L'essentiel
Claude Fable 5 est le modèle le plus puissant d'Anthropic, et la réponse courte à « que peut-il faire » est : un travail réel, en plusieurs étapes, qui tourne pendant des jours sans qu'un humain ait à le relancer à chaque tour. Il planifie, écrit et livre du code, lit d'énormes documents, délègue à des sous-agents et vérifie sa propre sortie. Dans les benchmarks d'Anthropic, c'est le modèle le plus puissant accessible au public, et les premiers testeurs le qualifient de meilleur modèle de codage disponible.
Deux mises en garde honnêtes l'accompagnent. Il est lent et coûteux, à 10 $ par million de tokens d'entrée et 50 $ par million de sortie, soit le double d'Opus 4.8. Et il ne répondra pas toujours à pleine puissance : une couche de sécurité renvoie discrètement certains prompts vers un modèle plus faible.
Si vous dirigez une équipe de support ou d'opérations, l'enseignement pratique est qu'un modèle aussi capable est le moteur, pas la voiture. Ce que vous déployez réellement, c'est un agent IA construit par-dessus, avec les connaissances, les garde-fous et les tests que le modèle brut n'inclut pas.
Alors, que peut réellement faire Claude Fable 5 ?
Claude Fable 5 est la cinquième génération de modèles d'Anthropic et un nouveau palier « classe Mythos » qui se situe au-dessus de Claude Opus 4.8, lui-même au-dessus de Sonnet 4.6. Si vous avez lu notre aperçu de Claude, c'est le nouveau plafond. Il est sorti le 9 juin 2026 et fonctionne sur claude.ai, l'API Claude, Claude Code, AWS et Microsoft Foundry.
Mais les specs et les paliers ne sont pas vraiment ce que les gens veulent dire quand ils demandent ce qu'il peut faire. Ils veulent dire : quel travail puis-je lui confier en lui faisant confiance pour le mener à terme ? Voici la carte honnête de ses capacités concrètes, puis nous passerons chacune en revue.
Il fonctionne de façon autonome pendant des jours, puis vérifie son propre travail
C'est la capacité autour de laquelle Anthropic a réellement bâti Fable 5, et c'est celle qui compte le plus. Faites-le tourner dans un harnais comme Claude Code ou Claude Managed Agents et, selon les mots d'Anthropic, il peut « travailler pendant des jours d'affilée : planifier à travers les étapes, déléguer à des sous-agents et vérifier son propre travail. »
Cette boucle — planifier, puis déléguer, puis travailler, puis vérifier — est la partie réellement nouvelle. Les modèles précédents perdaient le fil sur des tâches longues et en plusieurs étapes ; celui-ci garde le cap et, surtout, corrige sa propre copie. Anthropic le décrit comme « minutieux, proactif et testant son propre travail », et les fournisseurs cloud détaillent une boucle planifier, vérifier, affiner intégrée. L'autocorrection est la différence entre un agent qu'on doit surveiller et un agent qu'on peut laisser tourner toute la nuit.
L'échelle que cela débloque est réelle. Lors des premiers tests, Stripe a pointé Fable 5 vers une base de code Ruby de 50 millions de lignes et a exécuté une migration sur l'ensemble du projet en une journée, et des rapports de la communauté décrivent des sessions lançant jusqu'à 1 000 sous-agents en parallèle pour du travail à l'échelle d'une base de code. Cette capacité à tenir un objectif, à le découper en étapes et à les enchaîner est exactement ce qui sépare un agent IA d'un chatbot à base de règles : l'un termine le travail, l'autre attend l'instruction suivante.
Il écrit et livre du code de qualité production
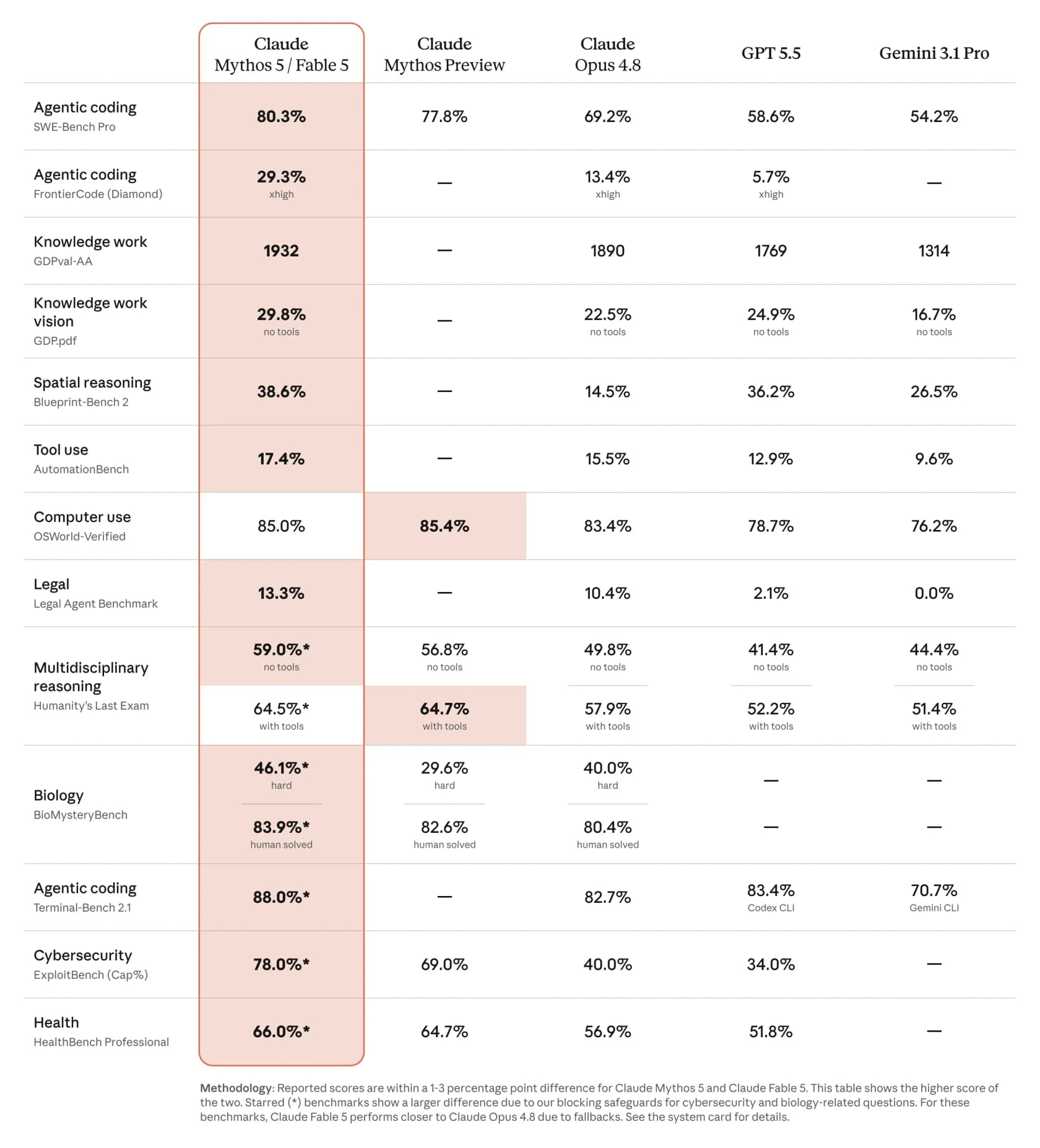
La chose la plus spectaculaire que Claude Fable 5 sait faire, c'est écrire des logiciels qui fonctionnent réellement. Dans la comparaison publiée par Anthropic, il obtient 80,3 % sur SWE-Bench Pro en codage agentique, contre 69,2 % pour Opus 4.8, avec GPT 5.5 à 58,6 % et Gemini 3.1 Pro à 54,2 %. Sur le benchmark plus difficile FrontierCode (Diamond), il fait plus que doubler Opus, passant de 13,4 % à 29,3 %. CNBC a rapporté un écart de plus de 10 % au-dessus d'Opus 4.8 sur certains tests.
Les chiffres sont une chose ; une journée entière de vrai travail en est une autre. Le développeur Simon Willison a pointé Fable vers sa bibliothèque LLM open source, et il a identifié et implémenté quatre correctifs distincts, puis a livré une nouvelle version presque entièrement écrite par le modèle. Son verdict résume bien le plafond de productivité :
« Je suis vraiment impressionné par la qualité de la conception de l'API, des tests, du code et de la documentation que Fable a assemblés pour cela. J'y ai passé plusieurs heures aujourd'hui, mais on dirait l'équivalent de plusieurs jours de travail. » - Simon Willison
Il n'était pas le seul. Andrej Karpathy l'a qualifié de bond en avant méritant un changement de version majeure, et un développeur faisant tourner le benchmark FrontierCode a publié une progression frappante : Opus 4.7 à 5,2 %, Opus 4.8 à 13,4 %, Fable 5 à 29,3 %. Si vous évaluez où il se situe par rapport au reste du domaine, notre tour d'horizon des meilleurs outils d'assistant de codage IA et des meilleurs outils de développement IA de Claude est une bonne lecture pour la suite.
Il lit les longs documents en désordre que vous avez déjà
Une grande partie du travail en entreprise n'est pas du code, ce sont des documents, et c'est là que la fenêtre de contexte d'un million de tokens gagne sa place. Fable 5 « comprend les diagrammes, graphiques et tableaux imbriqués dans des fichiers et des PDF », ce qu'Anthropic positionne autour du travail financier, juridique et analytique, et il n'y a pas de supplément de prix pour remplir ce contexte complet.
La preuve concrète est venue d'un utilisateur de Hacker News qui lui a confié un PDF de 50 pages de spécifications denses et interconnectées et a obtenu en retour une décomposition correcte de ce qui était fait, partiellement fait et manquant :
« Je lui ai donné un PDF de 50 pages de spécifications assez denses et interconnectées et je lui ai demandé lesquelles avaient été implémentées... il a correctement identifié ce qui était fait, ce qui était partiellement fait et ce qui manquait. » - Commentateur sur Hacker News
Pour toute équipe assise sur une pile de contrats, de documents de politique interne ou une vaste base de connaissances, c'est plus utile au quotidien qu'un point de plus sur un classement de codage. C'est aussi le même muscle qu'un agent de support utilise quand il lit vos documents d'aide et vos tickets passés pour répondre à un client, simplement pointé vers des documents internes.
Ce que tout cela coûte
Voici la partie qui tempère l'enthousiasme. Tout ce qui précède tourne aux prix d'un outil de pointe : 10 $ par million de tokens d'entrée et 50 $ par million de sortie, exactement le double d'Opus 4.8. Les tokens d'entrée mis en cache bénéficient d'une réduction de 90 %, et il y a un supplément de 1,1x pour l'inférence aux États-Unis uniquement, mais c'est le tarif affiché que vous ressentirez. Pour voir comment Fable 5 se positionne face au reste de la gamme, notre guide de tarification de Claude décompose chaque palier, et le forfait Claude Pro est là où la plupart des particuliers le rencontrent pour la première fois.
| Spécification | Claude Fable 5 |
|---|---|
| Sortie | 9 juin 2026 |
| Classe de modèle | « Classe Mythos », un palier au-dessus d'Opus 4.8 |
| Fenêtre de contexte | 1 000 000 de tokens |
| Sortie maximale | 128 000 tokens |
| Date limite de connaissances | Janvier 2026 |
| Prix d'entrée | 10 $ / 1 M de tokens (1 $ en cache) |
| Prix de sortie | 50 $ / 1 M de tokens |
| Supplément contexte long | Aucun |
Combien vous dépensez réellement dépend presque entièrement de l'intensité de réflexion que vous lui accordez. Simon Willison a fait passer son test « dessine un pélican à vélo » à travers les cinq niveaux d'effort de réflexion, et le coût d'une seule image allait de moins de 10 centimes en « low » à environ 72 centimes en « max ». Le niveau d'effort est un curseur que vous réglez, et c'est le principal levier de votre facture.
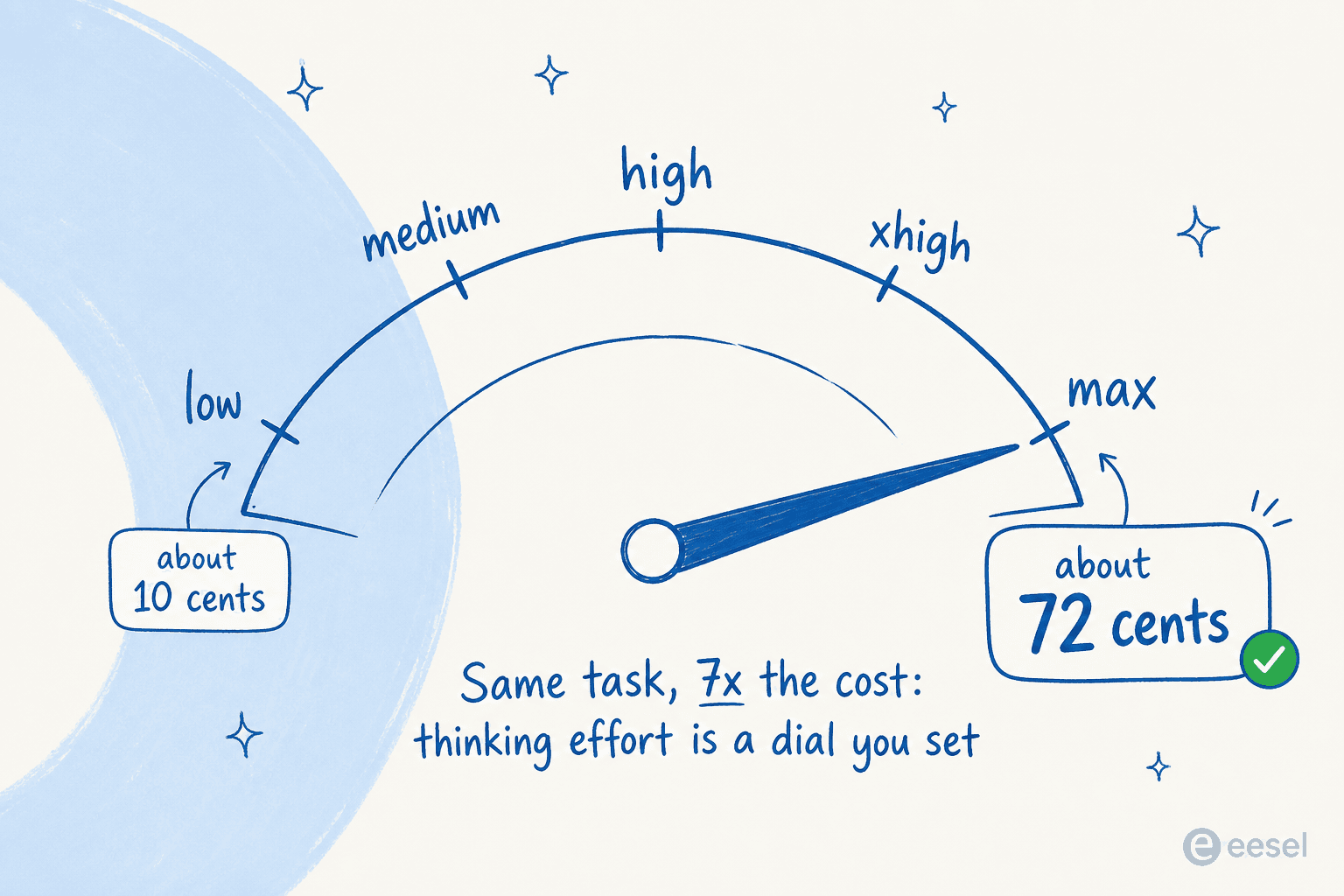
La facture grimpe vite en haut de gamme. Willison a suivi une seule journée de tests à 110,42 $ de dépenses en tokens. Mais il existe un vrai contrepoids : le responsable des évaluations de Canva a constaté que Fable utilisait environ la moitié des tokens d'Opus 4.8 dans leurs harnais agentiques internes, de sorte qu'un modèle plus intelligent qui termine en moins d'étapes peut aboutir à un coût réel à peu près équivalent. La leçon n'est pas « Fable est inabordable », c'est que vos coûts dépendent entièrement de la façon dont vous l'exécutez.
Ce que Claude Fable 5 ne fera pas
Les capacités sont à double tranchant, et il y a une chose que Fable 5 refuse délibérément de faire à pleine puissance. Pour les prompts de cybersécurité, de biologie, de chimie et de distillation de modèles, une nouvelle génération de classificateurs détecte le sujet et route votre réponse vers Opus 4.8 à la place, et on vous le signale. Anthropic affirme qu'au moins 95 % des sessions ne déclenchent jamais de repli.
Le hic, ce sont les faux positifs. Des développeurs ont signalé avoir été basculés vers le modèle plus faible en pleine session pour un travail tout à fait inoffensif, dont un utilisateur s'étant vu refuser un protocole basique de manipulation de liquides ne comportant rien de risqué. L'auteur en politique de l'IA Nathan Lambert a signalé un second mécanisme, plus discret, pour les prompts qui ressemblent à de la recherche de pointe en IA, où le modèle peut devenir moins efficace sans vous le dire. Le conseil pratique : si votre travail relève d'un secteur technique, testez avant de vous y engager.
Ce que tout cela signifie si vous dirigez une équipe de support
C'est notre domaine, alors soyons précis. Compte tenu de tout ce que Fable 5 peut faire, un responsable de support devrait-il se précipiter pour le brancher sur son helpdesk ? La plupart du temps, pas autant que le battage médiatique le suggère.
Voici la vérité inconfortable sur l'IA pour le service client : pour les tickets de niveau 1, le modèle est rarement le goulot d'étranglement. La plupart des équipes en quête d'automatisation du service client surévaluent discrètement le modèle qui se trouve en dessous. Un Opus 4.8 bien grounded, ou même Sonnet 4.6, répond déjà correctement à l'écrasante majorité des questions du type « où est ma commande », « comment réinitialiser mon mot de passe », « quelle est votre politique de remboursement ». Payer le double pour Fable 5 afin d'y répondre, c'est comme louer une voiture de Formule 1 pour aller déposer les enfants à l'école. Ce qui décide réellement si votre agent de helpdesk IA fonctionne, c'est tout ce qui enveloppe le modèle. C'est le même schéma qui sépare les outils solides de tout tour d'horizon de logiciels de helpdesk IA de ceux qu'on oublie.
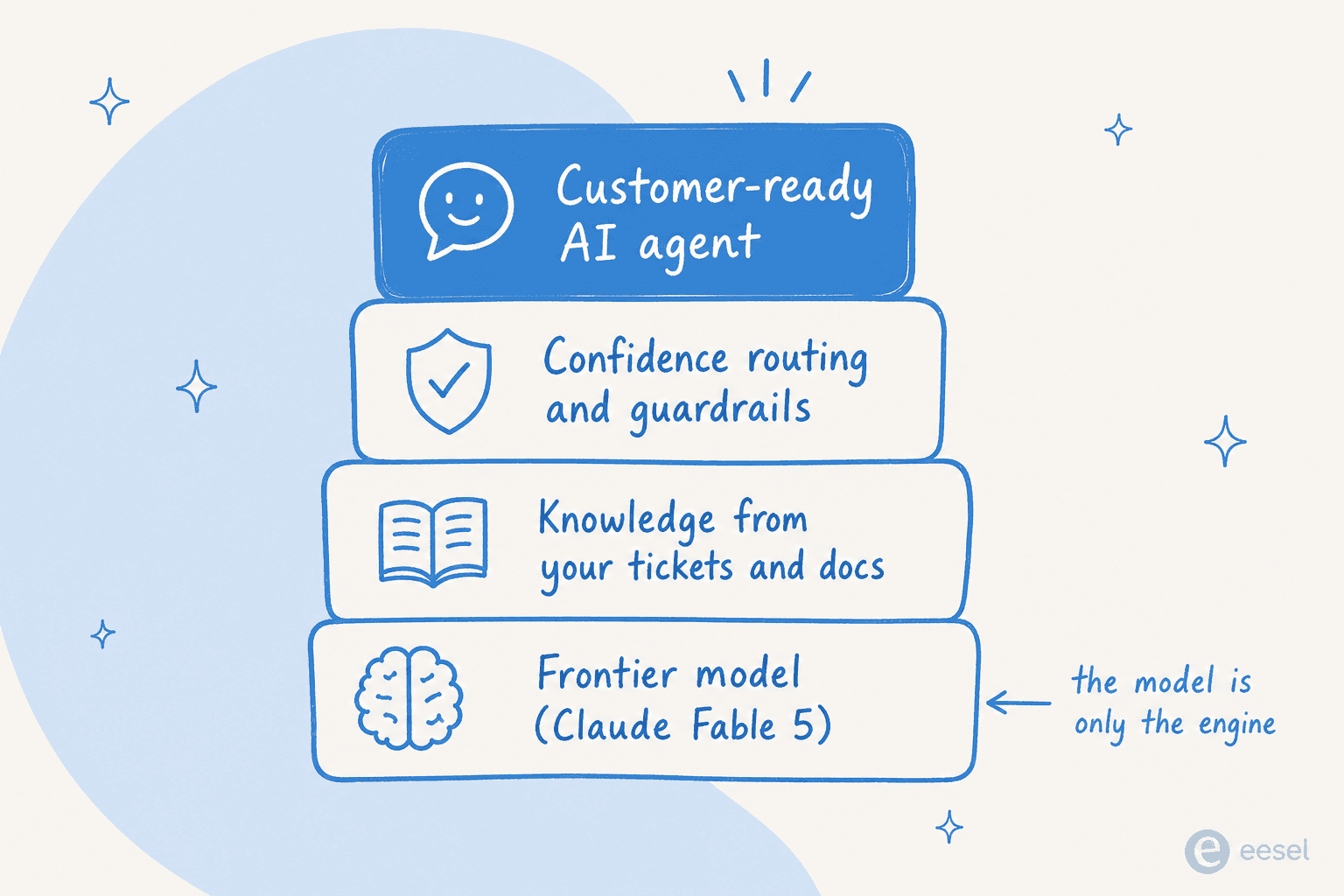
Trois choses comptent plus que le palier du modèle. Premièrement, connaît-il votre entreprise ? Le gain vient de l'entraînement sur vos tickets passés et vos documents d'aide, pas d'un modèle de base plus intelligent. Deuxièmement, sait-il quand se taire ? Les modèles bruts répondent avec assurance même lorsqu'ils ont tort, ce qui explique précisément pourquoi les chatbots donnent de mauvaises réponses ; les agents de production ont besoin d'un routage basé sur le niveau de confiance, le cœur de toute bonne configuration de tri des tickets, pour que les tickets à faible confiance soient mis en brouillon ou escaladés, et non envoyés automatiquement. Comme l'a formulé le responsable CX d'un fournisseur DTC de compléments alimentaires lors d'un entretien client, l'IA ne répondra jamais à 100 % des questions, donc ce qu'ils veulent vraiment, c'est un agent qui ne traite que les tickets sur lesquels il a confiance et laisse le reste tranquille. C'est une capacité produit, pas une capacité du modèle.
Troisièmement, pouvez-vous lui faire confiance avant la mise en production ? Cela renvoie directement à la question du faire ou acheter, qui revient sans cesse : « Anthropic vient de sortir un modèle incroyable, pourquoi ne pas construire notre bot de support sur l'API ? » Vous pouvez. C'est aussi un projet plus gros qu'il n'y paraît, car le modèle vous donne l'intelligence mais pas la connexion au helpdesk, les garde-fous, l'environnement de simulation ou les rapports. Plusieurs équipes techniques qui ont essayé sont passées à l'achat :
« Nous aurions pu essayer d'écrire notre propre application LLM, mais nous ne voulions pas y investir notre temps. Nous voulions quelque chose que nous n'aurions pas à maintenir. » - Karel, GENERAL BYTES
Un modèle de pointe est la couche la plus basse de la pile, pas la pile entière. Si votre produit principal, c'est l'IA, construisez. Si c'est autre chose et que vous voulez simplement que les tickets soient bien traités, acheter les couches au-dessus du modèle est plus rapide, moins cher et moins fragile, la même logique que celle qui sous-tend le choix de n'importe quelle IA pour l'automatisation des tickets plutôt qu'un script maison.
Essayez eesel
eesel AI est la couche qui se pose au-dessus des modèles de pointe comme Claude, de sorte que vous obtenez la capacité sans le projet d'ingénierie. Elle se branche sur votre helpdesk existant (Zendesk, Freshdesk, HubSpot, Gorgias et plus de 100 intégrations), apprend de vos tickets passés et de vos documents d'aide dès le premier jour, et répond sur le tri, la rédaction et la résolution.

Le facteur différenciant est la partie que Fable 5 ne peut pas vous donner seul : un mode simulation qui fait tourner l'agent sur des milliers de vos tickets passés afin que vous voyiez exactement comment il aurait répondu, et quel serait votre taux de résolution, avant qu'un seul client ne lui parle. C'est ainsi que Gridwise a atteint 73 % des demandes de niveau 1 résolues dès son premier mois. Et comme la tarification est à l'usage, à 0,40 $ par ticket résolu sans frais par siège, vous payez pour des résultats, pas pour des tokens que vous ne pouvez pas prévoir. Vous pouvez essayer eesel gratuitement avec 50 $ d'usage et sans carte bancaire.
Foire aux questions
Que peut faire Claude Fable 5 que les modèles plus anciens ne pouvaient pas ?
Claude Fable 5 peut-il écrire et exécuter du code tout seul ?
Claude Fable 5 peut-il traiter des questions de support client ?
Combien coûte l'exécution de Claude Fable 5 ?
Que ne peut pas faire Claude Fable 5 ?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.