
Prefiro que a IA nao diga nada a dizer algo errado
Trabalho na equipe de suporte do eesel, entao leio respostas de IA profissionalmente, as nossas e as que os clientes nos encaminham de ferramentas das quais estao escapando. O padrao que me mantem acordado nao e o agente que tropeça e faz uma pergunta esclarecedora. E o agente que inventa uma resposta limpa, confiante, completamente errada e a envia antes de alguem olhar.
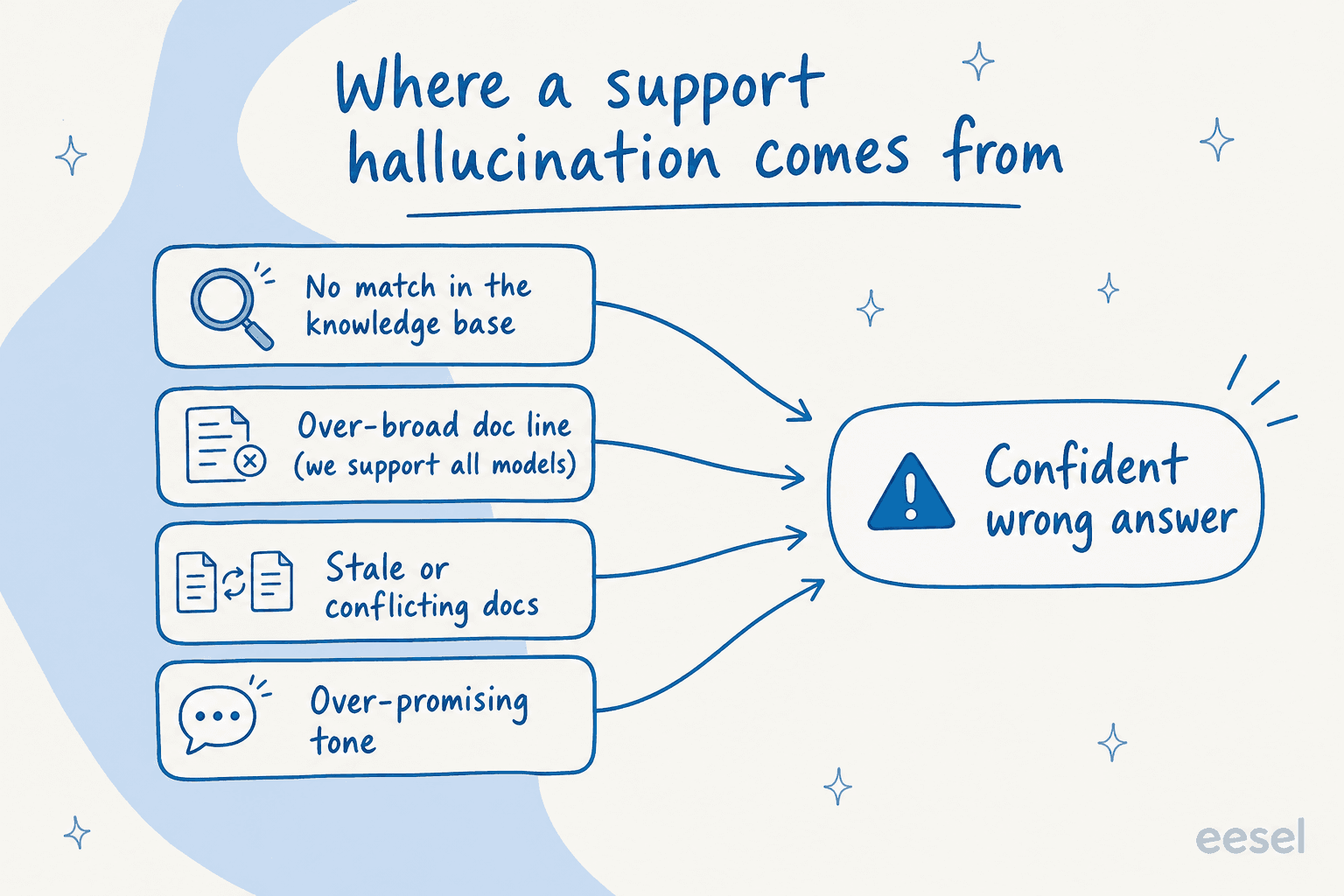
Um exemplo ficou gravado em mim. Uma equipe de telematica de veiculos B2B na Dinamarca, rodando Zendesk e escalando de algumas centenas de tickets por mes para alguns milhares, nos disse que seu bot ficava dizendo aos clientes "sim, suportamos seu modelo de carro" para marcas que nao estavam em seu banco de dados. Por que? Sua base de conhecimento tinha uma linha amigavel dizendo que "suportavam todos os modelos". A IA acreditou nisso. Nao estava mentindo, estava repetindo um documento escrito para marketing, nao para um agente autonomo respondendo perguntas reais. O proprio resumo deles dos primeiros dias: "tentativa e erro".
Isso e a coisa sobre alucinacoes no suporte: raramente e o modelo saindo dos trilhos. E o modelo repetindo fielmente uma lacuna na sua configuracao. Temos colocado agentes de IA em filas de suporte ao vivo por anos, atraves de milhares de tickets reais, e quase toda resposta errada que rastreei tem uma causa raiz entediante e corrigivel. Entao comecemos por ai.
Por que uma alucinacao de suporte custa mais do que uma alucinacao de chatbot
Quando um chatbot geral inventa algo, voce da de ombros e reformula. Quando um agente de suporte faz isso, o cliente age com base nisso. Ele espera por uma data de entrega que voce nao prometeu. Segue passos de configuracao para um recurso que voce nao tem. Em trabalhos regulamentados as apostas sobem rapidamente: um cofundador de uma empresa de tecnologia juridica nos disse que nao podiam se dar ao luxo de errar nada, porque ha uma linha tenue entre ser util e silenciosamente se aventurar a dar conselhos juridicos.
Voce pode ver o mesmo medo em avaliacoes publicas. Um Analista de Negocios do Salesforce avaliando um agente de suporte de IA no G2 colocou a versao de qualidade de dados diretamente:
"Se seus arquivos de Content Version (Knowledge Articles) nao foram atualizados desde 2021, o agente de IA dara com confianca aos clientes informacoes desatualizadas."
Muhammad O., Analista de Negocios do Salesforce, avaliando Agentforce Service no G2
E a versao sem ancoramento, de outro avaliador da mesma familia de ferramentas:
"Alem disso, a alucinacao e realmente ruim, ja que nao treinamos, e funciona em um modelo geral, as vezes simplesmente da informacoes que nao sao nossas."
Arjun G., Consultor Associado do Salesforce, avaliando Salesforce Agentforce no G2
Ambas as avaliacoes chegam ao mesmo ponto de extremos opostos: um agente e tao veridico quanto o que lhe e permitido ler e se e forcado a le-lo. Esse e todo o jogo. Aqui esta como eu o bloquearia.
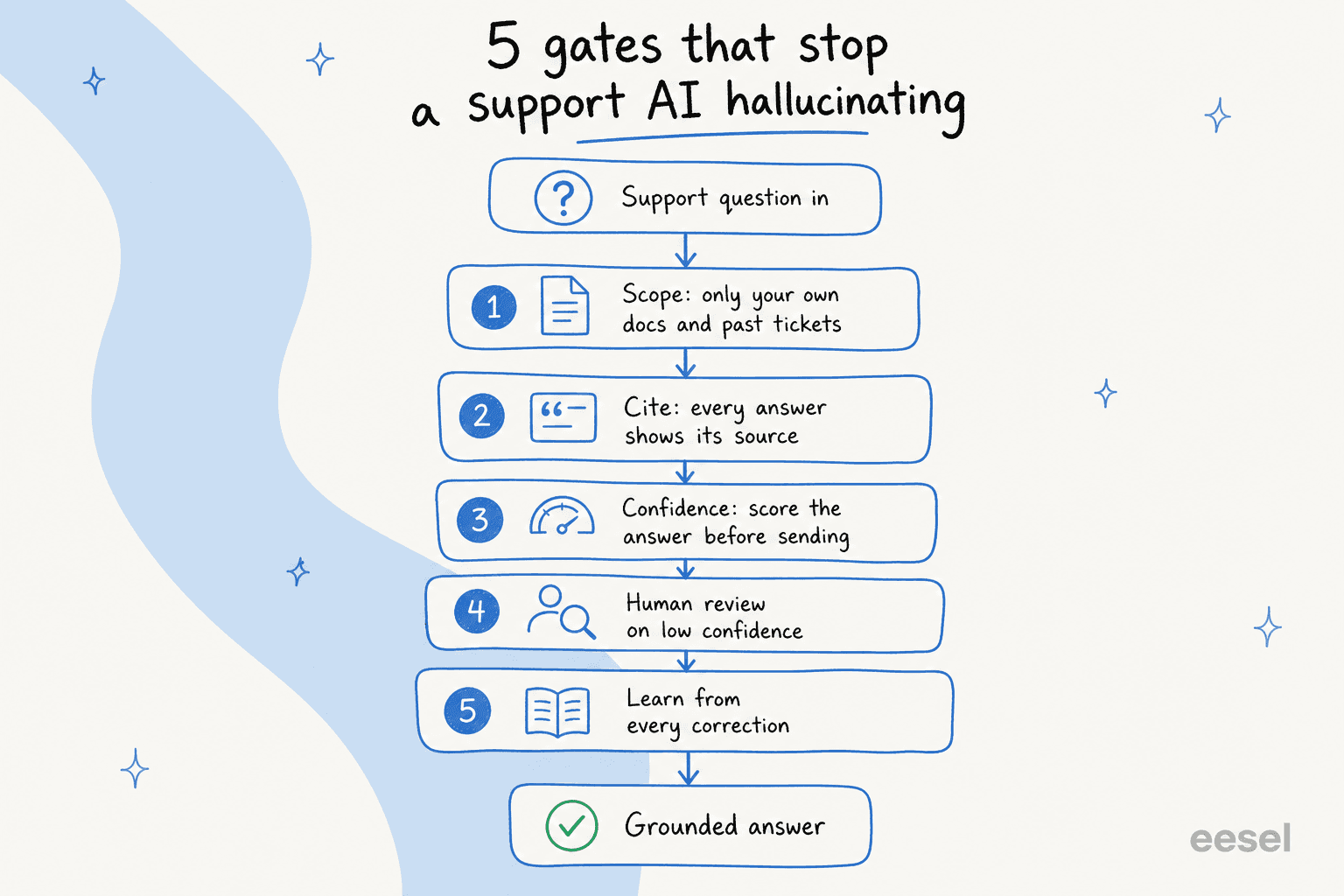
As cinco barreiras que impedem um agente de suporte de IA de alucinar
Pense menos como uma configuracao e mais como uma serie de barreiras pelas quais uma pergunta passa antes de chegar a um cliente. Cada barreira captura um modo de falha diferente, e as que sobrevivem a todas as cinco sao as respostas que voce realmente pode confiar em enviar por conta propria.
Barreira 1: delimite o conhecimento, depois delimite novamente
A primeira e maior alavanca e o que o agente pode ler. Um agente de suporte de IA deve responder a partir da sua propria fonte de verdade: seu centro de ajuda, seus tickets resolvidos passados, sua base de conhecimento interna, e nada mais. No momento em que lhe e permitido recorrer ao "conhecimento geral" para preencher uma lacuna, voce lhe deu permissao para adivinhar.
Aqui e tambem onde a higiene entediante de documentos importa. Essa linha "suportamos todos os modelos" e uma alucinacao esperando para acontecer, nao porque a IA e burra, mas porque e uma declaracao confiante e sem qualificacoes sentada em uma fonte que o agente trata como verdade. Quando voce treina uma IA na sua base de conhecimento, nao esta apenas apontando-a para documentos, esta auditando se esses documentos sao seguros para repetir literalmente a um estranho.
O eesel aprende com seus tickets passados, documentos de ajuda e fluxos de trabalho da equipe desde o primeiro dia, para que anos de conversas resolvidas se tornem conhecimento em que o agente pode se apoiar em vez de inventar. Ele se conecta diretamente as suas fontes de conhecimento existentes e mesas de ajuda, para que o agente leia os mesmos artigos nos quais sua equipe ja confia.

Se um topico genuinamente nao esta coberto, o comportamento correto e dizer isso ou transferir, nao improvisar. Um bom agente tambem deve sinalizar as lacunas que continua encontrando para que voce possa escrever o artigo ausente, em vez de cobri-las com uma suposicao. Esta e metade do valor de um chatbot de base de conhecimento de IA: ele diz o que seus documentos ainda nao cobrem.
Barreira 2: force uma citacao em cada resposta
Citacoes sao uma armadilha para alucinacoes. Se o agente tiver que apontar para o documento especifico do qual sua resposta veio, duas coisas boas acontecem: um revisor humano pode verificar com um clique, e o agente nao pode responder quando nao ha fonte para citar. Sem fonte, sem resposta confiante.
O cofundador de tecnologia juridica que mencionei antes ficou confortavel precisamente porque podia definir barreiras exatas sobre o fornecimento e o agente sempre mostrava citacoes transparentes. Isso nao e um adicional para eles, e o que lhes permitiu ativar a IA. Por baixo, e para isso que serve uma configuracao de recuperacao aumentada: a resposta e montada a partir de trechos recuperados, e os trechos viajam com ela.
Uma verificacao rapida para qualquer ferramenta que voce esta avaliando: peca para ver uma resposta com suas fontes anexadas. Se o fornecedor nao puder mostrar de onde veio uma determinada resposta, sua equipe tambem nao pode, e seu cliente tambem nao.
Barreira 3: rotear por confianca (essa e a mais importante)
Se voce fizer apenas uma coisa desta publicacao, faca isso. Um limite de confianca permite que o agente responda as perguntas de que tem certeza e deixe todo o resto em paz. Alta confianca, responde e envia. Media, escreve um rascunho para um humano aprovar. Baixa, nao toca o ticket e o roteia para uma pessoa.
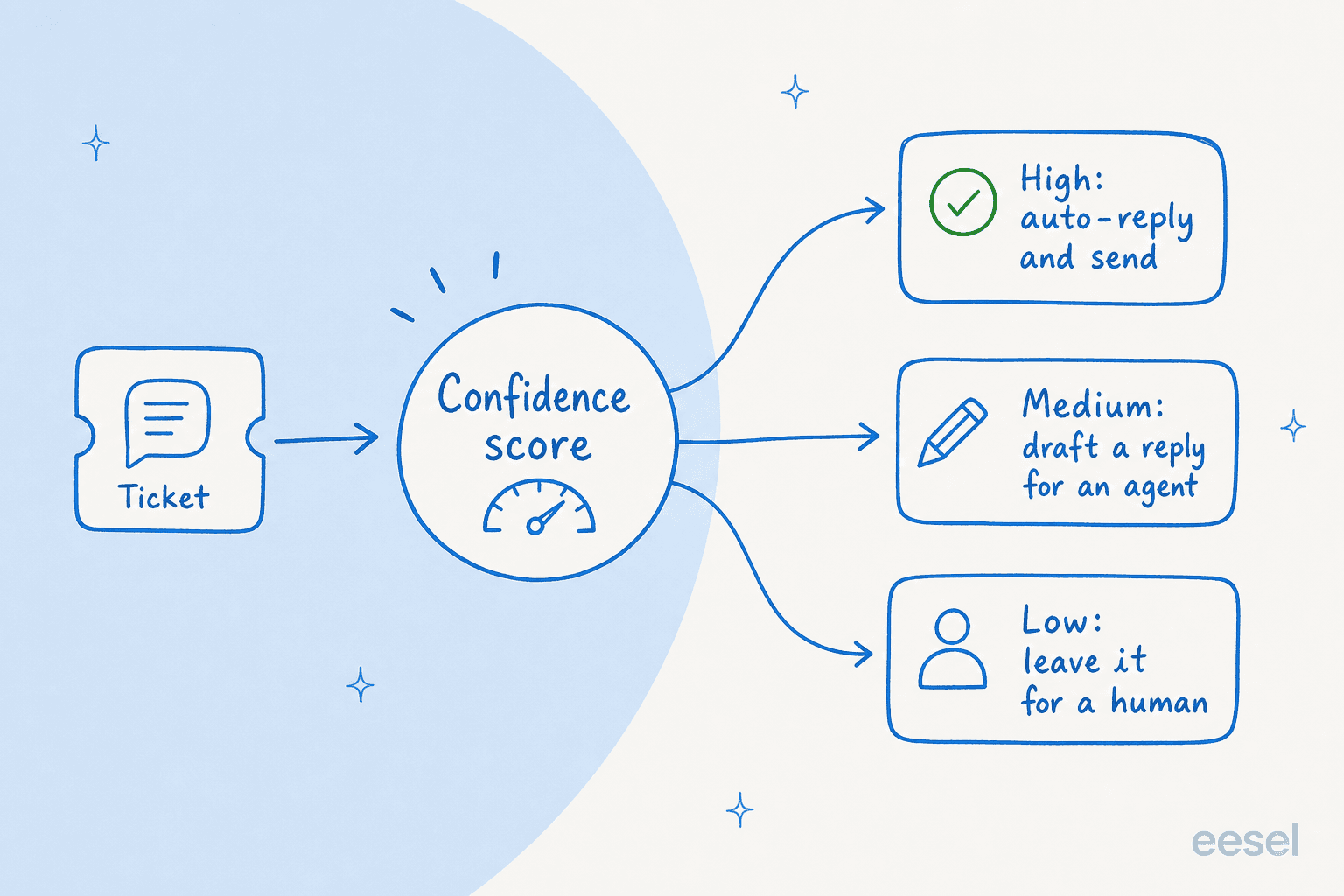
Isso surgiu na ligacao de vendas mais memoravel que reli. Um lider de CX em uma marca DTC de suplementos no Gorgias e Shopify, fazendo cerca de 7.000 tickets por mes, nos disse que o negocio dependia exatamente disso. Suas palavras, aproximadamente: a IA nunca vai responder 100% das perguntas, mas se tentar e simplesmente responder "desculpe, nao sei", ele nao pode checar os 7.000 tickets para ver se a resposta foi boa, entao o objetivo se perde. Ele precisava de uma IA que so lidasse com os tickets de que tinha certeza e deixasse o resto em paz. Essa e toda a tese de prevencao de alucinacoes em uma frase frustrada.
O roteamento por confianca e tambem o que faz a diferenca entre um agente de IA e um chatbot baseado em regras: o agente sabe quando nao sabe. O eesel vem com isso pronto para usar, e voce comeca completamente supervisionado, depois concede autonomia nos tipos de tickets faceis conforme constroi confianca, categoria por categoria. A maioria dos helpdesks expoe alguma versao disso; se voce esta no Zendesk, vale a pena entender o limite de confianca de intencoes e a mensagem de fallback para a qual o agente recorre.
Barreira 4: mantenha um humano nos tickets dificeis, com uma transferencia limpa
O roteamento por confianca so ajuda se a transferencia que se segue for limpa. Quando o agente recua, o ticket deve chegar a um humano com contexto completo: a conversa, o cliente, o que o agente nao tinha certeza, nao uma reinicializacao fria que faca o cliente se repetir.
Aqui e tambem onde voce da a sua equipe controle explicito sobre o que a IA toca. Muitas equipes querem certos tipos de tickets completamente fora da automacao: disputas de faturamento, cancelamentos, qualquer coisa juridica. Isso e um recurso, nao uma limitacao. Uma boa configuracao permite excluir tipos de tickets, definir o agente para so agir quando invocado explicitamente, e definir quando deve escalar. Se voce esta mapeando isso, nosso guia sobre escalacoes de agentes de IA cobre os padroes que funcionam. A mecanica de uma transferencia para um humano limpa importa tanto quanto o gatilho que a dispara.
Ha uma armadilha relacionada que vale a pena nomear: prometer demais. Um gerente de suporte de eCommerce com quem trabalhamos tinha que continuar dizendo ao seu chatbot de IA de ecommerce para parar de garantir aos clientes que os "resolveria" e parar de prometer entrega ate sexta-feira, porque ninguem podia garantir isso. Alucinacao nao e so inventar fatos, e tambem inventar compromissos. Barreiras de tom e promessas pertencem ao mesmo balde que barreiras de fatos.
Barreira 5: aprenda com cada correcao
A ultima barreira e a que se acumula. Cada vez que um humano edita ou rejeita um rascunho, esse sinal deve melhorar a proxima resposta, nao desaparecer no vazio. Um agente que aprende com correcoes torna-se mais preciso e confiante ao longo do tempo, o que significa que mais tickets passam pela barreira 3 honestamente em vez de baixar o nivel.

Com o eesel voce ajusta isso em linguagem simples: voce diz ao agente quando intervir, que tom usar e o que nunca prometer, e as correcoes alimentam seu comportamento. Sem projeto de retreinamento, sem equipe de ciencia de dados. Voce pode revisar o que ele esta fazendo nos registros de conversa e ajustar a partir dai, o mesmo ciclo em torno do qual um centro de treinamento do Zendesk e construido.
Nao confie nas barreiras sem verificar: simule primeiro
Aqui esta o passo que a maioria das equipes pula, e o que eu nunca lancaria sem. Antes de uma unica resposta ao vivo sair, execute o agente contra seus tickets historicos reais e veja como ele teria respondido.
A simulacao transforma "acho que isso e seguro" em um numero. Voce aponta o agente para milhares de conversas passadas e ele mostra como teria respondido, onde e confiante, onde teria adivinhado, e que parcela do volume teria conseguido lidar sozinho. Voce encontra as lacunas, as preenche e re-executa, tudo antes de qualquer cliente estar envolvido. E a diferenca entre esperar que suas barreiras aguentem e velas aguentar contra seu historico real de tickets.

Esta e tambem a forma honesta de prever sua taxa de resolucao em vez de confiar no numero de destaque de um fornecedor. Um lider de CX que citei antes fez o mesmo ponto de outra forma: ele nao queria esperar por um relatorio mensal para descobrir que a IA estava errada, queria saber antecipadamente. A simulacao e como voce sabe antecipadamente. O modo de simulacao do eesel roda contra seus tickets passados e relata cobertura por tema, para que voce va ao vivo nos tipos de tickets que provou que conseguia lidar, e apenas esses.
Serei direto sobre o compromisso, ja que o otimismo uniforme e seu proprio tipo de sinal. Fazer isso adequadamente significa que voce nao vira uma chave e automatiza tudo no primeiro dia. Voce comeca restrito, nos tipos de tickets que a simulacao aprovou, e expande conforme o agente merece. Se voce quer um agente que resolva 100% dos tickets desde a primeira hora com zero supervisao, nenhuma ferramenta honesta pode lhe dar isso, e as que afirmam sao as que alucinem. A vantagem e que o caminho mais lento e ancorado e tambem aquele em que os clientes realmente passam a confiar.
Onde o proprio modelo ajuda
Me apoiei muito em "e a sua configuracao, nao o modelo", porque e ai que estao as correcoes. Mas o modelo subjacente nao e irrelevante. Modelos mais novos sao melhores em dizer "nao tenho certeza" em vez de blefar, melhores em seguir fontes recuperadas e melhores em seguir instrucoes como "nunca prometa uma data de entrega". Uma configuracao de ancoramento forte em um modelo forte supera uma configuracao forte em um fraco. E tambem o que separa uma verdadeira ferramenta de assistencia a agentes de IA de um selecionador de macros glorificado.
A conclusao pratica: voce nao precisa escolher o modelo voce mesmo nem vigiar atualizacoes. O trabalho de uma boa plataforma de suporte e executar um modelo capaz e envolvê-lo nas cinco barreiras acima, para que voce obtenha as melhorias do modelo sem ter que rearquitetar nada. Essa e a camada em que o eesel se situa, e e por isso que o mesmo agente se comporta de forma consistente em mais de 100 integracoes. Seja sua pilha construida em um agente de IA do Gorgias ou um do HubSpot, as camadas de ancoramento e confianca viajam com ele.
Experimente o eesel
Sou parcial, trabalho aqui, e nos integramos com os helpdesks que mencionei, entao pondere minha opiniao com isso em mente. Mas a prevencao de alucinacoes e exatamente o problema em torno do qual o agente de helpdesk de IA do eesel foi construido. Ele aprende com seus tickets e documentos passados desde o primeiro dia, cita suas fontes, roteia por confianca para que respostas inseguras vao para um humano em vez do seu cliente, e permite simular contra seu historico real de tickets antes de ir ao vivo: as cinco barreiras, incorporadas em vez de adicionadas. As equipes o executam em escala real: um cliente resolve 73% das solicitacoes de nivel 1 no primeiro mes, e outro executa um agente totalmente automatizado em mais de 100.000 tickets em alemao por mes.
O preco e baseado em uso sem taxas por assento, para que voce nao pague por um agente sentado la adivinhando. Voce pode ver os planos ou iniciar um teste gratuito e executar primeiro uma simulacao nos seus proprios tickets. Essa simulacao e a forma mais rapida de ver, nos seus proprios dados, exatamente onde um agente de IA ajudaria e onde teria alucinado, antes de falar com qualquer cliente.
Perguntas frequentes
O que causa alucinacoes de IA no suporte ao cliente?
Como impeco meu agente de suporte de IA de inventar respostas?
O roteamento por confianca e suficiente para prevenir alucinacoes?
Como testo um agente de suporte de IA antes de entrar em producao?
Um agente de suporte de IA que evita alucinacoes ainda resolvera tickets suficientes?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.







