveram são seguros apenas porque os outros 27% escalaram de forma limpa. Esse é o ponto central.
Experimente o eesel
O eesel AI foi construído exatamente em torno dessa costura entre IA e humano. Aprende com seus tickets e documentos passados desde o primeiro dia, roteia por confiança para que só lide com o que tem certeza e entrega o resto para sua equipe com o fio completo anexado. A parte que indicaríamos primeiro: você pode simular tudo isso contra milhares de seus tickets históricos reais antes de entrar em produção, para que você veja sua taxa de resolução e seu comportamento de escalação antes que um cliente o faça. É precificação baseada em uso sem taxas por assento, e você pode excluir qualquer tipo de ticket da automação em linguagem natural.

Se você estiver avaliando opções de forma mais ampla, nosso resumo de agentes de suporte ao cliente de IA e nossas notas sobre ferramentas de triagem de tickets de IA são boas próximas leituras.
Perguntas frequentes
O que é gestão de escalações de IA?
Quando um agente de IA deve escalar um ticket para um humano?
Como funciona o roteamento baseado em confiança?
O que é uma transferência limpa de IA para humano?
Posso impedir que a IA toque certos tipos de tickets?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.








