Comment automatiser le triage des tickets : un guide étape par étape pour les équipes support
Stevia Putri
Katelin Teen
Dernière modification May 15, 2026
Quand votre boîte de réception s'ouvre chaque matin, chaque ticket est marqué URGENT. Les mêmes agents passent la première heure de leur poste non pas à résoudre des problèmes - mais à les trier. 15 à 25 % des tickets qu'ils assignent seront réassignés au moins une fois, ajoutant environ 47 minutes à chaque temps de résolution. Pour une équipe traitant 2 000 tickets par mois avec un taux d'erreur de 35 %, cela représente $329 000 par an en retraitement évitable - sans compter les pénalités de SLA, le churn lié aux résolutions lentes, ou le coût moral d'agents qualifiés réduits au rôle de trieur de boîte de réception.
L'agent helpdesk d'eesel AI lit chaque ticket entrant, le classifie, définit sa priorité, le route vers la bonne file d'attente et signale les risques d'escalade - le tout en moins d'une seconde, avant qu'un humain ne l'ouvre. Les équipes utilisant l'automatisation support d'eesel atteignent généralement 73 %+ de résolution autonome dès le premier mois. Ce guide explique précisément comment y parvenir : ce que le triage implique réellement, où les approches manuelles atteignent leurs limites, et les neuf étapes pour mettre en place un triage automatisé qui tient dans la durée.
Ce que le triage de tickets implique vraiment
Le triage est le travail qui se déroule entre l'arrivée d'un ticket et le moment où un agent commence à le résoudre. Il s'agit de quatre décisions, prises pour chaque ticket :
Classification. De quoi parle ce ticket ? Domaine produit, type de problème, segment client, cause racine, sentiment. Sans classification cohérente, le routage est du hasard et les rapports de tendances sont sans valeur. SentiSum décrit cela comme la construction d'une « taxonomie de tags » - un ensemble défini de catégories avec des définitions en une phrase pour que chaque agent (et chaque IA) applique les mêmes libellés. Au minimum : domaine produit, type de problème, signal d'urgence, sentiment, cause racine et segment client.
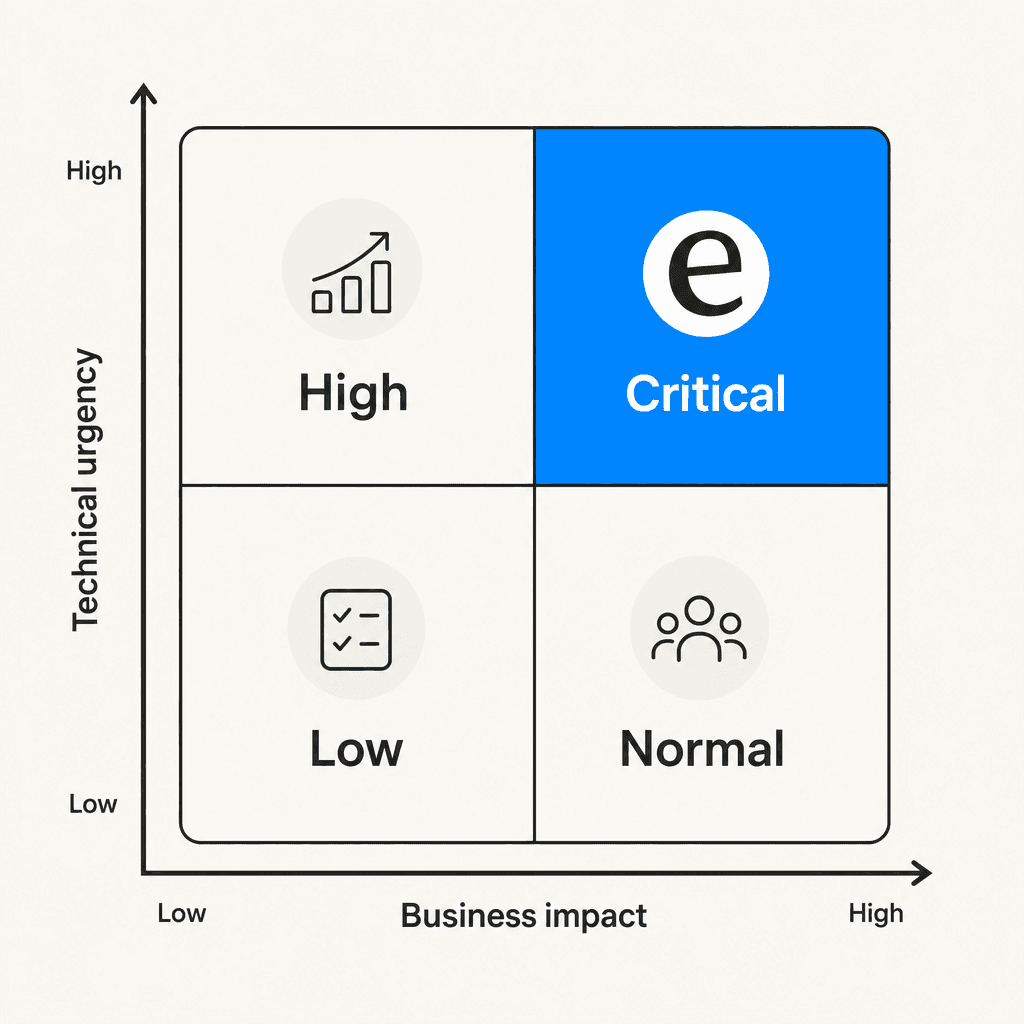
Priorisation. À quel point ce ticket est-il urgent par rapport à tout ce qui est ouvert ? Le cadre ITIL associe deux variables : l'impact métier (combien d'utilisateurs ou d'opérations sont affectés - le domaine du client) et l'urgence technique (quelle est la gravité du problème technique - le domaine de l'équipe support). Ensemble, elles produisent un niveau de priorité. La règle de conception clé : les clients ne fixent pas leur propre étiquette d'urgence. Ils rapportent l'impact. L'équipe support détermine l'urgence.
Routage. Où va ce ticket ? File d'attente, équipe, agent individuel. Les critères de routage incluent généralement le type de problème, les compétences de l'agent, le niveau client (entreprise ou PME), la langue et le canal d'origine.
Escalade. Ce ticket doit-il passer à un niveau supérieur avant que la situation ne s'aggrave ? L'escalade manuelle dépend d'un agent qui remarque un problème - une chaîne qui se brise sous le volume, surtout pour les tickets à fort sentiment qui ne semblent pas urgents à première vue.
Le coût d'une erreur sur l'une de ces quatre décisions est concret. Une équipe traitant 2 000 tickets par mois avec un taux d'erreur de 35 % - 700 tickets réassignés, chacun ajoutant 47 minutes de retraitement - accumule une facture de main-d'œuvre de $329 000 par an avant même de compter une seule violation de SLA. À $50/heure. À $75/heure, le chiffre grimpe à près de $500 000.
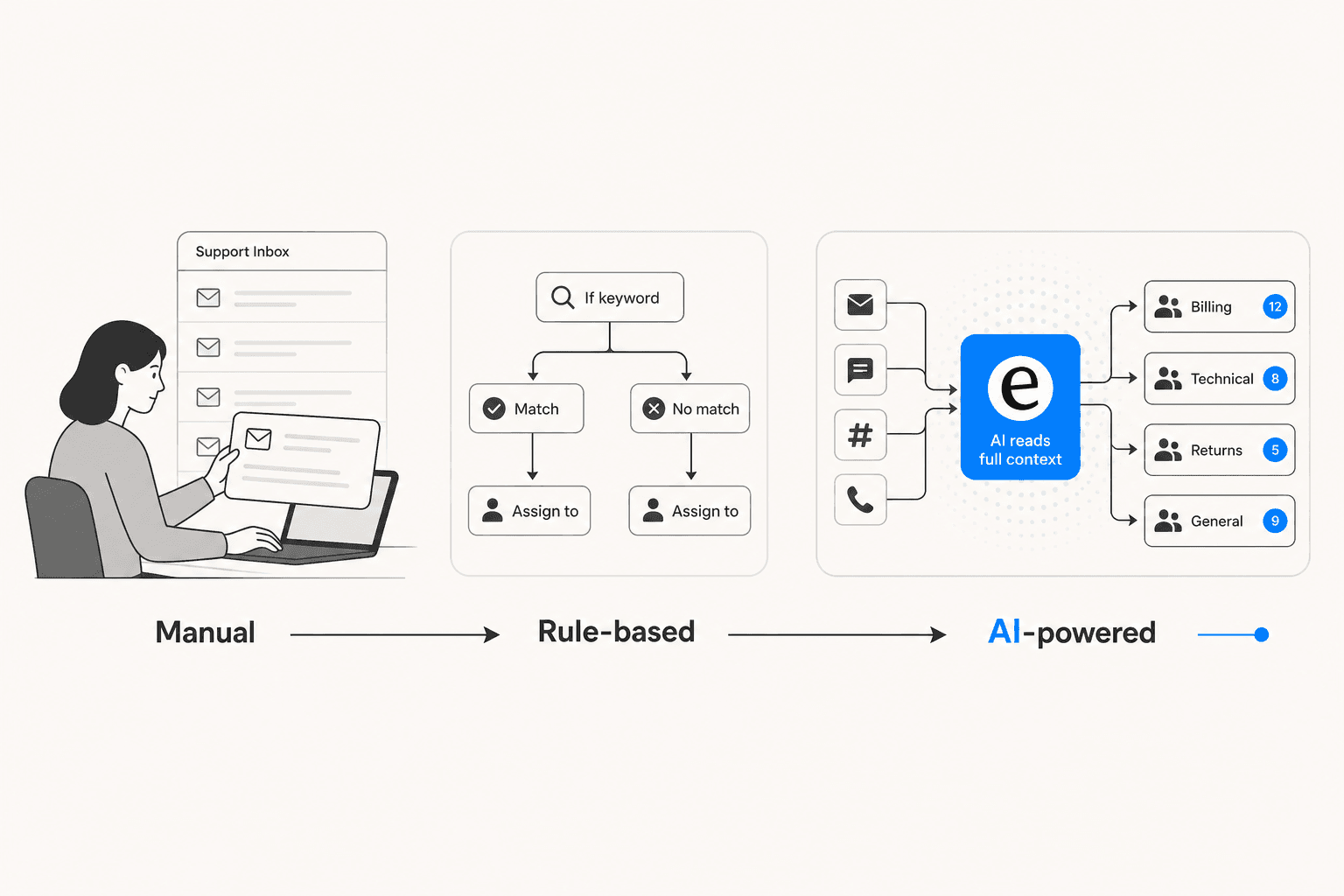
Pourquoi le triage manuel et basé sur des règles atteint ses limites
La plupart des équipes support commencent par l'une de deux approches. Toutes deux ont des plafonds rigides.
Le triage manuel signifie qu'une personne - ou un rôle de triage tournant au sein de l'équipe - lit chaque ticket entrant et prend les quatre décisions à la main. SentiSum a documenté le cas GoCardless qui employait deux agents à temps plein dédiés uniquement à la classification des tickets, en utilisant trois tags de sévérité (B1, B2, B3). Le travail de classification était suffisamment constant pour que son automatisation libère les deux ETP. Le triage manuel prend 1 à 3 minutes par ticket, se dégrade sous le volume et varie selon l'humeur de l'agent et le poste de travail.
L'automatisation basée sur des règles est l'amélioration évidente : une logique si/alors basée sur des mots-clés, des domaines d'e-mail, des champs de formulaire et des lignes d'objet. Chaque helpdesk le propose - les déclencheurs Zendesk, les automatisations Freshdesk, les files SLA Jira. Cela gère bien les types de tickets simples et stables, et se configure rapidement. Le plafond est bas : IrisAgent mesure la précision du routage basé sur des règles à 40-50 %. Les règles échouent sur les synonymes et les fautes de frappe, ne fonctionnent pas sur les tickets multi-problèmes, n'ont pas de conscience du sentiment et nécessitent des mises à jour manuelles constantes à mesure que le produit évolue. Le lancement d'une nouvelle fonctionnalité déclenche une nouvelle série de maintenance des règles.
Une observation tirée d'un fil r/msp de 86 commentaires sur la surcharge de triage capture le mode d'échec opérationnel commun aux deux approches :
"La leçon la PLUS importante que j'ai apprise bien trop tard : vous DEVEZ TRIER TOUS LES TICKETS AVANT D'EN DISPATCHER UN SEUL. Triez-les tous, puis dispatchez-les tous. Pas un par un."
Quand le triage et le dispatch se produisent simultanément - ce qui est le défaut dans tout système manuel ou basé sur des règles simples - les tickets urgents se retrouvent enfouis sous des arrivées antérieures, non urgentes. La boîte de réception devient une file ordonnée par heure d'arrivée, pas par priorité.
Le triage piloté par IA brise les deux plafonds. Il lit le contenu complet du ticket, l'historique de la conversation, le sentiment du client et le contexte du compte, puis prend les quatre décisions de triage en moins d'une seconde. IrisAgent mesure la précision du routage IA à 85-95 % dans les déploiements matures - contre le plafond de 40-50 % des règles - avec une cohérence des tags supérieure à 90 % et 50 % de réassignations en moins.
Comment automatiser le triage des tickets avec eesel AI
L'agent helpdesk d'eesel AI se connecte à votre helpdesk existant - Zendesk, Freshdesk, Gorgias, HubSpot, et d'autres - et apprend votre fonctionnement immédiatement à partir de vos tickets passés, macros, articles du centre d'aide et documentation connectée. Aucune formation manuelle, aucun assistant de configuration.
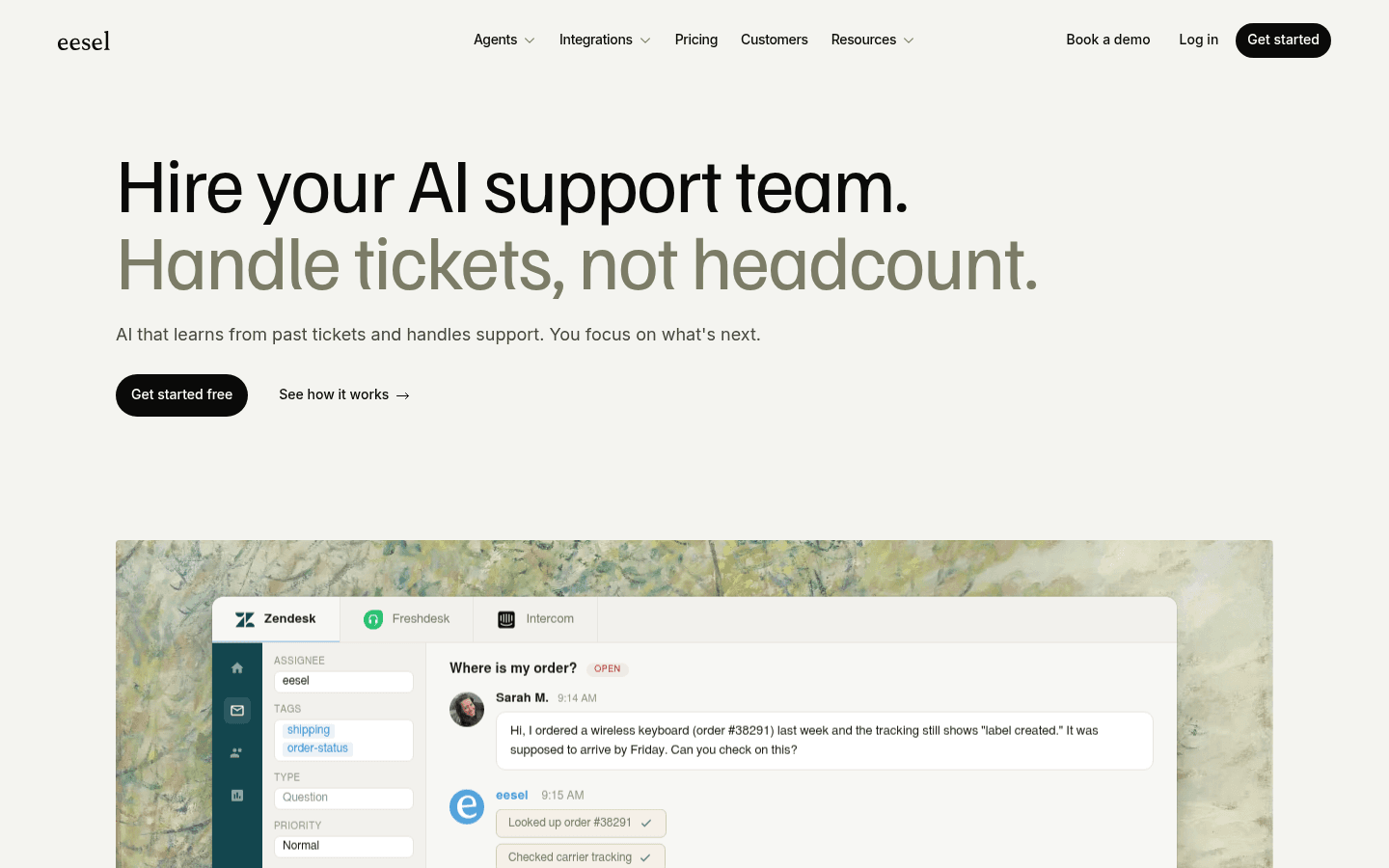
Pour le triage, eesel gère les quatre décisions :
- Classification : étiquette les tickets par type de problème, domaine produit, sentiment et segment client selon votre taxonomie existante
- Priorisation : évalue chaque ticket par rapport à votre matrice de priorités définie, en tenant compte du niveau client, de la proximité du SLA et du sentiment en temps réel
- Routage : assigne les tickets à la bonne file ou au bon agent selon les compétences, la langue, la capacité et le canal
- Escalade : surveille les signaux de churn, le risque SLA et la dégradation du sentiment, et escalade avant qu'une situation ne s'aggrave
Ce qui distingue eesel d'un moteur de règles, c'est le mode simulation. Avant la mise en production, eesel s'exécute sur des milliers de vos tickets historiques et montre exactement comment il aurait trié chacun - vous pouvez ainsi comparer les décisions de l'IA à ce que vos agents ont réellement fait, calibrer les divergences et lancer en production en toute confiance. Aucun ticket client en direct n'est à risque pendant les tests.
Les déploiements eesel matures atteignent jusqu'à 81 % de résolution autonome. Gridwise a résolu 73 % des demandes de niveau 1 dès le premier mois. Smava traite plus de 100 000 tickets par mois via eesel en allemand, entièrement automatisé.
Le déploiement est délibérément progressif : commencez avec eesel qui rédige des réponses pour révision par les agents sur quelques types de tickets, vérifiez la précision, puis élargissez son autonomie au fur et à mesure que la confiance se construit - de la même façon que vous promovriez tout nouveau membre de l'équipe sur la base de ses performances démontrées.
Mettre en place un triage automatisé : les 9 étapes
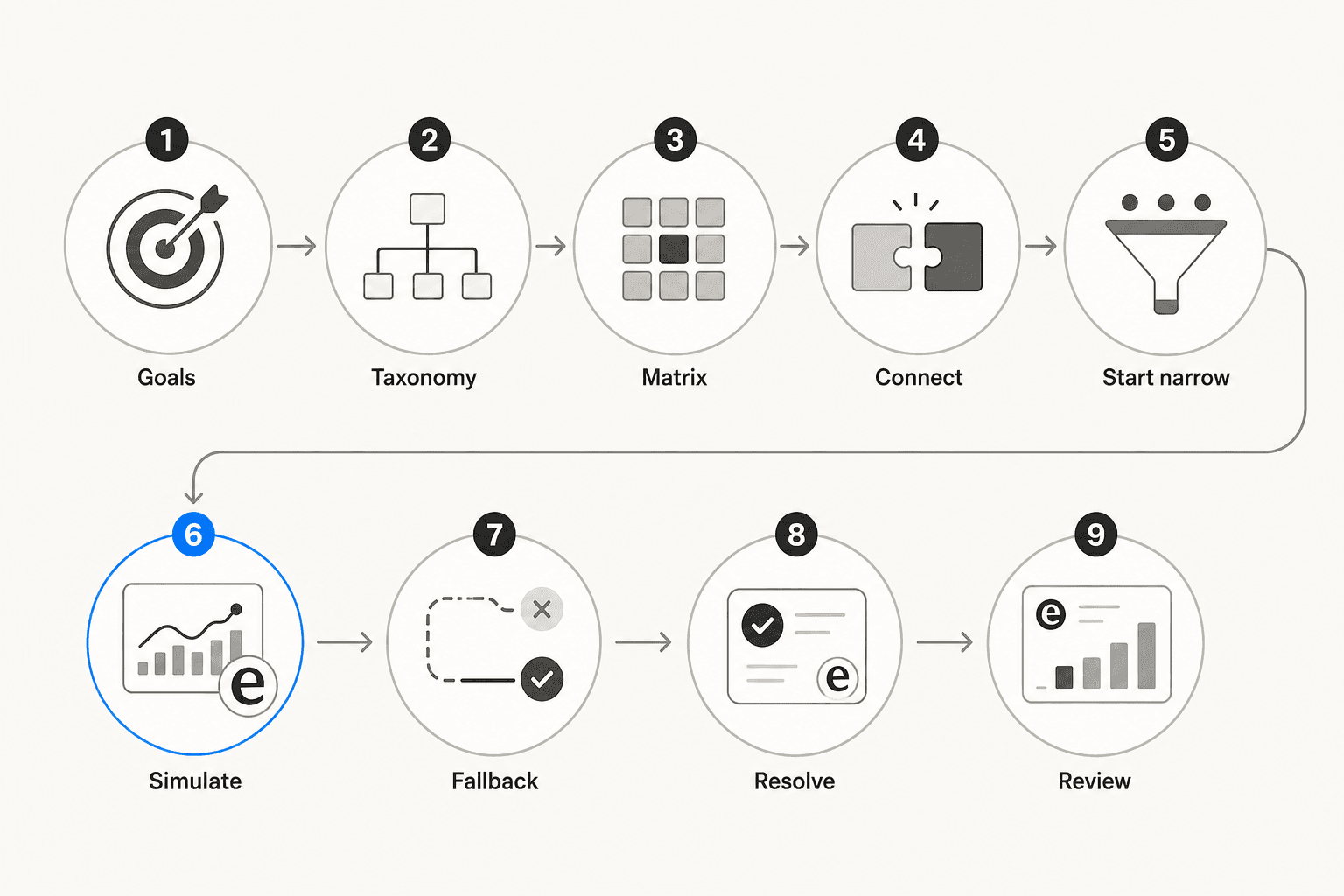
Étape 1 : Définir vos objectifs et vos SLA
Avant de toucher à tout outil, décidez à quoi ressemble le succès. SentiSum recommande de s'ancrer sur des questions spécifiques et mesurables : Quel segment client a besoin d'une réponse plus rapide ? Quel type de ticket cause le plus de violations de SLA ? Quel est le temps de première réponse actuel pour les tickets Critiques ?
Définissez des objectifs SLA explicites par niveau de priorité. Les meilleures pratiques d'eesel AI suggèrent quelque chose comme : Critique = réponse en 15 minutes, Élevé = 1 heure, Normal = 8 heures, Faible = 24 heures. Les chiffres exacts importent moins que leur cohérence. Une fois les SLA définis, l'automatisation du triage dispose d'une condition de succès claire.
Étape 2 : Construire une taxonomie de tags propre
Cartographiez toutes les catégories de tickets sur lesquelles vous devez agir, et rédigez une définition en une phrase pour chacune. Le guide d'IrisAgent est direct : « Si votre taxonomie de tags compte 200 catégories qui se chevauchent, l'automatisation accélère simplement le désordre. Nettoyez la taxonomie avant d'entraîner un quelconque modèle. »
Regroupez les tags redondants, supprimez ceux inutilisés et standardisez avant de connecter toute automatisation. Couvrez au minimum : domaine produit, type de problème, signal d'urgence, sentiment, cause racine et segment client. Le plafond de précision de l'IA est fixé par la clarté des catégories - une taxonomie floue produit un modèle flou.
Étape 3 : Créer une matrice de priorités
Construisez une grille 2×2 croisant impact × urgence en quatre niveaux : Critique, Élevé, Normal, Faible. Le guide d'eesel AI et plusieurs praticiens de r/msp recommandent tous deux cette approche, issue du cadre ITIL.
Règle de conception critique : les clients contrôlent l'impact (« combien d'utilisateurs sont bloqués ? »), votre équipe contrôle l'urgence (« quelle est la gravité du problème technique ? »). Ne laissez jamais les clients s'attribuer eux-mêmes un niveau de priorité. Utilisez des questions d'entrée structurées qui produisent des réponses objectives - « Y a-t-il une solution de contournement ? » et « Combien d'utilisateurs sont affectés ? » - et mappez automatiquement ces réponses vers un niveau.
Étape 4 : Connecter votre helpdesk et importer l'historique des tickets
Installez eesel AI via la marketplace de votre helpdesk et importez 6 à 12 mois de tickets résolus. IrisAgent recommande cet import historique comme le moyen le plus rapide d'obtenir un étiquetage précis dès le premier jour - le modèle s'entraîne sur vos données réelles, votre terminologie et vos schémas de résolution plutôt que sur une base générique du secteur.
Pour le triage basé sur des règles : identifiez les déclencheurs (domaine e-mail, mots-clés de l'objet, canal) et configurez-les directement dans les paramètres de votre helpdesk.
Étape 5 : Commencer par vos 3 à 5 intentions à plus fort volume
N'automatisez pas tout dès le premier jour. IrisAgent est explicite : choisissez les 3 à 5 intentions à plus fort volume - réinitialisations de mot de passe, statut de commande, questions de facturation - et prouvez une précision de 90 %+ sur celles-ci avant d'élargir. Une couverture complète dès le premier jour signifie une précision médiocre partout, ce qui érode la confiance de l'équipe avant qu'elle ait eu une chance de se construire.
Étape 6 : Simuler avant la mise en production
Exécutez votre configuration de triage sur des tickets historiques en mode simulation avant qu'elle ne touche un client en direct. La fonctionnalité de simulation d'eesel AI montre comment l'IA aurait géré des milliers de tickets passés - lesquels elle aurait routés correctement, lesquels incorrectement, et lesquels elle aurait escaladés - pour que vous puissiez calibrer avant le lancement. Cela élimine le risque de découvrir des problèmes à travers des réclamations clients.
Étape 7 : Concevoir le chemin de repli
Quand le score de confiance de l'IA tombe en dessous de votre seuil, le ticket doit être routé vers le triage humain avec le raisonnement de l'IA joint - et non forcer une décision à faible confiance. IrisAgent appelle cela le mécanisme de confiance : les replis à échec total détruisent la confiance plus vite qu'un mauvais routage occasionnel. La file de repli est aussi le filet de sécurité pour les tickets inédits qui ne correspondent pas aux schémas d'entraînement.
Étape 8 : Résoudre au moment du triage, pas après
Le triage est la première opportunité de résoudre un ticket, pas seulement de le trier. Wrangle et DevRev décrivent tous deux une IA agentique qui clôture les réponses aux problèmes connus, les requêtes pratiques (en puisant dans la base de connaissances), les consultations de compte et les accusés de réception de demandes de fonctionnalités - sans router vers un agent. Le client DevRev BILL a atteint 70 %+ de résolution autonome en intégrant la résolution à l'étape de triage. Le benchmark pour un triage IA mature est d'environ 60 % de résolution automatique.
Étape 9 : Fermer la boucle chaque semaine
Chaque correction manuelle effectuée par un agent après un mauvais routage est un signal d'entraînement. IrisAgent recommande de passer en revue les tickets mal étiquetés chaque semaine et d'alimenter les corrections dans le modèle. Les équipes qui maintiennent cette cadence atteignent une couverture de triage automatique à 100 % en 60 à 90 jours. Sautez la boucle pendant un trimestre et la précision se dégrade silencieusement - ce qu'IrisAgent appelle « la dérive de l'automatisation » - au fur et à mesure que le produit évolue et que le mix de tickets change.
Les erreurs courantes qui tuent les projets de triage automatisé
La plupart des échecs d'automatisation du triage sont des échecs de processus, pas des défaillances de modèle.
Laisser les clients auto-déclarer leur priorité. Kirsty Pinner, Head of Product dans une entreprise d'analyse du service client, via SentiSum : « L'une des choses que la plupart des entreprises font mal, c'est de laisser les clients auto-déclarer les problèmes dans les formulaires. Cela crée une méfiance inhérente dans toute analyse ultérieure. » Quand chaque client peut marquer son propre ticket Critique, le mot ne veut plus rien dire. Utilisez plutôt des questions d'entrée structurées liées à des critères objectifs.
Automatiser une taxonomie désordonnée. Si vos tags se chevauchent et sont appliqués de manière incohérente avant l'automatisation, ils se chevaucheront et seront appliqués de manière incohérente plus vite après l'automatisation. L'IA ne corrige pas la taxonomie - elle l'amplifie.
Vouloir tout couvrir dès le premier jour. Ce qui arrive quand les équipes se précipitent vers une couverture totale, d'après r/automation :
"Quelques erreurs suffisent à faire perdre confiance à votre équipe en votre agent, ce qui est la pire chose qui puisse arriver. Une fois qu'ils ne lui font plus confiance, ils vont tout vérifier en double et l'automatisation est pratiquement morte."
Une logique d'escalade floue. C'est la source de la plupart des plaintes relatives au triage IA en production :
"La plupart des problèmes ne sont pas des problèmes de modèle. Ce sont des problèmes de politique. Si votre logique d'escalade est floue, l'IA amplifie simplement le flou."
u/DFSautomations, r/automation
Avant d'accuser le modèle de mauvaises décisions d'escalade, vérifiez si vos règles d'escalade sont suffisamment claires pour qu'un humain les suive de manière cohérente. Si ce n'est pas le cas, aucune configuration IA ne pourra les corriger.
Dispatcher avant d'avoir trié toute la file. D'après r/msp : triez d'abord tous les tickets de la file, puis dispatchez. Le dispatch un par un enterre les tickets urgents sous des tickets non urgents arrivés simplement plus tôt.
Sauter la révision de correction hebdomadaire. La précision se dégrade à mesure que votre produit évolue et que le mix de tickets change. La boucle de correction est ce qui maintient le modèle à jour. Sans elle, vous utilisez un modèle périmé et vous ne le saurez pas avant que les violations de SLA ne commencent à apparaître.
Essayez eesel AI
L'agent helpdesk d'eesel AI gère le triage des tickets de bout en bout - classification, priorisation, routage et escalade - par-dessus votre helpdesk existant. Vous le connectez, exécutez des simulations sur des tickets passés pour vérifier la qualité avant la mise en production, et élargissez son autonomie à votre propre rythme au fur et à mesure qu'il gagne en confiance. La tarification est basée sur les tâches à $0,40 par ticket standard, avec un essai gratuit sans carte de crédit requise.