
Résumé
Oui, vous pouvez automatiser le tagging des tickets avec l'IA, et c'est l'une des choses à plus fort levier qu'une IA peut faire dans votre helpdesk car elle touche tout ce qui suit : le routage, le reporting, les SLA et les tickets que vos meilleurs agents finissent par voir. Le mécanisme est simple. L'IA lit chaque ticket entrant, détecte l'intention, la langue et le sentiment, compare avec votre liste de tags et applique le tag (ou route le ticket) avant qu'un humain ne l'ouvre.
Le problème n'est presque jamais l'IA. C'est votre liste de tags. Donnez à un modèle une taxonomie touffue et qui se chevauche, et il taguera de manière incohérente, de la même façon qu'un nouvel employé le ferait. Le vrai travail consiste donc à : assainir vos tags, entraîner l'IA sur vos tickets passés, la tester sur votre propre historique et n'activer l'application automatique que lorsque la précision se maintient.
Votre helpdesk a probablement une option native (triage intelligent Zendesk, triage automatique Freshdesk, règles Gorgias), et elles sont solides, mais la plupart sont bloquées derrière un module complémentaire par agent et un plan spécifique. Si vous préférez entraîner le tagging sur vos propres tickets résolus et le simuler avant de le mettre en production, c'est exactement ce que fait une couche IA comme eesel, par-dessus le helpdesk que vous utilisez déjà.
Ce que « tagger les tickets avec l'IA » signifie vraiment
Je gère la file de support d'eesel, alors je serai honnête sur la valeur que ça apporte. Les tags sont ennuyeux. Personne n'est entré dans le support client parce qu'il adorait choisir « Facturation » dans un menu déroulant quarante fois par jour. Mais les tags sont aussi la colonne vertébrale d'un helpdesk organisé : ils décident dans quelle équipe un ticket atterrit, quelle règle de routage de tickets se déclenche, ce que dit votre rapport hebdomadaire sur les tendances et si l'horloge SLA démarre avec la bonne priorité.
Automatiser ça signifie confier l'étape de lecture et d'étiquetage à une IA. Sous le capot, presque tous les outils font les mêmes quatre choses : ils lisent le message, le classifient (intention, langue, sentiment, parfois des entités nommées comme un numéro de commande), font correspondre cette classification à un tag de votre liste et l'appliquent. Les bons remplissent aussi les champs du ticket et le routent dans le même passage.
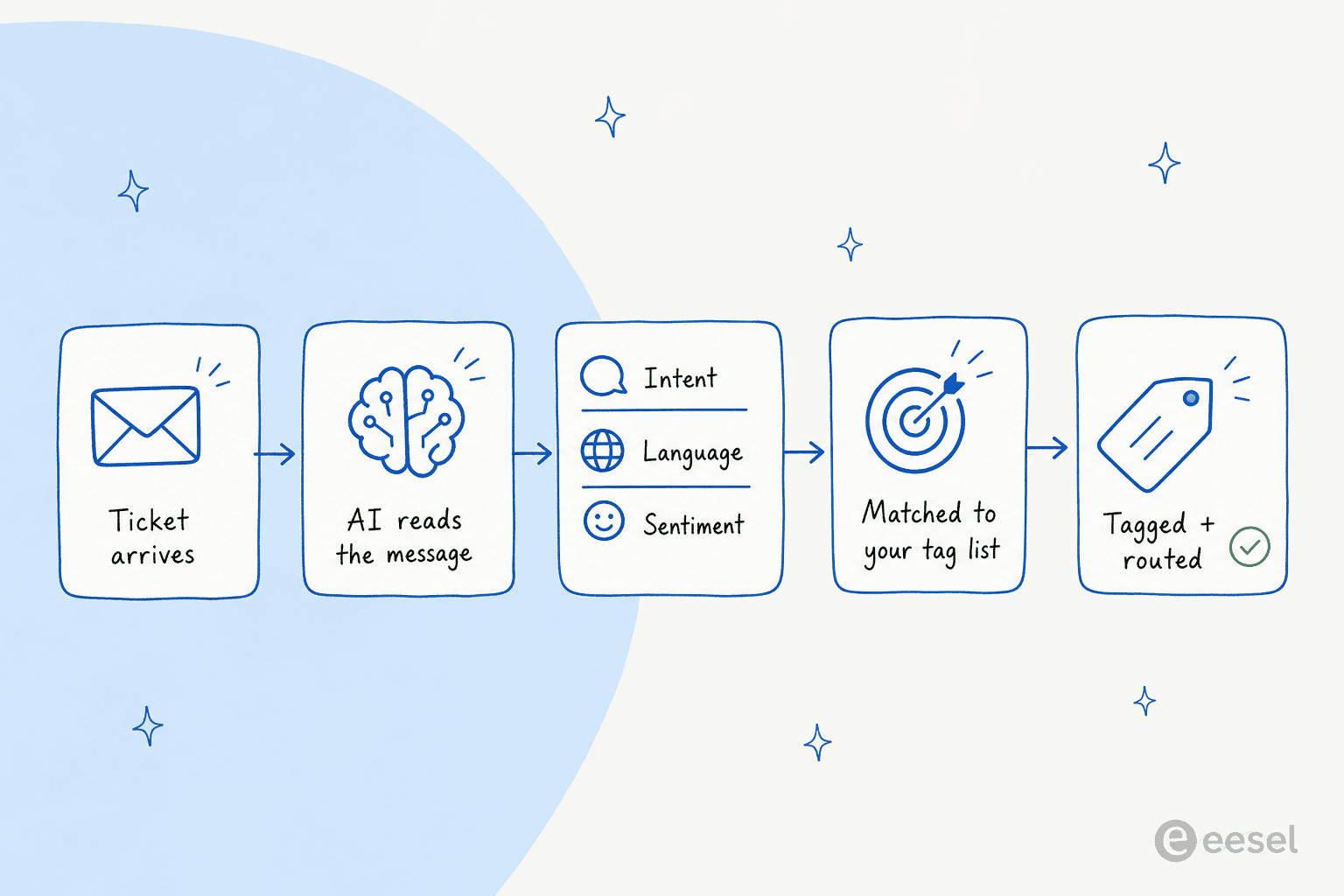
Ce qui m'a le plus surpris quand je l'ai vu tourner sur de vrais tickets, c'est combien de contexte il capte. Nous avons eu un pitch commercial froid qui est arrivé comme un ticket (quelqu'un essayant de nous vendre une liste de contacts), et au lieu de flancher, l'IA l'a comparé à des tickets passés, l'a reconnu comme du spam, l'a tagué et a laissé un refus poli en note interne. C'est la différence entre une classification de tickets par IA qui fait de la correspondance de mots-clés et une qui comprend vraiment de quoi parle le ticket.
Pourquoi le tagging manuel s'effondre silencieusement
Si votre tagging est encore manuel, voici ce qui se passe réellement, et vous avez probablement ressenti les trois.
Les agents le sautent. Quand la file est chargée, le tagging est la première chose à partir, donc la moitié de vos tickets finissent sans tag ou déversés dans un tag fourre-tout « général ». Ensuite vos rapports vous mentent, parce que les données n'ont jamais été propres dès le départ.
Tout le monde tague différemment. Un agent utilise « remboursement », un autre « remboursements », un troisième « retour-remboursement ». Vous avez maintenant trois tags pour un seul concept et aucun moyen fiable de compter combien de tickets de remboursement vous avez vraiment reçu. C'est la principale raison pour laquelle les projets d'analyse de tickets de support s'enlisent.
Et ça ne passe pas à l'échelle. Une équipe gérant quelques centaines de tickets par semaine peut s'en sortir. Une équipe gérant des tickets en volume élevé ne peut pas, et c'est exactement là où les tags cohérents importent le plus, parce que c'est là où le routage et les SLA font le travail de fond.
Les mauvais tags sont pires qu'aucun tag, parce qu'ils ressemblent à un signal. Un tableau de bord construit sur un tagging incohérent vous donne des chiffres confiants, mais faux, et vous prenez des décisions de personnel sur cette base.
Comment automatiser le tagging des tickets avec l'IA, étape par étape
Voici le déploiement que j'exécuterais vraiment, dans l'ordre. Il est délibérément prudent au milieu, parce que le mode d'échec n'est pas « l'IA ne peut pas tagger », c'est « l'IA a tagué 10 000 tickets de travers avant que quelqu'un ne vérifie ».
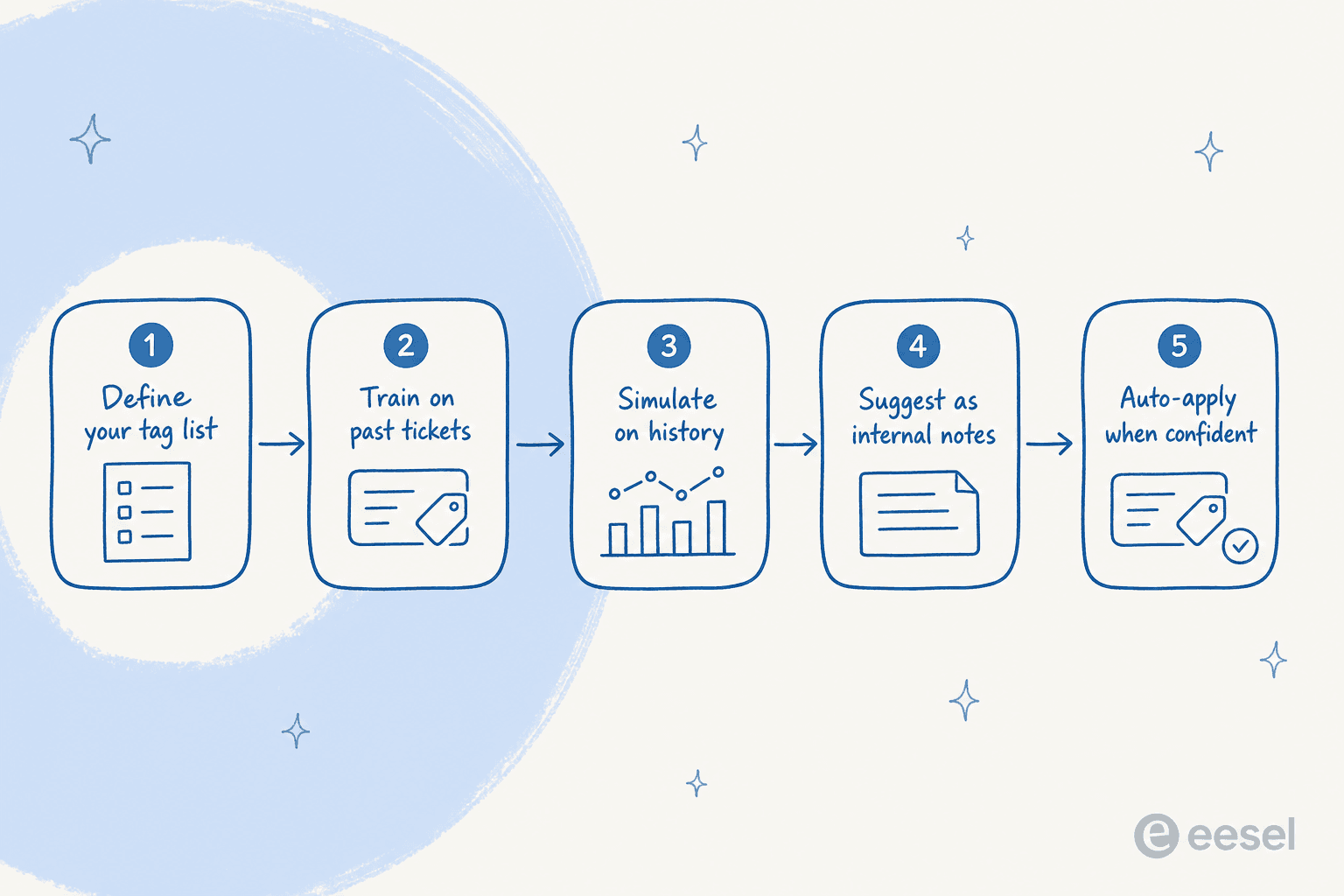
1. Auditer et assainir votre liste de tags d'abord
C'est l'étape que tout le monde veut sauter, et c'est celle qui décide si tout fonctionne. Récupérez votre liste de tags actuelle et soyez impitoyable : fusionnez les doublons (« remboursement » et « remboursements »), supprimez les tags sur lesquels personne ne route ni ne reporte, et visez un petit ensemble de catégories distinctes et non chevauchantes. L'IA ne peut être cohérente qu'autant que la liste que vous lui donnez.
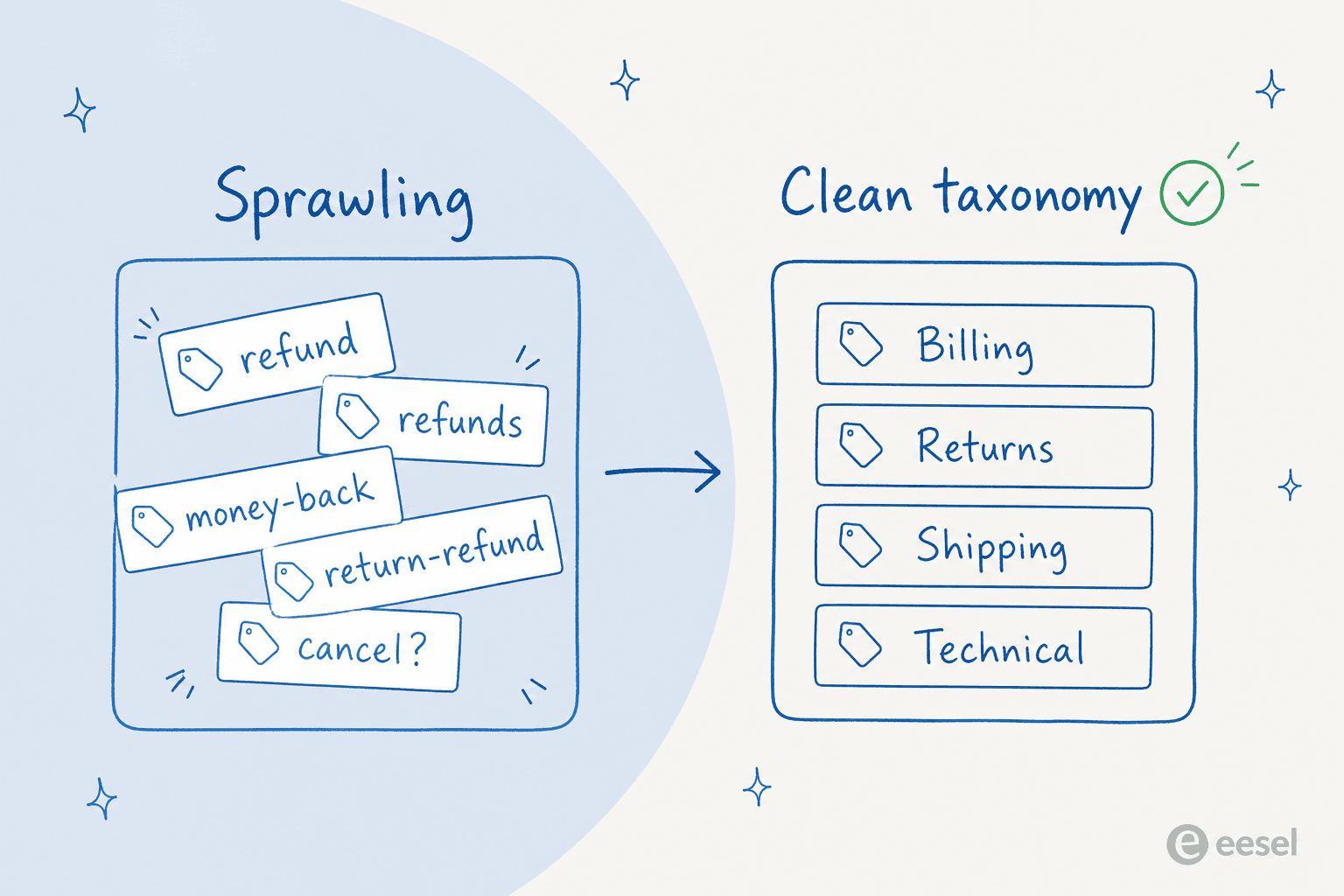
Un bon test : si deux personnes de votre équipe ne seraient pas d'accord sur quel tag un ticket reçoit, l'IA ne le sera pas non plus. Corrigez l'ambiguïté au niveau de la taxonomie, pas avec un prompt plus intelligent. Notre guide sur travailler avec les tags de tickets a une liste de contrôle plus complète si vous en avez besoin.
2. Entraîner l'IA sur vos tickets passés
Les modèles génériques taguent de manière générique. La différence entre un modèle qui tague comme votre meilleur agent et un qui devine, c'est s'il a appris de vos vrais tickets résolus. Vos tickets historiques sont les données d'entraînement : ils contiennent déjà le bon tag, les formulations réelles qu'utilisent vos clients et les cas limites.
C'est aussi là où certains outils natifs fixent un plancher : le triage automatique de Freshdesk, par exemple, a besoin d'environ 2 000 tickets historiques avant de prédire les champs de manière fiable. Si vous gérez une file plus modeste, préférez un outil qui peut aussi apprendre de votre documentation d'aide et de vos macros, pas seulement du volume de tickets.
3. Simuler avant de toucher un ticket en direct
C'est l'étape que je ne sauterais jamais. Avant que quoi que ce soit ne parte en production, faites tourner le modèle sur un lot de vos tickets historiques et comparez ses tags à ceux qu'a appliqués votre équipe. Vous cherchez deux chiffres : à quelle fréquence il s'accorde avec votre équipe, et là où il est confiant mais en désaccord (ce sont vos problèmes de taxonomie qui apparaissent).
Une simulation sur des tickets passés transforme « on pense que c'est précis » en « il était d'accord avec nous sur 91 % des tickets de facturation du dernier trimestre ». C'est le chiffre que vous apportez à votre manager avant d'activer le système.
4. Démarrer en mode suggestion, pas en application automatique
Faites d'abord tourner l'IA comme copilote : elle suggère un tag, laisse une note interne ou pré-remplit le champ, et un humain confirme. Ça construit la confiance et attrape les cas étranges pendant qu'une personne est encore dans la boucle. Comme me l'a dit un responsable CX, l'objectif est une IA qui ne gère que ce dont elle est sûre et laisse le reste tranquille. Cet instinct est correct, et c'est toute la raison pour laquelle les seuils de confiance existent.
5. Activer l'application automatique pour les cas confiants et surveiller les rapports
Une fois que le mode suggestion s'accorde régulièrement avec votre équipe, laissez l'IA appliquer automatiquement les tags au-dessus d'un seuil de confiance et gardez ceux à faible confiance en suggestions. Ensuite, surveillez la distribution de vos tags dans les rapports pendant les premières semaines. Si un tag fait soudainement un pic, c'est soit une vraie tendance, soit un bug de tagging, et dans les deux cas vous voulez le savoir. Des tags propres, c'est ce qui rend vos métriques de service client à nouveau fiables.
Vos options, par helpdesk
La plupart des helpdesks embarquent désormais une forme de tagging IA natif. Voici un état des lieux honnête, avec le piège de chacun, pour que vous puissiez décider si le natif suffit ou si vous voulez une couche dédiée par-dessus.
| Outil | Ce qu'il tague | Plan nécessaire | Prix de départ | Le piège |
|---|---|---|---|---|
| Zendesk intelligent triage | Sujet, sentiment (5 points), langue (~150), entités dans des champs personnalisés | Suite/Support Professional + module complémentaire Copilot | 50 $/agent/mois (annuel) | Les valeurs de triage ne sont disponibles qu'en anglais lors de la création de déclencheurs, de vues et de rapports |
| Freshdesk auto triage | Priorité, Groupe, Type, champs personnalisés, intention, sentiment (0-100) | Pro/Enterprise + Freddy AI Copilot | ~84 $/agent/mois tout compris | Nécessite ~2 000 tickets pour s'entraîner ; Email et Portail uniquement ; les règles existantes supplantent l'IA |
| Gorgias intents + rules | Taxonomie d'intention, sentiment, puis une règle applique le tag | Tous les plans Helpdesk (intentions granulaires nécessitent AI Agent) | À partir de 10 $/mois | Limite de 70 règles ; les sentiments ne peuvent pas être modifiés manuellement |
| eesel (couche par-dessus) | Intention, langue, sentiment, tags personnalisés de votre liste, remplissage de champs, routage | Fonctionne avec votre helpdesk existant | 0,40 $ par ticket, sans frais par siège | S'ajoute au helpdesk plutôt que de remplacer son IA native |
Zendesk
Le triage intelligent de Zendesk classifie automatiquement chaque ticket entrant par sujet, sentiment sur une échelle de 5 points et langue sur environ 150 langues détectées, plus des entités définies par l'administrateur qui remplissent automatiquement des champs personnalisés via des règles d'extraction. Depuis mi-2026, le champ « Intent » a été renommé « Topic », les anciens champs d'intention générant toujours leurs tags associés.
Deux choses à savoir : cela nécessite le module complémentaire Copilot (anciennement « Advanced AI »), qui coûte 50 $/agent/mois facturé annuellement sur Suite ou Support Professional et supérieur, et les valeurs de triage ne sont visibles qu'en anglais quand vous construisez des déclencheurs, des vues ou des rapports, même si ça classifie ~150 langues. Si vous voulez aussi rédiger des réponses avec l'IA dans Zendesk, c'est une capacité séparée qui s'appuie sur les mêmes tickets.
Freshdesk
Le triage automatique de Freshdesk est une fonctionnalité de Freddy AI Copilot qui prédit la Priorité, le Groupe, le Type, les menus déroulants personnalisés et les champs imbriqués en lisant le sujet et la description du ticket avec l'intention et le sentiment. Vous pouvez le faire tourner en mode manuel (il suggère) ou automatique (il applique à la création), et une fonctionnalité de sentiment séparée note les tickets de 0 à 100.
Les pièges s'accumulent. C'est bloqué derrière un plan Pro ou Enterprise plus le module complémentaire payant Freddy AI Copilot, ce qui pousse le plancher réaliste de tarification Freddy à environ 84 $/agent/mois. Il nécessite environ 2 000 tickets historiques pour s'entraîner, ne se déclenche que sur les canaux Email et Portail, peut prendre jusqu'à deux jours pour s'activer par champ, et vos règles d'automatisation existantes supplantent toujours les suggestions de l'IA. Rien de tout ça n'est rédhibitoire, mais c'est beaucoup à planifier. Si vous optimisez la configuration plus large, notre guide sur comment automatiser Freshdesk couvre le reste.
Gorgias
Gorgias le fait en deux parties. Son IA classifie chaque message entrant contre une taxonomie d'intention fixe plus un sentiment (Positif, Négatif, Neutre et un « promoter » plus récent), puis une règle déterministe QUAND/SI/ALORS lit ces intentions et sentiments de messages et applique le vrai tag. La détection basique d'intention et de sentiment plus le constructeur de règles sont disponibles sur tous les plans Helpdesk à partir de 10 $/mois, avec un modèle prêt à l'emploi « Identifier les intentions et les sentiments » pour bien démarrer.
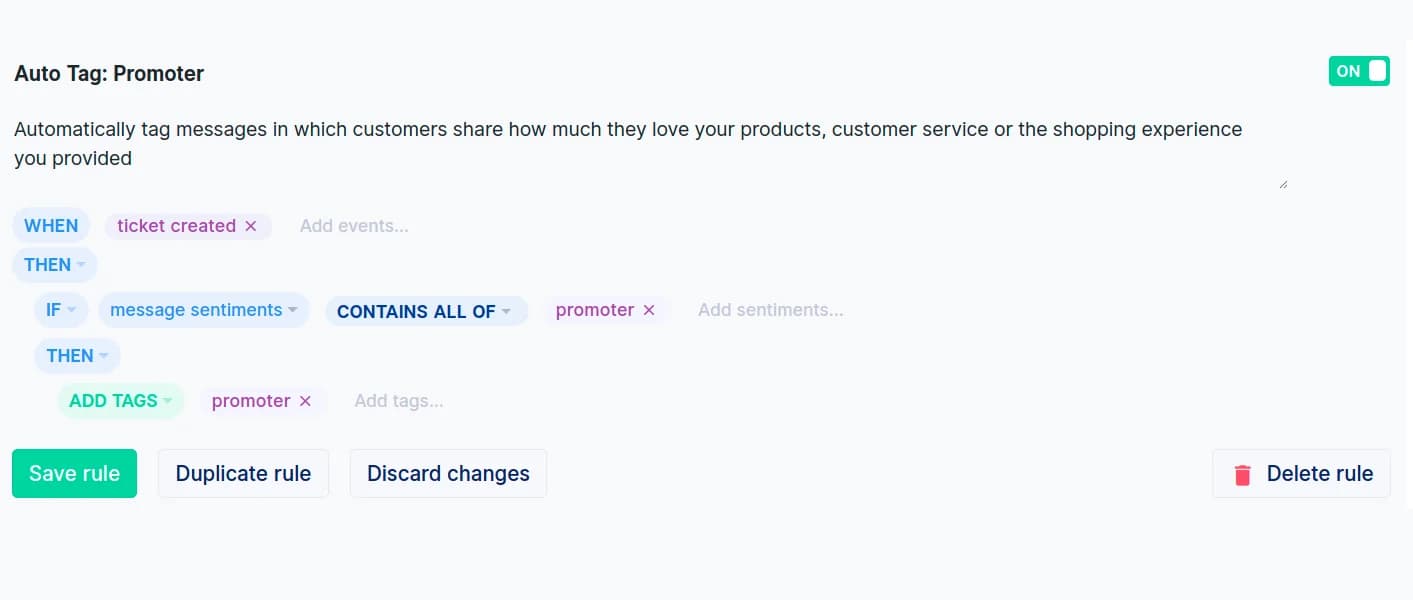
La taxonomie d'intention plus riche et granulaire et la page d'analyse des intentions se trouvent derrière un abonnement AI Agent séparé. Attention aux limites : il y a un plafond de 70 règles, un ordre d'exécution de priorité de déclencheur fixe, et les sentiments ne peuvent pas être modifiés manuellement, donc si l'IA qualifie un ticket de « Neutre » vous ne pouvez pas l'annuler à la main. Les règles d'auto-réponse de Gorgias suivent le même constructeur si vous voulez agir sur ces tags.
Le cas pour une couche IA dédiée
Alors quand le natif ne suffit-il pas ? D'après mon expérience, ça se résume à trois choses : vous êtes sur un helpdesk dont l'IA native est mince, vous ne voulez pas payer par agent pour un module complémentaire, ou vous voulez tagger de la même façon sur plus d'un outil. C'est le manque qu'une couche dédiée comble, et ça vaut la peine d'être clair sur l'échange.
L'argument le plus fort pour une couche est qu'elle s'entraîne sur vos tickets résolus et vous permet de simuler avant de passer en production. Une équipe danoise de télématique de véhicules B2B avec laquelle j'ai travaillé, qui s'étendait sur les marchés allemand, espagnol et italien, voulait exactement ça : un tagging automatique depuis sa propre liste de tags définie, un remplissage automatique de champs, des workflows d'escalade et des tickets traduits en anglais pour les agents avec des réponses renvoyées dans la langue du client, le tout par-dessus Zendesk. Le triage natif gère la première partie ; le reste, c'est là qu'une couche justifie sa place.
Le contre-argument honnête : une couche est un outil de plus dans la pile, et si le tagging natif de votre helpdesk couvre déjà vos besoins et que vous le payez de toute façon, ajouter un autre système est excessif. Utilisez le tableau ci-dessus. Si vous n'avez besoin que de tags de sujet et de sentiment et que vous êtes déjà sur le bon plan Zendesk, le natif est probablement suffisant.
Erreurs courantes que j'éviterais
Quelques pièges dans lesquels les équipes tombent, dans l'ordre approximatif de la douleur qu'ils causent :
- Automatiser une taxonomie désordonnée. Évoqué plus haut, mais ça vaut la peine de répéter : assainissez la liste de tags avant d'automatiser, pas après. L'automatisation amplifie la cohérence (ou le chaos) avec laquelle vous démarrez.
- Passer directement à l'application automatique. Sauter le mode suggestion signifie que votre premier signe d'un problème de tagging est un mauvais tableau de bord trois semaines plus tard. Méritez l'application automatique.
- Pas de seuil de confiance. Une IA forcée à tagger chaque ticket, même les ambigu, va deviner. Laissez-la laisser les tickets vraiment peu clairs à un humain, et vous réduirez fortement les faux positifs.
- Configurer et oublier. Vos produits, promotions et le langage de vos clients évoluent. Revérifiez votre distribution de tags mensuellement et réintroduisez les corrections pour que le modèle continue à apprendre. Les outils qui apprennent de vos modifications s'améliorent ; ceux qui n'apprennent pas, non.
Faites ça bien et le tagging cesse d'être une corvée que votre équipe déteste et devient la couche silencieuse qui fait vraiment fonctionner le triage de tickets et l'automatisation de tickets.
Essayez eesel pour le tagging de tickets
Si vous voulez un tagging IA qui s'entraîne sur vos propres tickets résolus et que vous pouvez tester avant qu'il touche un ticket en direct, c'est exactement ce pour quoi eesel est conçu. Il se branche sur le helpdesk que vous utilisez déjà (Zendesk, Freshdesk, Gorgias et plus de 100 intégrations), apprend de vos tickets passés et de votre documentation d'aide dès le premier jour, et tague, remplit des champs et route à partir de là, pendant que vous gardez le contrôle total sur ce qu'il applique automatiquement versus ce qu'il suggère.
Le différenciateur est le mode simulation : vous le faites tourner sur vos tickets historiques et voyez exactement comment il les aurait tagués avant que quoi que ce soit ne passe en production, donc vous ne devinez jamais sur la précision. La tarification est par ticket, pas par agent, ce qui a tendance à compter une fois que vous le comparez à un module complémentaire par siège.

Une équipe utilisant l'IA comme premier répondant sur un helpdesk Jira Service Management interne a exprimé l'attrait clairement :
« On l'utilise pour être le premier répondant à nos tickets Helpdesk dans Jira. Il agit essentiellement comme un agent le ferait. »
Jason Loyola, Head of IT, InDebted (étude de cas)
Vous pouvez connecter votre Zendesk (ou quel que soit le helpdesk que vous utilisez) et lancer une simulation en quelques minutes. Gratuit à essayer, sans carte de crédit.
Questions fréquemment posées
L'IA peut-elle tagger automatiquement les tickets dans Zendesk ?
Oui. Le triage intelligent de Zendesk tague par sujet, sentiment et langue avec le module complémentaire Copilot, et vous pouvez également superposer un outil dédié qui s'entraîne sur vos tickets passés. Consultez nos notes sur les capacités IA de Zendesk et comment automatiser les tickets Zendesk plus largement.
Combien coûte le tagging de tickets par IA ?
Les modules complémentaires natifs sont généralement facturés par agent : le module complémentaire Copilot de Zendesk coûte 50 $/agent/mois, et Freddy Copilot de Freshdesk fait monter le plancher réaliste à environ 84 $/agent/mois. Une alternative de tarification Freddy basée sur l'usage comme eesel facture par ticket, avec une tarification transparente et sans frais par siège.
L'IA va-t-elle tagger incorrectement les tickets ?
Parfois, surtout au début ou lorsque votre liste de tags se chevauche. La solution est de réduire la taxonomie, d'exécuter d'abord le modèle sur des tickets historiques et de conserver les tickets à faible confiance en mode suggestion. Notre guide sur la réduction des faux positifs va plus loin.
Ai-je besoin de milliers de tickets passés pour commencer à tagger avec l'IA ?
Certains outils natifs oui : le triage automatique de Freshdesk a besoin d'environ 2 000 tickets historiques avant de prédire les champs de manière fiable. Les outils qui s'entraînent sur vos tickets résolus et votre documentation d'aide peuvent démarrer plus tôt, ce qui compte si vous gérez une file d'attente plus petite. Comparez les approches dans notre guide de classification de tickets par IA.

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.









Comment automatiser le tagging des tickets avec l'IA ?
Vous connectez une IA à votre helpdesk, lui fournissez une liste de tags propre et la laissez lire chaque ticket entrant pour détecter l'intention, la langue et le sentiment, puis appliquer le tag correspondant. La voie la plus sûre est de commencer en mode suggestion, de vérifier les tags par rapport à votre historique avec un outil de triage de tickets et de n'activer l'application automatique que lorsque la précision se stabilise. Ce guide pas à pas couvre la version spécifique à Zendesk.