Warum sich die Automatisierung des Zendesk-Ticket-Taggings lohnt
Tags sind die unscheinbare Hälfte jedes Workflows in Zendesk. Sie steuern Routing, SLAs, Makros, Reporting und die meisten Ansichten – und die Trigger-Ausführungsreihenfolge hängt von ihnen ab. Wer das Tagging falsch macht, macht auch jeden nachgelagerten Teil des Zendesk-Ticketing-Prozesses ein kleines bisschen falsch.
Das eigentliche Problem: Menschen taggen inkonsistent. Dasselbe Ticket bekommt von einem Agenten billing, von einem anderen payments, von einem dritten billing-issue. Nach sechs Monaten lässt sich die gewünschte Auswertung „wie oft tritt das Rückerstattungskarten-Problem auf" nicht mehr beantworten, weil die zugrundeliegenden Daten verwässert sind. Automatisierung geht nicht nur darum, Tastendrücke zu sparen – es geht darum, dass die Tag-Hygiene über Monate hält, nicht nur über Tage.
Teams, die das gut machen, ersetzen keine Menschen durch KI bei jedem Tag. Sie verwenden deterministische Regeln für die einfachen Fälle, Klassifikatoren für die mittleren und einen KI-Agenten für die wirklich unübersichtlichen – und passen dann die Taxonomie selbst an, wenn sich das Geschäft ändert.
Die drei Wege, ein Zendesk-Ticket zu taggen, nach Autonomie geordnet
Vor den einzelnen Schritten das Grundmodell, auf dem der Rest des Beitrags aufbaut.
Ebene 1 – Trigger und Automatisierungen. Deterministisch. Die Regel wird selbst geschrieben, Zendesk befolgt sie. Kostenlos, transparent und fehleranfällig, wenn die Sprache variiert.
Ebene 2 – Intelligent Triage. Zendesks eigener Klassifikator, Teil des Copilot-Add-ons oder des Enterprise-Plans. Wendet automatisch Intent, Sentiment und Sprache an. Besser bei Sprachvariationen; gebunden an die Kategorien, auf die Zendesk vortrainiert hat.
Ebene 3 – ein KI-Agent, der das Ticket liest. Liest nicht nur die Betreffzeile, sondern den gesamten Text, die Kundenhistorie, Makros und das Hilfecenter. Wendet semantische Tags aus der eigenen Taxonomie an. Höchste Leistung, größter Einrichtungsaufwand.
Eine Ebene zu überspringen ist fast nie sinnvoll. Trigger-basiertes Tagging ist nach wie vor die schnellste, günstigste und vorhersagbarste Ebene – und ein KI-Tag für urgent ist ein schwächeres Signal als ein Trigger, der durch das Wort „down" in einem Ticket über die Produktions-API ausgelöst wird. Die Kunst liegt darin zu wissen, welche Ebene welchen Tag verantworten soll.
Ebene 1: Trigger und Automatisierungen – das deterministische Fundament
Hier sollte jedes Team beginnen, und überraschend viele kommen nie darüber hinaus.
Was es eigentlich ist
Ein Zendesk-Trigger reagiert auf Ticket-Ereignisse (erstellt, aktualisiert, Statusänderung) und kann eine Tags hinzufügen-Aktion ausführen, wenn seine Bedingungen zutreffen. Eine Automatisierung läuft auf einem Zeitplan – z. B. „jedes Ticket taggen, bei dem der Status seit 48 Stunden auf „Ausstehend" steht". Beide sind in Zendesks Trigger-Bedingungsreferenz und unserer Zendesk-Automatisierungsübersicht dokumentiert.
Einrichtungsschritte
- Zu Admin Center → Objekte und Regeln → Business-Regeln → Trigger gehen und auf Trigger hinzufügen klicken.
- Den Trigger spezifisch benennen, damit er später auditierbar ist – z. B.
Tag: Rückerstattung im BetreffstattRückerstattungs-Trigger. - Bedingungen hinzufügen. Häufige für Tag-Automatisierung:
Betreff enthält folgende Wörter,Kommentartext enthält,Kanal ist,Ticketformular ist,Organisation ist. Die Trigger-Regex-Funktion ermöglicht das Abgleichen von Mustern statt wörtlicher Begriffe – das ist die wichtigste Erweiterung für Keyword-Tagging. - Unter Aktionen Tags hinzufügen wählen und den Tag-Namen eingeben. Zendesk erstellt neue Tags beim Tippen automatisch – praktisch und gefährlich zugleich (siehe Taxonomie-Abschnitt unten).
- Speichern und an einem echten Ticket testen.
Bei Messaging-Kanal-Triggern sind Bedingungen und Aktionen etwas anders – besonders wichtig ist, dass das Gespräch getaggt werden kann, bevor es überhaupt an einen menschlichen Agenten übergeben wird.
Wo es versagt
Trigger sind deterministisch – das ist ihre Stärke und ihre Grenze. Ein Trigger, der nach dem Wort „Rückerstattung" sucht, übersieht Geld zurück, Chargeback, Bestellung zurückgeben und einen Kunden, der auf Spanisch schreibt. Der Tag-hinzufügen / Tag-entfernen-Ansatz lässt sich mit Synonymen stapeln, aber dann pflegt man für immer ein Keyword-Wörterbuch – und bei jedem neuen Produktlaunch muss es aktualisiert werden.
Es gibt außerdem eine harte Grenze: Trigger können kein Sentiment lesen, keine Dringlichkeit im Tonfall erkennen, und nichts, was vom gesamten Ticketverlauf statt der ersten Nachricht abhängt. Dafür braucht man Ebene 2 oder 3.
Ebene 2: Zendesk Intelligent Triage – Intent, Sentiment, Sprache
Das ist Zendesks eigener KI-Klassifikator, und er macht eine Sache gut: jedes Ticket automatisch nach Intent, Entität, Sentiment und Sprache klassifizieren. Zendesk positioniert es als Eingabe, die Routing, Automatisierung und Reporting antreibt – und das stimmt. Unsere G2-Lektüre zu Zendesk bestätigt, dass Bewerter Intelligent Triage als den Teil der Copilot-Suite hervorheben, der seinen Preis wert ist.
Was genau getaggt wird
Intelligent Triage wendet standardmäßig vier Klassifikationen an:
- Intent – was der Kunde anfragt. Zendesk liefert einen Starter-Set an Intents, die auf aggregierten Support-Daten trainiert wurden (z. B.
Kauf / neue Bestellung,Rückerstattung / Stornierung,Konto / Login), und dieser kann mit eigenen Intents erweitert werden. - Entität – das Substantiv zum Intent (
Bestellnummer,Konto-E-Mail,Produkt-SKU). - Sentiment –
positiv,neutral,negativbasierend auf dem Ton des Kunden im Gespräch. - Sprache – automatisch aus dem Nachrichtentext erkannt.
Einrichtungsschritte
- Sicherstellen, dass Copilot im Account vorhanden ist – entweder als Add-on für
50 $/Agent/Monat oder im Enterprise-Paket enthalten. - In Admin Center → KI → Intelligent Triage die Intent-, Sentiment- und Sprachklassifikation aktivieren.
- Intents vorhandenen Tags zuordnen. Zendesks Intents sind vordefiniert benannt (
purchase,cancellation) – entweder direkt als Tags übernehmen oder auf die eigene Taxonomie umzuordnen, damit die Berichte nicht in zwei parallele Benennungsschemata zerfallen. - Intent und Sentiment in vorhandene Trigger einbinden. Beispiel:
intent = refundUNDsentiment = negative→ Tagpriority_escalationsetzen und an die Eskalationsgruppe weiterleiten. - Das Reporting-Dashboard etwa 48 Stunden mit Live-Traffic beobachten, bevor den Labels für das Routing vertraut wird – die Konfidenz ist volumenabhängig.
Die ehrlichen Kosten
Zendesks Preismodell rechnet KI an zwei Stellen gleichzeitig ab – ein Pro-Agent-Add-on für Copilot und ein Pro-Resolution-Zähler für Automated Resolutions. Intelligent Triage selbst liegt innerhalb des Copilot-Add-ons, es wird also nicht pro Tag bezahlt – aber sobald diese Tags in KI-Agenten fließen, die automatisch antworten, wird das Resolution-Kontingent aufgebraucht, und Überschreitungen kosten laut Drittanalysen rund 1,20–1,50 $ pro Resolution über dem Commit.
Für eine offene Einschätzung der Rechnung: unser Zendesk-Preisbewertungsbeitrag und der Erklärungsartikel zur dynamischen Preisgestaltung bei Resolutions.
Was es immer noch nicht kann
Intelligent Triage taggt in Zendesks Kategorien, nicht in den eigenen. Wer ein Multi-Brand-DTC-Unternehmen betreibt und einen Tag wie shopify_subscription_billing_paused braucht, findet dafür keinen vordefinierten Intent – entweder Zendesks cancellation-Intent annähern (und die Präzision in den Berichten verlieren) oder Triage für diesen Ticket-Anteil ganz überspringen.
Außerdem ist es auf den eigenen Text des Tickets beschränkt. Der Kunde kontaktiert zum fünften Mal wegen desselben Problems? Triage erkennt dieses Signal nicht – es liest jedes Ticket frisch, ohne die vollständige Kundenhistorie. Ebene 3 behebt beides.
Ebene 3: Ein KI-Agent, der das Ticket wirklich liest
Das ist die Ebene, die die Lücke zwischen „Tagging" und „Ticket verstehen" schließt. Ein KI-Agent liest das vollständige Ticket plus Kundenhistorie plus Makros und Hilfecenter, entscheidet, worum es im Ticket wirklich geht, und setzt Tags aus der eigenen Taxonomie. In demselben Durchlauf kann er auch eskalieren, den Status ändern und neu zuweisen.

Was ein KI-Agent liest, was ein Klassifikator nicht liest
| Quelle | Native Trigger | Intelligent Triage | Ein KI-Agent |
|---|---|---|---|
| Betreff und Text dieses Tickets | Ja | Ja | Ja |
| Vollständige Tickethistorie des Kunden | Nein | Nein | Ja |
| Interne Makros und gespeicherte Antworten | Nein | Begrenzt | Ja |
| Hilfecenter / Wissensdatenbank | Nein | Nein | Ja |
| Eigene Tag-Taxonomie | Ja (selbst geschrieben) | Teilweise (gemappt) | Ja |
| Sentiment | Nein | Ja | Ja |
| Sprache | Nein | Ja | Ja |
| Gestern neu erfundene Tags | Ja (manuell) | Nein (Neutraining) | Ja (automatisch) |
Die vierte Zeile ist wichtiger als oft erkannt. Ein Agent, der vergangene Zendesk-Tickets lesen kann, hat Jahre an Kontext eingebaut – wenn ein neues Ticket mit „mein Abonnement wurde pausiert" eingeht, kann er es genauso taggen wie die 400 ähnlichen Tickets im letzten Jahr, anstatt aus einer Standard-Taxonomie zu raten.
So richtet man das mit eesel für Zendesk ein
Die kürzeste Version: vom Zendesk Marketplace installieren, vorhandene Tickets und Makros indexieren lassen, die Tag-Taxonomie in normaler Sprache beschreiben, eine Simulation mit vergangenen Tickets durchführen, um die Labels zu prüfen, dann live gehen.
Die ausführlichere Version, Schritt für Schritt:
- eesel AI für Zendesk installieren vom Marketplace und über das eesel-Dashboard autorisieren. Zwei Klicks.
- Ingestion abwarten: Hilfecenter-Artikel, die letzten 12 Monate gelöster Tickets und Makros werden verarbeitet. Kein manuelles Labeln. Die Plattform unterstützt auch Confluence, Notion, Google Drive und Shopify, falls die Tag-Logik Daten aus diesen Quellen benötigt.
- Die Tag-Taxonomie in normaler Sprache beschreiben in der Agentenkonfiguration. Das eesel-Dashboard nimmt Anweisungen wie „Jedes Ticket über Abonnement-Pausierungen mit
subscription_pausedtaggen. Wenn der Kunde eine Rückerstattung erwähnt, zusätzlichrefund_requesttaggen. Wenn die Sprache nicht Englisch ist, den Tag mit dem Sprachcode prefixen." – kein Regel-Builder, keine Bedingungsmatrix. - Die Simulation ausführen gegen vergangene Tickets. Das ist der Schritt, den kein anderer hat und auf den man bestehen sollte – man sieht genau, welche Tags der Agent hätte vergeben würden auf historischen Tickets, nebeneinander mit den Tags, die Menschen tatsächlich gesetzt haben, bevor der Agent jemals Live-Ticketdaten berührt.
- Autonomes Tagging aktivieren für die Kategorien, bei denen man dem Agent vertraut, und den Agenten im Entwurfsmodus für die anderen lassen. Entwürfe posten Tags nur als interne Notizen – für Menschen sichtbar, für Kunden unsichtbar, und trivial rückgängig zu machen, falls man seine Meinung ändert.
- Die Berichte lesen. eesel zeigt die Tags, bei denen es unsicher ist, und wo die Taxonomie selbst so unscharf ist, dass sich zwei Tags überschneiden – das ist normalerweise das nützlichste Audit des eigenen Zendesks seit Jahren.
„Im ersten Monat löst eesel 73 % unserer Tier-1-Anfragen. eesel bietet eine einfache Zendesk-Implementierung und -Einrichtung. Unser Team hat innerhalb unseres 7-tägigen Tests implementiert und Ergebnisse erzielt. Antworten sind einfach zu korrigieren und anzupassen. Die Plattform umfasst sogar Automatisierungen für Ticket-Tagging, Zuweisung und Statusaktualisierungen!"
Kim Simpson, Gridwise (G2-Bewertung)
eesel rechnet 0,40 $ pro Ticket end-to-end ab – jeder Hin-und-Her-Austausch zum selben Ticket zählt als eine Aufgabe, und Tagging ist inklusive. Keine Sitzungsgebühr, kein Resolution-Zähler, kein Copilot-Add-on on top. Ein monatliches Ausgabenlimit lässt sich setzen, und der Agent pausiert, wenn es erreicht ist.
Für den weiteren Marktüberblick zum Vergleich: unsere Übersichten zu Zendesk-KI-Alternativen und dem besten KI für Ticket-Automatisierung behandeln Decagon, Ada, Aisera, Forethought und weitere.
Bevor irgendetwas getaggt wird: die Taxonomie richtigstellen
Das ist der Abschnitt, den alle überspringen und alle bereuen. Welche Automatisierung auch immer gewählt wird, kann nur so gut sein wie die Tags, zwischen denen sie wählen kann.
Ein schnelles Audit, das sich an einem Nachmittag durchführen lässt:
- Die letzten 12 Monate an Tags exportieren und die Nutzung zählen. Alles unter ~30 Verwendungen ist entweder ein Tippfehler, ein Einmalereignis oder ein Tag, dessen Rückzug vergessen wurde. Zusammenführen oder löschen.
- Nach Synonymen suchen.
billing,billing-issue,payments,payment_problemsind dasselbe. Eines auswählen, die anderen als Aliase setzen, nachgelagerte Ansichten korrigieren. - Das gesamte Set auf Snake_case vereinheitlichen.
priority-highundpriority_highsind für Zendesk unterschiedliche Tags. Eine Konvention wählen. - Maximal drei Hierarchieebenen. Ein Tag wie
support_billing_refund_card_declined_visaist unbrauchbar. Zwei oder drei Ebenen –billing > refund > card_declined– reichen meistens aus. - Gegenseitig ausschließend auf jeder Ebene. Wenn die KI zwischen
urgentundpriority_highwählen muss, trifft sie bei verschiedenen Tickets unterschiedliche Entscheidungen. Entscheiden, welcher bleibt.
Sobald die Taxonomie sauber ist, die Automatisierung obendrauf aufbauen. In umgekehrter Reihenfolge vorzugehen – zuerst Automatisierung, Taxonomie-Bereinigung nie – führt zu Zendesk-Instanzen mit 400 Tags, die niemand mehr entwirren kann.
Was tatsächlich aufgesetzt werden würde
Ein reales funktionierendes Setup, von Anfang bis Ende:
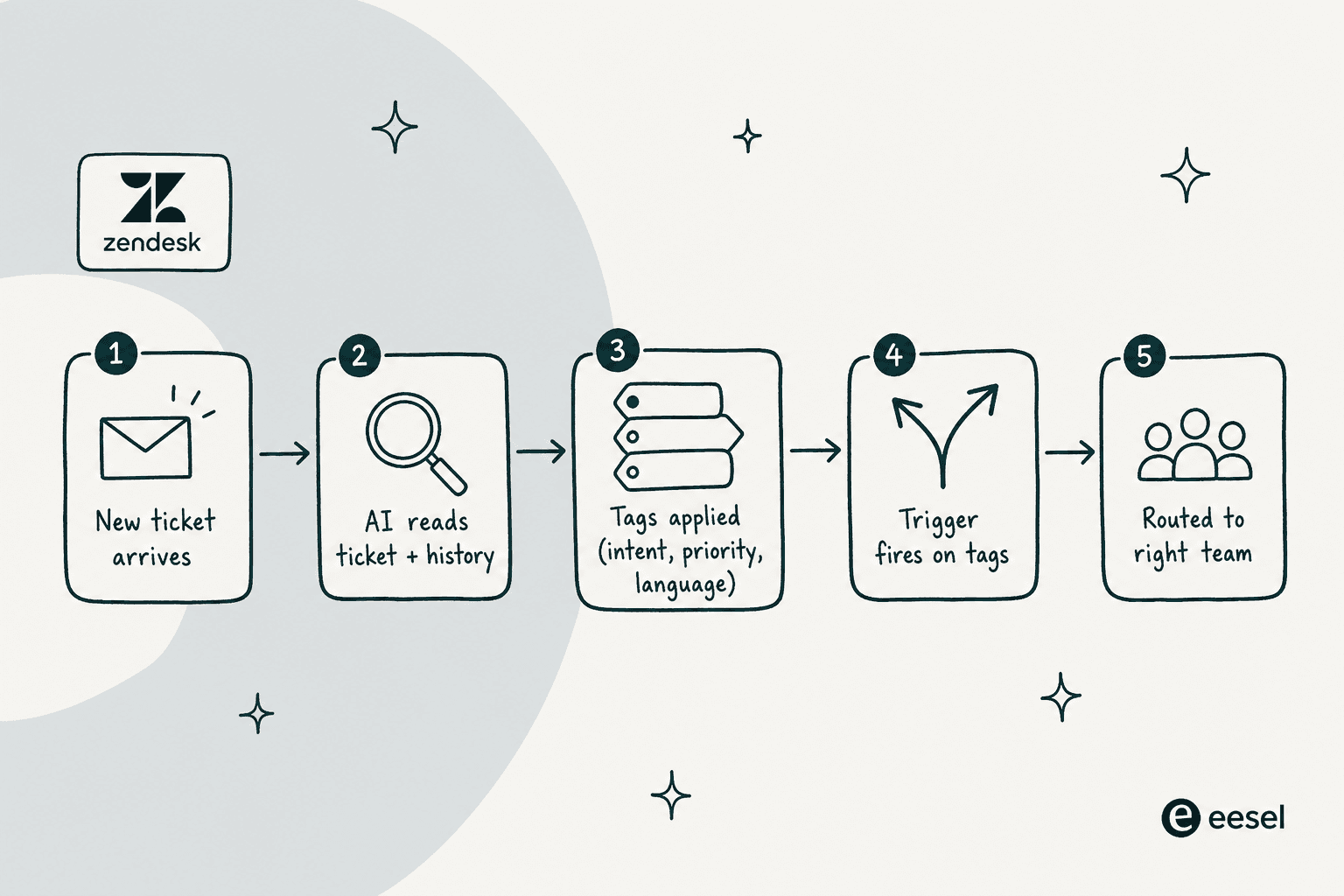
- Fünf harte Trigger für die universell eindeutigen Fälle –
password,cancel,outage,legal,billing. Diese laufen zuerst, weil sie kostenlos, schnell und eindeutig sind. Die vollständige Referenz, was ein Tags-hinzufügen-Trigger abgleichen kann, ist einen Lesezeichen wert. - Intelligent Triage aktiviert, auf die eigene Taxonomie statt auf Zendesks Standardwerte gemappt – damit
purchasezuintent_purchasewird,cancellationzuintent_cancel, und sie in dasselbe Benennungsschema wie die manuellen Tags passen. - eesel AI im Shadow-Modus für zwei Wochen, mit Tags nur als interne Notizen. Die Diffs lesen, die Taxonomie korrigieren wo der Agent unsicher ist, und die Falschpositivrate sinken sehen – unser Beitrag zur Reduzierung von KI-Falschpositiven ist das Kalibrierungshandbuch.
- Auf autonomen Betrieb umschalten für die Kategorien, bei denen der Diff sauber ist. Die mehrdeutigen Kategorien im Entwurfsmodus lassen und monatlich überprüfen.
- Ein Makro pro Haupt-Tag, damit ein Mensch, der das Ticket aufnimmt, die vorgeschlagene Aktion neben dem Tag sieht – das macht den Tag handlungsorientiert statt dekorativ.
Das ist dasselbe Muster, das bei hochvolumigen eesel-Kunden wie Smava (100.000+ deutschsprachige Zendesk-Tickets pro Monat, vollautomatisiert) und Ecosa (10.000+ mehrsprachige Tickets pro Monat, ≤1 Stunde Integration mit Zendesk) funktioniert hat. Die Form des Workflows ändert sich nicht zwischen einem Team mit 1.000 Tickets pro Monat und einem mit 100.000 – nur die Tag-Taxonomie wird dichter.
Häufige Fehler
Eine kurze Liste der am häufigsten gesehenen Misserfolge:
- Zendesk bei jedem Tippfehler automatisch Tags erstellen lassen. Die
Tags hinzufügen-Aktion in einem Trigger erzeugt jeden eingegebenen String. Eine wöchentliche Überprüfung neuer Tags einrichten, damitsubscriptiom_paused(Tippfehler beachten) nicht still zu einem eigenen Bucket wird. - Nach Gefühl statt nach Regel taggen. Makros und Trigger sollten die einzigen Quellen konsistenter Tags sein. Wenn ein Agent
urgentmanuell hinzufügt, bedeutet es bis Freitag sechs verschiedene Dinge. - KI-Konfidenz ohne Shadow-Periode vertrauen. Jeder KI-Agent, der eine Installation wert ist, liefert einen Konfidenzwert. Diesen nutzen. Tags unter ~80 % Konfidenz sollten zumindest anfangs in den Entwurfsmodus und zur menschlichen Überprüfung gehen.
- Sprache vergessen. Ein spanischsprachiger Kunde, der mit dem englischen Tag
refundversehen wird, ist ein verlorener Report. Ebene 2 (Spracherkennung) und Ebene 3 (mehrsprachige KI) beheben das – Ebene 1 allein nicht. - Nicht beschneiden. Tags häufen sich an. Alle sechs Monate exportieren und die Tags unter dem eigenen Nutzungs-Schwellenwert löschen.
Die ehrliche Einschätzung zu Zendesks eigener KI aus der Community: Sie ist gut bei mittleren Fällen und wird bei großem Volumen schnell teuer. Die meistzitierte Reddit-Beschwerde über Automated Resolutions ist die automatische Abrechnung ohne Deckel, ohne Karenzzeit und ohne Vormonatswarnung – weshalb wir für jedes Team mit echtem Volumen standardmäßig auf eine Pro-Ticket-Alternative zurückgreifen würden.
eesel für Zendesk-Ticket-Tagging ausprobieren
Wer bis hierher gelesen hat, bekommt eine konkrete Empfehlung: Ebene 1 an einem Nachmittag einrichten, Intelligent Triage aktivieren, wenn bereits für Copilot bezahlt wird, und eesel AI für Zendesk für die Ebene hinzuziehen, die keiner der beiden erreicht – semantisches Tagging, mehrsprachiger Support und Lernen aus eigenen vergangenen Tickets.
eesel wird vom Zendesk Marketplace installiert, ist in unter 30 Minuten verbunden, läuft in der Simulation gegen vergangene Tickets, bevor es ein Live-Ticket berührt, und rechnet 0,40 $ pro Ticket ab – Tagging, Zuweisung, Statusänderungen und Antworten alles inklusive.
Try eesel kostenlos, oder einen 30-minütigen Demo-Termin buchen – dann wird das Zendesk-Setup mit echten Tickets gemeinsam durchgegangen.
Häufig gestellte Fragen
Was ist Zendesk Intelligent Triage und wie viel kostet es?
Können Zendesk-Trigger Tickets ohne KI automatisch taggen?
Gibt es eine günstigere Alternative zum KI-Tagging in Zendesk?
Wie verhindere ich Fehler beim KI-gestützten Ticket-Tagging?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.