
En bref
Oui, l'IA peut faire l'assurance qualité du support, et elle fait ce que le QA humain n'a jamais pu faire : évaluer chaque conversation plutôt qu'un échantillon de 2 %. Donnez-lui une grille claire et vos propres tickets résolus, et elle lit chaque conversation clôturée, la note sur l'exactitude, le ton, la résolution, la politique et le sourcing, puis signale celles qui méritent l'attention d'un humain.
La nuance honnête : c'est un premier passage précis, pas un verdict définitif. Lorsque nous avons audité un agent IA sur le trafic réel de tickets d'un client, il a atteint environ 93 % de précision de triage et capté 100 % des spams, mais ses réponses en brouillon n'étaient directionnellement correctes que 88 % du temps, avec un taux d'erreur factuelle de 7 %. Ce 7 % est exactement la raison pour laquelle un humain garde encore la main sur les décisions de jugement.
Ce que la plupart des équipes oublient : si l'IA répond aux tickets, cet agent IA est le seul agent au plus grand volume que vous ayez, alors évaluez-le avant qu'il touche un client. L'agent helpdesk IA d'eesel effectue cette vérification sous forme de simulation sur votre propre historique de tickets, ce qui est le plus proche d'un passage QA avant la mise en production.
Alors, l'IA peut-elle vraiment faire le QA du support ?
Réponse courte : oui, et mieux que la version manuelle sur la seule dimension qui compte le plus — la couverture.
Je conçois les agents IA qui font cela, alors permettez-moi d'être précis sur ce que signifie « oui ». Le QA support traditionnel, c'est un analyste qui tire une poignée de tickets par agent par semaine, les note dans un tableur, et passe à autre chose. Si votre équipe traite quelques milliers de conversations par mois, c'est une revue de peut-être 2 % d'entre elles — et un 2 % biaisé en plus, car les évaluateurs gravitent vers les tickets faciles à noter. Le cas limite bizarre qui a silencieusement fait partir un client ne fait presque jamais partie de l'échantillon.
L'IA inverse cela. Dès qu'un modèle lit chaque conversation selon votre grille, évaluer 100 % des conversations coûte à peu près le même effort qu'évaluer 2 %. La couverture cesse d'être quelque chose que vous rationnez. Le hic, c'est que « lire tout » et « juger tout correctement » sont deux affirmations différentes. L'IA excelle dans la première. La seconde est là où vous gardez un humain dans la boucle.
Ce que l'IA fait bien (et la preuve)
Voici où le QA IA est vraiment fort — et je préfère vous montrer de vrais chiffres plutôt que des adjectifs.
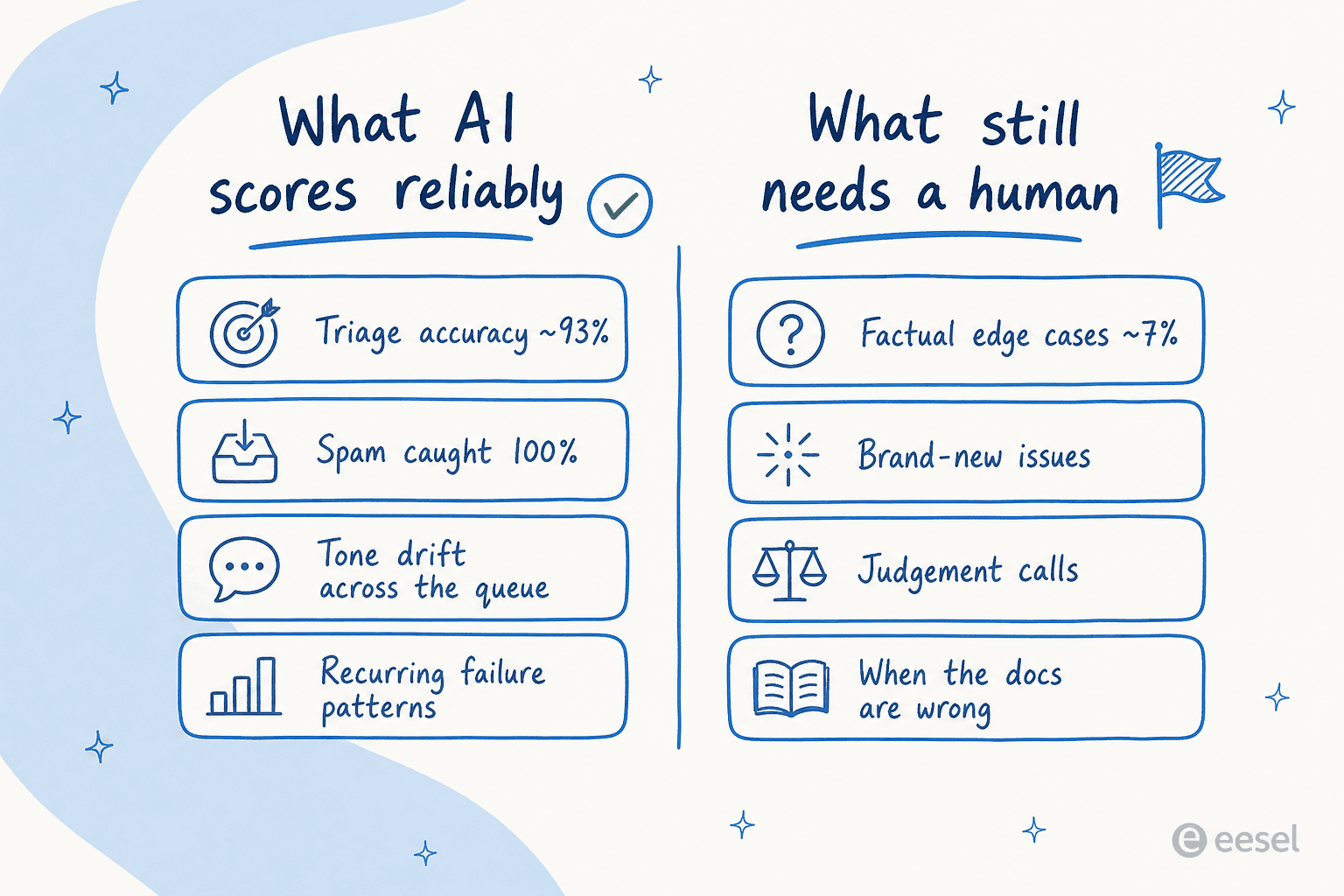
Lorsque nous avons fait tourner un agent sur le trafic Zendesk réel d'un client, il a atteint environ 93 % de précision de triage et capté 100 % des spams sans aucun faux positif, sur une boîte de réception qui était à 22 % spam. Catégorie par catégorie, c'était encore plus précis : des brouillons utiles sur les retours et remboursements 93,8 % du temps, les réclamations de garantie 96,4 %, les demandes de produits et les consultations de statut de remboursement 100 %. Ce sont les tickets répétitifs et à forte densité de motifs que le QA existe pour maintenir cohérents, et un modèle qui a lu votre historique est excellent pour repérer où une réponse dérive du motif.
La même force s'applique à vos humains. L'IA est très douée pour les choses qu'un évaluateur fatigué rate : un ton qui glisse sur les remboursements, une politique qu'un agent continue à appliquer de manière subtilement incorrecte, un sujet où chaque réponse obtient un score bas parce que la doc d'aide sous-jacente est obsolète. Ce sont des motifs, et les motifs sont ce qu'un modèle lisant toute la file d'attente trouve — ce qu'un échantillon de 2 % ne peut structurellement pas faire. Il ne s'ennuie jamais non plus au ticket 4 000, ce que je ne peux pas dire d'une équipe QA humaine.
Comment l'IA évalue-t-elle concrètement une conversation
C'est la partie que les gens s'imaginent être une boîte noire, et ce n'est vraiment pas le cas. Le mécanisme est la même grille qu'un évaluateur humain utiliserait, simplement appliquée à tout.
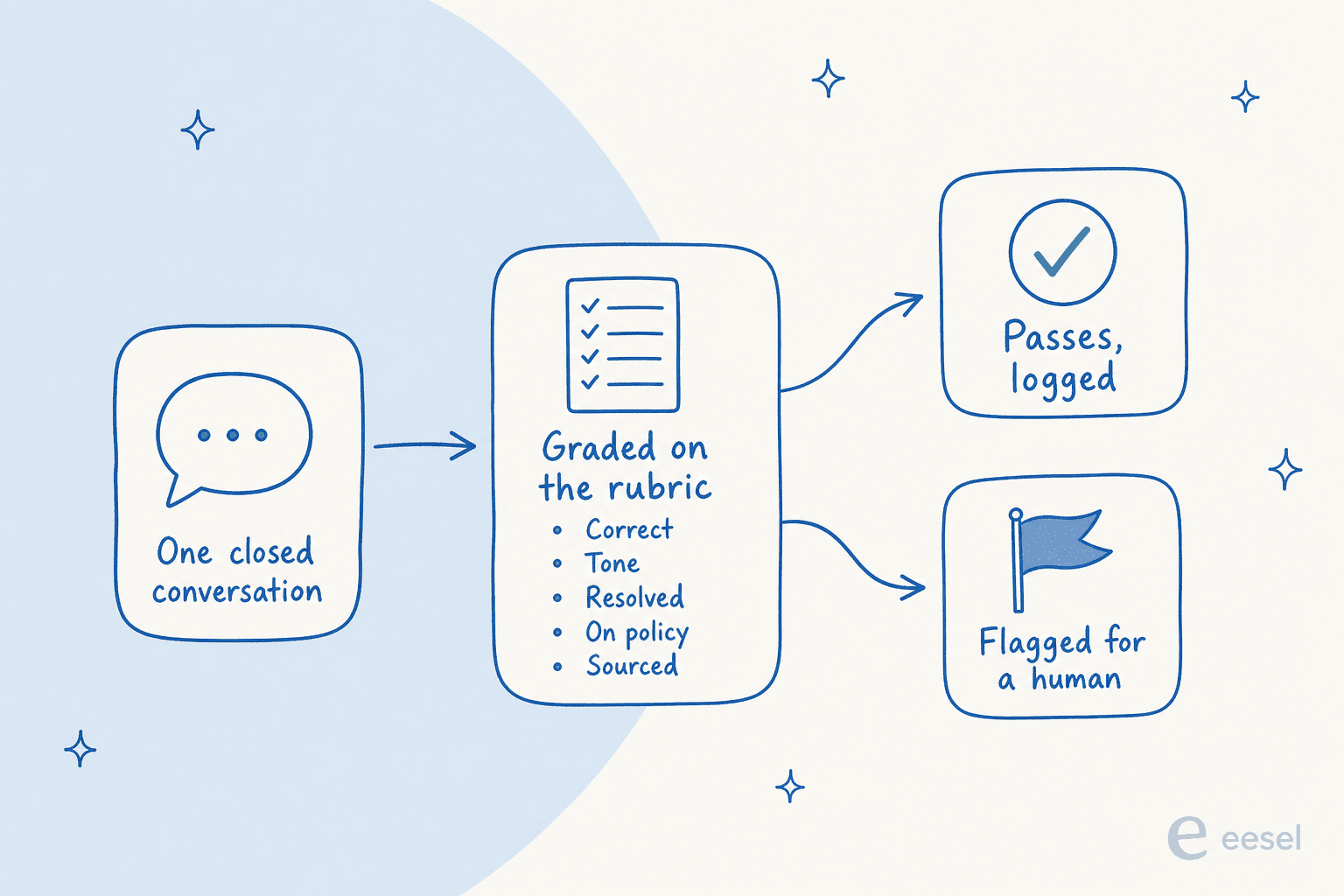
Une conversation clôturée entre. L'IA la note selon quelques dimensions explicites : était-elle factuellement correcte, le ton était-il juste, le problème a-t-il réellement été résolu, la politique a-t-elle été respectée, et a-t-elle cité une vraie source plutôt qu'inventé quelque chose ? Les conversations qui passent sont enregistrées ; celles qui obtiennent un score bas sont signalées à une personne pour examen. Ce que vous voulez en sortie, ce n'est pas un seul chiffre, c'est une ventilation que vous pouvez suivre dans le temps, afin de voir que ce lot a tous échoué sur la même politique ou qu'un sujet fait baisser vos scores.
Deux choses font ou défont cela. Premièrement, la grille doit être explicite — pas de « vous le saurez quand vous le verrez ». Cinq dimensions précises valent mieux que trente floues, pour l'IA comme pour l'humain. Deuxièmement, vous devez lui fournir à la fois les conversations et la base de connaissances dont la réponse aurait dû provenir. Un score de « faux » n'est utile que si vous savez si c'est l'agent qui avait tort ou la documentation — et cette distinction est la différence entre former une personne et réécrire un article. Si vous voulez la construction complète, nous avons rédigé un guide étape par étape sur le QA support avec l'IA.
Là où le QA IA a encore besoin d'un humain
Voici maintenant l'autre moitié honnête, parce qu'un article sur le QA qui ne liste que des points forts est exactement le genre de chose que le QA IA est censé repérer.
Revenons à cet audit. Les brouillons de l'agent étaient directionnellement corrects 88 % du temps, mais seulement 12 % étaient assez bons pour qu'un agent les envoie tels quels, et il y avait un taux d'erreur factuelle de 7 %. Creusez dans l'écart et c'est révélateur : environ 65 % des réécritures concernaient juste la longueur et le ton (l'IA écrivait huit phrases là où l'équipe en envoie trois), environ 20 % nécessitaient des données que l'IA ne pouvait pas voir (une consultation ERP ou logistique), et seulement environ 5 % étaient l'IA qui avait complètement tort. Donc la plupart de ce qui « nécessite un humain » est corrigeable avec une meilleure formation, mais ce dernier fragment d'erreur factuelle est la partie que vous n'automatisez jamais entièrement.
L'exemple le plus frappant que j'ai observé : l'IA d'une équipe disait avec assurance aux clients « oui, nous prenons en charge votre modèle » pour des produits qui n'étaient pas réellement dans leur base de données, parce que le centre d'aide indiquait « nous prenons en charge tous les modèles ». L'IA n'hallucinait pas — elle répétait fidèlement une doc qui était fausse. Aucun niveau de qualité de modèle ne rattrapera cela seul. Un humain lisant le motif signalé le repère en cinq minutes. C'est la vraie division du travail dans l'IA vs le support humain : l'IA lit tout et remonte le motif suspect, une personne décide de ce que cela signifie et corrige la cause racine.
Donc les choses à garder sous surveillance humaine : les nouveaux problèmes sans précédent dans votre historique, les décisions de jugement comme une exception de bonne volonté, tout ce qui dépend d'un contexte métier qui vit dans la tête de quelqu'un plutôt que dans vos docs, et l'étalonnage périodique des propres scores de l'IA. Traitez la note de l'IA comme l'opinion d'un deuxième analyste, pas comme un verdict final, et vous obtenez la couverture sans les angles morts.
Le test que la plupart des équipes ignorent : l'IA peut-elle s'évaluer elle-même ?
Voici le point que la plupart des articles « IA pour le QA » survolent, et c'est celui qui me préoccupe le plus. Si vous allez laisser l'IA gérer des tickets, cet agent IA doit passer le QA avant de toucher un client — et la plupart des équipes ne font jamais cette vérification.
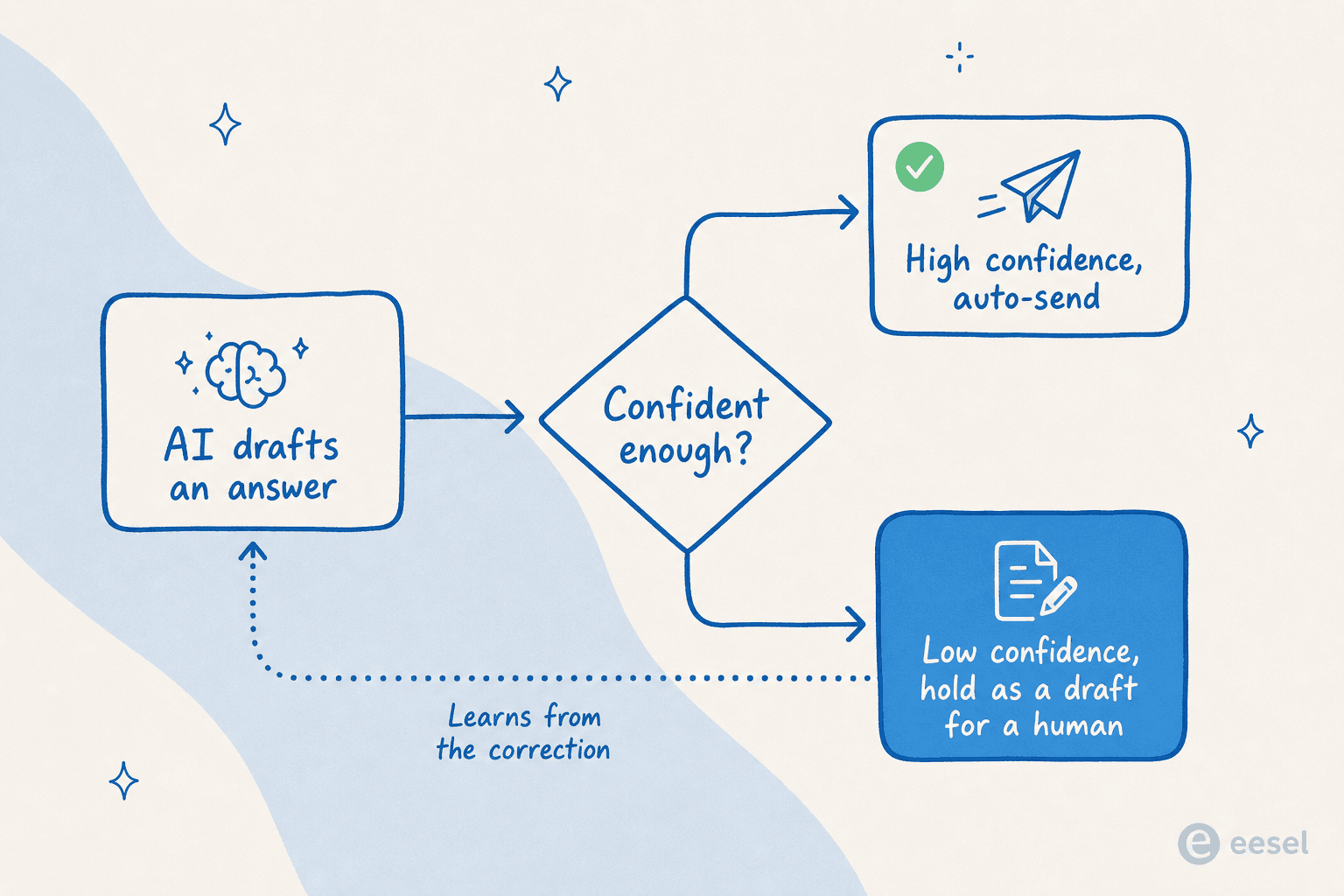
Le mécanisme est le routage basé sur la confiance. L'agent n'envoie automatiquement que les réponses dont il est confiant ; tout ce qui est en dessous du seuil est retenu comme brouillon pour un humain, et il apprend de la correction pour que la même erreur cesse de se répéter. Un responsable de suppléments DTC nous a parfaitement résumé les enjeux : une IA qui répond « désolé, je ne sais pas » à tout est inutile, mais une IA qui devine est pire, « parce que personne ne peut relire 7 000 tickets pour repérer les suppositions ». Le QA est la réponse aux deux.
Nous avons donc intégré la vérification dans le déploiement. Avant qu'un agent eesel soit mis en production, vous le faites tourner dans une simulation sur vos vrais tickets passés et vous voyez sa qualité et sa couverture par sujet, sans aucun client impliqué. C'est ainsi que nous avons obtenu les chiffres de 93 % et 7 % en premier lieu, du côté sûr du verre. Une fois en production, les mêmes scores apparaissent dans vos analytics d'agent, donc le QA sur l'automatisation ne s'arrête jamais vraiment.

C'est aussi la réponse la plus honnête à « puis-je lui faire confiance ? ». Vous ne lui faites pas confiance par foi. Vous le passez au QA, vous le configurez en brouillon plutôt qu'en envoi automatique là où sa confiance est faible, et vous élargissez son autonomie au fur et à mesure que les scores le méritent. C'est la ligne entre une démo et un déploiement.
Comment les équipes utilisent concrètement le QA IA au quotidien
En pratique, cela se stabilise en une boucle, et la boucle importe plus que n'importe quel score individuel. L'IA évalue chaque conversation à mesure qu'elle se clôture. Elle remonte les moments de coaching qu'un humain devrait examiner, regroupés par ce qu'ils ont en commun, plutôt que cinq tickets aléatoires. Un responsable d'équipe agit sur les tendances : former les agents signalés, corriger les docs derrière les erreurs répétées, mettre à jour les règles de tagging de tickets et d'escalade qu'un sujet à score faible expose. Corrigez la doc derrière une erreur récurrente et vous réduisez souvent le volume de tickets en même temps.
En termes d'outils, vous avez deux camps. Les plateformes QA dédiées comme Zendesk QA (le produit anciennement connu sous le nom de Klaus) et MaestroQA évaluent automatiquement les conversations et alimentent les workflows de coaching — elles conviennent bien si le QA est une fonction autonome pour vous. L'autre camp est celui des logiciels de service client IA qui intègrent le QA aux côtés de l'agent qui fait le travail, de sorte que le même moteur qui évalue les conversations de votre équipe est celui qui fait le QA des brouillons de l'IA. Une dernière garde-fou mérite d'être dit clairement : le QA n'est pas le CSAT. Un client peut noter cinq étoiles une réponse faussement confiante, donc vous voulez à la fois vos scores QA et votre rapport CSAT, pas l'un se substituant à l'autre.
Essayez eesel pour le QA du support
Si vous voulez un QA de support IA sans assembler trois outils ensemble, c'est exactement ce pour quoi l'agent helpdesk IA d'eesel est conçu. Il se connecte à votre helpdesk existant, lit vos conversations passées et votre base de connaissances, et vous permet de lancer une simulation sur de vrais tickets historiques afin de voir la qualité et la couverture avant que quoi que ce soit ne soit mis en production.

La partie utile pour le QA, c'est que le même moteur qui évalue les brouillons d'un agent IA est celui qui lit les conversations de votre équipe — donc le QA sur les humains et le QA sur l'automatisation vivent au même endroit plutôt que dans deux tableurs. Cela se branche en une après-midi, connaît déjà votre centre d'aide, et la tarification à l'usage ne vous facture pas par siège pour le privilège de réviser vos propres tickets. Gratuit pour essayer.
Questions fréquemment posées
L'IA peut-elle faire l'assurance qualité du support avec précision ?
Que ne peut pas faire l'IA en matière d'assurance qualité du support ?
Quelle part de mon volume de support l'IA QA peut-elle couvrir ?
L'IA peut-elle aussi évaluer un agent de support IA ?
Le QA IA remplace-t-il mes analystes QA ?
Quels outils peuvent faire l'assurance qualité du support avec l'IA ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








Comment l'IA évalue-t-elle concrètement une conversation de support ?