Por que "quando a IA não tem certeza" é a forma errada de enquadrar a questão
A maioria dos guias de configuração trata a escalação como um problema de ajuste: escolha um limite de confiança, defina em 0,7, pronto. Esse é o enquadramento que gera o workaround r/lifehacks de "dizer palavrão para chegar a um humano" do outro lado. A comunidade aprendeu a burlar gatilhos de palavras-chave frágeis porque o número de confiança do bot nunca foi o problema real do cliente.
O problema real dos clientes é sentir-se preso.
Veja onde a frustração de verdade mora. De r/Anthropic:
"Falei com o bot, foi escalado para um humano e então disse que os humanos estão sobrecarregados de solicitações e entrarão em contato em breve por e-mail."
A escalação tecnicamente funcionou. O cliente ainda estava furioso, porque a IA o jogou em um buraco negro assíncrono sem contexto. De um comerciante do r/shopify bloqueado do suporte:
"Preciso de ajuda com um problema, mas parece que todos os métodos para falar com um ser humano de verdade estão bloqueados pelo chatbot de IA deles."
E de Ojas Patil no LinkedIn, contando sobre um chat de pedido atrasado com o Zomato:
"Em teoria, a automação deveria tornar o suporte mais rápido. Na prática, os clientes passam mais tempo tentando convencer um bot a deixá-los falar com um humano."
Então configurar a escalação não é realmente "qual limite devo escolher?". São três trabalhos de design separados rodando em paralelo:
- Gatilhos - o que deve fazer a IA dar um passo atrás. Não uma regra, cinco.
- Payload - o que viaja com a conversa quando ela sai da IA.
- Experiência do cliente na transição - o que o usuário vê, ouve e aguarda entre a IA e o humano.
Faça um bem e pule os outros, você construiu o que Navdeep Singh Gill no LinkedIn Pulse chama de "um abandono com etapas extras." O restante deste artigo explica como acertar nos três.
Os cinco gatilhos que devem disparar a escalação
Um único limite é o bug de produção mais comum. Confiança é um input, não todo o sinal. O enquadramento da BlueTweak: "a maioria das equipes implementa apenas um tipo, mas os melhores sistemas usam os três" - gatilhos explícitos, baseados em confiança e contextuais, todos conectados juntos.

1. Solicitação explícita do usuário - o inegociável
Quando um cliente digita "quero falar com um humano", "falar com um agente" ou algo parecido, escale imediatamente. Sem etapa de confirmação. Sem "tem certeza?" Sem nova tentativa. Da BlueTweak:
"Quando um cliente pede diretamente um humano, o sistema deve escalar imediatamente sem loops, sem atrito, sem novas tentativas. Ignorar isso é uma das formas mais rápidas de destruir a confiança."
O Salesforce Agentforce implementa isso na camada de classificador de tópicos especificamente para que não possa ser engolido pela lógica interna: "Quando um usuário pede explicitamente para falar com um humano, o sistema ignora a lógica interna para disparar uma transferência imediatamente."
Este também é o gatilho que é mais frequentemente quebrado de propósito, geralmente porque alguém está otimizando a taxa de deflexão. Não faça isso. O número de engajamento de 80% em chatbots da Social Intents é condicional: "80% das pessoas só usarão chatbots se souberem que existe uma opção humana." Esconda a saída de emergência e sua taxa de deflexão sobe enquanto o engajamento colapsa. (Para a armadilha de métricas relacionada, veja nossa opinião sobre IA para deflexão de chat ao vivo.)
2. Baixa confiança + uma segunda IA de controle de qualidade
Este é o gatilho que todo guia apresenta primeiro, e o mais difícil de ajustar. Três coisas importam:
O número de confiança não é o que você pensa. De acordo com o guia de design de escalação da Digital Applied 2026:
"Modelos treinados com RLHF estão sistematicamente mal calibrados: sua maior confiança verbal frequentemente se correlaciona com outputs incorretos. Como documenta uma análise de superconfiança em produção, uma confiança declarada de 90% frequentemente corresponde a algo mais próximo de 75% de precisão real."
Portanto, um limite bruto de 0,7 não é uma taxa de falha de 30% – é mais próximo de 40-45% de taxa de falha real, acumulada em agentes de múltiplos passos. Defina limites mais altos do que parece natural e aperte-os em intenções onde errar é caro. A Social Intents recomenda começar em "abaixo de 40% duas vezes seguidas", com limites mais altos (cerca de 0,4) em reembolsos, faturamento e cancelamentos.
Combine confiança com cobertura de conhecimento. Um bot que não tem documentos relevantes para citar deve escalar mesmo que esteja confiante, por isso os chatbots de IA que se conectam à sua base de conhecimento embasam cada resposta antes de responder. O comportamento documentado do Agente de IA do Gorgias:
"As respostas do Agente de IA são baseadas inteiramente nas fontes que você conecta. Ele não especulará além delas, e se não conseguir encontrar uma resposta relevante, transfere em vez de adivinhar."
Coloque um modelo de controle de qualidade separado na frente de cada resposta. Esse é o padrão mais pulado em configurações de produção. Gorgias novamente:
"Cada resposta também passa por uma etapa de controle de qualidade interna – um segundo modelo de IA mede a confiança e, se a resposta não atender ao limite, ela não é enviada."
O segundo portão do modelo captura o caso em que o modelo primário está confiantemente errado, que é o modo de falha mais prejudicial de todos. Para um detalhamento mais profundo de como ajustar os limites sem escalar demais, nosso guia de limite de confiança de intenção do agente de IA do Zendesk analisa os trade-offs de métricas.
3. Sentimento e tópicos sensíveis - escalar independentemente da confiança
Esse gatilho dispara mesmo quando a IA está confiante. Dos controles do Gorgias, a lista de transferência recomendada codificada para a maioria das lojas:
"Disputas legais ou qualquer menção de ação legal; perguntas médicas ou referências a condições de saúde; linguagem relacionada a fraude ou menções de chargeback; qualquer reclamação que requeira um julgamento fora da política escrita."
Adicione uma camada de estado emocional. A Social Intents recomenda monitorar frases como "Isso não está ajudando", "Estou ficando irritado", padrões de perguntas repetidas ou comprimento crescente de mensagens, e acionar um pedido de desculpas + transferência antes que o cliente abandone.
A CX Today chama essa camada de "pontuação de risco":
"Mesmo que o bot esteja confiante, esta situação é sensível demais para automatizar? Pense em sinais de fraude, disputas de faturamento, clientes vulneráveis, divulgações regulatórias ou qualquer coisa que possa causar danos à reputação se manuseada incorretamente."
4. VIP / segmento de cliente
Nem todo cliente é igual. Da Social Intents:
"Se você consegue identificar usuários prioritários (clientes platina, grandes gastadores, contas-chave), considere escalá-los para um humano após o triagem inicial do chatbot… dê aos clientes VIP escalações prioritárias durante o horário comercial para manter seus melhores clientes extremamente satisfeitos."
Esse gatilho se apoia em dados do cliente que o agente de IA já possui: valor do pedido, nível da conta, pontuação NPS, idade da conta. Conecte-o aos campos de segmento que você já rastreia no seu helpdesk. Um exemplo prático: qualquer pessoa com LTV > $10k é roteada completamente fora da automação durante o horário comercial, e só recebe um agente de IA fora do horário. O cálculo sobre se isso vale a pena tende a favorecer a automação. Veja nossa análise de custo de agente de IA vs. agente humano.
5. A ação requer aprovação humana
Reserve isso para operações irreversíveis: movimentação de dinheiro, exclusão de conta, aprovação de reembolso, emissão de desconto, alterações de identidade, exportação de dados. O modelo de risco de ação de quatro níveis da Digital Applied é direto sobre isso:
"Nível 4 - Alto Risco / Irreversível. Deploys em produção, movimentação de dinheiro, exclusão de dados, alterações de privilégios, comunicações externas. A aprovação humana é inegociável aqui, independentemente de quão confiante o agente afirme estar."
O equivalente em linguagem simples do Gorgias: "Não ofereça um desconto sem que um agente humano o aprove primeiro."
Um detalhe crítico: o portão de aprovação não pode residir dentro do prompt da IA. Digital Applied novamente:
"A lógica de aprovação deve ser aplicada na camada de execução do fluxo de trabalho, não negociada pela IA em tempo de execução."
Se você deixar o modelo decidir se sua própria próxima ação precisa de aprovação, uma mensagem de cliente suficientemente persuasiva pode convencê-lo a não perguntar. Incorpore a regra no fluxo de trabalho que dispara a ação, na camada de integração, não no prompt.
O payload de transferência: o que o humano realmente precisa
Este é o modo de falha que engole a maioria das configurações de escalação. O gatilho dispara corretamente. A conversa se move. O humano começa frio. O cliente experimenta isso como "a automação desperdiçou meu tempo."
Os números sobre isso são mais contundentes do que recebem crédito. Segundo a pesquisa da PwC citada pela BlueTweak:
"73% dos consumidores dizem que ter que repetir informações é uma das partes mais frustrantes de uma interação de suporte, especialmente após ser transferido."
E segundo a Digital Applied:
"Cerca de 70% dos clientes esperam que um agente conheça seu histórico quando uma conversa é escalada, mas apenas cerca de 34% das equipes de suporte dizem que suas ferramentas realmente transmitem esses dados de forma limpa."
Uma lacuna expectativa-entrega de 70/34 é um problema estrutural, não de ajuste. A razão pela qual isso aparece em todo lugar: a maioria das plataformas afirma "passar o contexto" entregando ao humano uma transcrição bruta. Isso não é contexto, são dados não estruturados.
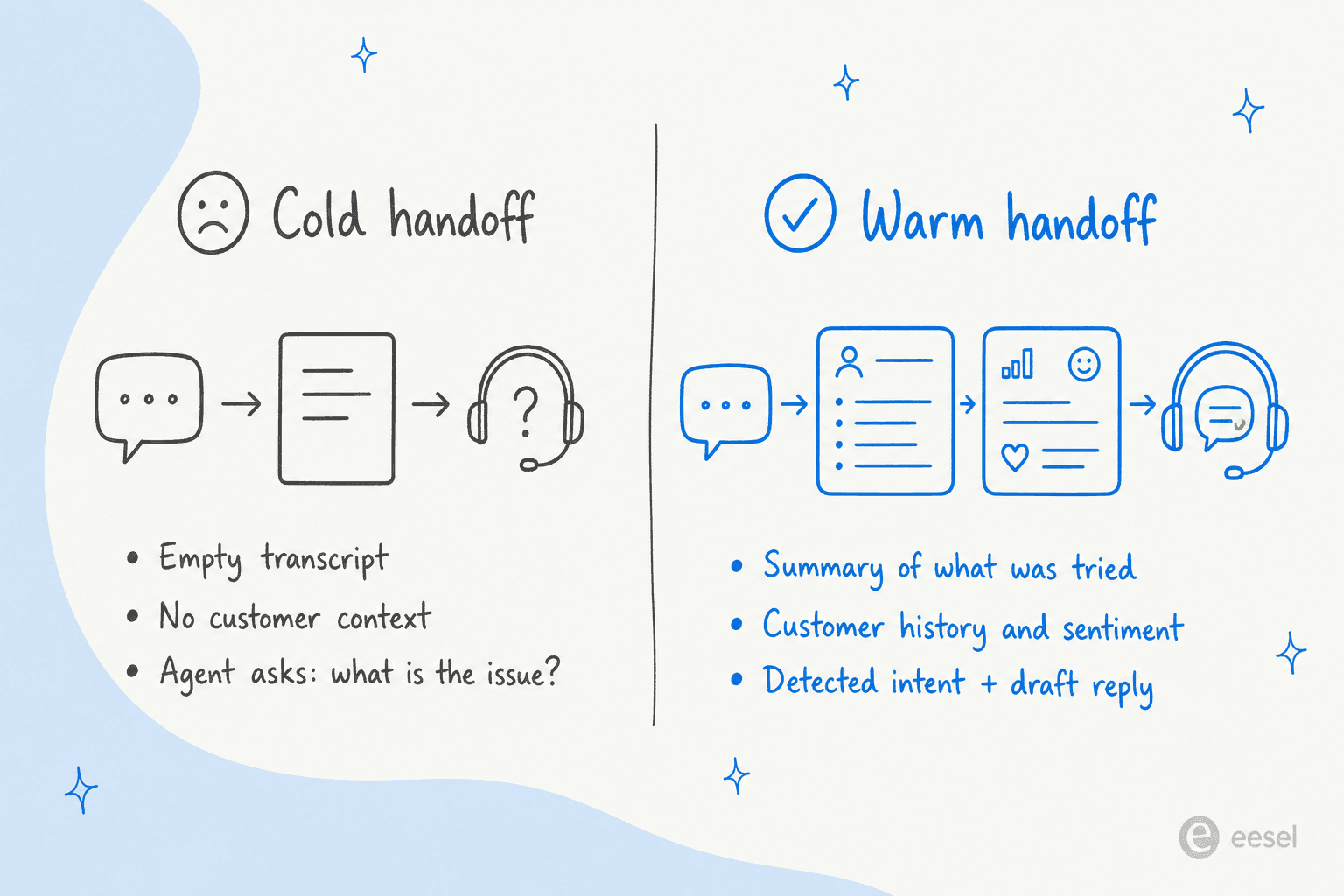
O pacote de contexto mínimo
Do enquadramento da BlueTweak, um payload funcional tem seis campos:
| Campo | O que é | Por que importa |
|---|---|---|
| Resumo do problema | Uma frase nas palavras do agente, não do cliente | O agente lê isso primeiro; todo o resto carrega sob demanda |
| Intenção detectada | A categoria classificada (ex.: refund_request, wismo, billing_dispute) | Deixa o agente saber em qual categoria o bot achava que isso se encaixava - e o que pode ter errado |
| Dados do cliente e conta | Nome, plano, valor do pedido, LTV, pedidos recentes, histórico de suporte | Ancora o agente no relacionamento, não apenas na conversa |
| Indicadores de sentimento | Estado emocional detectado na transferência (frustrado / neutro / positivo) | Prepara o agente para o tom antes de ler |
| O que a IA tentou | Respostas enviadas, fontes citadas, ações realizadas ou tentadas | Evita que o agente sugira algo que a IA acabou de tentar |
| Rascunho de resposta | Uma resposta inicial que o humano pode editar e enviar | O maior aumento de CSAT; o agente nunca começa do zero |
Para escalações de aprovação de ação especificamente, a Digital Applied recomenda adicionar "um impacto financeiro estimado, um sinalizador de reversibilidade, as abordagens alternativas que o agente avaliou, um ID de sessão para correlação de auditoria e um timestamp de prazo de aprovação", para que o aprovador não seja solicitado a clicar em sim sem ver o que está aprovando.
A abertura também importa
A primeira mensagem do agente após a transferência é onde os clientes decidem se a transição foi calorosa ou fria. Da Social Intents:
"Olá Jana, vejo que você estava conversando com nosso bot sobre redefinir sua senha. Deixe-me ajudá-lo com isso."
Versus o modo de falha:
"Olá, como posso ajudá-lo?"
O primeiro reconhece o trabalho da IA. O segundo reseta o cliente para zero. O primeiro é uma vitória de 5 segundos; o segundo é o início de uma sequência de abandono de 54%.
Como realmente configurar isso: um passo a passo em 5 etapas
Os mecanismos, na ordem em que você deve construí-los.
Etapa 1 - Decida o que a IA não deve tocar
Antes de ajustar os gatilhos, defina a lista de proibições. Isso é mais rápido do que parece e reduz drasticamente a superfície que você precisa acertar.
Abra um mês recente de tickets. Marque as categorias onde errar é caro: reembolsos, disputas de faturamento, alterações de conta, qualquer coisa adjacente ao jurídico, qualquer coisa envolvendo identidade ou dados pessoais, qualquer coisa em setores regulados (médico, financeiro, aconselhamento jurídico). Essas categorias não precisam de um limite de confiança – precisam de uma regra rígida que diz "sempre escalar."
De um cliente real que anonimizamos como líder de CX em uma marca DTC de suplementos no Gorgias + Shopify (~7 mil tickets/mês):
"Há certos tickets que não quero que passem por IA."
Isso não é uma restrição para contornar – é um requisito de funcionalidade. Dê a si mesmo a capacidade de dizer "toda essa categoria vai para humanos, sem IA."
No eesel, isso é uma única linha em linguagem natural nas regras de escalação do agente:
"Nunca responda a tickets marcados com
refund_request,legaloubilling_dispute. Encaminhe-os diretamente para a equipe com um resumo de uma linha."
No Zendesk você faz isso colocando um bloco de escalação no início dos fluxos relevantes – nosso guia do construtor de fluxos do Zendesk explica onde colocá-los. No Gorgias, é uma lista de tópicos de transferência, configurada de acordo com a configuração de ações do Agente de IA. O resultado é o mesmo: certas coisas simplesmente nunca tocam a IA.
Etapa 2 - Configure a lógica de gatilhos de múltiplos sinais
Para tudo que a IA tem permissão para tocar, adicione os outros quatro gatilhos por cima.
Para um detalhamento mais aprofundado especificamente sobre isso, nosso guia de transferência para humano do agente de IA do Zendesk e o tutorial de configuração de transferência do agente de IA do Zendesk aprofundam os mecanismos do canal de mensagens, e nosso guia de mensagem de fallback do agente de IA do Zendesk cobre o que dizer quando nada corresponde.
Uma configuração inicial razoável:
- Limite de confiança: 0,6 de base, 0,8 em intenções de alto risco (reembolsos, faturamento, cancelamentos).
- Limite de falha repetida: 2 turnos com o cliente perguntando a mesma coisa de formas diferentes → escalar no 3º.
- Gatilho de sentimento: frustração detectada → pedir desculpas + oferecer humano.
- Regra VIP: clientes marcados com
vipou com LTV > $X → direto para humano durante o horário comercial. - Aprovação de ação: reembolsos > $X, exclusões de conta, emissão de desconto → escalar, independentemente de quão confiante a IA esteja sobre o que fazer.
Se sua ferramenta expõe apenas um botão, você precisará simular os outros, geralmente inserindo tópicos de transferência em uma lista e monitorando palavras-chave. É assim que funciona a Orientação em linguagem natural do Tidio Lyro. É funcional, mas não captura os casos de sentimento a menos que você escreva regras para as palavras que clientes frustrados realmente usam.

Etapa 3 - Escreva a mensagem de transição
Seja qual for o gatilho, o cliente ouve algo no momento da transferência. Não fique em silêncio. Da Social Intents:
"Não mude silenciosamente. O bot deve dizer algo como: 'Claro, estou conectando você com um agente humano que pode ajudar mais.' Se houver tempo de espera, defina expectativas: ex. 'Um agente entrará em breve' ou 'Você é o número 2 na fila, um agente estará com você em aproximadamente 1-2 minutos.'"
Três coisas a incluir:
- Um reconhecimento do que eles estavam tentando fazer.
- Um tempo de espera estimado, mesmo que seja um intervalo.
- Uma nota de que o humano terá o contexto completo, para que não sintam que estão recomeçando.
Para fora do horário comercial, capture um e-mail e diga quando esperar uma resposta. O padrão de chat offline do Gorgias – "Quando uma transferência ocorre enquanto o chat está offline, o Agente de IA pede ao comprador seu endereço de e-mail para que sua equipe possa fazer um acompanhamento por e-mail mais tarde" – é o padrão correto. O toggle opcional "Compartilhar horário de funcionamento na mensagem de transferência" é um pequeno toque que define expectativas.
Etapa 4 - Passe o payload estruturado
A maioria das plataformas passa ao próximo humano uma transcrição e chama isso de concluído. Esse é o modo de falha da transferência fria. Construa o payload a partir dos seis campos acima e certifique-se de que o agente os veja antes da transcrição, não enterrados sob 20 mensagens.
No Zendesk, isso significa preencher os campos e tags do ticket como parte do bloco de escalação, depois usar uma visão de transcrições de conversa que exibe o resumo no topo. Na visão de logs de conversa do agente de IA do Zendesk é onde você detectará lacunas no payload. No Gorgias, o padrão de marcação automática (ai_handover para escalações, ai_ignore para tickets excluídos) permite construir regras de roteamento posteriores, e nosso guia de transferência do Gorgias explica como conectar essas marcações à atribuição de agentes.
O padrão do eesel é colocar o resumo como uma nota interna estruturada antes de o agente ler o thread, para que a primeira coisa que o agente veja seja "Resumo: o cliente quer atualizar o envio no pedido #4521, a IA tentou enviar o link de autoatendimento, o cliente respondeu que não consegue encontrá-lo na conta." Esse é o âncora do agente. A transcrição completa está lá se ele quiser, mas raramente precisa.
Etapa 5 - Meça os resultados da transferência, não a taxa de transferência
Essa é a etapa que todo mundo pula. Da BlueTweak:
"Uma taxa baixa pode indicar forte automação ou sinalizar que os clientes estão presos em loops de IA. Uma taxa alta pode refletir baixo desempenho da IA ou simplesmente um caso de uso que genuinamente requer intervenção humana. A métrica só se torna significativa quando combinada com resultados."
As métricas que realmente importam:
- Resolução no primeiro contato (FCR) pós-transferência - rastreada separadamente do FCR geral. Se os tickets escalados continuam voltando, ou os tickets errados estão sendo escalados ou o payload está falhando.
- Taxa de recontato em uma janela de 24-48 horas após a escalação. "Um dos indicadores mais confiáveis de falha oculta," segundo a BlueTweak.
- Delta de CSAT - CSAT em conversas escaladas vs. resolvidas automaticamente. Se as escaladas consistentemente pontuam mais baixo, o problema é a experiência de transferência, não o agente.
- Pontuação de integridade do contexto - o agente avalia cada transferência: suficiente / parcial / ausente. Barato de coletar, expõe bugs do payload rapidamente.
- Tempo-até-humano após o cliente optar por sair da IA. Longa espera + baixo contexto = a pior combinação de CSAT.
- Frequência de substituição - se os supervisores continuam substituindo o bot, seus limites estão muito frouxos.
Realize uma revisão mensal das transferências do quartil inferior. A cadência recomendada pelo Gorgias: "ler tickets sinalizados, avaliar bom/ok/ruim com motivos, verificar a página de Intenções para clusters de transferência, revisar e aprovar Oportunidades de Orientação, atualizar a Orientação quando as políticas mudarem" (Gorgias). Aplique o mesmo loop em qualquer lugar que você tenha configurado isso.
Para um design de métricas mais aprofundado, veja nossos guias sobre métricas e taxas de resolução do agente de IA do Zendesk e a comparação mais ampla de IA vs. suporte ao cliente humano.
Como os principais agentes de IA de helpdesk lidam com escalação
Se você está escolhendo um fornecedor (ou tentando descobrir por que o seu continua roteando errado), a diferença entre plataformas está principalmente em como a lógica de gatilho é exposta – blocos construídos pelo autor, dials nativos de confiança ou regras em linguagem natural. A forma da superfície de escalação é o que você está realmente comprando.
| Fornecedor | Modelo de gatilho de escalação | Vale saber |
|---|---|---|
| Agentes de IA do Zendesk | Blocos de escalação definidos pelo autor + evento de transferência de conversa. Gatilhos por solicitação do usuário, intenção não correspondente ou posicionamento do bloco | "Um agente permanece como o primeiro respondente até que o ticket associado à conversa seja fechado" – a janela padrão de 4 dias de resolução para fechamento pode deixar o estado de transferência em suspense. Veja nosso guia de escalações do Zendesk |
| Freshdesk Freddy | Toggle "Automatizar transferência de agente" + Configurações de transferência no AI Agent Studio. Principalmente orientado a solicitações; sem dial de confiança NLP público | O modo de pré-visualização "não realizará transferências de agentes para consultas sem resposta ou quando suporte de agente humano foi solicitado" – você não pode testar completamente a escalação sem ir para produção. Veja nossas melhores práticas do Freshdesk |
| Gorgias Automate | Quatro gatilhos explícitos: baixa confiança, tópico de transferência listado, lacuna de conhecimento, solicitação explícita ou raiva/frustração detectada | O Agente de IA de Chat é apenas para Shopify. Comerciantes não-Shopify não podem usar isso para chat. Veja nosso guia de transferência do Gorgias |
| Ada | Objeto Handoff de primeira classe com Nome + Descrição; variantes ao vivo / assíncrono / fora do horário; fallbacks integrados | Máximo de cinco transferências ativas; variáveis em blocos de transferência são separadas dos dados coletados por Ações – a armadilha mais comum |
| Salesforce Einstein/Agentforce | Diálogo do Sistema de Transferência para Agente em etapas posicionadas pelo autor; Confused Dialog como fallback | Etapas de transferência conflitantes substituem silenciosamente o Próximo Passo – duas configurações podem competir entre si sem aviso |
| Help Scout | Sem agente autônomo – Rascunhos de IA e Assistência de IA são human-in-the-loop por padrão | "Escalação" não faz sentido porque o humano nunca saiu do processo. Apenas para o plano Plus/Pro; precisa de ~100 respostas anteriores antes de os Rascunhos de IA gerarem algo |
| Tidio Lyro | Orientação estilo prompt – regras em linguagem natural para clientes de alto valor, tópicos sensíveis, disponibilidade de agentes | A lógica de escalação deriva à medida que o modelo Claude subjacente é atualizado; nível gratuito limitado a 50 respostas do Lyro. Veja nosso guia do agente de IA do Tidio |
Para um contexto mais amplo, veja nossos resumos de a melhor IA para automação de suporte ao cliente, os melhores chatbots de suporte ao cliente de IA e ferramentas de chat ao vivo de IA para suporte – o comportamento de escalação é uma das dimensões em que os pontuamos.
Dois padrões se destacam na tabela. Primeiro, a maioria dessas ferramentas obriga você a expressar a escalação como lógica de fluxo – blocos de escalação, diálogos de transferência, bots do sistema. Ótimo se você é um construtor de bot dedicado; é atrito se você quer que um líder de suporte escreva as regras. Segundo, quase nenhum deles especifica o contrato de payload em documentos públicos. Apenas o Zendesk expõe um formato de metadados passControl estruturado via API; Ada expõe variáveis (com a armadilha de Ações mencionada). Para todos os outros, o que viaja com a transferência é o que estava na conversa, o que é uma forma educada de dizer "a transcrição."
Essa é a lacuna que o eesel preenche, mas o princípio se generaliza: independentemente do que você usar, torne o payload explícito em vez de esperar que a plataforma passe a coisa certa.
Modos de falha comuns e a correção para cada um
Padrões que se repetem em documentação de fornecedores, publicações de praticantes e o sentimento da comunidade que analisamos:
- O bot alucina em vez de escalar. Respostas de baixa confiança são enviadas, o CSAT colapsa silenciosamente. Correção: o segundo portão de controle de qualidade de IA antes do envio. Sem ele, "um bot que alucina com confiança uma política de reembolso errada é um resultado pior do que um que diz 'não tenho certeza, deixe-me buscar um humano'" (r/AI_CustomerService).
- Loop em "não entendi" até o cliente desistir. O Freshdesk sinaliza isso diretamente: "configure esses momentos para transferir conversas de forma transparente para agentes humanos, evitando loops intermináveis frustrantes." Correção: a regra de 2 turnos.
- A "saída de emergência" está oculta. "30% dos consumidores mudariam para um concorrente após uma única experiência ruim com chatbot"; "80% das pessoas só usarão chatbots se souberem que existe uma opção humana" (Social Intents). Correção: torne a opção "Falar com um agente" visível desde a primeira mensagem.
- Reconfiguração de contexto. A escalação acontece, o agente começa frio, o cliente interpreta como "a automação desperdiçou meu tempo" (CX Today). Correção: o payload de antes.
- Retorno em loop – redirecionar o cliente de volta para o mesmo fluxo que acabou de falhar com ele. "A confiança colapsa rapidamente" (CX Today). Correção: rastrear fluxos com falha por intenção e desativá-los.
- Beco sem saída – o bot não consegue resolver e não oferece um próximo passo crível. "Os clientes se sentem presos" (CX Today). Correção: qualquer caminho de fallback é melhor que nenhum – mesmo "entraremos em contato por e-mail em 24 horas."
- Ações não verificáveis – "o bot afirma ter 'resolvido', mas nada muda. Isso não é apenas um problema de CX – é um risco de fraude e conformidade em ambientes sensíveis" (CX Today). Correção: o portão de aprovação no nível do fluxo de trabalho do gatilho 5.
- A super-escalação mata o ponto de deflexão. A falha reversa. Segundo a Digital Applied: "Quando as solicitações de aprovação chegam com muita frequência, as pessoas param de lê-las. Elas desenvolvem um reflexo – aprovar, aprovar, aprovar – e esse reflexo é uma superfície de ataque." Correção: estruture suas aprovações em camadas; nem tudo que é sinalizado é Nível 4.
- Taxa de deflexão como único KPI. De r/sysadmin sobre um helpdesk de TI interno: "Ele tratou 5000 problemas este mês! 5000 tickets que não chegaram à nossa cara fila humana. Exceto que metade deles re-abriram tickets dois dias depois quando a 'resposta' do bot não corrigiu nada de verdade, e agora temos um backlog e usuários mais irritados" (r/sysadmin). Correção: taxa de recontato.
- Falha de recontato oculta. O cliente retorna dentro de 24-48 horas após a escalação; um dos sinais de falha mais confiáveis (BlueTweak). Correção: a métrica existe; meça-a.
- Lógica de aprovação da qual a IA pode ser convencida a abrir mão. Se a IA decide se sua própria próxima ação precisa de aprovação, uma mensagem de cliente suficientemente persuasiva pode convencê-la a não perguntar (Digital Applied). Correção: as regras de aprovação residem na camada de fluxo de trabalho, nunca no prompt.
Um exemplo real de transferência calorosa
Como isso parece de ponta a ponta quando funciona. De um usuário final no widget de chat do site do SE Ranking (história de cliente anonimizada que temos permissão de compartilhar):
"Como excluo palavras-chave do meu projeto?"
(O agente de IA responde a partir dos documentos de ajuda.)
"Como excluo mecanismos de busca?"
(O agente de IA responde a partir dos documentos de ajuda.)
"Posso falar com um humano?"
(A IA imediatamente dispara
handover_to_helpdesk, anexa as duas perguntas + respostas, o e-mail do cliente e um resumo de uma linha: "Usuário estava navegando pelos docs de exclusão de palavras-chave/mecanismos de busca; agora quer ajuda humana – provavelmente uma pergunta de acompanhamento para a qual não temos documentação.")
Duas perguntas de documentos desviadas. No momento em que o cliente pediu um humano, transferência instantânea, contexto completo. Esse é o padrão inteiro: a IA faz o trabalho fácil, dá um passo atrás no momento em que deixa de ser a ferramenta certa, e o humano começa na mensagem 4 com visibilidade completa das mensagens 1-3.
Um segundo padrão, de uma equipe de medtech configurando um widget de chat de site apoiado por Confluence com escalação para Jira:
"Copiei o snippet e não funciona no Netlify..." (A IA ajuda a depurar) ... "Funcionou. Posso compartilhar o chat de pré-visualização/teste com meu colega para ele tentar?" (A IA ativa uma configuração de integração ao vivo, no meio do chat, e depois escala o ticket do Jira para acompanhamento.)
O padrão que se repete: a IA lida com o que é bom nisso. Então, no momento em que algo precisa de julgamento ou aprovação humana, a escalação dispara – com contexto, no canal certo, para a equipe certa.
Experimente o eesel para escalação de chat de IA
Se você quer todo esse padrão – cinco gatilhos, regras em linguagem natural, transferência calorosa com contexto completo – sem construí-lo a partir de primitivos, essa é a proposta do eesel.
O eesel funciona como um colega de equipe de IA dentro do helpdesk que você já usa – Zendesk, Freshdesk, Gorgias, Freshservice, Slack, e-mail – para que você não precise trocar de plataforma para obter regras de escalação que realmente funcionem nelas. As regras em si são escritas em linguagem natural: "Nunca responda a solicitações de reembolso; encaminhe-as para a equipe com um resumo", "Se o cliente mencionar ação legal ou estorno, escale imediatamente com um sinalizador de sentimento", "VIPs marcados com a tag priority sempre vão para um humano durante o horário comercial." Sem construtor de fluxos, sem árvore de diálogo.
O payload de transferência é estruturado por padrão: cada ticket escalado recebe um resumo, a intenção detectada, o histórico recente do cliente e um rascunho de resposta anexado como nota interna antes de qualquer humano ler. A configuração leva minutos a partir dos seus artigos de ajuda existentes e tickets passados – sem treinamento manual, sem rotulagem de dados. Você pode testar com tickets passados antes de entrar em produção e começar no modo rascunho (a IA sugere, o humano envia) antes de mudar para autônomo nas categorias fáceis assim que tiver confiança. O preço é por tarefa, não por assento, então o custo de ser conservador na escalação é o que deveria ser – baixo.
Experimente o eesel gratuitamente com um crédito de $50, sem cartão necessário.
Perguntas frequentes
Como configuro um agente de IA que escala para um humano quando não tem certeza?
Conecte a escalação a cinco gatilhos ao mesmo tempo, não apenas um: uma solicitação explícita do usuário, uma resposta de baixa confiança (combinada com uma segunda IA de controle de qualidade antes do envio da resposta), uma detecção de sentimento ou tópico sensível, um segmento de cliente VIP e qualquer ação que exija aprovação humana – reembolsos, cancelamentos, tudo que for irreversível. Configure isso no construtor de bot do seu fornecedor ou, com o eesel, escreva-os em inglês simples nas regras de escalação do agente. Depois, teste com tickets passados antes de entrar em produção.
O que é escalação de chat de IA?
Escalação de chat de IA é o momento em que um agente de suporte de IA para de tentar resolver uma conversa e a transfere para um humano, porque o usuário pediu, a confiança do modelo caiu, o sentimento mudou ou a próxima ação requer aprovação humana. Bem feita, é a ponte de confiança entre a automação e sua equipe. Mal feita, o cliente a percebe como "abandono com etapas extras". Nossa visão geral dos melhores agentes de suporte ao cliente de IA compara como cada fornecedor lida com isso.
Qual é um bom limite de confiança para escalação de chat de IA?
Não existe um único número. Trate a confiança como um dos vários inputs: modelos treinados com RLHF estão sistematicamente mal calibrados, então uma confiança declarada de 90% frequentemente corresponde a uma precisão real de cerca de 75%. A maioria das equipes começa em torno de 40% e eleva o limite para intenções de alto risco como reembolsos. O guia de limites do Zendesk explica como ajustar isso sem escalar demais.
Que contexto um agente de IA deve passar para um humano durante a transferência?
Um resumo estruturado, não uma transcrição bruta. O mínimo: uma descrição de uma linha do problema do cliente, o que a IA já tentou, a intenção detectada, o sentimento, dados relevantes do cliente ou pedido, e um rascunho de resposta que o agente pode editar e enviar. De acordo com a pesquisa da PwC, 73% dos clientes citam ter que repetir informações como a parte mais frustrante do suporte, então o objetivo é que o agente nunca mais pergunte "qual é o problema?". Veja nosso guia de transcrições de conversas do Zendesk para ver como isso funciona em uma plataforma.
As regras de escalação de chat de IA podem funcionar no Zendesk, Freshdesk e Gorgias ao mesmo tempo?
Não nativamente – cada fornecedor constrói seu próprio bot do seu próprio jeito. A escalação do Zendesk usa blocos colocados pelo autor; Freshdesk Freddy usa um toggle de transferência orientado a solicitações; Gorgias usa regras de confiança + tópico. Se quiser um conjunto de regras para vários helpdesks, é aí que uma plataforma como o eesel ajuda: as mesmas regras em linguagem natural se aplicam independentemente de o ticket estar no Zendesk, Freshdesk ou Gorgias.

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.