Comment prioriser les tickets de support avec l'IA ?
Kurnia Kharisma Agung Samiadjie
Katelin Teen
Dernière modification June 23, 2026

Résumé
Si vous venez de taper "comment prioriser les tickets de support avec l'IA" dans Google, il y a de bonnes chances que votre file d'attente soit secrètement en premier entré, premier sorti — une réinitialisation de mot de passe passe avant une panne d'entreprise simplement parce qu'elle est arrivée en premier. La réponse courte : laissez l'IA lire chaque ticket entrant, le classifier et le noter en urgence, impact commercial et risque SLA, pour que le ticket qui compte vraiment saute la file tout seul.
Je passe la plupart de mon temps à observer ce que cherchent les responsables du support, et cette question renvoie toujours au même vrai problème. Le ticket urgent ne manque pas, il est enterré. La solution n'est pas une règle de tri plus intelligente, c'est une couche qui décide de la priorité par ticket au lieu de s'appuyer sur quelques filtres de mots-clés fragiles.
Nous avons appliqué l'IA à des files de support en production pendant des années, et dans nos propres tests cette couche de triage a atteint 93 % de précision de triage sur du trafic de tickets réel et a capturé 100 % du spam avant qu'il ne touche un humain. Voici comment tout cela fonctionne, où ça rate silencieusement, et comment je le déploierais concrètement.
Ce que "prioriser les tickets avec l'IA" signifie vraiment
La plupart des priorisations actuelles sont des suppositions déguisées en système. Vous avez quelques règles de routage de tickets ("si le sujet contient 'urgent', marquer"), peut-être une liste VIP, et un agent qui parcourt la file chaque matin pour décider ce qui brûle. Ça s'effondre dès qu'un client écrit "question rapide" dans l'objet d'un litige de facturation, ou qu'une panne arrive formulée poliment.
Faire ça avec l'IA, c'est différent. Au lieu de correspondre à des mots-clés, le modèle lit vraiment le ticket comme le ferait un agent expérimenté, puis le place sur deux axes qui comptent : son urgence et son impact commercial. C'est la différence entre le triage de tickets qui trie par mots de surface et la priorisation qui trie par signification.
Le modèle mental auquel je reviens toujours est une simple matrice de priorité. Où un ticket atterrit détermine ce qui devrait lui arriver.
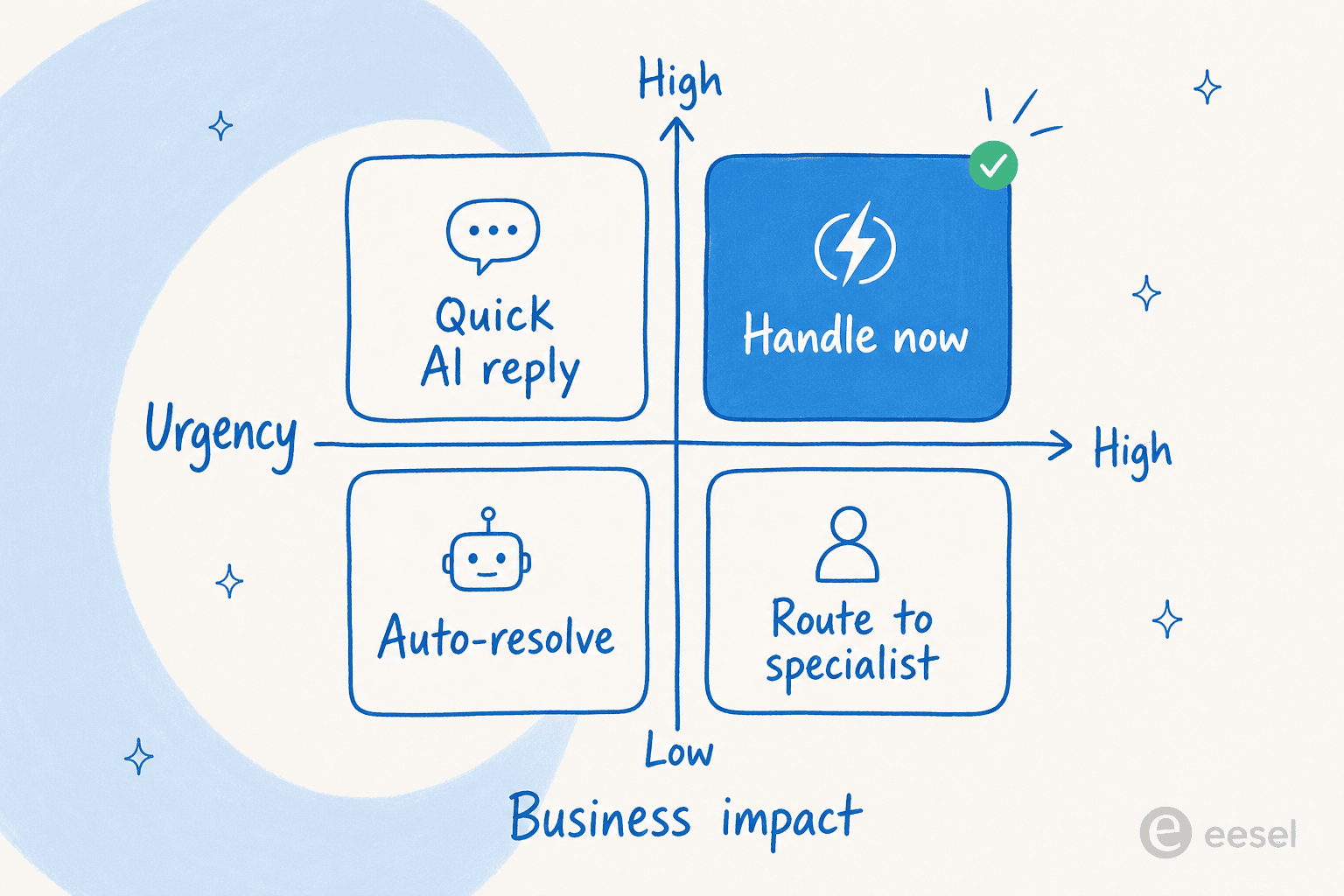
Un ticket à haute urgence et fort impact (une panne touchant un compte payant) devrait aller directement chez un humain. Un ticket à faible urgence et faible impact (une procédure déjà répondue par un article d'aide) ne devrait jamais atteindre un agent — c'est un candidat pour la résolution automatique. Les deux coins inconfortables du milieu sont là où l'IA gagne sa valeur : le ticket à fort impact mais pas encore urgent qui a besoin d'un spécialiste, et le ticket bruyant mais trivial qui n'a besoin que d'une réponse rapide et correcte.
Comment l'IA priorise un ticket en un seul passage
Voici la partie qui surprend les gens : classer, noter et acheminer un ticket ne sont pas trois travaux séparés que l'IA fait en séquence. Un agent helpdesk IA moderne fait tout ça à l'instant où un ticket arrive, en une seule lecture.
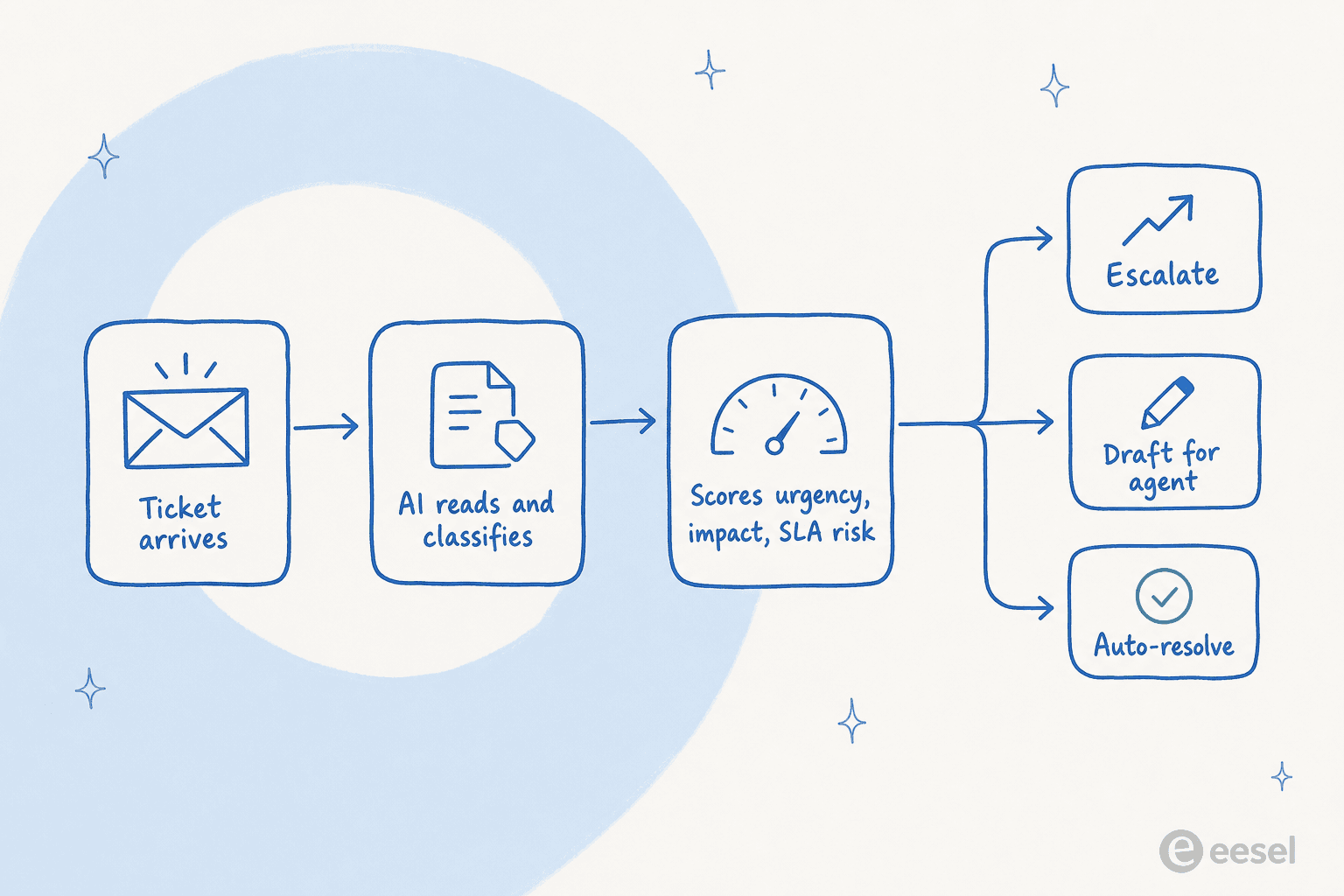
Parcourons-le avec un exemple réel. Un ticket arrive : "Toujours pas de connexion, c'est le troisième email que j'envoie, notre démo avec notre conseil d'administration est dans une heure." En un seul passage, l'agent le lit, le classe comme problème d'accès, capte les signaux d'urgence (troisième contact, délai dur), évalue l'impact (ça ressemble à un compte clé) et remarque que l'horloge SLA est déjà à risque. Il étiquette le ticket, augmente la priorité et escalade vers un humain avec un résumé — tout avant que quelqu'un ouvre la boîte de réception.
Comparons avec un ticket à faible enjeu : "Comment changer ma photo de profil ?" Même passage unique, résultat totalement différent. L'agent reconnaît une procédure documentée, rédige ou envoie la réponse et ne l'ajoute jamais à la pile d'un humain. C'est tout le principe de la déflexion de niveau 1 — ça dégage le volume facile pour que la file de vos agents ne contienne que ce qui nécessite un cerveau.
Les signaux que pondère une IA sont plus riches que n'importe quel ensemble de règles que vous construiriez manuellement : la formulation et le ton réels, le nombre de contacts, le niveau du client, la valeur du compte, le sujet lui-même (une panne dépasse une demande de fonctionnalité) et le temps déjà écoulé. Vous ne maintenez pas cette logique — le modèle l'infère de chaque ticket et de vos patterns de résolution historiques.
Essayez : que ferait l'IA avec votre ticket ?
Choisissez le ticket qui ressemble le plus à votre file chaotique du lundi et voyez où un agent IA bien réglé le placerait. C'est une version simplifiée de la même logique urgence-plus-impact ci-dessus.
La conclusion ne sont pas les quatre catégories — c'est que la décision se prend automatiquement, par ticket, à l'instant où il arrive, au lieu d'attendre qu'un humain fasse le triage manuellement.
Où la priorisation de tickets échoue silencieusement
C'est la partie que la plupart des conseils "activez juste l'IA" esquivent, et c'est elle qui détermine si le projet survivra au contact d'une vraie file.
Le plus grand mode d'échec est de laisser l'IA agir sur des tickets dont elle n'est pas sûre. Si elle essaie de tout répondre et hausse les épaules avec "désolé, je ne sais pas" sur les difficiles, vous venez de créer une deuxième file à auditer. Une responsable CX a formulé l'objection mieux que je ne pourrais le faire :
"L'IA ne pourra jamais répondre à 100 % des questions, mais si elle essaie et répond juste 'désolé, je ne sais pas', je ne peux pas vérifier mes 7 000 tickets pour voir si l'IA a vraiment donné une bonne réponse. J'ai besoin d'une IA qui gère seulement les tickets qu'elle est confiante de traiter et tous les autres, qu'elle les laisse tranquilles."
une responsable CX dans une marque DTC de compléments alimentaires sur Gorgias, lors d'un appel commercial sur le routage basé sur la confiance
C'est tout l'argument pour le routage basé sur la confiance. Un bon agent priorise et connaît les limites de sa propre compétence : haute confiance signifie agir, faible confiance signifie rédiger ou escalader vers un humain. Le chiffre qui compte n'est pas "combien de tickets a-t-il touchés", mais combien il a traités correctement sans que vous le vérifiiez.
Deux autres pièges que je vois souvent :
- Pas d'interrupteur pour les types de tickets sensibles. Beaucoup d'équipes veulent que certaines catégories (menaces légales, annulations, tout ce qui est réglementé) restent totalement hors de l'automatisation. Vous devez pouvoir dire "l'IA ne touche jamais ces tickets", et la plupart des configurations basées sur des règles ne peuvent pas l'exprimer proprement. Cherchez l'exclusion de types de tickets avant de faire confiance au routage.
- Passer en production en aveugle. Activer la priorisation sur une file en production en espérant que ça marche, c'est la façon de perdre la confiance de l'équipe. La solution est de simuler sur des tickets passés d'abord, pour voir exactement où l'IA aurait mal priorisé et le corriger avant qu'un client le ressente.
L'IA priorise-t-elle vraiment correctement ?
Question légitime, et la réponse honnête est : seulement si vous le mesurez. La raison pour laquelle je fais confiance à cette approche n'est pas une diapo de vendeur, c'est ce qui apparaît quand vous pointez un agent sur du trafic de tickets réel et que vous le notez.
Dans un test sur du trafic Zendesk en direct pour une équipe e-commerce de taille moyenne, la couche de triage IA a atteint 93 % de précision de triage, capturé 100 % du spam sans faux positifs (sur une boîte de réception à 22 % de courrier indésirable) et produit des brouillons directionnellement corrects 88 % du temps.
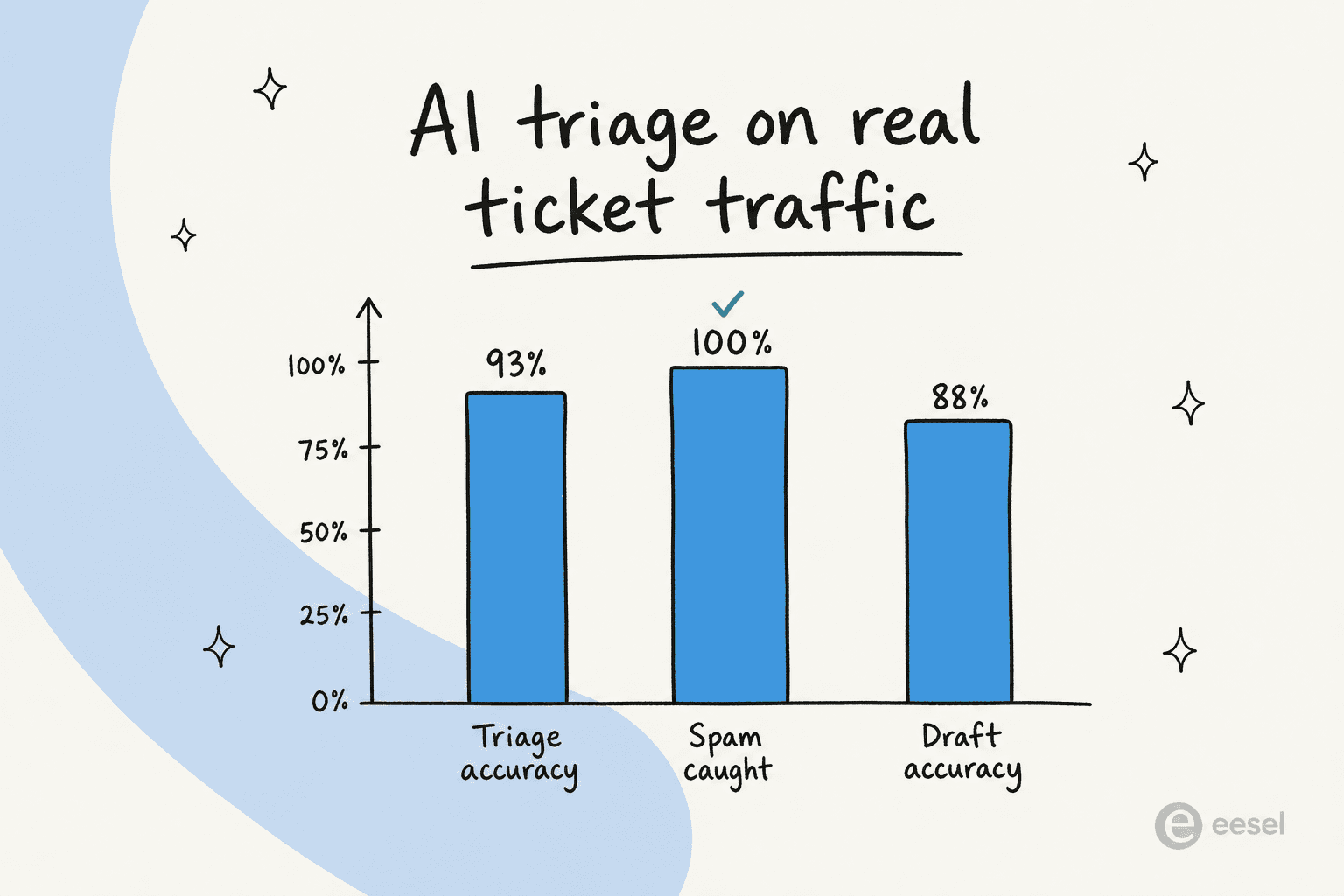
Les chiffres sur le spam et le triage sont le gain de priorisation caché en pleine vue : un cinquième de cette file était du bruit qui n'avait jamais besoin d'un humain, et l'IA l'a extrait avant qu'il ne dilue l'attention de quiconque. C'est la résolution au premier contact et l'hygiène de file en un seul mouvement.
Ça se confirme aussi en production. Une équipe d'analytique d'économie à la demande sur Zendesk nous a dit sans détour :
"Dans le premier mois, eesel résout 73 % de nos demandes de niveau 1. La plateforme inclut même des automatisations pour l'étiquetage des tickets, l'assignation et les mises à jour de statut."
Kim Simpson, Gridwise, sur notre page helpdesk
Étiquetage, assignation, statut — c'est ça la priorisation, simplement exprimée en actions sur le ticket plutôt qu'en nombre dans un champ. L'intérêt de suivre les métriques de taux de résolution et vos métriques de service client plus larges est de pouvoir prouver que les décisions de priorité étaient correctes, pas seulement occupées.
L'acheminer dans le helpdesk que vous utilisez déjà
Vous n'avez pas besoin de remplacer votre stack pour faire ça. La couche de priorisation se superpose au helpdesk que vous avez déjà, lit les tickets et écrit en retour les tags, la priorité, l'assignation et les réponses via la même API qu'utilisent vos agents.
C'est le même schéma que vous soyez sur Zendesk, Freshdesk, Gorgias ou HubSpot. Si vous cherchez des options, le récapitulatif des meilleurs logiciels helpdesk IA et nos notes sur les helpdesks spécifiques à l'e-commerce et le support B2B précisent quels outils gèrent la priorisation nativement versus ceux qui ont besoin d'une couche supplémentaire. Pour les équipes Zendesk spécifiquement, il y a une plongée plus profonde dans ses capacités IA et les applications de classification.
Comment je le déploierais concrètement
Si je configurais ça de zéro cette semaine, l'ordre importe plus que les outils :
- Définissez ce que "priorité" signifie pour votre équipe. Notez ce qui saute vraiment la file (pannes, risque de churn, comptes VIP) versus ce qui peut attendre. L'IA a besoin d'une cible.
- Connectez votre helpdesk et vos connaissances. Pointez-le sur des tickets passés et les docs d'aide pour qu'il apprenne vos patterns, pas les suppositions d'un modèle générique.
- Activez d'abord la classification, en mode copilote. Laissez-le étiqueter et noter sans agir, et lisez les résultats pendant une semaine.
- Simulez, puis escaladez par confiance. Faites-le tourner sur des tickets historiques, corrigez les lacunes, puis laissez-le agir seulement là où il est sûr et transférer tout le reste.
- Élargissez l'autonomie au fur et à mesure que les chiffres le confirment. Suivez la précision et le taux de résolution, et n'élargissez ce qu'il gère qu'une fois que les données le justifient.
Pour la version complète étape par étape avec captures d'écran, notre guide pour prioriser les tickets avec l'IA détaille chaque étape, et le récapitulatif des outils de triage IA compare les outils qui le font.
Essayez eesel pour la priorisation de tickets
Si vous voulez ça sans un déploiement de six semaines, eesel AI se connecte à votre helpdesk existant, apprend de vos tickets passés dès le premier jour et commence à classifier, noter et acheminer les tickets en arrière-plan. Les deux choses qui le rendent adapté à la priorisation spécifiquement : le routage basé sur la confiance, pour qu'il n'agisse que là où il est sûr et laisse le reste aux humains, et un mode simulation qui rejoue vos tickets historiques pour que vous voyiez exactement comment il aurait priorisé avant qu'un seul client soit affecté.
La tarification est basée sur l'usage (à partir de 0,40 $ par ticket traité par l'IA, sans frais par siège), et il y a un essai gratuit sans carte, pour que vous puissiez le pointer sur votre propre file et voir où il envoie les choses. Essayez eesel et voyez à quoi ressemble votre vrai backlog une fois que l'urgent arrête de se cacher.








Comment prioriser les tickets de support avec l'IA ?