Zusammenfassung
Der größte Teil der Support-QA basiert auf einer Lüge durch Auslassung: Sie prüfen 1–3 % der Gespräche manuell und sprechen dann über „Qualität", als würde diese Stichprobe die anderen 97 % repräsentieren. Das tut sie nicht. Support-QA mit KI bedeutet, jedes einzelne Gespräch automatisch anhand Ihres Bewertungsschemas zu prüfen, sodass die Abdeckung aufhört, der Engpass zu sein.
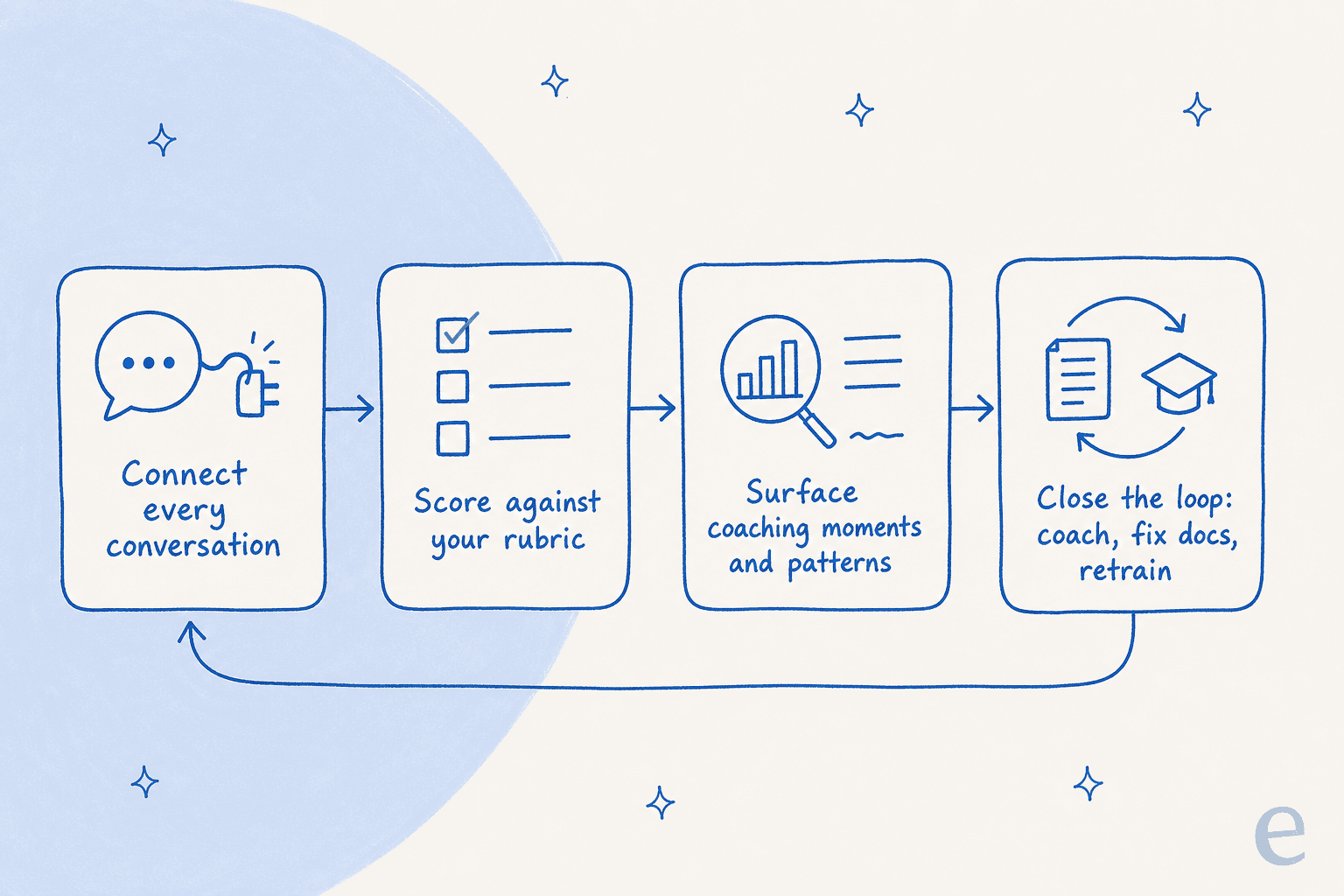
Praktisch gesehen besteht der Ablauf aus fünf Schritten: Schreiben Sie auf, wie eine gute Antwort aussieht, verbinden Sie Ihre gesamte Gesprächshistorie, lassen Sie die KI alles bewerten, heben Sie die Coaching-Momente und wiederkehrenden Muster hervor, die manuelle Stichproben übersehen hätten, und schließen Sie den Kreis durch Agenten-Coaching und das Korrigieren der Dokumentation hinter den Fehlern.
Der Schritt, den alle überspringen: Unterziehen Sie auch den KI-Agenten einer QA. Ich habe erlebt, wie ein selbstsicher klingender Bot eine falsche Antwort gab – bevor Sie Automatisierung mit Live-Tickets vertrauen, bewerten Sie sie zuerst gegen Ihre bisherigen Tickets. eesel's KI-Helpdesk-Agent führt diese Simulation mit Ihrer eigenen Historie durch, was dem nächsten Äquivalent eines QA-Durchlaufs vor dem Go-live entspricht.
Was Support-QA wirklich ist – und warum die manuelle Version kaputt ist
Support-QA ist Qualitätssicherung für Kundengespräche. Sie nehmen ein Bewertungsschema (War die Antwort korrekt? War der Ton richtig? Hat es das Problem wirklich gelöst?) und bewerten Gespräche daran, um dann anhand der Erkenntnisse Agenten zu coachen und Lücken zu schließen. Gut gemacht, ist das der Weg, wie ein Support-Team besser wird, statt nur schneller zu werden – und es ist mit allem verknüpft, von SLA-Management bis zu Support-Kosteneinsparungen.
Das Problem, das ich in der Praxis kenne: Die manuelle Version schaut immer nur auf einen Bruchteil. Ein QA-Analyst zieht pro Agent und Woche eine Handvoll Tickets, bewertet sie in einer Tabelle und macht weiter. Wenn Ihr Team einige tausend Gespräche pro Monat bearbeitet, prüfen Sie vielleicht 2 % davon. Die 98 %, die Sie nicht geöffnet haben, könnten voller höflicher, selbstbewusster und völlig falscher Antworten sein – Ihr QA-Programm würde es nie erfahren.
Dieser Bruchteil ist nicht nur klein, er ist verzerrt. Analysten werden von Tickets angezogen, die leicht zu bewerten, aktuell oder bereits markiert sind. Der wirklich seltsame Grenzfall, derjenige, der leise einen Kunden verloren hat, schafft es selten in die Stichprobe. So coachen Sie Agenten bei einem zufälligen 2-%-Anteil, während die Muster, die wirklich CSAT beeinflussen, in dem Teil verborgen bleiben, den niemand liest.
Manuelle QA ist außerdem langsam und inkonsistent. Zwei Prüfer bewerten dasselbe Gespräch unterschiedlich. Bis eine Coaching-Notiz ankommt, hat der Agent 400 weitere Tickets bearbeitet. All das ist nicht die Schuld des Analysten – es ist ein Mathematikproblem: Menschen können nicht alles lesen, also lesen sie eine Stichprobe, und eine Stichprobe kann Ihnen nichts über Ihre gesamte Warteschlange sagen.
Was sich ändert, wenn KI Ihre QA übernimmt
Die Verschiebung ist einfach zu formulieren und kaum zu übertreiben: 100 % der Gespräche zu bewerten kostet ungefähr denselben Aufwand wie 2 % zu bewerten. Sobald eine KI jedes Gespräch anhand Ihres Schemas liest, ist die Abdeckung nicht länger das, was Sie rationieren müssen.
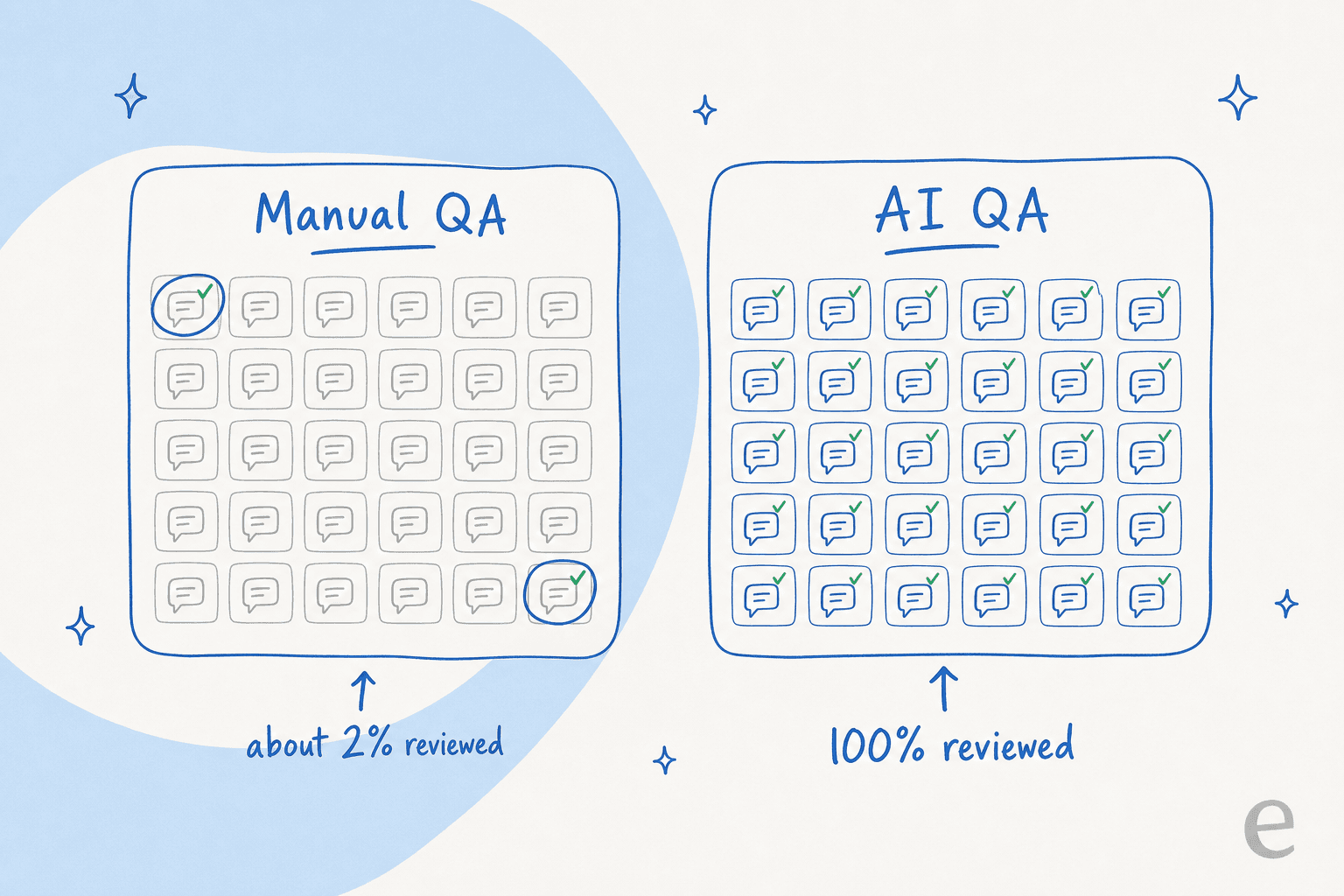
Drei Dinge ändern sich gleichzeitig. Erstens verschwindet die Stichprobenverzerrung, weil es keine Stichprobe gibt – die KI bewertet die gesamte Warteschlange mit einem einheitlichen Schema. Zweitens verkürzt sich der Feedback-Kreis: Ein Gespräch kann Minuten nach seinem Abschluss bewertet werden, nicht erst am Ende eines Prüfzyklus. Drittens hört QA auf, eine Stichprobenkontrolle zu sein, und wird zu einer Support-Kennzahl, die Sie tatsächlich im Zeitverlauf verfolgen können – nach Agent, nach Thema, nach Kanal.
Was sich nicht ändert: Urteilsvermögen gehört weiterhin den Menschen. Die KI liest alles und markiert, was auffällig wirkt; ein Mensch entscheidet, was dagegen zu tun ist. Diese Arbeitsteilung ist dieselbe, die KI vs. menschlichen Support überall funktionieren lässt – Maschinen für das Volumen, Menschen für die Entscheidungen, die einen denkenden Kopf brauchen. Daher passt QA so natürlich neben einem KI-Copiloten in Ihren Support-Workflow: Dieselben Gesprächsdaten fließen in beide ein.
Support-QA mit KI: Schritt für Schritt
Das Ganze gut umzusetzen ist im Grunde KI und Automatisierung im Support, auf Qualität statt auf Volumen ausgerichtet – und Sie brauchen dafür kein Data-Team. Das Ganze umfasst fünf Schritte, wobei der Kreislauf genauso wichtig ist wie die Schritte selbst, weil QA nur dann lohnt, wenn Erkenntnisse zurück in die Arbeit fließen.
Schritt 1: Schreiben Sie auf, wie „gut" aussieht
QA ist nur so gut wie ihr Bewertungsschema, und ein KI-Schema muss explizit sein – kein „Sie erkennen es, wenn Sie es sehen." Legen Sie die wenigen Kriterien fest, nach denen jede Antwort bewertet wird. In der Praxis sind das etwa fünf Dimensionen: War es sachlich korrekt, war der Ton richtig, hat es das Problem gelöst, hat es die Richtlinien befolgt, und wurde eine echte Quelle zitiert statt etwas erfunden?
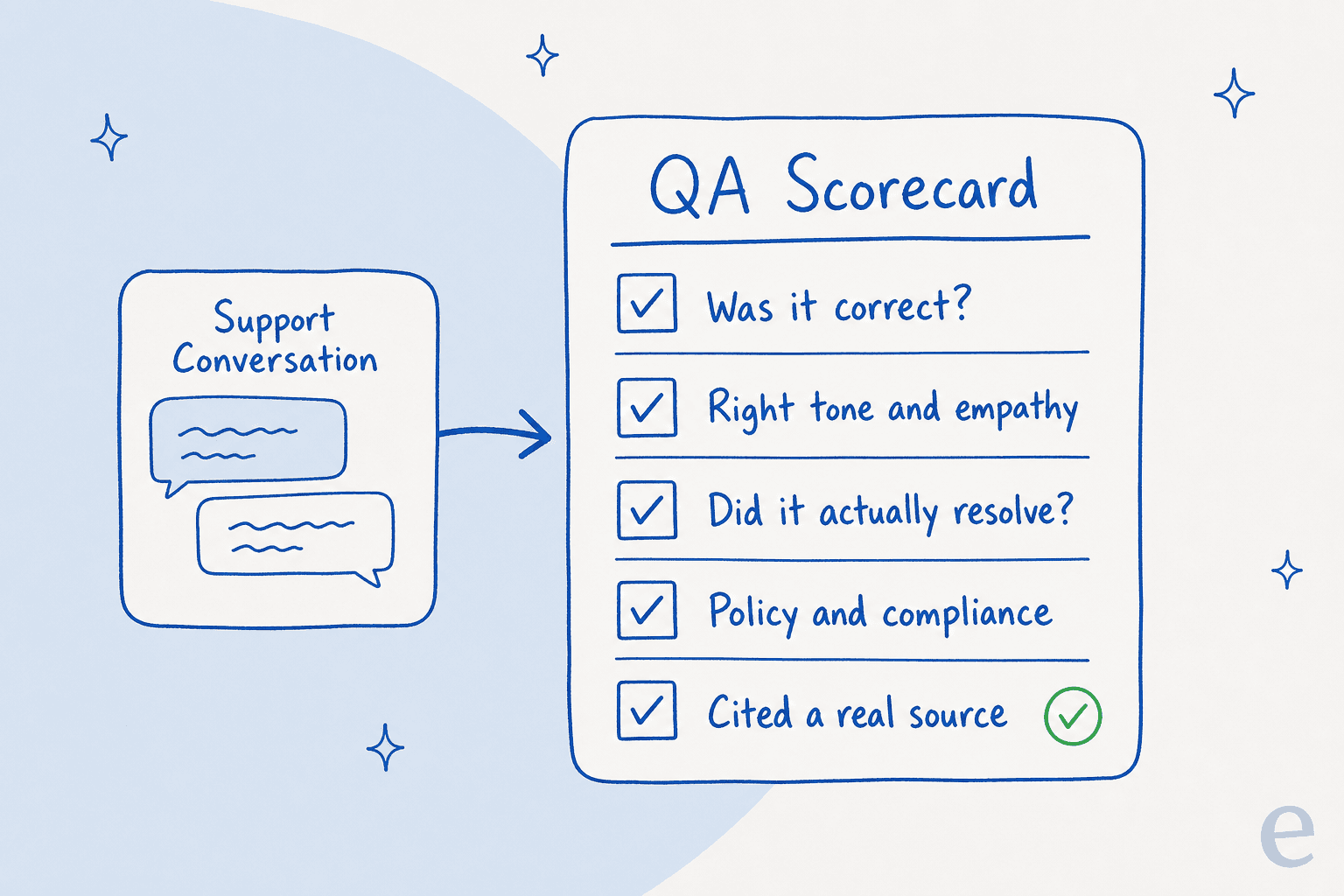
Halten Sie es kompakt. Ein Schema mit 30 Kriterien klingt rigoros und wird inkonsistent angewandt – von Menschen wie von KI. Die Quellenangabe-Zeile ist wichtiger, als die meisten erwarten: Eine selbstbewusste Antwort ohne Quelle dahinter ist genau die Art von Sache, die in einer Tabelle gut aussieht und sich beim Nachprüfen als Halluzination entpuppt.
Schritt 2: Verbinden Sie jedes Gespräch – keine Stichproben
Richten Sie die KI auf Ihre gesamte Gesprächshistorie aus, nicht auf einen Export der markierten Tickets der letzten Woche. Das bedeutet normalerweise, Ihren Helpdesk direkt zu verbinden, sodass abgeschlossene Gespräche automatisch einfließen – egal ob Sie Zendesk, Freshdesk, Gorgias oder Help Scout nutzen.

Hier kommt auch Ihre Wissensdatenbank ins Spiel. Eine QA-Bewertung von „falsch" ist nur nützlich, wenn Sie wissen, ob der Agent falsch lag oder die Dokumentation. Wenn die KI sowohl die Gespräche als auch das Quellmaterial erhält, das hätte verwendet werden sollen, kann sie diese beiden Fälle unterscheiden – das ist der Unterschied zwischen dem Coachen eines Menschen und dem Korrigieren eines Wissensdatenbank-Chatbot-Artikels.
Schritt 3: Automatisch anhand des Schemas bewerten
Nun liest die KI jedes Gespräch und bewertet es nach Ihren Dimensionen. Das gewünschte Ergebnis ist keine einzelne Zahl, sondern eine Aufschlüsselung: Dieses Gespräch hat bei der Lösung schlecht abgeschnitten, dieses hat die Antwort getroffen, aber der Ton war daneben, diese Charge hat alle an derselben Richtlinie versagt. Trends sind wichtiger als jede einzelne Note.

Behandeln Sie die erste Woche der Bewertungen als Kalibrierung, nicht als Evangelium. Lesen Sie einen Teil der KI-Noten gegen Ihr eigenes Urteil und passen Sie das Schema dort an, wo es zu streng oder zu nachsichtig ist. Nach ein paar Durchläufen stabilisieren sich die Bewertungen, und Sie werden ihnen vertrauen wie einem zweiten Analysten – mit gelegentlicher Stichprobenkontrolle. Das ist dieselbe Disziplin wie beim Verfolgen der Erstantwortzeit oder jeder anderen Support-Kennzahl: Die Metrik ist erst nützlich, wenn Sie ihr vertrauen.
Schritt 4: Coaching-Momente und Muster aufdecken
Alles zu bewerten ist sinnlos, wenn das Ergebnis eine Wand aus Zahlen ist. Die Stärke liegt darin, dass die KI die Gespräche herausfiltern kann, die ein Mensch sich wirklich ansehen sollte: die drei Tickets dieser Woche, bei denen ein Agent etwas gegen die Richtlinien versprochen hat, das Thema, bei dem jede Antwort schlecht bewertet wurde, der neue Mitarbeiter, dessen Ton bei Rückerstattungen nachlässt.
Das ist die Coaching-Ebene, und hier verdient sich QA ihren Wert. Anstatt „hier sind fünf zufällige Tickets, die ich bewertet habe" erhält Ihr Teamleiter: „Hier sind die spezifischen Momente, die ein Gespräch wert sind, gruppiert nach dem, was sie gemeinsam haben." Wiederkehrende Muster fließen auch direkt in den Rest Ihres Betriebs ein: Ein Thema, das immer wieder schlecht bewertet wird, ist normalerweise ein Ticket-Triage- oder Eskalations-Problem, kein Personalproblem. Korrigieren Sie die Dokumentation oder die Ticket-Tagging-Regel dahinter, und oft reduzieren Sie gleichzeitig das Ticket-Volumen.
Schritt 5: Den Kreis schließen
QA, die nichts verändert, ist Theater. Der letzte Schritt besteht darin, die Erkenntnisse zurückzuführen: die Agenten coachen, die die KI markiert hat, die Dokumentation hinter den wiederkehrenden Fehlern überarbeiten und das Schema aktualisieren, wenn sich Produkt und Richtlinien ändern.

Wenn ein Teil Ihres Supports automatisiert ist, bedeutet den Kreis schließen auch, die KI selbst zu korrigieren. Gute Tools lernen aus diesen Korrekturen, sodass ein einmaliger Fix verhindert, dass derselbe Fehler sich wiederholt. Das verwandelt QA von einem rückwärtsgewandten Zeugnis in etwas, das Kundenservice-Automatisierung Woche für Woche aktiv verbessert.
Was alle vergessen: Auch den KI-Agenten einer QA unterziehen
Hier ist der Teil, den die meisten „KI für QA"-Beiträge überspringen – und der mir nach mehr als drei Jahren, in denen ich KI-Agenten in Live-Support-Warteschlangen eingesetzt habe, am wichtigsten ist. Wenn Sie KI Tickets bearbeiten lassen, muss diese KI eine QA bestehen, bevor sie einen Kunden berührt. Die meisten Teams führen diese Prüfung nie durch.
Ich habe erlebt, wie ein selbstsicher klingender Bot eine Frage mit voller Überzeugung falsch beantwortet hat. Ein DTC-Supplements-Lead hat das Risiko gegenüber uns klar benannt: Ein KI, der auf alles „Tut mir leid, ich weiß es nicht" antwortet, ist nutzlos, aber ein KI, der rät, ist schlimmer – weil niemand 7.000 Tickets nachträglich lesen kann, um die Ratereien zu finden. Die Antwort auf beides ist QA: Der Agent sollte nur das übernehmen, wobei er sich sicher ist, und Sie sollten seine Arbeit genauso bewerten wie die eines Menschen.
Also haben wir diese Prüfung eingebaut. Bevor ein eesel-Agent live geht, können Sie ihn in einer Simulation gegen Ihre echten vergangenen Tickets laufen lassen und seine Qualität und Abdeckung nach Thema sehen – ohne dass ein einziger Kunde betroffen ist. Als wir einen Agenten gegen den tatsächlichen Zendesk-Traffic eines Kunden auditiert haben, erzielte er etwa 93 % Triage-Genauigkeit und erkannte 100 % des Spams bei null falsch positiven Ergebnissen. Die Antwort-Entwürfe waren aber nur zu 88 % inhaltlich korrekt, mit einer sachlichen Fehlerquote von 7 %. Genau wegen dieser 7 % unterziehen Sie den KI-Agenten einer QA: Er sieht im Gesamtbild großartig aus und braucht dennoch einen Konfidenz-Schwellenwert und einen Menschen in der Schleife bei schwierigen Fällen. Dieselben Bewertungen erscheinen dann live in Ihren Agenten-Analysen, sodass die QA des KI-Agenten nie wirklich aufhört.
Das ist auch die ehrlichste Antwort auf „Kann ich ihm vertrauen?" Sie vertrauen nicht auf Treu und Glauben – Sie unterziehen ihn einer QA, setzen ihn auf Entwurf statt Auto-Senden, wo sein Vertrauen gering ist, und erweitern seine Autonomie, wenn die Bewertungen es rechtfertigen. Das ist der Unterschied zwischen einer Demo und einem Einsatz in der Produktion.
Häufige Fehler, die Sie vermeiden sollten
Ein paar Fallen, in die Teams tappen, wenn sie QA auf KI verlagern:
- Die KI-Bewertung als endgültig behandeln. Sie ist ein erster Durchlauf, kein Urteil. Prüfen Sie sie stichprobenartig, besonders am Anfang – genau wie Sie einen neuen Analysten kalibrieren würden.
- Ein zu großes Bewertungsschema. Dreißig Kriterien klingt rigoros und führt zu inkonsistenten Bewertungen. Fünf scharfe Dimensionen schlagen dreißig unscharfe.
- Gespräche bewerten, ohne den Kreis zu schließen. Wenn sich nichts ändert (kein Coaching, keine Dokumentations-Korrekturen, keine Schema-Updates), haben Sie einen sehr gründlichen Bericht erstellt, auf den niemand reagiert.
- Die Automatisierung nicht der QA unterziehen. Wenn KI Tickets beantwortet, ist sie der Agent mit dem bei weitem höchsten Volumen. Sie nicht zu bewerten ist der größte blinde Fleck überhaupt.
- QA mit CSAT verwechseln. Ein Kunde kann ein Gespräch mit fünf Sternen bewerten, nachdem er eine selbstbewusst falsche Antwort erhalten hat. QA prüft, ob die Antwort tatsächlich korrekt war – deshalb möchten Sie sowohl Ihre QA-Bewertungen als auch Ihren Gorgias CSAT-Bericht oder Ihre Freshdesk-CSAT, ohne dass eines das andere ersetzt.
eesel für Support-QA ausprobieren
Wenn Sie Support-QA mit KI umsetzen möchten, ohne drei Tools zusammenzustückeln, ist genau das der Kern von eesel's KI-Helpdesk-Agent. Er verbindet sich mit Ihrem bestehenden Helpdesk und Ihrer Wissensdatenbank, liest Ihre bisherigen Gespräche und – das ist der entscheidende Teil für QA – lässt Sie eine Simulation über echte historische Tickets laufen, damit Sie Qualität und Abdeckung sehen können, bevor irgendetwas live geht.

Was KI-Kundenservice-Software angeht: Der nützliche Teil für QA ist, dass dieselbe Engine, die die Entwürfe eines KI-Agenten bewertet, auch die Gespräche Ihres Teams liest – sodass QA für Menschen und QA für Automatisierung an einem Ort stattfinden statt in zwei Tabellen. Es funktioniert wie ein Teammitglied, das an einem Nachmittag eingesteckt wird und Ihr Help-Center bereits kennt, mit nutzungsbasiertem Pricing, das Ihnen keinen Sitzplatz berechnet, nur damit Sie Ihre eigenen Tickets prüfen können. Kostenlos ausprobierbar.
Häufig gestellte Fragen
Was ist Support-QA, und worin unterscheidet sich KI-gestützte Support-QA?
Kann KI Support-Gespräche wirklich präzise bewerten?
Wie viel meines Support-Volumens sollte ich per KI einer QA unterziehen?
Ersetzt KI-gestützte Support-QA meine QA-Analysten?
Wie unterziehe ich einen KI-Support-Agenten selbst einer QA?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.