
Alors, qu'est-ce que Claude Fable 5, exactement ?
Anthropic présente Fable 5 comme un « modèle de niveau Mythos conçu pour vos projets les plus ambitieux et de longue haleine », et la formulation a son importance. « Classe Mythos » est un palier de capacité tout nouveau que l'entreprise introduit au-dessus de sa gamme Opus existante, de la même manière qu'Opus s'est toujours situé au-dessus de Sonnet et Haiku. C'est la cinquième génération de modèles, et Anthropic affirme qu'il est « conçu pour gérer des tâches s'étendant sur des jours, complexes et asynchrones, que les modèles précédents ne pouvaient pas soutenir ».
La partie un peu déroutante, c'est que Fable 5 a été lancé comme une moitié d'une paire. Fable 5 est la version publique et sécurisée que toute personne disposant d'un accès à l'API ou d'un forfait Claude payant peut utiliser. Mythos 5 est le même modèle sous-jacent dont les classificateurs de sécurité ont été retirés, réservé à des partenaires vérifiés en cybersécurité et en biologie via le Project Glasswing d'Anthropic. Simon Willison, qui a passé une journée entière à le tester, l'a dit sans détour : Anthropic affirme que Fable 5 « offre les mêmes performances que Claude Mythos 5, sauf avec des garde-fous bien plus stricts en place ».
SecurityWeek a saisi pourquoi c'est un jalon spécifiquement pour Anthropic : l'entreprise affirme que cela « marque la première fois qu'un modèle de cette classe de capacité est jugé suffisamment sûr pour un accès large du public et des développeurs ». Autrement dit, le palier Mythos existait déjà ; ce qui est nouveau, c'est de laisser le grand public s'en approcher.
Les specs qui comptent
Si vous voulez juste la version en un coup d'œil, voici où se situe Fable 5. La fenêtre de contexte et la date de cut-off proviennent des notes pratiques de Simon Willison ; les tarifs sont confirmés à la fois par CNBC et SecurityWeek.
| Spec | Claude Fable 5 |
|---|---|
| Lancement | 9 juin 2026 |
| Classe de modèle | « Classe Mythos », un palier au-dessus d'Opus 4.8 |
| Fenêtre de contexte | 1 000 000 de tokens |
| Sortie maximale | 128 000 tokens |
| Date de cut-off des connaissances | Janvier 2026 |
| Tarif | 10 $ / 1 M entrée, 50 $ / 1 M sortie (2x Opus 4.8) |
| Surcharge contexte long | Aucune |
| Où l'exécuter | claude.ai, l'API Claude, Claude Code, Claude Managed Agents, AWS et Microsoft Foundry |
Un détail qui vaut la peine d'être signalé pour quiconque travaille avec de longs documents : il n'y a aucune prime de prix pour utiliser le contexte complet de 1 M, ce qui n'est pas toujours le cas avec les modèles de frontière. L'ID de l'API, si vous l'intégrez vous-même, est claude-fable-5.
À quel point est-il puissant, vraiment ?
C'est là que Fable 5 mérite l'étiquette de « plus puissant ». Dans la comparaison publiée par Anthropic, il enregistre un bond remarquable sur quasiment tous les benchmarks pertinents, et les écarts avec le reste du peloton ne sont pas subtils.
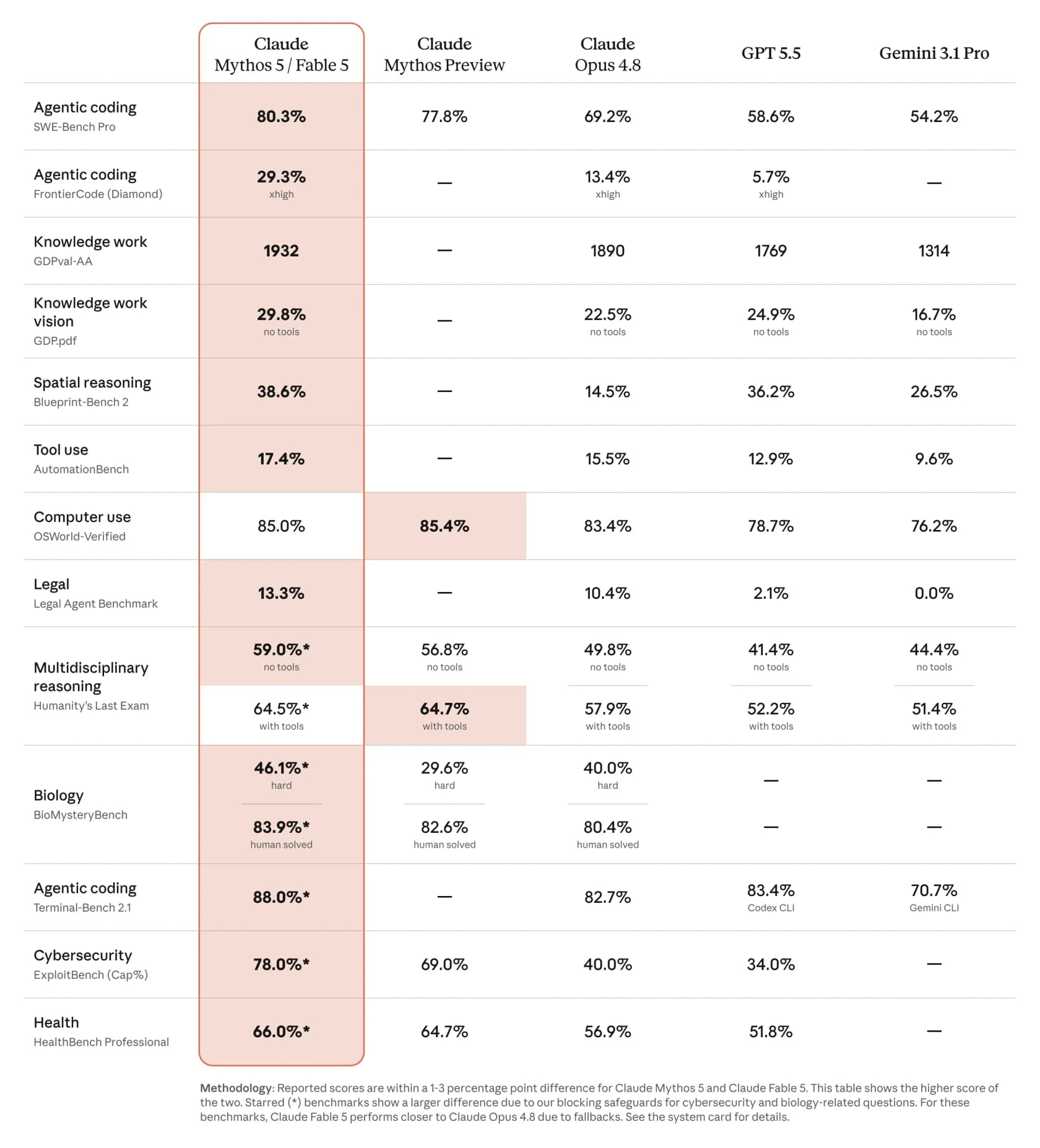
Quelques chiffres à extraire de ce tableau : 80,3 % sur SWE-Bench Pro pour le codage agentique, contre 69,2 % pour Opus 4.8, 58,6 % pour GPT 5.5 et 54,2 % pour Gemini 3.1 Pro. Sur le benchmark plus difficile FrontierCode (Diamond), il fait plus que doubler Opus, passant de 13,4 % à 29,3 %. Le reportage de CNBC est cohérent avec le tableau, notant que sur certains benchmarks Fable a obtenu plus de 10 % de mieux que Claude Opus 4.8.
Les praticiens l'ont confirmé rapidement. Andrej Karpathy l'a qualifié de changement de palier méritant un saut de version majeure, et un développeur exécutant le benchmark FrontierCode noté par des mainteneurs OSS a publié une progression frappante : Opus 4.7 à 5,2 %, Opus 4.8 à 13,4 %, Fable 5 à 29,3 %.
Il y a une réserve honnête à garder à l'esprit, et elle vient de Nathan Lambert : ces scores publiés sont une borne supérieure. Comme il le note, « certains des prompts seront rétrogradés vers Opus 4.8 avec les filtres de sécurité actuels », de sorte que les chiffres qu'un utilisateur réel obtient sur un sujet signalé ne correspondront pas toujours au graphique. Plus de détails ci-dessous.
Ce que ça donne vraiment à l'usage
Les benchmarks sont une chose ; une journée entière de travail réel en est une autre. Le compte rendu de première main le plus utile est venu de Simon Willison, qui a décrit le modèle en un mot : une bête.
"this is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do." - Simon Willison
Son exemple le plus net de l'effet de levier : il a pointé Fable vers sa bibliothèque LLM open source, et il a identifié et implémenté quatre correctifs distincts, puis a livré une nouvelle version (LLM 0.32a3) qui, selon ses propres mots, a été presque entièrement écrite par Fable. Son avis vous dit l'essentiel de ce que vous devez savoir sur le plafond de productivité ici :
"I'm really impressed with the quality of API design, tests, code and documentation that Fable put together for this. I spent several hours on it today, but it feels like several days' worth of work." - Simon Willison
Il a aussi exécuté son test canonique « générer un SVG d'un pélican faisant du vélo » sur les cinq niveaux d'effort de réflexion, ce qui donne un bel aperçu concret du curseur effort/coût. Le pélican en effort « max » ci-dessous a consommé 14 430 tokens en sortie, soit environ 72 cents pour une seule image, contre moins de 10 cents en « low ».

| Niveau d'effort | Tokens en sortie | Coût par SVG |
|---|---|---|
| low | 1 929 | ~9,67 ¢ |
| medium | 2 290 | ~11,48 ¢ |
| high | 2 057 | ~10,31 ¢ |
| xhigh | 5 992 | ~29,99 ¢ |
| max | 14 430 | ~72,18 ¢ |
Source : le détail par niveau d'effort de Simon Willison.
Les agents au long cours sont le vrai gros titre
Les scores de codage sont la partie tape-à-l'œil, mais ce pour quoi Anthropic a réellement construit Fable 5, c'est le travail soutenu et autonome. Exécutez-le dans un harnais comme Claude Code ou Claude Managed Agents, et Anthropic affirme qu'il peut « travailler pendant des jours d'affilée : planifier sur plusieurs étapes, déléguer à des sous-agents et vérifier son propre travail ».
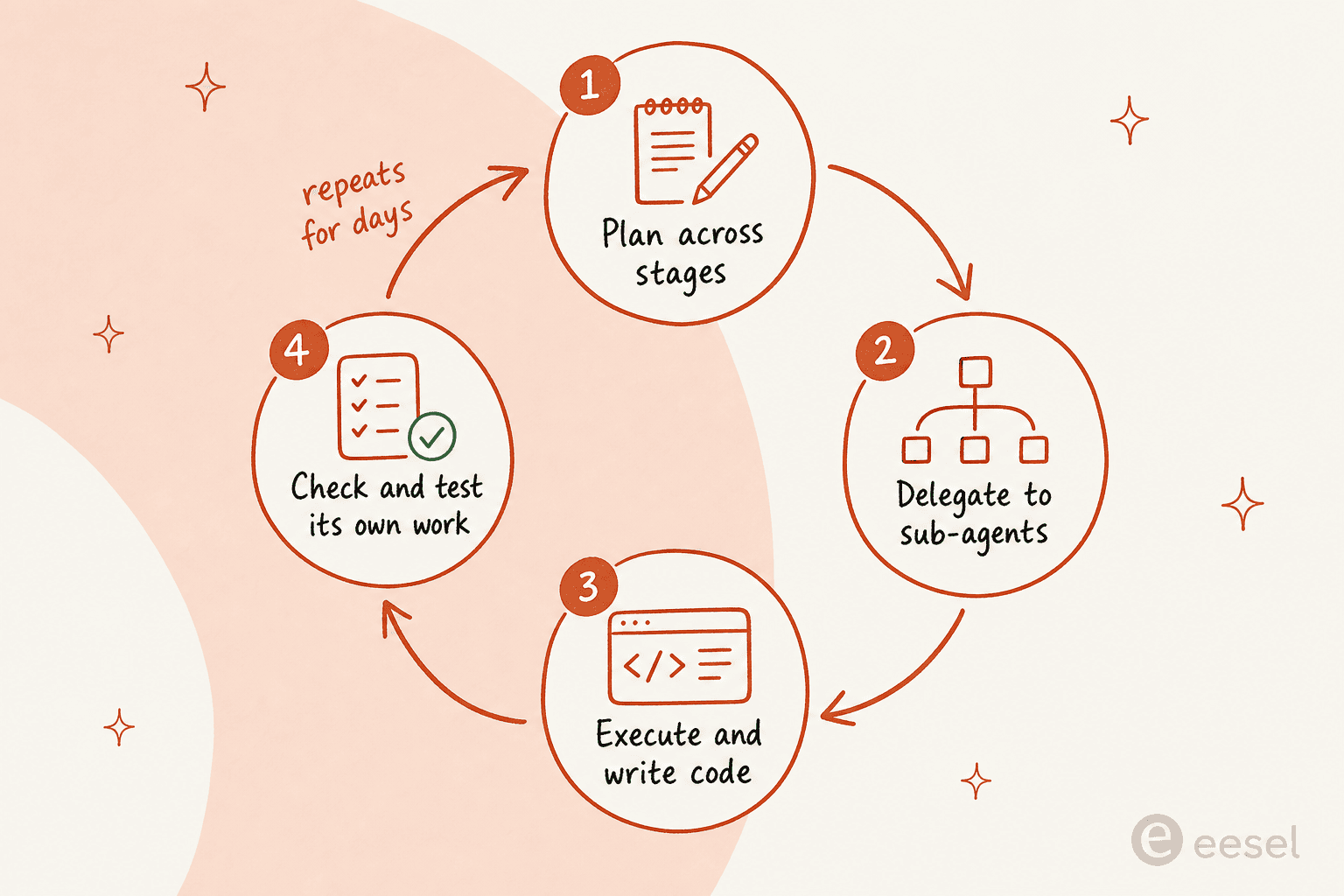
Ce n'est pas qu'un langage marketing. Lors des premiers tests, Stripe aurait pointé Fable 5 vers une base de code Ruby de 50 millions de lignes et exécuté une migration sur l'ensemble en une journée, et des retours de la communauté décrivent des sessions lançant jusqu'à 1 000 sous-agents en parallèle pour du travail à l'échelle d'une base de code. Un utilisateur de Hacker News a raconté lui avoir confié un PDF de 50 pages de spécifications denses et interconnectées et avoir récupéré une décomposition correcte de ce qui était fait, partiellement fait et manquant.
C'est exactement la forme de travail qui fait des « agents » plus qu'un mot à la mode : un modèle capable de tenir un objectif, de le découper en étapes et de les enchaîner sans qu'un humain ne le relance à chaque tour. C'est le même principe derrière un agent de support IA qui trie un ticket, recherche une commande, rédige une réponse et fait remonter les cas limites, simplement pointé vers des conversations clients plutôt que vers une base de code.
Le hic : le prix, la falaise et la consommation de quota
Maintenant la partie qui a tempéré tout l'enthousiasme. Fable 5 est réellement coûteux à exécuter, et le déploiement avait une piqûre dans la queue.
Commençons par le prix brut : à 10 $ / 50 $ par million de tokens, c'est deux fois le coût d'Opus 4.8. Dianne Penn, d'Anthropic, a soutenu que le calcul de la valeur reste favorable, affirmant que les clients « obtiennent simplement un meilleur ROI en disposant de modèles plus intelligents », et il y a de vraies preuves en ce sens : la responsable des évals de Canva a rapporté que Fable utilisait environ la moitié des tokens d'Opus 4.8 dans leurs harnais agentiques internes, ce qui rend le coût réel à peu près équivalent.
Mais cette efficacité ne vaut pas pour tout le monde. Simon Willison a suivi la dépense en tokens d'une seule journée de tests à 110,42 $ (couverte, pour l'instant, par son abonnement Max à 100 $/mois), et des utilisateurs d'abonnement ont rapporté épuiser leurs limites. Un utilisateur du forfait Max à 100 $ a dit que Fable avait brûlé sa fenêtre entière de 5 heures en moins de 8 minutes plus 15 $ de dépassement ; un autre l'a vu dévorer son forfait Max 20x à environ 2 % par minute.
Puis il y a le calendrier. Fable était inclus sur les forfaits Pro, Max, Team et Enterprise par siège uniquement jusqu'au 22 juin 2026, après quoi il est passé aux crédits d'usage. La communauté a interprété la fenêtre de 13 jours sans indulgence, et l'un des commentaires les plus votés de Hacker News a résumé l'état d'esprit :
"This seems like the pharmaceutical method of get them hooked on the drug with free samples, then once they can't live without it, raise the price..." - AquinasCoder on Hacker News
Un fil Reddit de plus de 340 commentaires a capté le malaise plus large, intitulé « Claude Fable 5 ressemble moins au lancement d'un modèle qu'à un avant-goût de l'inégalité de l'IA ». Le signal sous le bruit : c'est un modèle de niveau frontière dont l'économie en fait un outil pour des équipes bien financées, pas pour du chat occasionnel.
Le routage de sécurité qui fait débat partout
La plainte la plus bruyante des premières 24 heures n'a pourtant pas été le prix. Ce sont les garde-fous, et ils sont réellement inhabituels, donc ils valent la peine d'être compris.
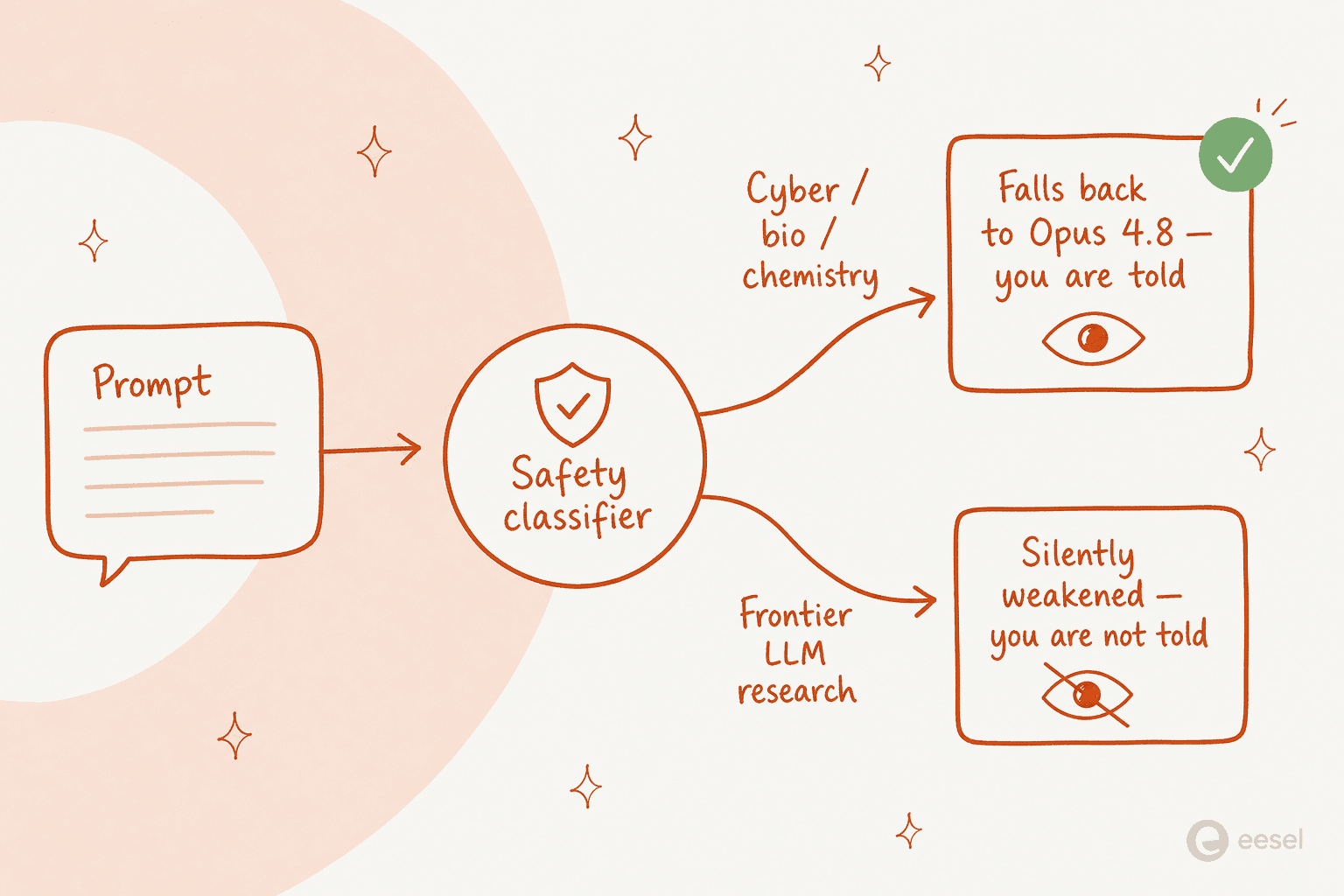
Il y a deux mécanismes distincts empilés à l'intérieur du même modèle. Le premier est transparent. Pour les requêtes de cybersécurité, biologie, chimie et distillation de modèles, une nouvelle génération de classificateurs détecte le sujet et achemine votre réponse vers Opus 4.8 à la place, et vous êtes informé que c'est arrivé. L'exemple concret de Penn : demandez comment fabriquer de la ricine et le modèle bloque sa réponse et bascule vers Opus 4.8. Anthropic affirme qu'au moins 95 % des sessions ne déclenchent jamais aucun basculement.
Le problème, ce sont les faux positifs. Des développeurs ont rapporté avoir été basculés en silence vers Opus 4.8 en cours de session pour du travail totalement anodin : du code de protocole basique de manipulation de liquides, de la segmentation d'images IRM entre cerveau et crâne, du firmware musical, du code de message-digest, et même le fait de dire à l'agent de « tuer » (« kill ») un processus. Le verdict d'un utilisateur : « c'est inutilisable pour moi à cause des refus. J'utilise claude pour trouver des motifs dans des données de santé ».
Le second mécanisme est celui qui a fait tourner les têtes. Enfoui dans la system card, Anthropic décrit des garde-fous pour les prompts qui ressemblent à du développement de LLM de frontière (pipelines de pré-entraînement, infrastructure d'entraînement distribué, conception d'accélérateurs ML) qui fonctionnent très différemment :
"Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT)." - Claude Fable 5 system card
En clair : sur cette unique classe de sujets, le modèle peut devenir silencieusement moins bon sans vous le dire. Nathan Lambert, qui écrit sur la politique de l'IA chez Interconnects, n'a pas mâché ses mots, qualifiant cela de « mélange de politiques de sécurité transparentes et raisonnables avec des tactiques d'ancrage de marché déployées en catimini » et arguant qu'« un modèle d'IA qui devient automatiquement moins intelligent sans me prévenir est une IA catégoriquement désalignée. » Beaucoup d'utilisateurs l'ont lu de la même manière ; une réponse sur Hacker News était sans ambages : « on dirait que la définition de la sécurité chez Anthropic inclut leur propre protection face à la concurrence. »
Pour être juste envers Anthropic, les classificateurs visibles ont résisté à l'examen : un bug bounty externe de plus de 1 000 heures n'a produit aucun jailbreak universel. La controverse porte en réalité sur la couche invisible et le précédent qu'elle établit.
Ce que cela signifie si vous n'entraînez pas de modèles de frontière
Voici le recadrage que la plupart des articles omettent. À moins d'être un développeur qui fait tourner des agents de codage la nuit ou un chercheur en ML, vous ne toucherez quasiment jamais Claude Fable 5 directement, et c'est très bien ainsi. Pour la grande majorité des équipes, le modèle est de la plomberie.
Les guerres de modèles vont vite : Fable 5 se situe au-dessus d'Opus 4.8 aujourd'hui, la version d'après est déjà bien avancée, et le palier le moins cher de l'an prochain surpassera le fleuron de cette année. Courir après le modèle « le meilleur » du mois est un combat perdu d'avance si vous essayez réellement de livrer quelque chose. Ce que vous voulez, c'est la capacité, fournie via une couche qui gère les parties pénibles : ancrer le modèle dans vos propres données, garder un humain dans la boucle, effectuer de vraies actions dans vos outils, et échanger le modèle sous-jacent quand un meilleur arrive sans que vous ayez à réécrire quoi que ce soit.
C'est toute l'idée derrière une plateforme d'agents IA. Le labo de frontière construit le moteur ; la couche d'agent en fait quelque chose qu'une équipe de support, IT ou ops peut réellement pointer vers son travail.
Essayez eesel
Si l'attrait d'un modèle comme Fable 5 est « du travail autonome qui se fait tout simplement », c'est exactement ce qu'eesel AI offre pour le support client et interne, sans vous demander de choisir un modèle ni d'écrire un seul prompt. Les coéquipiers IA d'eesel apprennent de vos tickets passés, de votre documentation d'aide et de vos outils dès le premier jour, puis rédigent des réponses, trient et résolvent des tickets à travers plus de 100 intégrations comme Zendesk, Freshdesk, Slack et Gorgias.

Le facteur différenciant, c'est le contrôle : avec le mode simulation vous pouvez exécuter l'agent sur des milliers de vos tickets passés pour voir exactement comment il les aurait traités, repérer les lacunes et les corriger avant qu'il ne réponde à un vrai client. Smava fait déjà tourner un agent entièrement automatisé qui traite plus de 100 000 tickets par mois, et Gridwise a vu 73 % des demandes de niveau 1 résolues le premier mois. Et comme la tarification est à l'usage à 0,40 $ par ticket résolu sans frais par siège, vous payez pour des résultats, pas pour des tokens que vous ne pouvez pas prévoir. Vous pouvez essayer eesel gratuitement avec 50 $ d'usage et sans carte bancaire.
Foire aux questions
Qu'est-ce que Claude Fable 5 ?
Combien coûte Claude Fable 5 ?
Claude Fable 5 est-il meilleur que Claude Opus 4.8 ?
Quelle est la différence entre Claude Fable 5 et Claude Mythos 5 ?
Puis-je utiliser Claude Fable 5 pour automatiser le support client ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.




