
En résumé
La plupart des programmes de QA support reposent sur un mensonge par omission : vous examinez 1 à 3 % des conversations manuellement, puis parlez de « qualité » comme si cet échantillon représentait les 97 % restants. Ce n'est pas le cas. Faire du QA support avec l'IA, c'est noter automatiquement chaque conversation selon votre grille, afin que la couverture ne soit plus le goulot d'étranglement.
En pratique, le processus se déroule en cinq étapes : définir à quoi ressemble une bonne réponse, connecter l'ensemble de votre historique de conversations, laisser l'IA tout noter, faire remonter les moments de coaching et les patterns récurrents que l'échantillonnage manuel aurait manqués, puis boucler la boucle en coachant les agents et en corrigeant la documentation derrière les erreurs.
L'étape que tout le monde saute : auditer aussi l'agent IA. J'ai vu un bot au ton assuré donner une mauvaise réponse, alors avant de confier l'automatisation à des tickets en production, notez-la d'abord sur vos tickets passés. L'agent helpdesk IA d'eesel effectue cette simulation sur votre propre historique, ce qui est ce qui se rapproche le plus d'un passage QA avant la mise en production.
Ce qu'est vraiment le QA support, et pourquoi la version manuelle est cassée
Le QA support, c'est l'assurance qualité appliquée aux conversations clients. Vous prenez une grille (la réponse était-elle correcte ? le ton était-il adapté ? le problème a-t-il été résolu ?) et vous évaluez les conversations selon cette grille, puis vous utilisez ce que vous trouvez pour coacher les agents et combler les lacunes. Bien fait, c'est ainsi qu'une équipe support s'améliore plutôt que de simplement aller plus vite, et cela s'articule avec tout, de la gestion des SLA aux économies sur les coûts support.
Voici le problème que j'ai vécu sur la file d'attente : la version manuelle ne regarde toujours qu'une infime fraction. Un analyste QA tire une poignée de tickets par agent par semaine, les note dans un tableur, et passe à autre chose. Si votre équipe traite quelques milliers de conversations par mois, vous en examinez peut-être 2 %. Les 98 % que vous n'avez pas ouverts pourraient être pleins de réponses polies, assurées et totalement fausses, et votre programme QA ne le saurait jamais.
Cette fraction n'est pas seulement petite, elle est biaisée. Les analystes sont attirés par les tickets faciles à noter, récents ou déjà signalés. Le vrai cas limite hors norme, celui qui a silencieusement perdu un client, ne fait que rarement partie de l'échantillon. Vous finissez donc par coacher les agents sur 2 % aléatoires tandis que les patterns qui font vraiment bouger le CSAT se cachent dans la partie que personne ne lit.
Le QA manuel est aussi lent et incohérent. Deux examinateurs notent la même conversation différemment. Au moment où une note de coaching arrive, l'agent a traité 400 tickets supplémentaires. Rien de tout cela n'est la faute de l'analyste, c'est un problème mathématique : les humains ne peuvent pas tout lire, alors ils lisent un échantillon, et un échantillon ne peut pas vous renseigner sur votre file d'attente.
Ce qui change quand l'IA pilote votre QA
Le changement est simple à énoncer et difficile à surestimer : noter 100 % des conversations coûte à peu près le même effort que d'en noter 2 %. Une fois qu'une IA lit chaque conversation selon votre grille, la couverture n'est plus la ressource que vous rationalisez.
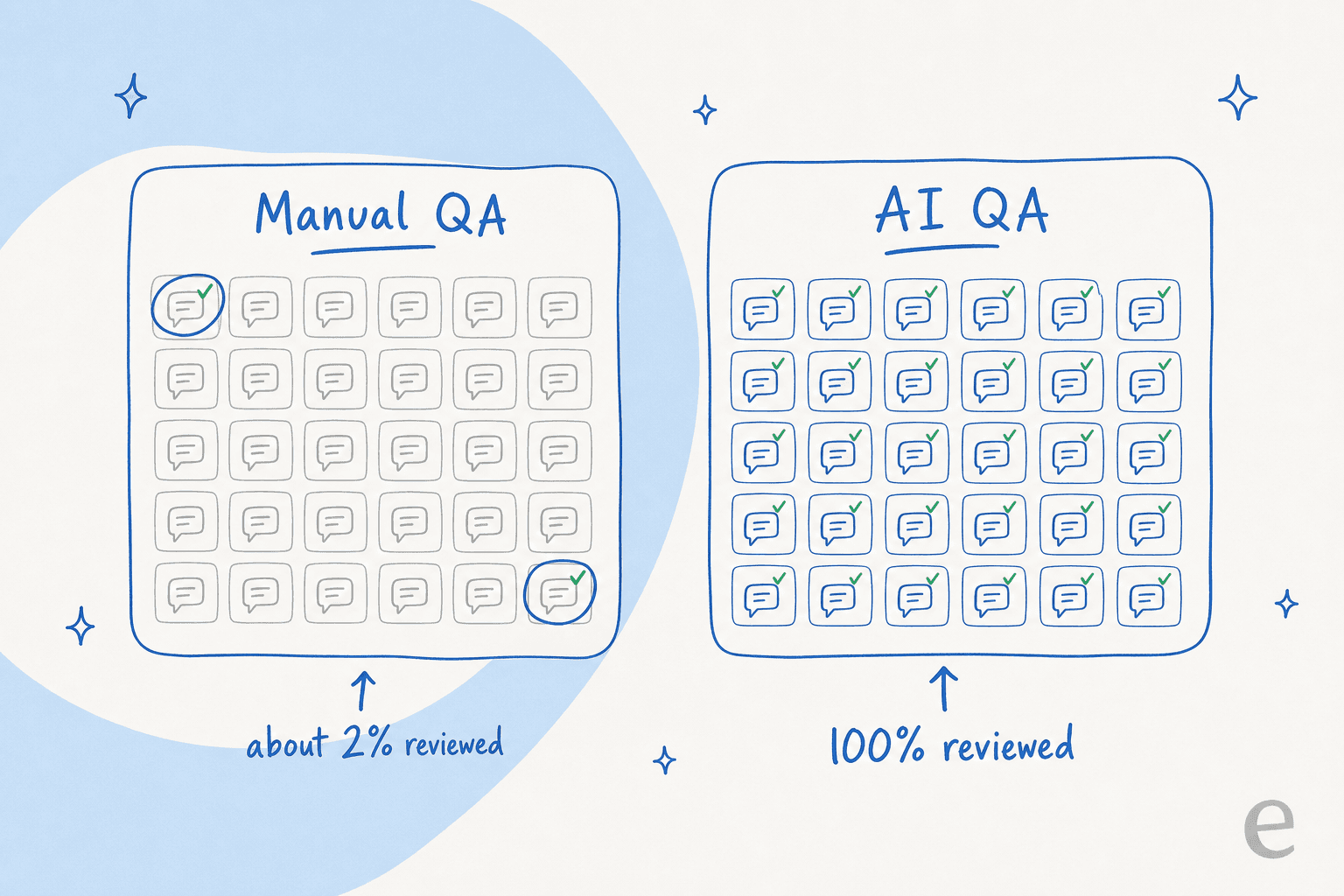
Trois choses changent simultanément. Premièrement, le biais d'échantillonnage disparaît, car il n'y a pas d'échantillon : l'IA note l'ensemble de la file avec une grille cohérente. Deuxièmement, la boucle de rétroaction se resserre : une conversation peut être notée quelques minutes après sa clôture, et non en fin de cycle de révision. Troisièmement, le QA cesse d'être un contrôle ponctuel et devient un indicateur support que vous pouvez réellement suivre dans le temps, par agent, par sujet, par canal.
Ce qui ne change pas : le jugement appartient toujours aux humains. L'IA lit tout et signale ce qui semble anormal ; un humain décide quoi en faire. Cette division du travail est la même que celle qui fait fonctionner le support IA vs humain partout ailleurs : les machines pour le volume, les personnes pour les décisions qui nécessitent un cerveau. C'est aussi pourquoi le QA s'associe si naturellement à un copilote IA dans votre flux de travail support : les mêmes données de conversation alimentent les deux.
Comment faire du QA support avec l'IA, étape par étape
Bien le faire, c'est simplement l'IA et l'automatisation dans le support orientées vers la qualité plutôt que le volume, et vous n'avez pas besoin d'une équipe data pour cela. Tout tient en cinq étapes, et la boucle compte autant que les étapes, car le QA ne vaut la peine d'être fait que si les constats alimentent à nouveau le travail.
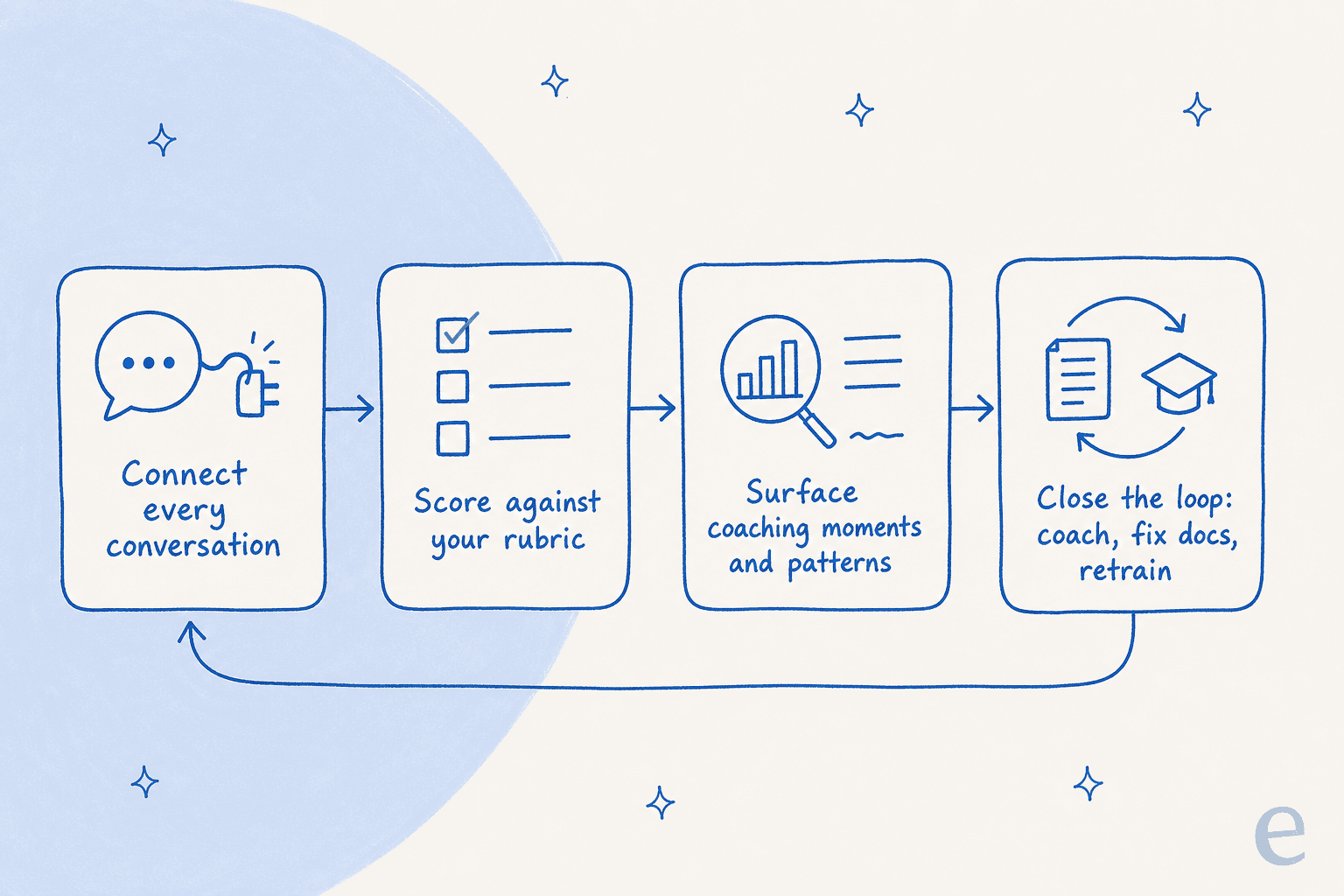
Étape 1 : Définir ce qu'est une « bonne » réponse
Le QA n'est bon que si sa grille l'est, et une grille pour l'IA doit être explicite, sans « vous le saurez quand vous le verrez ». Détaillez les quelques critères sur lesquels chaque réponse est évaluée. En pratique, ce sont environ cinq dimensions : était-elle factuellement correcte, le ton était-il adapté, a-t-elle résolu le problème, a-t-elle suivi la politique, et a-t-elle cité une vraie source plutôt que d'inventer quelque chose.
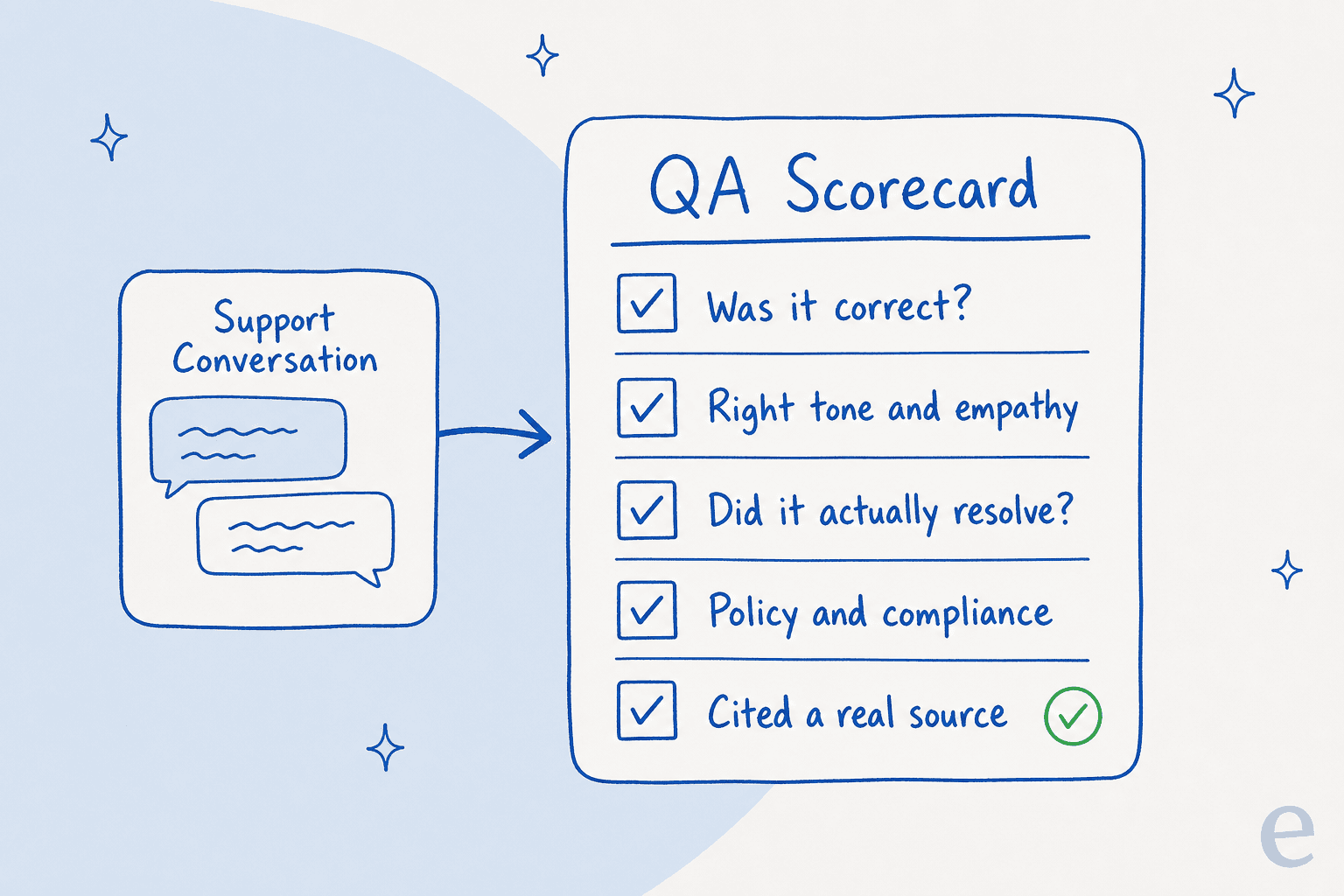
Restez concis. Une grille à 30 critères est une grille que personne n'applique de façon cohérente, qu'il soit humain ou IA. Le critère de sourcing compte plus que les gens ne le pensent : une réponse assurée sans source derrière elle est exactement le genre de chose qui semble correcte dans un tableur et s'avère être une hallucination lorsque vous vérifiez.
Étape 2 : Connecter chaque conversation, pas un échantillon
Pointez l'IA sur l'ensemble de votre historique de conversations, pas sur un export des tickets signalés la semaine dernière. Cela signifie généralement connecter votre helpdesk directement pour que les conversations closes arrivent automatiquement, que vous soyez sur Zendesk, Freshdesk, Gorgias ou Help Scout.

C'est aussi là qu'intervient votre base de connaissances. Une note QA de « incorrect » n'est utile que si vous savez si c'est l'agent qui avait tort ou si c'était la documentation. Alimenter l'IA avec les conversations et le contenu source qu'elle aurait dû utiliser lui permet de distinguer les deux, ce qui fait la différence entre coacher une personne et corriger un article de chatbot de base de connaissances.
Étape 3 : Notation automatique selon la grille
L'IA lit maintenant chaque conversation et la note selon vos dimensions. Ce que vous voulez en sortie n'est pas un seul chiffre, c'est une ventilation : cette conversation a obtenu une note basse sur la résolution, celle-ci a bien répondu mais le ton était décalé, ce lot a tous échoué sur la même politique. Les tendances comptent plus que chaque note individuelle.

Traitez la première semaine de notes comme une calibration, pas comme parole d'évangile. Lisez une partie des notes de l'IA par rapport à votre propre jugement et ajustez la grille là où elle est trop sévère ou trop indulgente. Après quelques passages, les notes se stabilisent, et vous leur ferez confiance comme à un second analyste, avec des vérifications ponctuelles occasionnelles. C'est la même discipline que celle qui sous-tend le suivi du temps de première réponse ou de tout autre indicateur support : l'indicateur n'est utile qu'une fois que vous y croyez.
Étape 4 : Faire remonter les moments de coaching et les patterns
Noter tout est inutile si le résultat est un mur de chiffres. La valeur ajoutée, c'est que l'IA peut extraire les conversations qu'un humain devrait vraiment examiner : les trois tickets de cette semaine où un agent a promis quelque chose hors politique, le sujet où chaque réponse a obtenu une note basse, le nouvel embauché dont le ton dérape sur les remboursements.
C'est la couche de coaching, et c'est là que le QA justifie son existence. Au lieu de « voici cinq tickets aléatoires que j'ai notés », le responsable d'équipe reçoit « voici les moments spécifiques qui méritent une conversation, regroupés par ce qu'ils ont en commun ». Les patterns récurrents alimentent également directement le reste de votre activité : un sujet qui obtient régulièrement de mauvaises notes est généralement un problème de triage de tickets ou d'escalade, pas un problème de personnes. Corrigez la documentation ou la règle de marquage des tickets derrière et vous réduisez souvent le volume de tickets en même temps.
Étape 5 : Boucler la boucle
Un QA qui ne change rien n'est que du théâtre. La dernière étape consiste à réinjecter les constats : coacher les agents signalés par l'IA, réécrire la documentation derrière les erreurs récurrentes, et mettre à jour la grille à mesure que votre produit et vos politiques évoluent.

Lorsqu'une partie de votre support est automatisée, boucler la boucle signifie aussi corriger l'IA elle-même. Les bons outils apprennent de ces corrections, de sorte qu'une correction que vous faites une fois empêche la même erreur de se reproduire. Cela transforme le QA d'un bulletin de notes rétrospectif en quelque chose qui améliore activement l'automatisation du service client semaine après semaine.
Ce que tout le monde oublie : auditer l'IA elle-même
Voici ce que la plupart des articles sur « l'IA pour le QA » passent sous silence, et c'est ce qui me préoccupe le plus après plus de trois ans à mettre des agents IA sur des files de support en production. Si vous allez laisser l'IA traiter des tickets, cette IA doit réussir le QA avant de toucher un client, et la plupart des équipes ne font jamais cette vérification.
J'ai vu un bot au ton assuré répondre de façon incorrecte à une question avec une totale conviction. Un responsable DTC de compléments alimentaires nous a clairement énoncé le risque : une IA qui répond « désolé, je ne sais pas » à tout est inutile, mais une IA qui devine est pire, parce que personne ne peut relire 7 000 tickets pour attraper les suppositions. La réponse aux deux est le QA : l'agent ne doit traiter que ce dont il est confiant, et vous devez noter son travail de la même façon que vous notez celui d'un humain.
Nous avons donc intégré cette vérification. Avant qu'un agent eesel soit mis en ligne, vous pouvez le faire tourner en simulation sur vos vrais tickets passés et voir sa qualité et sa couverture par sujet, sans qu'aucun client soit impliqué. Lorsque nous avons audité un agent sur le trafic Zendesk réel d'un client, il a obtenu environ 93 % de précision de triage et attrapé 100 % des spams sans faux positifs, mais les réponses brouillon n'étaient directionnellement correctes qu'à 88 % du temps, avec un taux d'erreur factuelle de 7 %. Ces 7 % sont la raison entière pour laquelle vous auditez l'IA : elle semble excellente dans l'agrégat et a quand même besoin d'un seuil de confiance et d'un humain dans la boucle pour les cas difficiles. Les mêmes scores apparaissent ensuite en direct dans vos analytics d'agent, donc le QA sur l'IA ne s'arrête jamais vraiment.
C'est aussi la réponse la plus honnête à « puis-je lui faire confiance ? ». Vous ne lui faites pas confiance sur la foi, vous l'auditez, vous la configurez en brouillon plutôt qu'en envoi automatique là où sa confiance est faible, et vous élargissez son autonomie à mesure que les scores le justifient. C'est la différence entre une démo et un déploiement.
Les erreurs courantes à éviter
Quelques pièges dans lesquels je vois les équipes tomber lorsqu'elles basculent leur QA sur l'IA :
- Traiter la note de l'IA comme définitive. C'est un premier passage, pas un verdict. Vérifiez-la par sondage, surtout au début, de la même façon que vous calibreriez un nouvel analyste.
- Une grille trop grande. Trente critères paraissent rigoureux et notent de façon incohérente. Cinq dimensions précises valent mieux que trente floues.
- Noter les conversations sans jamais boucler la boucle. Si rien ne change (pas de coaching, pas de corrections de documentation, pas de mises à jour de grille), vous avez construit un rapport très complet sur lequel personne n'agit.
- Oublier d'auditer l'automatisation. Si l'IA répond aux tickets, c'est l'« agent » au volume le plus élevé que vous ayez. Ne pas la noter est le plus grand angle mort de tous.
- Confondre QA et CSAT. Un client peut noter une conversation cinq étoiles après avoir reçu une réponse fausse mais assurée. Le QA vérifie si la réponse était réellement correcte, c'est pourquoi vous voulez à la fois vos notes QA et votre rapport CSAT Gorgias ou CSAT Freshdesk, sans que l'un remplace l'autre.
Essayez eesel pour le QA support
Si vous souhaitez faire du QA support avec l'IA sans assembler trois outils différents, c'est exactement ce autour de quoi l'agent helpdesk IA d'eesel est conçu. Il se connecte à votre helpdesk et à votre base de connaissances existants, lit vos conversations passées, et (c'est la partie qui compte pour le QA) vous permet de lancer une simulation sur de vrais tickets historiques pour voir la qualité et la couverture avant que quoi que ce soit ne soit mis en production.

En ce qui concerne les logiciels de service client IA, la partie utile pour le QA est que le même moteur qui note les brouillons d'un agent IA lit également les conversations de votre équipe, de sorte que le QA des humains et le QA de l'automatisation se trouvent au même endroit plutôt que dans deux tableurs séparés. Cela fonctionne comme un coéquipier qui s'intègre en une après-midi et connaît déjà votre centre d'aide, avec une tarification basée sur l'usage qui ne vous facture pas par siège pour le privilège de réviser vos propres tickets. Gratuit à l'essai.
Questions fréquentes
Qu'est-ce que le QA support, et en quoi le QA support par IA est-il différent ?
L'IA peut-elle vraiment noter les conversations support avec précision ?
Quel pourcentage de mon volume support dois-je auditer avec l'IA ?
Le QA support par IA remplace-t-il mes analystes QA ?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.







Comment auditer un agent support IA lui-même ?