Zusammenfassung
Ja, du kannst Ticket-Tagging mit KI automatisieren, und es ist eines der wirkungsvollsten Dinge, die eine KI in deinem Helpdesk tun kann, weil es alles Nachgelagerte berührt: Routing, Reporting, SLAs und welche Tickets deine besten Agents überhaupt zu sehen bekommen. Der Mechanismus ist einfach. Die KI liest jedes eingehende Ticket, erkennt Intent, Sprache und Stimmung, gleicht das mit deiner Tag-Liste ab und vergibt das Tag (oder leitet das Ticket weiter), bevor ein Mensch es öffnet.
Der Haken ist fast nie die KI. Es ist deine Tag-Liste. Gibst du einem Modell eine ausufernde, überlappende Taxonomie, wird es inkonsistent taggen – genauso wie ein neuer Mitarbeiter es täte. Die eigentliche Arbeit lautet also: Tags bereinigen, die KI auf deinen vergangenen Tickets trainieren, sie gegen deine eigene Historie testen und die automatische Vergabe erst aktivieren, wenn die Genauigkeit stimmt.
Dein Helpdesk hat wahrscheinlich eine native Option (Zendesk Intelligent Triage, Freshdesk Auto Triage, Gorgias Rules), und sie sind solide, aber die meisten sind hinter einem Per-Agent-Add-on und einem bestimmten Plan versteckt. Wenn du lieber das Tagging auf deinen eigenen gelösten Tickets trainieren und simulieren möchtest, bevor es live geht, macht genau das ein KI-Layer wie eesel – auf dem Helpdesk, den du bereits betreibst.
Was "Tickets mit KI taggen" wirklich bedeutet
Ich betreue eesel's Support-Warteschlange, also bin ich ehrlich darüber, wo der Mehrwert liegt. Tags sind langweilig. Niemand ist in den Kundensupport gegangen, weil er vierzig Mal täglich "Abrechnung" aus einer Dropdown-Liste auswählen wollte. Aber Tags sind auch das Rückgrat eines organisierten Helpdesks: Sie entscheiden, welches Team ein Ticket erhält, welche Ticket-Routing-Regel ausgelöst wird, was dein Wochenbericht als Trend ausweist und ob deine SLA-Uhr mit der richtigen Priorität startet.
Das zu automatisieren bedeutet, den Lese-und-Beschriftungs-Schritt an eine KI zu übergeben. Im Kern machen fast alle Tools dasselbe: Sie lesen die Nachricht, klassifizieren sie (Intent, Sprache, Stimmung, manchmal Named Entities wie eine Bestellnummer), gleichen diese Klassifizierung mit einem Tag in deiner Liste ab und wenden es an. Die guten füllen in demselben Durchgang auch Ticket-Felder aus und leiten das Ticket weiter.
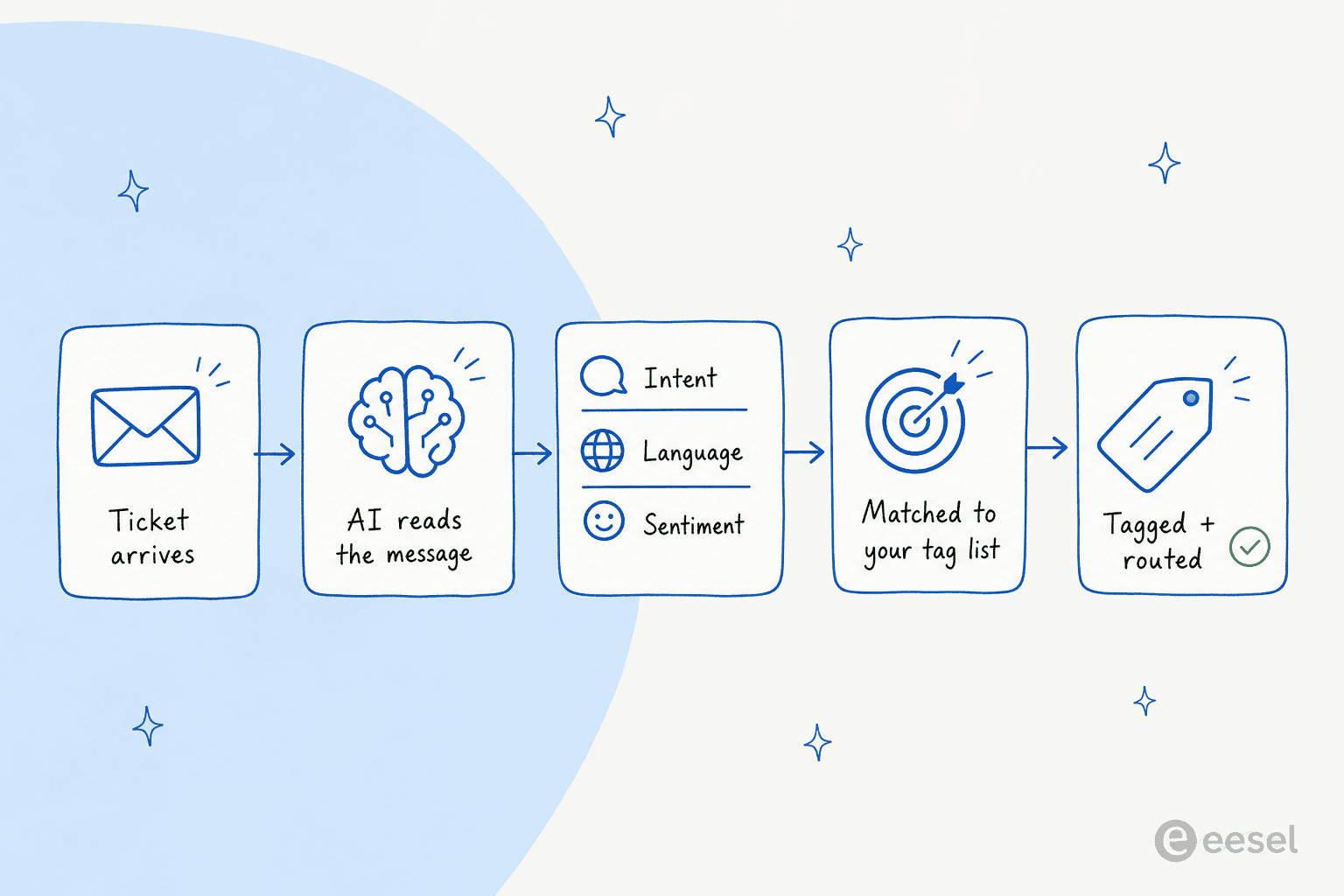
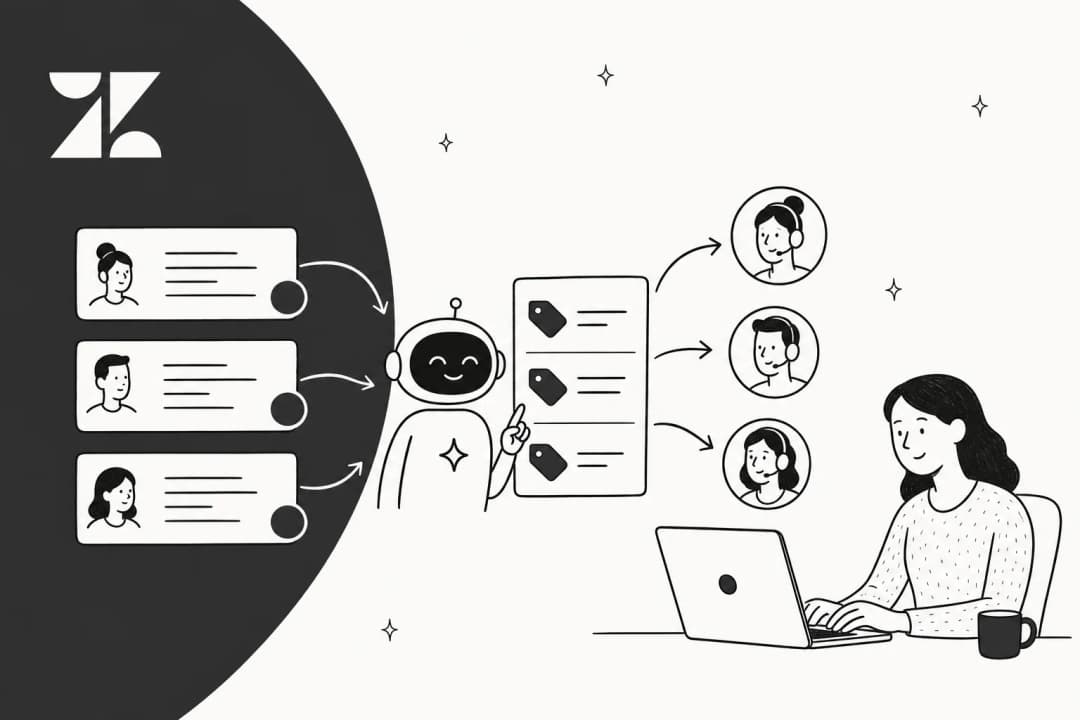
Was mich am meisten überraschte, als ich es auf echten Tickets laufen sah, ist, wie viel Kontext es aufnimmt. Bei uns kam eine kalte Verkaufsnachricht als Ticket herein (jemand wollte uns eine Kontaktliste verkaufen), und statt zu scheitern, verglich die KI sie mit vergangenen Tickets, erkannte sie als Spam, vergab das Tag und hinterließ eine freundliche Absage als interne Notiz. Das ist der Unterschied zwischen KI-Ticket-Klassifizierung, die nur Keywords abgleicht, und einer, die wirklich versteht, worum es in dem Ticket geht.
Warum manuelles Tagging stillschweigend zusammenbricht
Wenn dein Tagging noch manuell ist, passiert gerade Folgendes – und du hast wahrscheinlich alle drei Punkte schon gespürt.
Agents überspringen es. Wenn die Warteschlange voll ist, ist Tagging das Erste, das wegfällt. Also enden die Hälfte deiner Tickets ungetaggt oder landen in einem Sammel-Tag "Allgemein". Dann lügen dir deine Reports, weil die Daten von Anfang an nicht sauber waren.
Jeder taggt anders. Ein Agent benutzt "Erstattung", ein anderer "Rückerstattung", ein dritter "Rückgabe-Erstattung". Jetzt hast du drei Tags für ein Konzept und keine zuverlässige Möglichkeit zu zählen, wie viele Erstattungstickets du wirklich bekommen hast. Das ist der häufigste Grund, warum Support-Ticket-Analyse-Projekte ins Stocken geraten.
Und es skaliert nicht. Ein Team, das ein paar Hundert Tickets pro Woche bearbeitet, kommt irgendwie durch. Ein Team, das Hochvolumen-Tickets bearbeitet, nicht, und genau dort sind konsistente Tags am wichtigsten, weil dort Routing und SLAs die schwere Arbeit erledigen.
Schlechte Tags sind schlimmer als keine Tags, weil sie wie ein Signal wirken. Ein Dashboard, das auf inkonsistentem Tagging basiert, liefert dir selbstbewusst falsche Zahlen, und du triffst Personalentscheidungen auf deren Basis.
Ticket-Tagging mit KI automatisieren – Schritt für Schritt
Hier ist der Rollout, den ich tatsächlich durchführen würde, in dieser Reihenfolge. Er ist in der Mitte bewusst vorsichtig, weil der Fehlerfall nicht "die KI kann nicht taggen" ist, sondern "die KI hat 10.000 Tickets falsch getaggt, bevor jemand nachgeschaut hat".
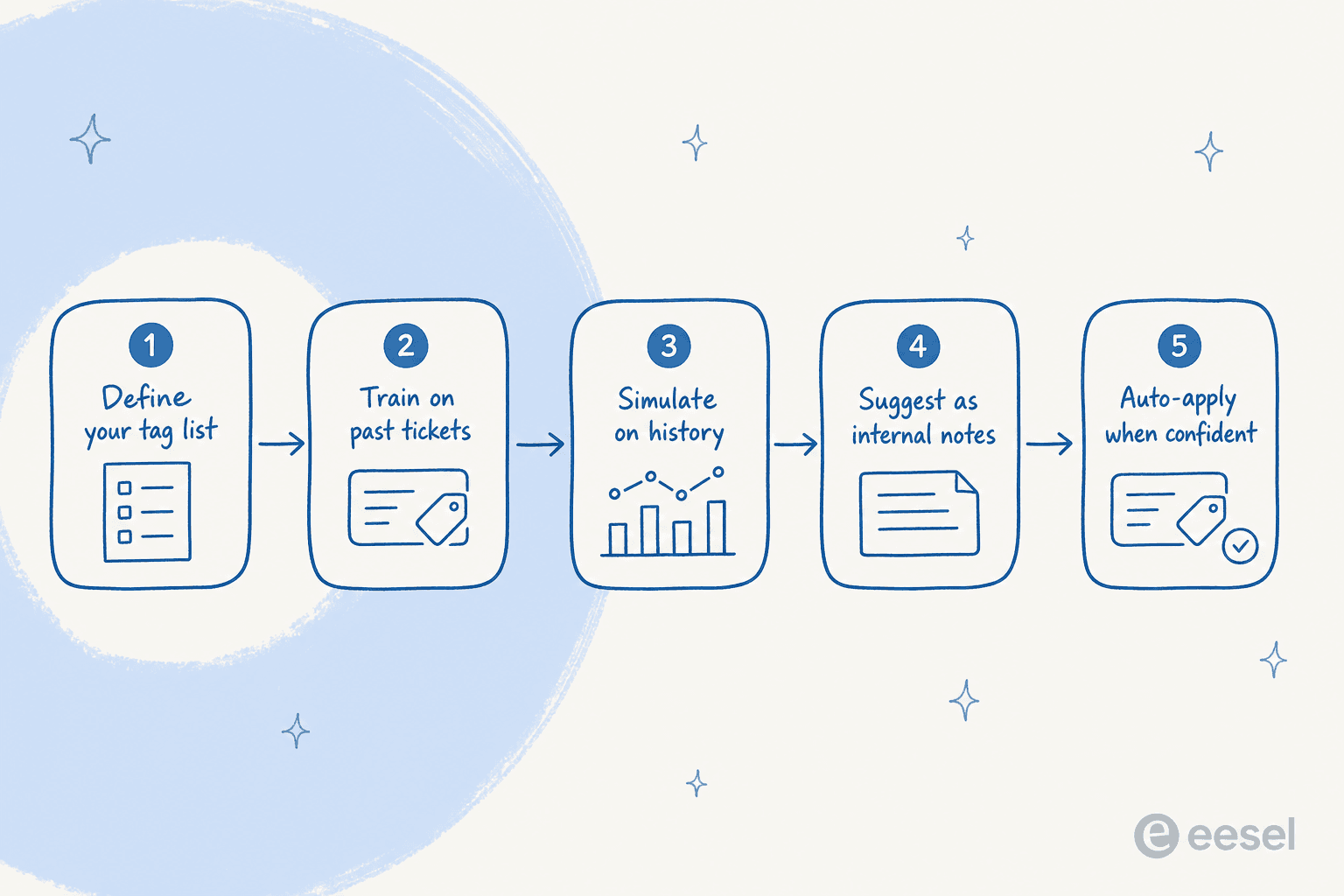
1. Zuerst deine Tag-Liste prüfen und bereinigen
Das ist der Schritt, den alle überspringen wollen, und er entscheidet, ob das Ganze funktioniert. Ruf deine aktuelle Tag-Liste ab und sei rücksichtslos: Führe Duplikate zusammen ("Erstattung" und "Rückerstattung"), entferne Tags, auf die niemand routet oder die niemand in Reports verwendet, und strebe nach einer kleinen Menge klar abgegrenzter, nicht überlappender Kategorien. Die KI kann nur so konsistent sein wie die Liste, die du ihr gibst.
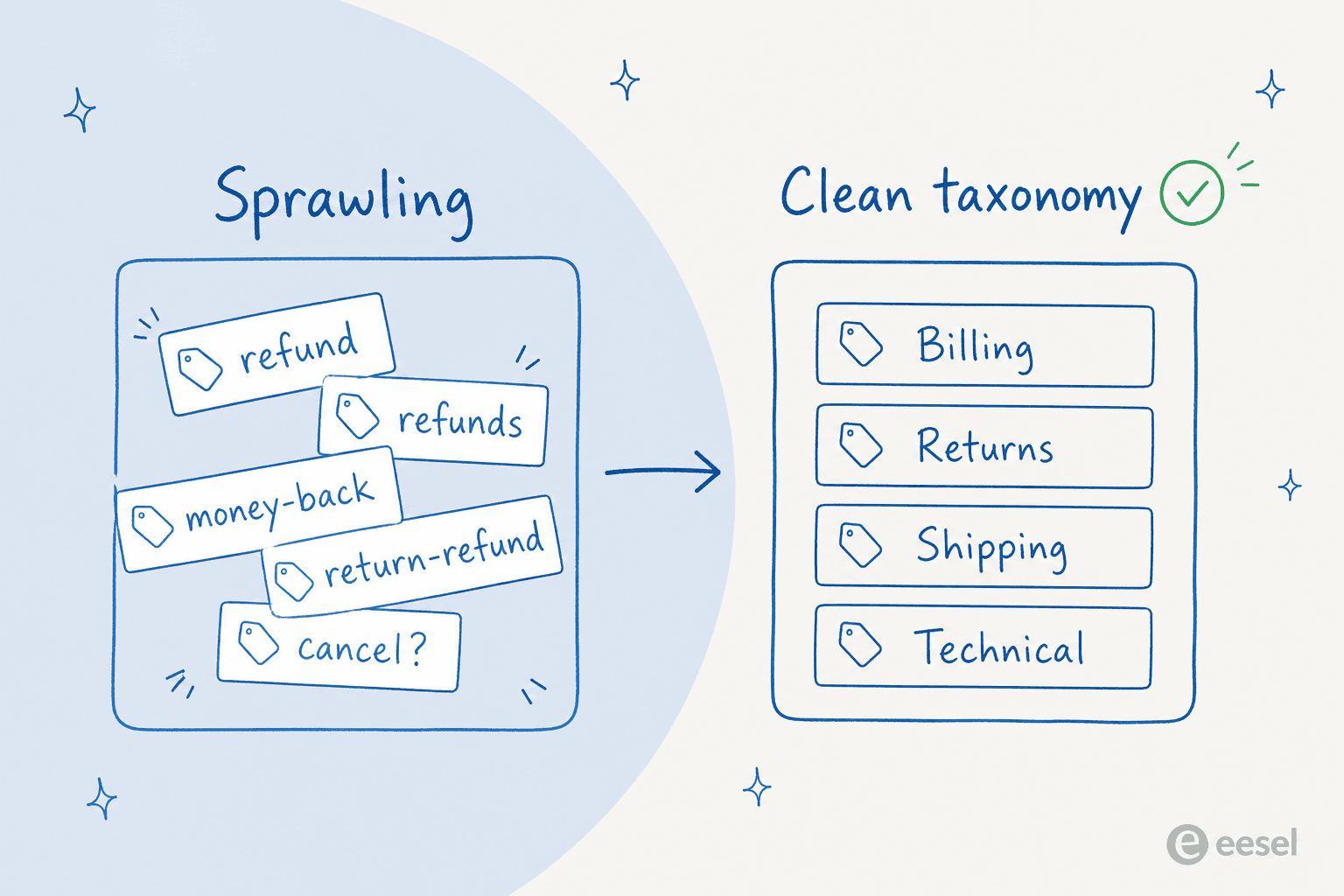
Ein guter Test: Wenn zwei Menschen in deinem Team sich über das Tag eines Tickets uneinig wären, wird die KI das auch sein. Behebe die Mehrdeutigkeit auf der Taxonomie-Ebene, nicht mit einem cleveren Prompt. Unser Leitfaden zum Arbeiten mit Ticket-Tags enthält eine ausführlichere Checkliste, falls du eine brauchst.
2. Die KI auf deinen vergangenen Tickets trainieren
Generische Modelle taggen generisch. Der Unterschied zwischen einem Modell, das wie dein bester Agent taggt, und einem, das rät, liegt darin, ob es aus deinen tatsächlich gelösten Tickets gelernt hat. Deine historischen Tickets sind die Trainingsdaten – sie enthalten bereits das richtige Tag, die tatsächlichen Formulierungen deiner Kunden und die Grenzfälle.
Hier setzen auch einige native Tools eine Untergrenze: Freshdeks Auto-Triage beispielsweise benötigt rund 2.000 historische Tickets, bevor es Felder zuverlässig vorhersagt. Wenn du eine schlankere Warteschlange betreibst, tendiere zu einem Tool, das auch aus deinen Hilfedokumenten und Makros lernen kann, nicht nur aus dem Ticket-Volumen.
3. Simulieren, bevor du ein Live-Ticket anfasst
Das ist der Schritt, den ich nie überspringen würde. Bevor irgendetwas live geht, lass das Modell über einen Stapel deiner historischen Tickets laufen und vergleiche seine Tags mit denen, die dein Team vergeben hat. Du suchst nach zwei Zahlen: wie oft es mit deinem Team übereinstimmt und wo es selbstbewusst widerspricht (das sind deine Taxonomie-Probleme, die sich zeigen).
Eine Simulation gegen vergangene Tickets verwandelt "wir denken, es ist genau" in "es stimmte bei 91 % der Abrechnungstickets des letzten Quartals mit uns überein". Das ist die Zahl, die du deinem Manager präsentierst, bevor du den Schalter umlegt.
4. Im Vorschlagsmodus starten, nicht mit automatischer Anwendung
Lass die KI zunächst als Copilot laufen: Sie schlägt ein Tag vor, hinterlässt eine interne Notiz oder befüllt das Feld vor, und ein Mensch bestätigt. Das schafft Vertrauen und fängt die seltsamen Fälle auf, während noch eine Person in der Schleife ist. Wie es ein CX-Lead formulierte, mit dem ich gesprochen habe: Das Ziel ist eine KI, die nur das übernimmt, wobei sie sich sicher ist, und den Rest in Ruhe lässt. Dieser Instinkt ist richtig, und er ist der ganze Grund, warum Konfidenz-Schwellenwerte existieren.
5. Automatische Anwendung für sichere Fälle aktivieren und Reports beobachten
Sobald der Vorschlagsmodus konsistent mit deinem Team übereinstimmt, lass die KI Tags oberhalb eines Konfidenz-Schwellenwerts automatisch vergeben und behalte die wenig konfidenten als Vorschläge. Beobachte dann deine Tag-Verteilung in den Reports in den ersten Wochen. Wenn ein Tag plötzlich ansteigt, ist das entweder ein echter Trend oder ein Tagging-Fehler – und in beiden Fällen willst du es wissen. Saubere Tags machen deine Kundenservice-Metriken wieder vertrauenswürdig.
Deine Optionen nach Helpdesk
Die meisten Helpdesks haben jetzt irgendeine Form von nativem KI-Tagging. Hier ist ein ehrlicher Überblick, mit dem jeweiligen Haken, damit du entscheiden kannst, ob native Funktionen ausreichen oder ob du einen dedizierten Layer darüber möchtest.
| Tool | Was es taggt | Benötigter Plan | Startpreis | Der Haken |
|---|---|---|---|---|
| Zendesk Intelligent Triage | Thema, Stimmung (5-Punkte-Skala), Sprache (~150), Entitäten in benutzerdefinierte Felder | Suite/Support Professional + Copilot-Add-on | 50 $/Agent/Monat (jährlich) | Triage-Werte sind beim Erstellen von Triggern, Ansichten und Reports nur auf Englisch verfügbar |
| Freshdesk Auto Triage | Priorität, Gruppe, Typ, benutzerdefinierte Felder, Intent, Stimmung (0–100) | Pro/Enterprise + Freddy AI Copilot | ~84 $/Agent/Monat insgesamt | Benötigt ~2.000 Tickets zum Trainieren; nur E-Mail und Portal; bestehende Regeln überschreiben die KI |
| Gorgias Intents + Rules | Intent-Taxonomie, Stimmung, dann vergeben eine Regel das Tag | Alle Helpdesk-Pläne (granulare Intents benötigen AI Agent) | Ab 10 $/Monat | 70-Regel-Obergrenze; Stimmungen können nicht manuell bearbeitet werden |
| eesel (Layer on top) | Intent, Sprache, Stimmung, benutzerdefinierte Tags aus deiner Liste, Feldausfüllung, Routing | Funktioniert auf deinem bestehenden Helpdesk | 0,40 $ pro Ticket, keine Sitzgebühr | Ergänzt deinen Helpdesk, ersetzt dessen native KI nicht |
Zendesk
Zendesks Intelligent Triage klassifiziert automatisch jedes eingehende Ticket nach Thema, Stimmung auf einer 5-Punkte-Skala und Sprache in rund 150 erkannten Sprachen, plus vom Admin definierte Entitäten, die benutzerdefinierte Felder über Extraktionsregeln automatisch ausfüllen. Seit Mitte 2026 wurde das Feld "Intent" in "Topic" umbenannt, wobei die alten Intent-Felder weiterhin ihre zugehörigen Tags generieren.
Zwei wichtige Punkte: Es erfordert das Copilot-Add-on (früher "Advanced AI"), das 50 $/Agent/Monat bei jährlicher Abrechnung auf Suite oder Support Professional und höher kostet, und die Triage-Werte werden beim Erstellen von Triggern, Ansichten oder Reports nur auf Englisch angezeigt, auch wenn es ~150 Sprachen klassifiziert. Wenn du außerdem Antworten mit KI in Zendesk entwerfen möchtest, ist das eine separate Funktion, die auf denselben Tickets aufbaut.
Freshdesk
Freshdeks Auto Triage ist eine Freddy AI Copilot-Funktion, die Priorität, Gruppe, Typ, benutzerdefinierte Dropdowns und verschachtelte Felder vorhersagt, indem sie Betreff und Beschreibung des Tickets sowie Intent und Stimmung liest. Du kannst es im manuellen Modus (es schlägt vor) oder automatischen Modus (es wendet beim Erstellen an) betreiben, und eine separate Stimmungsfunktion bewertet Tickets auf einer Skala von 0 bis 100.
Die Einschränkungen summieren sich. Es ist hinter einem Pro- oder Enterprise-Plan plus dem kostenpflichtigen Freddy AI Copilot-Add-on verborgen, was den realistischen Freddy-Pricing-Mindestpreis auf etwa 84 $/Agent/Monat treibt. Es benötigt rund 2.000 historische Tickets zum Trainieren, wird nur bei E-Mail- und Portal-Kanälen ausgelöst, kann bis zu zwei Tage dauern, um pro Feld aktiviert zu werden, und deine bestehenden Automatisierungsregeln überschreiben immer die Vorschläge der KI. Nichts davon ist ein Ausschlusskriterium, aber es ist viel zum Planen. Wenn du die breitere Konfiguration optimierst, deckt unser Leitfaden zu Freshdesk automatisieren den Rest ab.
Gorgias
Gorgias macht es in zwei Hälften. Seine KI klassifiziert jede eingehende Nachricht anhand einer festen Intent-Taxonomie plus einer Stimmung (Positiv, Negativ, Neutral und einem neueren "Promoter"), und dann liest eine deterministische WENN/WENN/DANN-Regel diese Nachrichten-Intents und -Stimmungen und vergibt das eigentliche Tag. Die grundlegende Intent- und Stimmungserkennung plus der Regel-Builder sind in allen Helpdesk-Plänen ab 10 $/Monat verfügbar, mit einer vorgefertigten Vorlage "Intents und Stimmungen identifizieren" zum schnellen Einstieg.
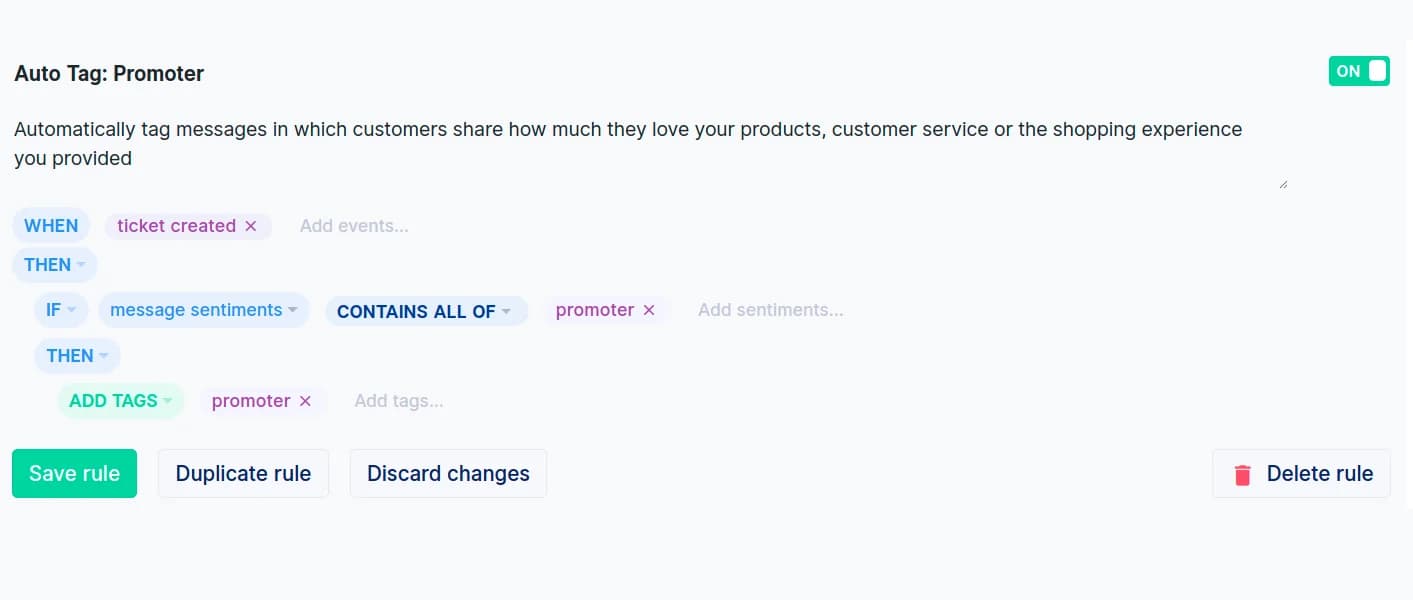
Die reichhaltigere, granulare Intent-Taxonomie und die Intents-Analytics-Seite erfordern ein separates AI Agent-Abonnement. Beachte die Einschränkungen: Es gibt eine Obergrenze von 70 Regeln, eine feste Ausführungsreihenfolge nach Trigger-Priorität und Stimmungen können nicht manuell bearbeitet werden – wenn die KI ein Ticket als "Neutral" einstuft, kannst du das nicht manuell überschreiben. Gorgias' Autoresponder-Regeln folgen demselben Builder, wenn du auf diese Tags reagieren möchtest.
Das Argument für einen dedizierten KI-Layer
Wann also reicht das Native nicht aus? Meiner Erfahrung nach läuft es auf drei Dinge hinaus: Du nutzt einen Helpdesk, dessen native KI dünn ist, du willst kein Per-Agent-Add-on bezahlen oder du möchtest überall auf dieselbe Weise taggen, auch über mehrere Tools hinweg. Das ist die Lücke, die ein dedizierter Layer füllt, und es lohnt sich, den Trade-off klar zu benennen.
Das stärkste Argument für einen Layer ist, dass er auf deinen gelösten Tickets trainiert und dir erlaubt, vor dem Live-Gang zu simulieren. Ein dänisches B2B-Fahrzeugtelematik-Team, mit dem ich gearbeitet habe und das in deutsche, spanische und italienische Märkte expandierte, wollte genau das: automatisches Tagging aus seiner eigenen definierten Tag-Liste, automatisches Ausfüllen von Feldern, Eskalations-Workflows und Tickets, die für Agents ins Englische übersetzt werden, mit Antworten, die in der Sprache des Kunden zurückgesendet werden – alles auf Zendesk aufgebaut. Native Triage erledigt den ersten Teil; den Rest erledigt ein Layer.
Das ehrliche Gegenargument: Ein Layer ist ein weiteres Tool im Stack, und wenn das native Tagging deines Helpdesks bereits deinen Bedarf deckt und du sowieso dafür bezahlst, ist ein weiteres System übertrieben. Nutze die obige Tabelle. Wenn du nur Themen- und Stimmungs-Tags brauchst und bereits den richtigen Zendesk-Plan hast, ist nativ wahrscheinlich ausreichend.
Häufige Fehler, die ich vermeiden würde
Ein paar Fallen, in die Teams tappen, in grober Reihenfolge des verursachten Schadens:
- Eine unordentliche Taxonomie automatisieren. Oben bereits besprochen, aber es lohnt sich zu wiederholen: Bereinige die Tag-Liste, bevor du automatisierst, nicht danach. Automatisierung verstärkt jede Konsistenz (oder jedes Chaos), mit der du startest.
- Direkt zur automatischen Anwendung wechseln. Den Vorschlagsmodus zu überspringen bedeutet, dass dein erstes Anzeichen für ein Tagging-Problem ein falsches Dashboard drei Wochen später ist. Verdiene dir die automatische Anwendung.
- Kein Konfidenz-Schwellenwert. Eine KI, die gezwungen wird, jedes Ticket zu taggen, auch die mehrdeutigen, wird raten. Lass sie die wirklich unklaren Tickets für einen Menschen belassen, und du wirst Falschmeldungen deutlich reduzieren.
- Einrichten und vergessen. Deine Produkte, Aktionen und die Sprache deiner Kunden verändern sich. Überprüfe deine Tag-Verteilung monatlich und speise Korrekturen zurück, damit das Modell weiterlernt. Tools, die von deinen Korrekturen lernen, werden besser; die es nicht tun, nicht.
Mache das richtig, und Tagging hört auf, eine lästige Pflicht zu sein, die dein Team hasst, und wird zur stillen Schicht, die Ticket-Triage und Ticket-Automatisierung wirklich funktionieren lässt.
eesel für Ticket-Tagging ausprobieren
Wenn du KI-Tagging willst, das auf deinen eigenen gelösten Tickets trainiert und das du testen kannst, bevor es ein Live-Ticket berührt, ist das genau das, wofür eesel gebaut wurde. Es verbindet sich mit dem Helpdesk, den du bereits betreibst (Zendesk, Freshdesk, Gorgias und 100+ Integrationen), lernt ab dem ersten Tag aus deinen vergangenen Tickets und Hilfedokumenten und taggt, füllt Felder aus und leitet von dort weiter – während du die volle Kontrolle darüber behältst, was es automatisch anwendet und was es nur vorschlägt.
Das Unterscheidungsmerkmal ist der Simulationsmodus: Du lässt ihn über deine historischen Tickets laufen und siehst genau, wie er sie getaggt hätte, bevor etwas live geht – damit du nie über die Genauigkeit rätst. Die Preisgestaltung erfolgt pro Ticket, nicht pro Agent, was tendenziell wichtig wird, sobald man es mit einem Per-Seat-Add-on vergleicht.

Ein Team, das KI als First Responder auf einem internen Jira Service Management-Helpdesk einsetzt, brachte die Attraktivität auf den Punkt:
"Wir nutzen es als First Responder für unsere Helpdesk-Tickets in Jira. Es agiert im Wesentlichen genau wie ein Agent."
Jason Loyola, Head of IT, InDebted (Fallstudie)
Du kannst deinen Zendesk (oder welchen Helpdesk du auch immer nutzt) verbinden und eine Simulation in wenigen Minuten durchführen. Kostenlos zum Ausprobieren, keine Kreditkarte erforderlich.
Häufig gestellte Fragen
Wie automatisiere ich Ticket-Tagging mit KI?
Du verbindest eine KI mit deinem Helpdesk, gibst ihr eine saubere Tag-Liste und lässt sie jedes eingehende Ticket lesen, um Intent, Sprache und Stimmung zu erkennen und dann das passende Tag zu vergeben. Am sichersten ist es, im Vorschlagsmodus zu starten, die Tags mit einem Ticket-Triage-Tool gegen deine eigene Historie zu prüfen und die automatische Vergabe erst zu aktivieren, wenn die Genauigkeit konstant ist. Diese Anleitung behandelt die Zendesk-spezifische Version.
Kann KI Tickets in Zendesk automatisch taggen?
Ja. Zendesks intelligente Triage taggt nach Thema, Stimmung und Sprache im Copilot-Add-on, und du kannst zusätzlich ein dediziertes Tool darüberlegen, das auf deinen bisherigen Tickets trainiert. Sieh dir unsere Hinweise zu den Zendesk-KI-Funktionen und dazu an, wie man Zendesk-Tickets umfassend automatisiert.
Was kostet KI-Ticket-Tagging?
Native Add-ons werden in der Regel pro Agent abgerechnet: Zendesks Copilot-Add-on kostet 50 $/Agent/Monat, und Freshdeks Freddy Copilot hebt den realistischen Mindestpreis auf etwa 84 $/Agent/Monat. Eine nutzungsbasierte Freddy-Pricing-Alternative wie eesel berechnet stattdessen pro Ticket, mit transparenten Preisen und ohne Sitzgebühr.
Wird KI Tickets falsch taggen?
Manchmal, besonders am Anfang oder wenn sich deine Tags überschneiden. Die Lösung besteht darin, die Taxonomie zu bereinigen, das Modell zunächst gegen historische Tickets laufen zu lassen und Tickets mit geringer Konfidenz im Vorschlagsmodus zu belassen. Unser Leitfaden zur Reduzierung falscher Positivmeldungen geht tiefer ins Detail.
Brauche ich Tausende von vergangenen Tickets, um mit KI-Tagging anzufangen?
Einige native Tools schon: Freshdeks Auto-Triage benötigt rund 2.000 historische Tickets, bevor sie Felder zuverlässig vorhersagt. Tools, die auf deinen gelösten Tickets und Hilfedokumenten trainieren, können früher starten, was wichtig ist, wenn du eine kleinere Warteschlange betreibst. Vergleiche Ansätze in unserem Leitfaden zur KI-Ticket-Klassifizierung.

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.