Comment réduire mon backlog de tickets de support avec l'IA ?
Kurnia Kharisma Agung Samiadjie
Katelin Teen
Dernière modification June 23, 2026

En bref
Réponse courte : oui, l'IA peut réduire un backlog de tickets de support, et généralement plus vite qu'un recrutement. Mais le levier, ce n'est pas de pointer l'IA sur toute la file. C'est de pointer l'IA sur les 60 à 80 % de tickets répétitifs qui se résument à la même poignée de questions, et de laisser les cas complexes aux humains.
Voici la décision en trois parties. Quoi automatiser : les tickets auxquels vous répondez de la même façon chaque jour (statut de commande, remboursements, réinitialisations de mot de passe). Comment le faire en sécurité : laissez l'IA apprendre de vos anciens tickets, simulez-la sur votre historique réel avant qu'elle touche un client, puis laissez-la résoudre automatiquement uniquement ce dont elle est sûre et router silencieusement le reste. Ce que ça coûte : avec une tarification à l'usage d'environ 0,40 $ par ticket, le calcul bat presque toujours le coût d'un nouveau recrutement.
Si vous voulez la version étape par étape, j'ai rédigé un guide séparé pour vider un backlog. Cet article traite de la décision derrière : l'IA peut-elle vraiment faire ça pour votre file, et comment le savoir avant de miser dessus.
D'abord, qu'y a-t-il vraiment dans votre backlog ?
Avant de se demander « l'IA peut-elle régler ça », la question la plus utile est « de quoi s'agit-il vraiment ». Car un backlog ne signifie presque jamais que votre équipe est lente. Cela signifie que les mêmes questions faciles arrivent plus vite qu'une petite équipe ne peut taper les mêmes réponses.
J'ai passé quelques années à observer d'où vient le trafic de recherche pour « réduire le volume de tickets » et « backlog de tickets », et la réalité derrière le mot-clé est toujours la même : un responsable support submergé, des clients bien plus nombreux que les agents. Un client d'eesel, une petite équipe e-commerce sur Zendesk, l'a dit clairement en expliquant que l'IA « soulage notre petite équipe de support des questions auxquelles une simple IA peut facilement répondre ». C'est le backlog en une phrase. Ce n'est pas difficile. C'est répétitif.
Quand on décompose vraiment une file, l'essentiel se résume à une courte liste d'intentions récurrentes. Un opérateur e-commerce multi-marques que j'ai rencontré traitait plus de 500 tickets par jour, et le volume était dominé par trois choses : les demandes de remboursement, les désabonnements et le suivi de commandes. Cette forme — une large base répétitive et une fine couche de vrais cas de jugement par-dessus — est ce qui rend un backlog si facile à résorber.
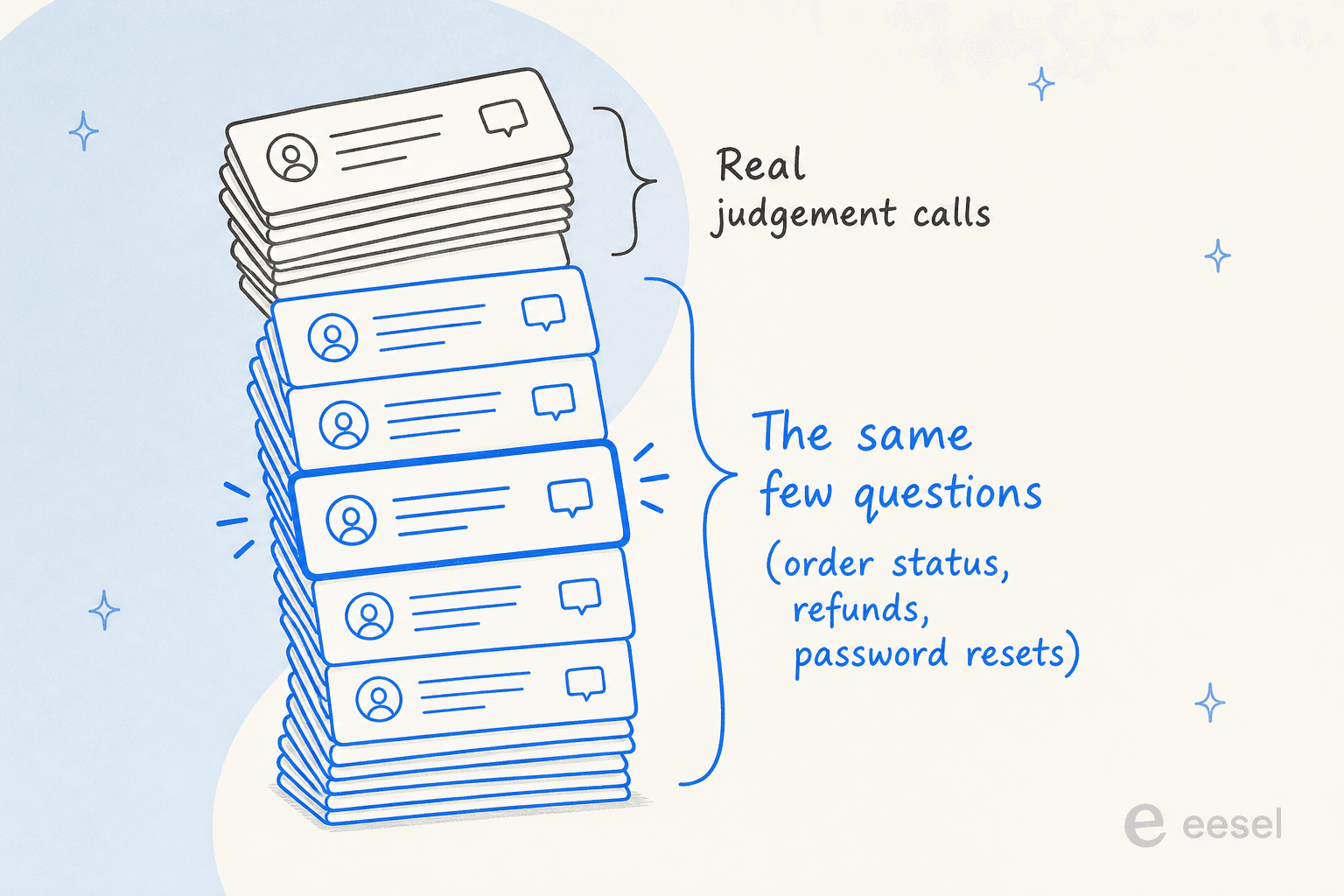
La vraie question devient alors plus précise et bien plus facile à répondre : l'IA peut-elle gérer la base répétitive de manière assez fiable pour que vos agents ne voient que les tickets qui nécessitent réellement une personne ? La réponse est oui, avec des conditions à bien comprendre.
L'IA peut-elle vraiment faire ça ? La réponse honnête
Oui pour la base répétitive. Avec précaution pour le reste.
Je préfère être direct plutôt que de faire de la vente. Chez eesel, j'ai passé des années à déployer l'IA sur des files de support en direct, sur des milliers de tickets réels, et j'ai vu un bot au ton assuré donner silencieusement une mauvaise réponse — c'est exactement pourquoi je simule désormais chaque déploiement sur des tickets historiques avant la mise en production. La promesse n'est donc pas « l'IA résout tout ». C'est que l'IA résout la partie de votre backlog qui est réellement répétitive, et les chiffres sont là pour le prouver.
Une entreprise d'analyse de l'économie à la demande sur Zendesk a résolu 73 % des demandes de niveau 1 dès le premier mois avec eesel, avec des résultats visibles en seulement 7 jours d'essai. Dans un essai contrôlé sur une boîte mail e-commerce allemande, l'IA a atteint 93 % de précision de triage et a intercepté 100 % des spams (soit environ un cinquième de cette boîte) sans aucun faux positif. Ce sont les catégories ennuyeuses et répétitives, et c'est exactement le backlog.
Le contrepoids honnête : dans ce même essai, les agents n'ont envoyé qu'environ 12 % des brouillons de l'IA tels quels, le plus souvent en réduisant une réponse de huit phrases à trois phrases. Ce n'est pas que l'IA se trompe (le taux d'erreurs factuelles était d'environ 7 %) ; c'est une question de ton et de longueur, le genre de chose qui s'améliore rapidement dès que l'IA s'entraîne sur les réponses passées de votre équipe. L'exemple illustre la réalité : l'IA est excellente pour la résolution répétitive et le triage, et elle ressemble de plus en plus à votre équipe au fil du temps.
La répartition ressemble donc à ceci.
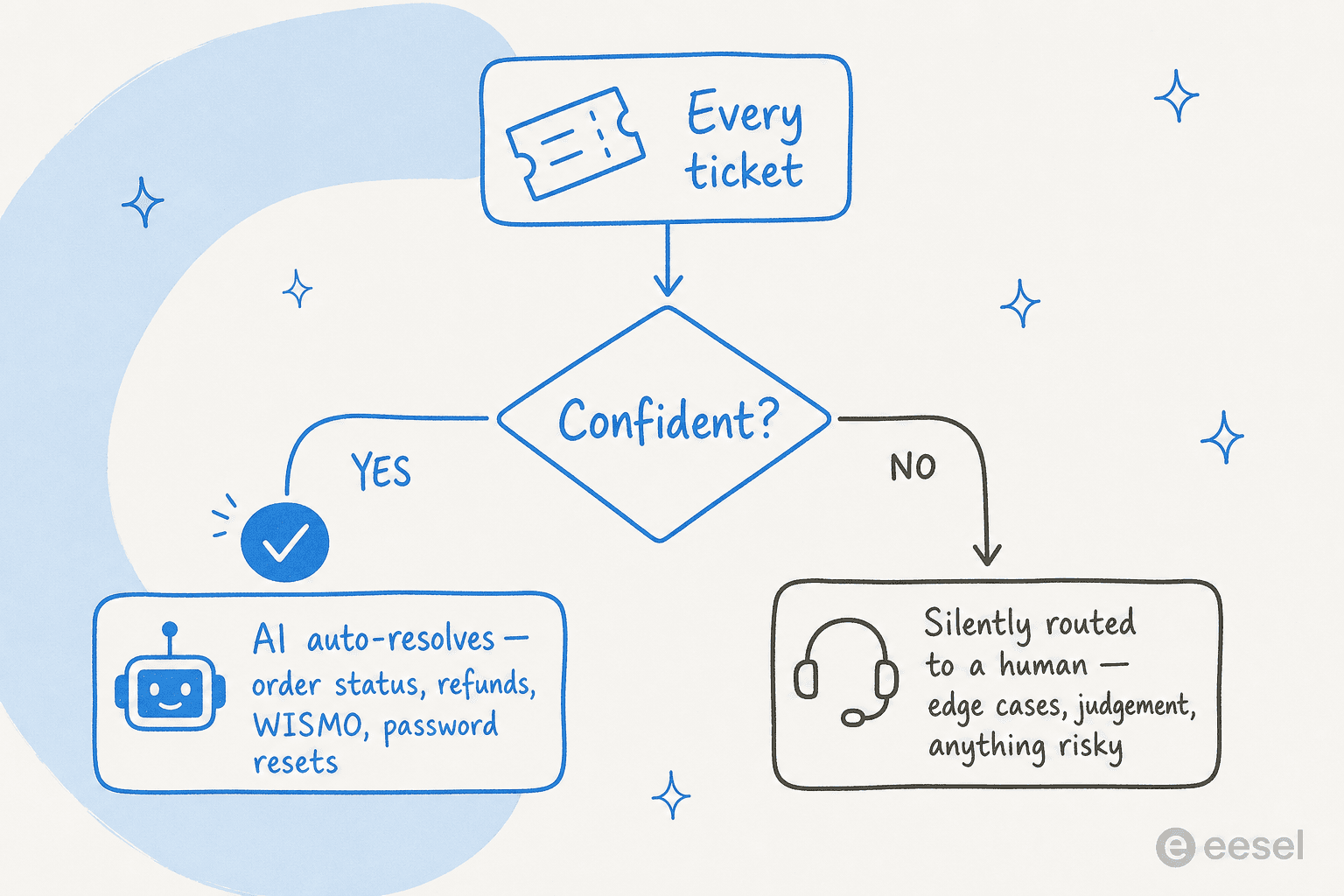
Ce que l'IA résout de façon fiable dans un backlog :
- Les tickets « où est ma commande », les remboursements et retours en cours, les réinitialisations de mot de passe et accès aux comptes, et tout ce qui est déjà couvert dans une macro ou un article d'aide.
- Le triage et le marquage de toute la file, afin que même les tickets traités par un humain arrivent triés et résumés.
- Les spams, qui représentent parfois une part surprenante de la pile dans certaines boîtes mail.
Ce qui doit rester entre les mains d'un humain :
- Les clients mécontents, les cas limites, tout ce qui a un enjeu financier ou légal, et tout ce dont l'IA n'est pas sûre.
Cette dernière ligne est l'ensemble du modèle de sécurité, et elle vient directement des acheteurs. Comme me l'a dit un responsable CX gérant 7 000 tickets par mois : « J'ai besoin d'une IA qui ne traite que les tickets dont elle est sûre, et pour tous les autres, qu'elle les laisse tranquilles. » C'est le routage basé sur la confiance, et c'est la différence entre une IA qui vide un backlog et une IA qui en crée un pire.
Quelle part de mon backlog l'IA peut-elle réellement prendre en charge ?
Les pourcentages abstraits ne vous aident pas à décider. Vos chiffres, si. Choisissez le cas le plus proche de votre volume mensuel et de la répétitivité de votre file, et vous obtiendrez une estimation approximative de ce que l'IA pourrait prendre en charge, de ce qui reste humain, et de ce que le côté IA coûte à peu près avec une tarification à l'usage.
Backlog drain estimator
A rough read, not a quote. AI cost assumes ~$0.40 per resolved ticket.
The number that matters isn't the cost line, it's the hours your team gets back when the repetitive pile stops landing on them. Compare it to the cost of another agent or how to measure ROI.
La plupart des équipes sont surprises de voir combien de tickets tombent dans la colonne « l'IA pourrait s'en charger » une fois qu'elles sont honnêtes sur la vraie répétitivité de leur file.
Comment savoir si ça marchera avant de toucher un client ?
C'est la question qui bloque vraiment les gens, et c'est normal. Laisser l'IA se déchaîner sur une file en direct sans preuve, c'est risquer de transformer un backlog en tournée d'excuses.
La réponse, c'est la simulation. Avant qu'un agent eesel réponde à qui que ce soit, vous le faites tourner sur vos propres tickets historiques — des centaines ou des milliers — et vous lisez exactement ce qu'il aurait répondu. Vous voyez la couverture par sujet, vous voyez où il est sûr de lui et où il s'abstient, et vous trouvez les lacunes avant qu'un client les découvre. Ce n'est pas une démo sur les données de quelqu'un d'autre ; c'est votre vrai backlog, en simulation à blanc.

Deux autres garde-fous comptent autant que la simulation :
- Routage basé sur la confiance. L'IA ne répond qu'à ce dont elle est sûre et laisse silencieusement le reste de côté. Aucun message « désolé, je ne sais pas » envoyé aux clients, qui est le mode d'échec que les acheteurs craignent le plus.
- Réponses ancrées dans vos connaissances, avec sources. Un bon agent répond à partir de votre centre d'aide et de vos anciens tickets, pas depuis Internet, et cite ses sources. Si vous voulez la version approfondie, j'ai écrit sur la prévention des hallucinations de l'IA et la formation sur la base de connaissances.
Commencez en mode supervisé pendant une semaine (l'IA rédige, les humains envoient), observez où elle a raison, puis donnez-lui de l'autonomie sur les catégories qu'elle maîtrise. Ce chemin copilote-puis-pilote automatique est le schéma que presque toutes les équipes que j'ai intégrées veulent vraiment, et c'est ainsi que vous construisez la confiance sans tout miser sur la file dès le premier jour.
Et le coût, vraiment ?
L'estimateur ci-dessus vous donne un chiffre mensuel approximatif, mais le modèle que vous choisissez importe plus que l'étiquette de prix.
Le piège, c'est la tarification par résolution. Cela semble juste jusqu'à ce que votre volume monte en flèche : un outil qui facture par ticket résolu vous facture davantage lors de votre saison chargée, exactement quand vous pouvez le moins vous le permettre. Dans une analyse de coût que j'ai réalisée pour un revendeur à environ 1 000 tickets par mois, la tarification par résolution revenait à environ 792 $ par mois à volume normal, puis gonflait vers 3 168 $ lors d'une pointe Black Friday à 4 000 tickets. Une utilisation facturée à un tarif fixe et prévisible par ticket ne vous pénalise pas pour un bon mois ou un mois chargé.
Face au coût de ne pas résorber le backlog, presque n'importe quelle tarification raisonnable gagne. Un backlog, ce sont des temps de réponse lents, des clients perdus et des agents épuisés, et l'alternative — un nouveau recrutement — coûte bien plus que 0,40 $ par ticket. Si vous voulez mettre des chiffres réels dessus, j'ai un article sur combien l'IA permet d'économiser dans le support et une analyse complète de la comparaison coût IA vs humain. En résumé : les économies viennent des heures que votre équipe cesse de passer sur les cinq mêmes questions.
Réduire le backlog une fois ou le réduire durablement
Voilà ce que la plupart des conseils « videz votre backlog » oublient : le vider une fois, c'est la partie facile. Si vous déblayez la file puis que vous éteignez l'IA, le backlog se reconstruit, parce que les tickets répétitifs n'ont jamais cessé d'arriver.

Le réduire durablement, c'est laisser l'IA comme premier intervenant. Chaque nouveau ticket est trié et résumé à son arrivée, les répétitifs sont résolus sur place, et vos agents commencent leur journée avec une file déjà triée plutôt qu'un mur. Réintégrez les questions récurrentes dans votre base de connaissances et votre libre-service les intercepte encore plus tôt, de sorte que la pile se réduit à la source. C'est la différence entre un nettoyage ponctuel et une file qui reste durablement vide, et c'est là que le temps de première réponse baisse aussi discrètement.
Ça fonctionne dans le helpdesk que vous utilisez déjà, donc il n'y a pas de migration à gérer en plus du backlog que vous combattez déjà.
Essayez eesel pour votre backlog
Si votre backlog est constitué de la même poignée de questions qui s'accumulent, c'est exactement ce qu'eesel a été conçu pour résorber. Il se connecte au helpdesk que vous utilisez déjà — que ce soit Zendesk, Freshdesk, Gorgias ou Front — apprend de vos anciens tickets et de votre documentation en quelques minutes, et vous permet de simuler l'ensemble sur votre historique réel avant qu'il réponde à un seul client. La seule chose que je signale honnêtement : le gain vient de la base répétitive, donc c'est mieux adapté aux files à volume élevé et récurrentes qu'à un backlog de tickets véritablement uniques.
Vous pouvez essayer eesel gratuitement, lancer une simulation sur votre propre backlog, et voir votre vrai taux de couverture avant de vous engager.










Comment réduire mon backlog de tickets de support avec l'IA ?