Comment résorber le backlog de tickets de support avec l'IA
Riellvriany Indriawan
Katelin Teen
Dernière modification June 22, 2026

En bref
Un backlog de support ne vient presque jamais de tickets difficiles. Il vient des mêmes questions faciles s'accumulant plus vite qu'une petite équipe ne peut taper les mêmes réponses. La façon la plus rapide de le résorber est donc de pointer l'IA sur les éléments répétitifs en premier, pas sur toute la file d'un coup.
Voici la version courte de comment je le ferais : connecter le helpdesk, laisser un agent IA apprendre de vos tickets passés et de vos docs d'aide, le simuler sur votre vrai historique de tickets pour voir ce qu'il aurait dit, puis le lâcher sur la poignée de catégories à haute confiance (statut de commande, remboursements, réinitialisations de mot de passe) tandis que chaque décision de jugement va encore à une personne. Fait correctement, cela vide la majeure partie d'un backlog parce que la majeure partie d'un backlog est constituée des mêmes cinq questions.
La seule règle qui compte plus que toute autre : l'IA ne doit traiter que les tickets dont elle est confiante et laisser le reste tranquille. Faites ça correctement et l'IA vide la file sans que vous ayez à revérifier son travail.
Pourquoi votre backlog est presque certainement résorbable
Je travaille dans la file de support, donc je vais dire l'évidence à voix haute : un backlog ressemble à une montagne de problèmes uniques, mais ce n'est presque jamais le cas. C'est un petit nombre de types de questions, répétées des centaines de fois, qui se sont accumulées parce qu'il y avait plus de clients que de personnes pour y répondre.
C'est exactement la situation qui crée les backlogs en premier lieu. Un directeur du support dans une entreprise EdTech à croissance rapide l'a exprimé clairement en décrivant pourquoi ils se sont appuyés sur l'automatisation :
« En tant que startup à croissance rapide avec une petite équipe, nos clients sont bien plus nombreux que nos employés. Il est crucial que nous ayons des solutions de libre-service robustes ainsi que des outils pour décupler l'efficacité de nos équipes en contact avec les clients. »
Jon Miron, Directeur du Support, étude de cas Yellowdig
Quand les clients surpassent les agents, la file gagne. Et les tickets qui la font gagner sont rarement les épineux ; ce sont les « où est ma commande » et « comment réinitialiser mon mot de passe » qu'un agent de support IA peut répondre à partir d'une macro que vous avez déjà rédigée.
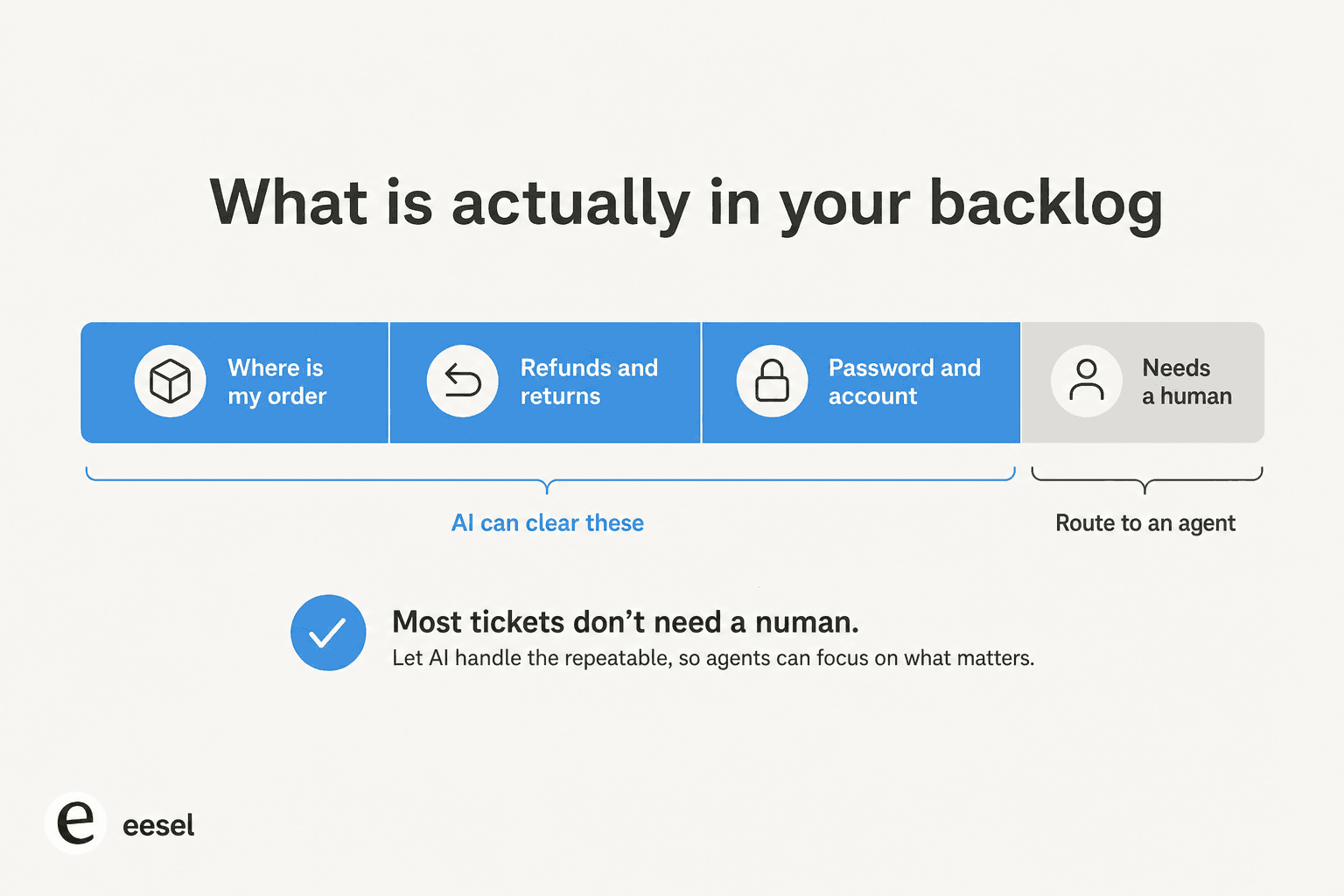
C'est pourquoi je suis confiant que votre backlog est résorbable avant même de l'avoir vu. Quand on examine l'historique d'un nouveau client, la part répétitive est généralement énorme. Lors d'un test sur le vrai trafic Zendesk d'un joaillier allemand, eesel a atteint 93 % de précision dans le tri et 100 % de détection du spam sur environ 1 000 tickets mensuels, avec une utilité de brouillon de catégorie supérieure à 93 % pour les retours, remboursements et questions produits. C'est la partie de la file que l'IA mange au petit-déjeuner.
Avant de commencer : ce dont vous avez besoin
Vous n'avez pas besoin d'une équipe data ni d'un projet de six semaines. Vous avez besoin de trois choses :
- Un helpdesk auquel l'IA peut se connecter. Zendesk, Freshdesk, Gorgias, Help Scout, ou ce que vous utilisez. Si vous êtes encore en train de choisir, voici un tour d'horizon des logiciels helpdesk IA pour 2026.
- Vos réponses existantes. Tickets passés, macros ou réponses enregistrées, et articles du centre d'aide. C'est le matériel d'entraînement de l'IA, et c'est ce que j'entends le plus souvent demander par les clients : les gens veulent que l'agent soit entraîné sur leur propre historique de tickets, pas sur un modèle générique.
- Une courte liste de types de questions « sûrs ». Les cinq ou environ catégories auxquelles vous répondez de la même façon à chaque fois. C'est votre premier objectif d'automatisation, et rien d'autre.
C'est tout. Le backlog que vous regardez est en réalité votre atout le plus précieux ici, parce que c'est la matière première dont l'IA apprend.
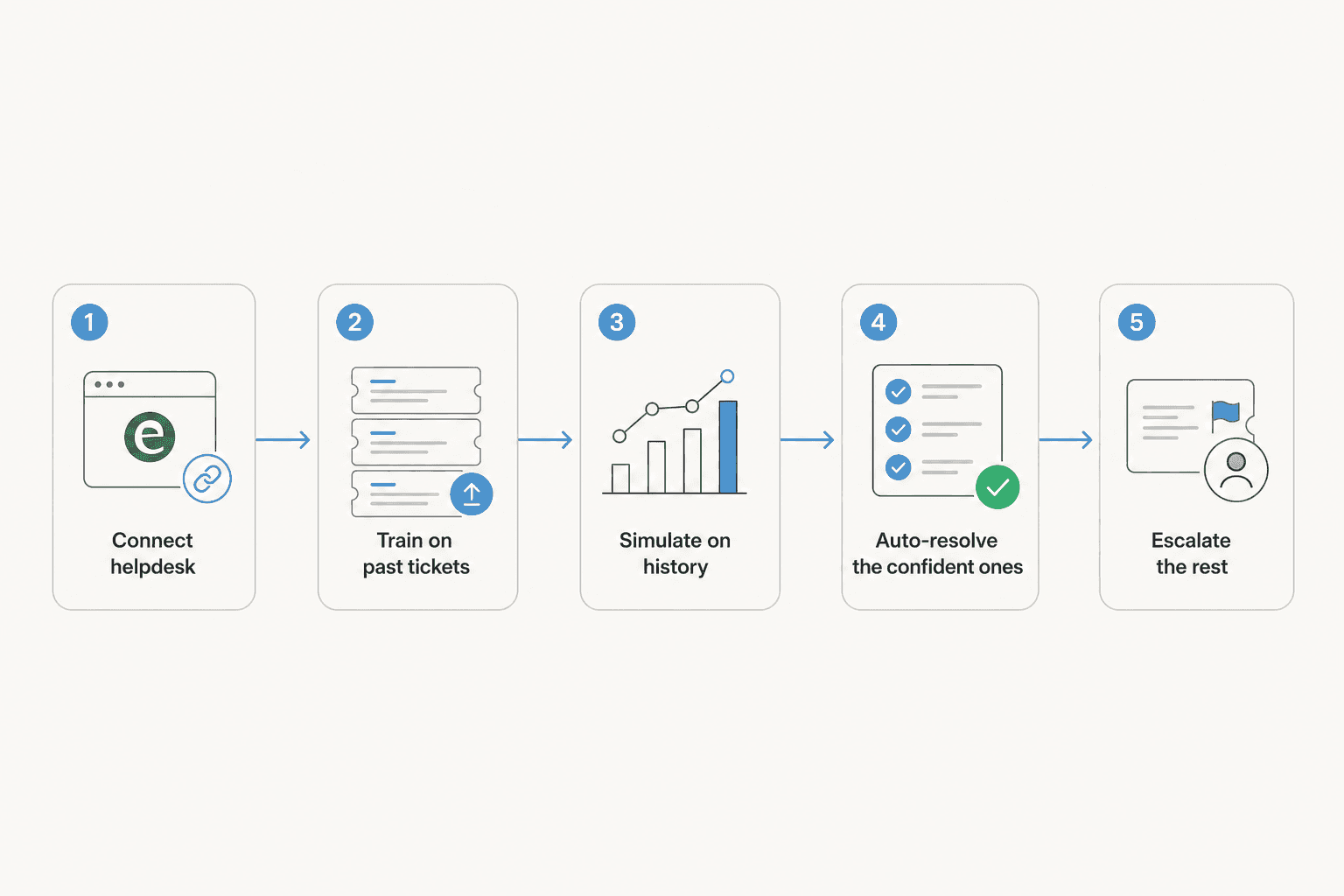
Étape 1 : Connectez votre helpdesk et laissez l'IA apprendre votre historique
Le premier geste est de connecter l'IA à l'endroit où vos tickets vivent déjà et de la laisser lire vos résolutions passées, macros et docs d'aide. Un bon agent helpdesk IA les traite comme ses sources : il apprend comment votre équipe répond, avec votre voix, avec vos politiques.

La partie que les équipes sous-estiment : c'est rapide maintenant. Les outils en libre-service se connectent en quelques minutes, ce qui est très loin du onboarding de plusieurs semaines que les anciens fournisseurs citent encore. Une entreprise d'analyse de l'économie gig sur Zendesk a obtenu de vrais résultats lors d'un essai de 7 jours (plus sur leurs chiffres ci-dessous). Si un fournisseur vous dit que vider votre backlog commence par une implémentation d'un trimestre, c'est le problème du fournisseur, pas le vôtre.
Étape 2 : Simulez avant de laisser l'IA toucher un vrai client
C'est l'étape qui sépare un déploiement propre d'un déploiement effrayant, et celle que je ne sauterais jamais.
Nous l'avons appris à la dure au fil des années à déployer l'IA sur des files en direct : un bot qui sonne confiant donnera silencieusement de mauvaises réponses si vous le laissez faire, et sur un backlog de 7 000 tickets personne ne va relire chaque réponse pour le détecter. Une responsable CX dans une marque DTC à fort volume d'environ 7 000 tickets par mois a formulé la peur exactement comme il faut lors d'un appel avec nous. L'IA ne répondra jamais à toutes les questions, a-t-elle dit, mais « je ne peux pas aller vérifier tous mes 7 000 tickets pour voir si l'IA a vraiment bien répondu ». Sa demande était simple : « J'ai besoin d'une IA qui ne gère que les tickets dont elle est confiante, et tous les autres, qu'elle les laisse tranquilles. »
C'est pourquoi je simule chaque déploiement sur des tickets historiques en premier. Vous faites tourner l'IA sur une tranche de votre vrai backlog dans un mode sûr où elle n'envoie rien, et vous lisez ce qu'elle aurait répondu. Vous voyez le taux de résolution, repérez les catégories où elle est hésitante, et l'affinez avant qu'un seul client soit impliqué. Ça transforme « j'espère que ça marche » en « j'ai vu exactement ce que ça fait ».
Étape 3 : Résolvez automatiquement les tickets répétitifs, acheminez le reste
Maintenant vous videz la file. Dirigez l'IA sur vos catégories sûres et laissez-la les résoudre de bout en bout, tandis que tout ce qui dépasse son seuil de confiance est trié et acheminé vers le bon humain.
C'est aussi là où les automatisations au-delà des réponses font leur travail : étiquetage, affectation et mises à jour de statut. Une entreprise d'analyse de conducteurs sur Zendesk qui a résolu 73 % de ses demandes de niveau 1 au premier mois a souligné que la plateforme gérait aussi « l'étiquetage des tickets, l'affectation et les mises à jour de statut » automatiquement, pas seulement la rédaction de réponses. Ce travail de ménage est la moitié de ce qui rend un backlog ingérable, donc automatiser l'étiquetage des tickets et l'acheminement le vide en même temps que les réponses.
L'effet de levier ici est réel. Une équipe au Royaume-Uni a obtenu 56 tickets résolus avec seulement 9 macros synchronisées, et utilisait encore l'agent plus d'un mois après l'expiration de son essai. Vous n'avez pas besoin d'une immense base de connaissances pour commencer ; vous avez besoin de la poignée de réponses qui reviennent le plus souvent.
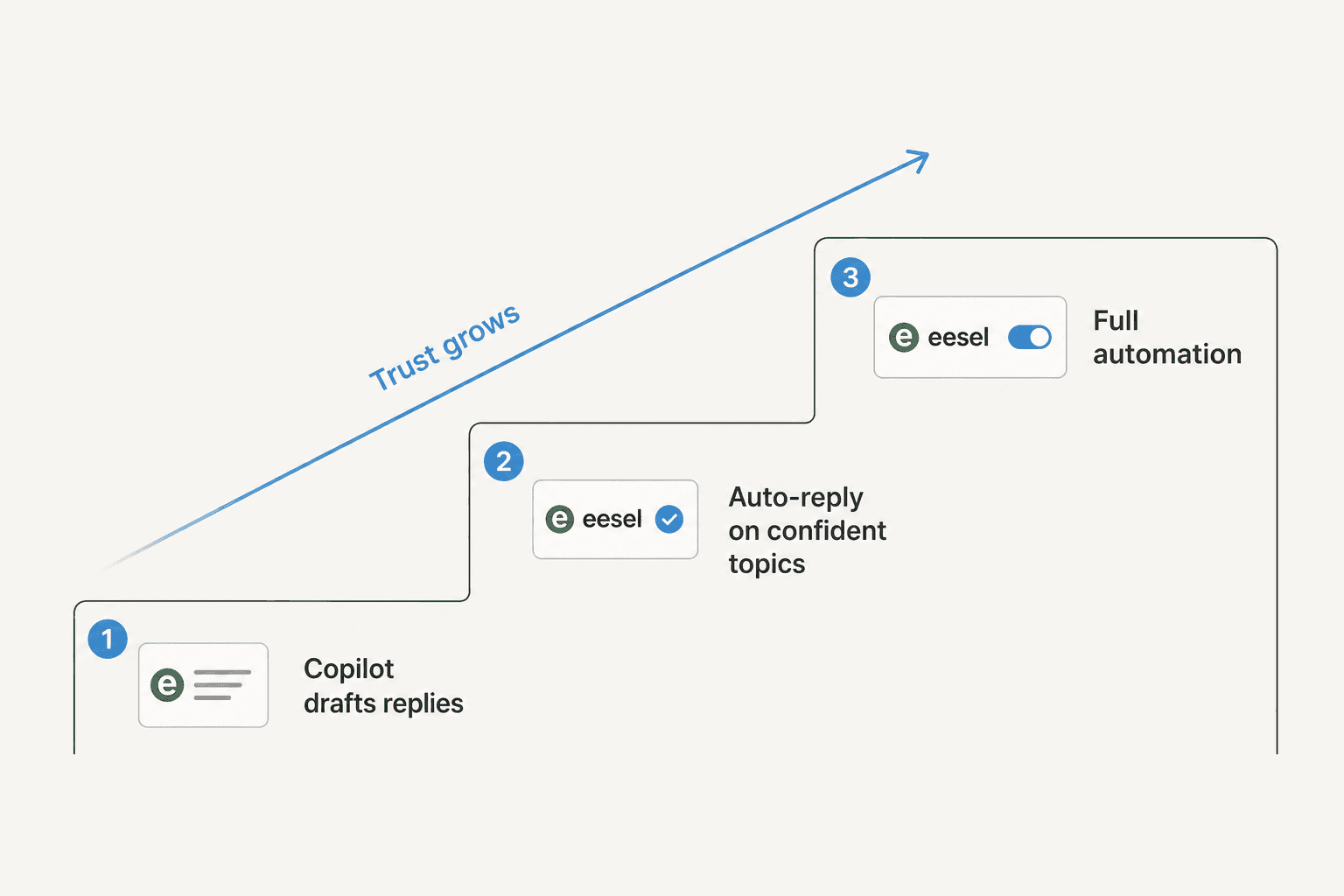
Étape 4 : Déploiement par phases, pas tout d'un coup
L'erreur que je vois les équipes faire est de passer l'IA en automatisation totale le premier jour puis de paniquer. Le schéma qui fonctionne vraiment, et celui que la plupart des clients demandent, est une échelle :
- D'abord le copilote. L'IA rédige les réponses, vos agents relisent et envoient. Vous construisez la confiance et la file commence à bouger parce que taper la réponse est la partie lente.
- Réponse automatique sur vos catégories les plus sûres. Une fois que la simulation et le mode copilote montrent que l'IA est solide sur, disons, le statut de commande, laissez-la gérer cette catégorie de façon autonome.
- Élargissez le périmètre. Ajoutez des catégories au fur et à mesure que les données le justifient. L'automatisation totale est une destination à laquelle on arrive, pas un interrupteur qu'on actionne à l'aveugle.
L'objectif de l'échelle n'est pas la prudence pour elle-même. C'est que chaque échelon vous donne des preuves pour le suivant, de sorte que lorsque l'IA résout automatiquement une grande partie du backlog, vous savez déjà que c'est sûr parce que vous l'avez vu y parvenir.
Étape 5 : Empêchez le backlog de revenir
Vider un backlog une fois est satisfaisant. Le garder vide est la vraie victoire.
Laissez l'IA active comme premier répondant pour que les nouveaux tickets soient triés et les répétitifs résolus au moment où ils arrivent, au lieu de s'accumuler la nuit dans le backlog du lendemain. Puis fermez la boucle : chaque question fréquente que l'IA traite est candidate à un meilleur article d'aide ou une réponse en libre-service qui empêche le ticket d'être soumis. Surveillez vos rapports pour voir quelles catégories fuient encore, et réalimentez-les.

C'est aussi là où l'économie devient agréable. Un compte e-commerce gérant environ 700 tickets par semaine a fait tourner l'IA à environ 1 $ par ticket, ce qui est le genre de chiffre qui recadre un backlog de « il faut recruter » en « on a déjà la capacité ». Si vous voulez le calcul plus approfondi, voici une analyse honnête de combien l'IA économise dans le support.
Erreurs courantes à éviter
- Tout automatiser d'un coup. Le contrôle par confiance est tout le jeu. Laissez l'IA gérer ce qu'elle connaît et laissez le reste aux humains.
- Sauter la simulation. Si vous ne pouvez pas voir ce que l'IA aurait répondu avant qu'elle réponde, vous pariez. Testez-la sur votre historique d'abord.
- Le traiter comme un nettoyage unique. Un backlog vidé à la main repart. Un backlog vidé par un premier répondant toujours actif reste vide.
- Oublier le ménage. Les réponses sont visibles ; l'étiquetage, l'acheminement et les mises à jour de statut sont le travail invisible qui bouche une file. Automatisez aussi le tri et l'acheminement.
- Acheter sur la démo, pas sur les données. Une belle démo ne prouve rien sur vos tickets. Faites prouver à n'importe quel outil ce qu'il vaut sur votre backlog avant de vous engager.
Essayez eesel pour résorber votre backlog
Si vous voulez le chemin le plus rapide à travers tout ce qui précède, c'est la partie de la file pour laquelle eesel a été construit. Il se connecte à Zendesk, Freshdesk, Gorgias, Help Scout et plus encore, apprend de vos tickets et macros passés, puis fait la seule chose qui rend un backlog sûr à automatiser : il vous permet de simuler l'agent sur votre vrai historique de tickets avant qu'il touche un client, afin que vous puissiez voir le taux de résolution et l'affiner d'abord.

C'est une configuration sans code que vous pouvez avoir opérationnelle en quelques minutes, contrôlée par la confiance pour qu'elle ne résolve automatiquement que ce dont elle est sûre, et gratuite à l'essai. Pointez-la sur le backlog que vous regardez en ce moment et observez quels tickets elle viderait.
Questions fréquentes
Quels tickets l'IA doit-elle traiter en premier lors de la résorption d'un backlog ?
Est-il sûr de laisser l'IA répondre automatiquement à un backlog de tickets clients ?
Combien de temps faut-il pour configurer l'IA afin de réduire un backlog de tickets ?
Comment empêcher le backlog de support de revenir ?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.







Comment résorber rapidement le backlog de tickets de support avec l'IA ?