
Ce qu'est vraiment Claude Sonnet 5
Je construis des intégrations et des API pour gagner ma vie, donc quand un nouveau modèle sort, je lis la documentation avant le fil de discussion du lancement. Voici ce que la documentation officielle d'Anthropic dit de Claude Sonnet 5, sans le vernis marketing.

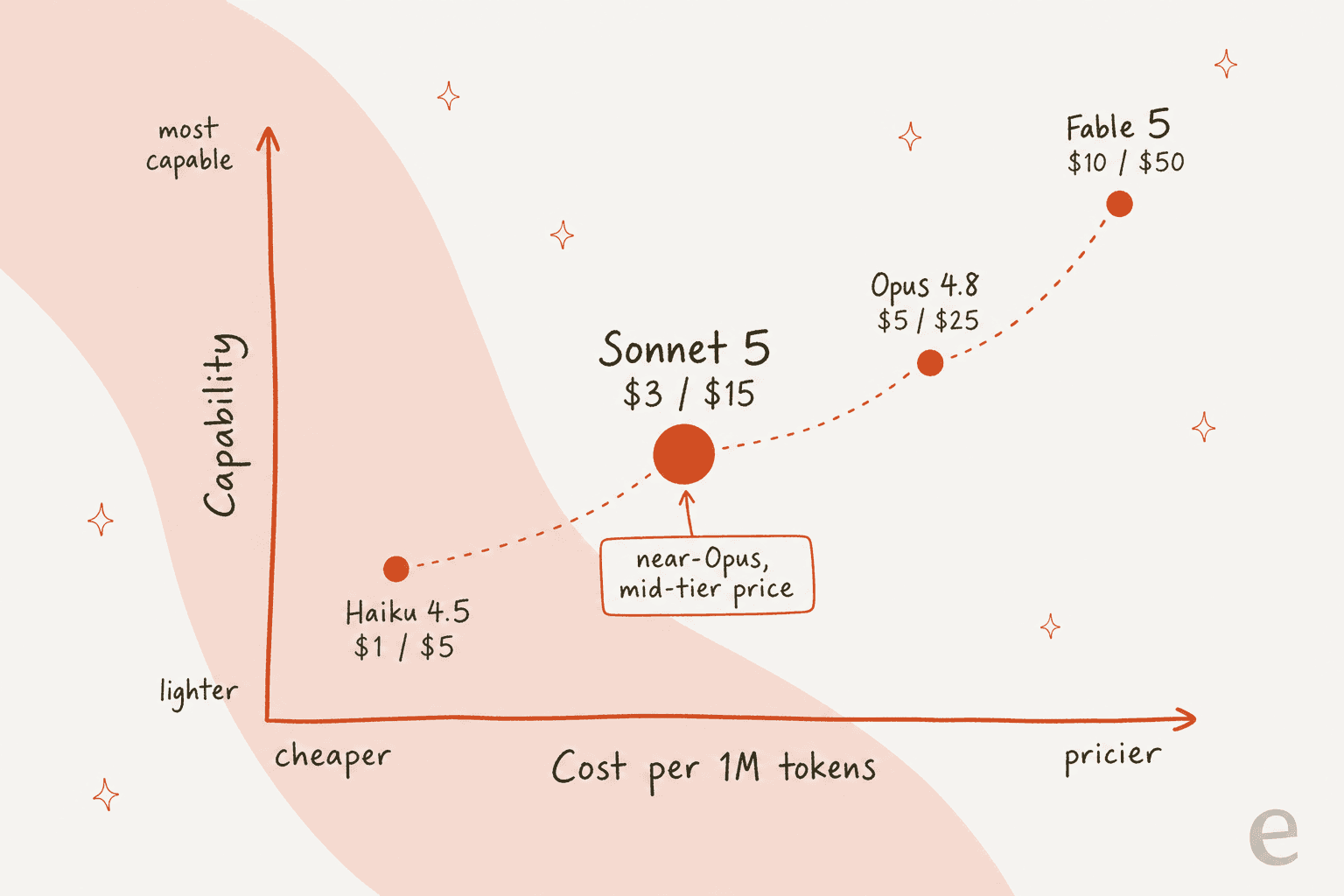
Anthropic a annoncé Sonnet 5 fin juin 2026 comme « notre Sonnet le plus agentique à ce jour », et en a fait le modèle par défaut dès le premier jour pour les utilisateurs Claude gratuits et Pro. C'est le palier équilibré de la famille Claude 5. Il fonctionne avec une fenêtre de contexte de 1M de tokens et jusqu'à 128K tokens en sortie, le même plafond que le palier Opus. L'argument est qu'il atteint une qualité proche d'Opus spécifiquement sur le codage et les tâches agentiques, le type de travail multi-étapes utilisant des outils qu'effectue un agent de support, tout en coûtant bien moins cher à faire fonctionner. La comparaison approximative d'Anthropic est que Sonnet 5 en effort medium équivaut à l'ancien Sonnet 4.6 en high, et que Sonnet 5 en high équivaut à 4.6 en max. En d'autres termes, vous en avez plus pour le même réglage.
Sa place dans la famille est la vraie histoire. Anthropic propose désormais quatre paliers publics, et Sonnet 5 est celui que la plupart des équipes mettront réellement en production.
Quelques nouveautés sous le capot, et elles comptent plus que le numéro de version ne le laisse penser :
- La réflexion adaptative est activée par défaut. Vous ne définissez plus un « budget de réflexion » fixe en tokens. Le modèle décide de la quantité de raisonnement à appliquer par requête, et vous l'ajustez avec un cadran
effortà la place. xhigharrive au palier Sonnet. Sonnet 5 est le premier modèle Claude de palier équilibré à proposer le réglagexhigh, qu'Anthropic recommande pour les tâches de codage et agentiques les plus difficiles. C'est le même cadran sur lequel s'appuie Claude Code.- Vision haute résolution. Sonnet 5 lit des images jusqu'à 2576px sur le plus grand côté, utile si vos flux de support impliquent des captures d'écran ou des reçus.
- Un nouveau tokenizer. Plus de détails ci-dessous, car cela change discrètement votre facture.
Tarifs de Claude Sonnet 5
Voici la partie que tout le monde attendait vraiment. Le tarif API de Sonnet 5 est de 3 $ par million de tokens en entrée et 15 $ par million en sortie, avec des tarifs de lancement de 2 $/10 $ valables jusqu'au 31 août 2026. Côté grand public, Sonnet est le palier « équilibré » au sein d'un abonnement Claude.
Comparé à ses cousins, l'argument de valeur est clair :
| Modèle | Entrée ($/1M) | Sortie ($/1M) | Contexte | Idéal pour |
|---|---|---|---|---|
| Haiku 4.5 | 1 $ | 5 $ | 200K | Tâches rapides, économiques et simples |
| Claude Sonnet 5 | 3 $ (lancement 2 $) | 15 $ (lancement 10 $) | 1M | Codage et tâches agentiques à grande échelle |
| Opus 4.8 | 5 $ | 25 $ | 1M | Travail autonome le plus complexe et le plus long |
| Fable 5 | 10 $ | 50 $ | 1M | Le raisonnement le plus exigeant |
Sonnet 5 est donc environ 40 % moins cher qu'Opus 4.8, en entrée comme en sortie, tout en revendiquant l'essentiel de sa capacité sur les tâches qu'exécute un agent de support. Pour une file d'attente traitant des millions de tokens par mois, cet écart s'accumule vite.
Mais il y a un piège qui n'apparaît pas sur la grille tarifaire. Sonnet 5 utilise un nouveau tokenizer qui compte environ 30 % de tokens en plus pour le même texte que ne le faisait Sonnet 4.6. Le prix par token est plus bas, mais chaque conversation représente désormais plus de tokens, donc votre coût réel par ticket résolu peut atterrir ailleurs que ce que suggère une estimation au dos d'une enveloppe.
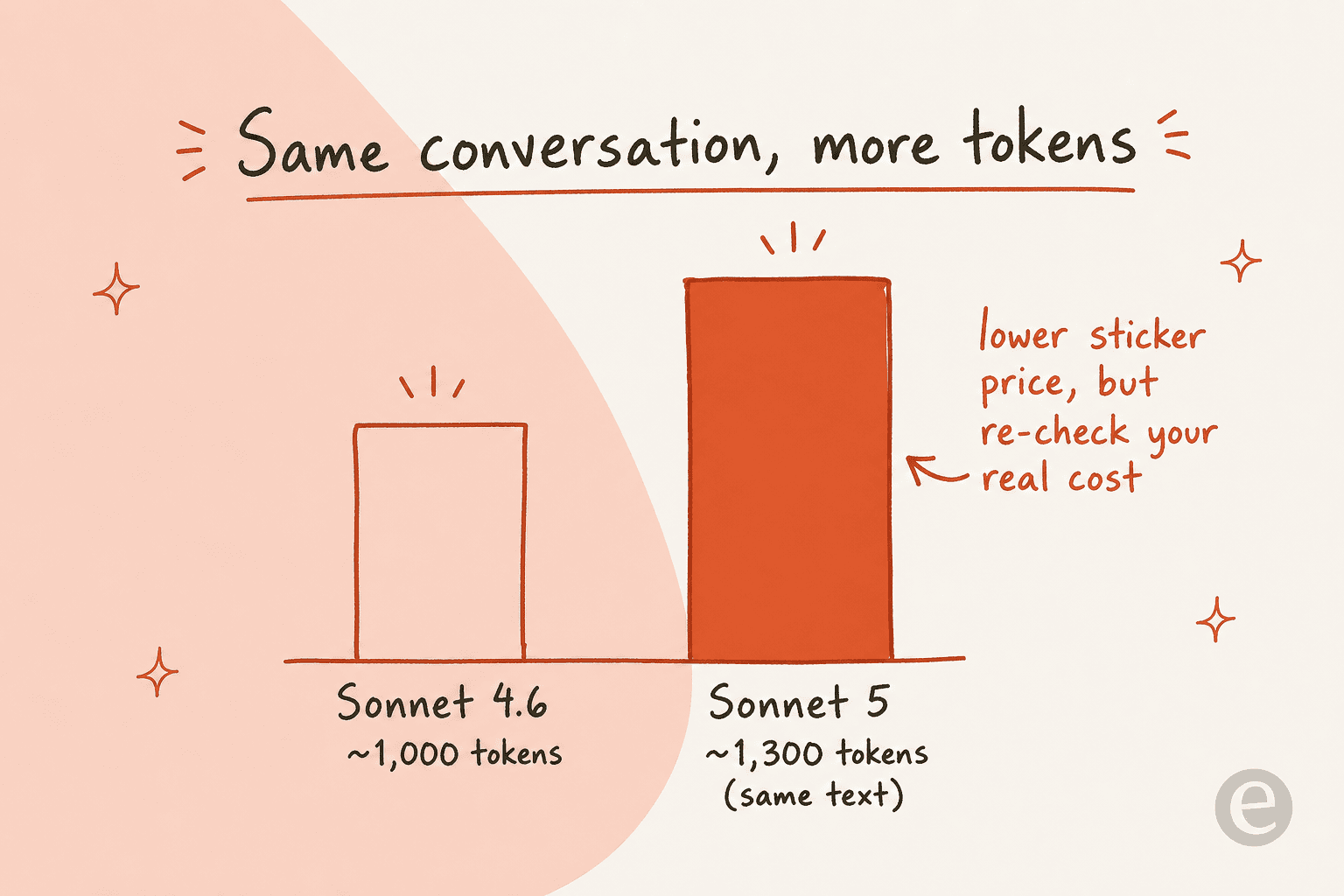
C'est déjà le débat qui agite Sonnet 5. Ses partisans y voient un travail de niveau Opus au prix de Sonnet, mais des analyses plus pointues sur X font remarquer qu'une fois la remise de lancement terminée et en fonctionnant à effort élevé, le coût par tâche peut en réalité dépasser celui d'Opus 4.8 selon des indices indépendants. Les deux peuvent être vrais à la fois : l'étiquette est plus basse, le nombre de tokens est plus élevé, et l'effort fait varier le total dans un sens ou dans l'autre.
Les réactions de terrain vont dans le même sens. Dans un fil de premières impressions sur r/ClaudeAI (plus de 90 commentaires quelques heures après le lancement), un développeur a ouvert le débat avec exactement le compromis dont il est question dans cet article :
« J'utilise Sonnet 5 en effort [xhigh] depuis environ 30 minutes, principalement sur des tâches que je confierais à Opus 4.8... »
fil de premières impressions, r/ClaudeAI
C'est le signal à surveiller : des gens qui se tournent vers Sonnet 5 pour des tâches qu'ils confiaient auparavant à Opus. Savoir si cela se vérifie sur vos tickets est une question à laquelle aucun benchmark ne peut répondre, ce qui est tout l'objet de la section suivante.
En pratique : mesurez la consommation de tokens sur vos propres tickets avec claude-sonnet-5 plutôt que de réutiliser un chiffre obtenu avec un modèle plus ancien. Si vous essayez de modéliser le coût total de possession spécifiquement pour le support, le guide sur le coût d'un agent de support IA est un meilleur point de départ que le calcul brut par token, car la majeure partie du coût d'un agent de support n'est jamais le modèle.
Ce qui a changé depuis Sonnet 4.6
Si vous mettez à jour une intégration existante plutôt que de repartir de zéro, quatre points sont à connaître avant de changer la chaîne du modèle :
- La réflexion fonctionne différemment. L'ancien contrôle fixe
budget_tokensa disparu sur Sonnet 5. Omettre le réglage de réflexion active désormais automatiquement la réflexion adaptative, alors qu'auparavant elle s'exécutait sans réflexion. Si vous n'y avez jamais touché, vos requêtes vont discrètement commencer à raisonner davantage (et à consommer plus de votre budget de sortie), donc laissez un peu de marge àmax_tokens. - L'effort est votre cadran principal. Gardez
highcomme réglage par défaut et passez àxhighpour les tâches agentiques les plus difficiles. Abaissez-le àmediumoulowpour les tâches économiques et sensibles à la latence comme le marquage des tickets ou la classification d'intention. - Le changement de tokenizer est réel. Comme vu plus haut, refaites vos calculs de référence de tokens. C'est la façon la plus courante dont une migration surprend une équipe finance.
- La vision est devenue plus précise. L'entrée d'image haute résolution est automatique. Pratique si vous triez des tickets qui arrivent sous forme de captures d'écran.
Rien de tout cela n'est spectaculaire si vous fonctionnez déjà sur l'API Claude. C'est un changement de chaîne de modèle plus un réajustement, pas une réécriture. La plateforme développeur Claude conserve la même structure de requête que celle qu'elle avait pour la famille Opus 4.x.
Ce que Sonnet 5 signifie si vous gérez une équipe de support
Voici où un modèle moins cher et plus intelligent devient vraiment intéressant, et vraiment trompeur.
Chaque fois qu'un modèle performant sort, une vague d'équipes se dit la même chose : le modèle est si bon et si peu cher maintenant, on devrait juste construire notre propre bot de support sur l'API et se passer du fournisseur. Je comprends. En tant que personne qui écrit ce genre de code, brancher un appel Sonnet 5 qui répond à une question de support est un après-midi satisfaisant.
Le piège, c'est que l'appel au modèle représente les 20 % faciles. Tout ce qui rend une IA sûre à exposer à de vrais clients se trouve sous la ligne de flottaison, et rien de tout cela n'arrive dans la réponse de l'API.

Je n'invente rien ici. J'ai vu des clients partir construire en interne directement sur l'API Claude, et le schéma est constant : la démo fonctionne en une semaine, puis la longue traîne de la récupération d'informations, du contrôle des hallucinations, du routage et de l'escalade dévore les six mois suivants. Un responsable technique qui a choisi d'acheter plutôt que de construire l'a dit clairement :
« On aurait pu essayer d'écrire notre propre application LLM, mais on ne voulait pas y investir notre temps. On voulait quelque chose qu'on n'aurait pas à maintenir. »
Karel, responsable technique chez GENERAL BYTES
Le pire scénario n'est pas qu'un modèle brut donne une mauvaise réponse. C'est qu'il donne une mauvaise réponse avec assurance. En plus de trois ans à déployer de l'IA sur des files de support en production, le pire schéma que j'ai observé est un bot qui semble sûr de lui et raconte tranquillement quelque chose de faux à un client, ou décrit un travail qu'il n'a jamais réellement effectué. C'est exactement pour cela que tout déploiement sérieux devrait être simulé sur vos tickets historiques au préalable, pour que vous voyiez les chiffres de précision et de couverture avant qu'un vrai client ne les découvre, pas après. Un benchmark de modèle vous dit que le moteur est rapide ; il ne vous dit rien sur le comportement de votre bot spécifique sur vos tickets spécifiques.
Donc, le bilan honnête sur Sonnet 5 pour le support : il rend le moteur moins cher et meilleur, ce qui est excellent, et il ne change presque rien aux 80 % difficiles. Que vous construisiez ou que vous achetiez, budgétez votre temps pour les parties que l'API ne fournit pas, le routage, les garde-fous, l'escalade vers des humains, et les tests, car c'est là que se gagne ou se perd réellement la confiance des clients.
Essayer eesel
Si la conclusion honnête est « je veux une qualité de niveau Sonnet 5 sur mes tickets sans construire les 80 % restants », c'est exactement le vide que eesel comble. Il fonctionne comme un nouveau membre de l'équipe de support qui se connecte à Zendesk, Freshdesk, Gorgias, Help Scout ou Intercom en quelques minutes et connaît déjà votre centre d'aide et vos tickets passés.
Le point le plus important au vu de tout ce qui précède : eesel vous permet de simuler sur des milliers de vos tickets historiques réels avant la mise en production, afin que vous voyiez les chiffres de résolution et de couverture en amont, au lieu de les découvrir sur un client réel. Le routage basé sur la confiance maintient l'IA sur les tickets qu'elle peut gérer et confie le reste à un humain, ce qui est le garde-fou qui transforme un modèle astucieux en un coéquipier digne de confiance. Ce n'est pas un benchmark que eesel poursuit ; c'est pourquoi des équipes comme Gridwise ont résolu 73 % des demandes de niveau 1 dès leur premier mois.

Les tarifs sont basés sur l'usage, à environ 0,40 $ par ticket traité, sans frais par poste ni minimum de plateforme, et vous pouvez essayer eesel gratuitement. Quel que soit le modèle sous-jacent, qu'il s'agisse de Sonnet 5 aujourd'hui ou de son successeur l'année prochaine, c'est le travail qui l'entoure qui résout réellement le ticket.
Questions fréquentes
Qu'est-ce que Claude Sonnet 5 ?
Combien coûte Claude Sonnet 5 ?
Claude Sonnet 5 est-il meilleur qu'Opus 4.8 ?
Puis-je construire un agent de support client avec Claude Sonnet 5 ?
Quelle est la différence entre Claude Sonnet 5 et Sonnet 4.6 ?
xhigh, passe à une vision haute résolution, et utilise un nouveau tokenizer qui compte environ 30 % de tokens en plus pour le même texte. Ce dernier point compte pour le budget, donc revérifiez votre coût réel par conversation plutôt que de réutiliser d'anciennes estimations. Plus d'informations sur le choix du modèle dans le guide meilleur chatbot IA.
Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.







