Wie priorisiere ich Support-Tickets mit KI?
Kurnia Kharisma Agung Samiadjie
Katelin Teen
Zuletzt bearbeitet June 23, 2026

Kurzzusammenfassung
Wenn Sie gerade „Wie priorisiere ich Support-Tickets mit KI" in Google eingegeben haben, stehen die Chancen gut, dass Ihre Warteschlange im Grunde First-in-First-out funktioniert – ein Passwort-Reset steht vor einem Enterprise-Ausfall, nur weil er zuerst ankam. Die kurze Antwort: Lassen Sie die KI jedes eingehende Ticket lesen, klassifizieren und nach Dringlichkeit, Geschäftsauswirkung und SLA-Risiko bewerten, damit das wirklich wichtige Ticket die Warteschlange automatisch überspringt.
Ich beschäftige mich intensiv damit, wonach Support-Leiter suchen, und diese Frage führt immer zum gleichen eigentlichen Problem. Das dringende Ticket fehlt nicht, es ist vergraben. Die Lösung ist keine cleverere Sortierregel, sondern eine Schicht, die die Priorität pro Ticket festlegt, statt mit ein paar starren Schlüsselwortfiltern zu arbeiten.
Wir führen KI seit Jahren auf Live-Support-Warteschlangen und haben in eigenen Tests festgestellt, dass diese Triage-Schicht 93 % Triage-Genauigkeit bei echtem Ticket-Traffic erreichte und 100 % des Spams abfing, bevor er überhaupt einen Menschen berührte. Im Folgenden erkläre ich, wie das Ganze funktioniert, wo es leise schiefgehen kann und wie ich es tatsächlich einführen würde.
Was „Tickets mit KI priorisieren" wirklich bedeutet
Die meiste Priorisierung heute ist ein Raten, das als System verkleidet ist. Sie haben ein paar Ticket-Routing-Regeln („Wenn Betreff 'dringend' enthält, markieren"), vielleicht eine VIP-Liste, und einen Agenten, der jeden Morgen die Warteschlange überfliegt und entscheidet, was brennt. Das bricht zusammen, sobald ein Kunde „kurze Frage" im Betreff einer Abrechnungsstreitigkeit schreibt oder ein Ausfall höflich formuliert ankommt.
Das mit KI zu tun bedeutet etwas anderes. Statt Schlüsselwörter abzugleichen, liest das Modell das Ticket tatsächlich so wie ein erfahrener Agent, dann platziert es auf zwei wichtigen Achsen: wie dringend es ist und welche geschäftliche Auswirkung es hat. Das ist der Unterschied zwischen Ticket-Triage, die nach Oberflächenwörtern sortiert, und Priorisierung, die nach Bedeutung sortiert.
Das mentale Modell, auf das ich immer wieder zurückgreife, ist eine einfache Prioritätsmatrix. Wo ein Ticket landet, entscheidet, was mit ihm passieren soll.
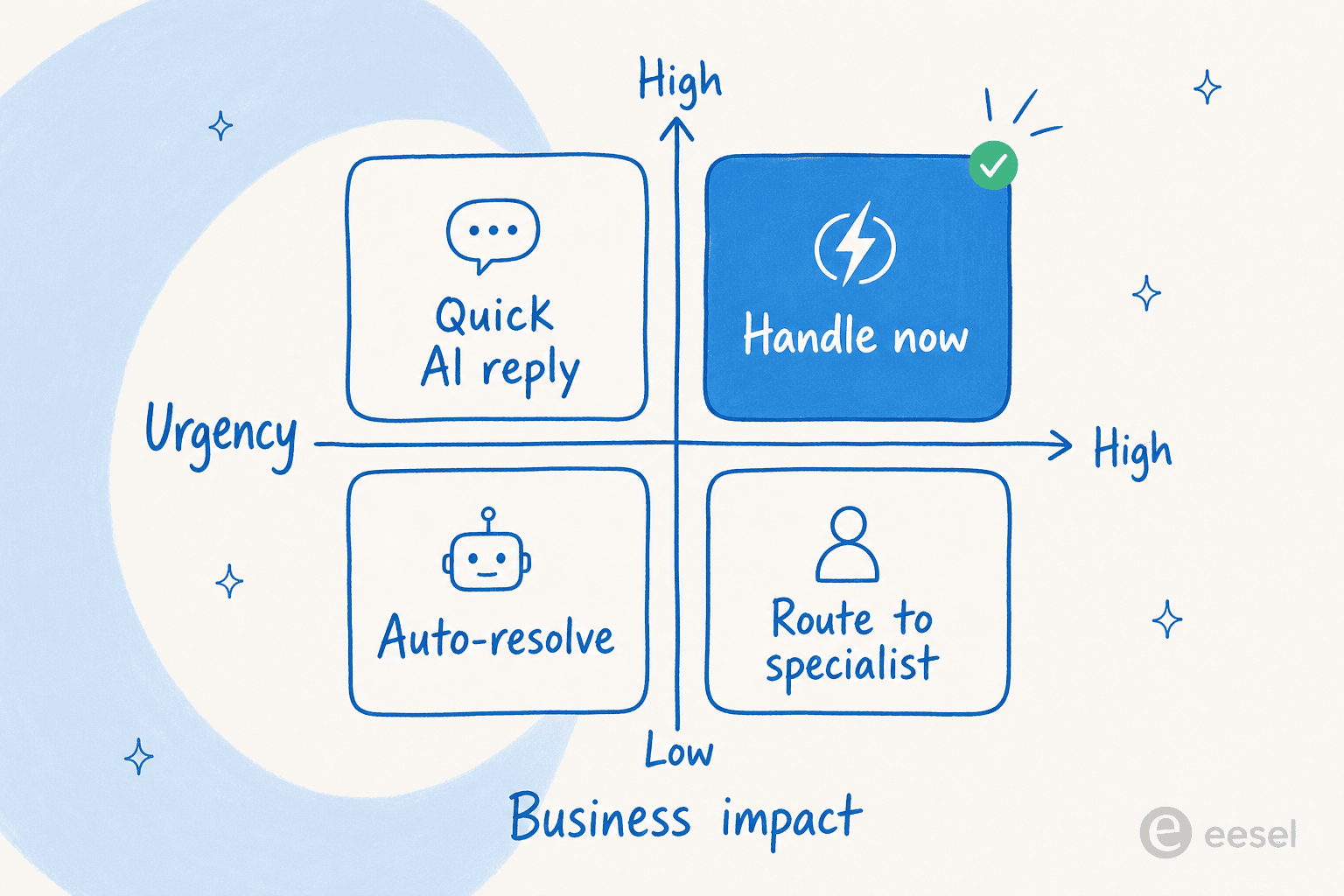
Ein Ticket mit hoher Dringlichkeit und hoher Auswirkung (ein Ausfall bei einem zahlenden Konto) sollte direkt zu einem Menschen gehen. Eines mit geringer Dringlichkeit und geringer Auswirkung (eine Anleitung, die ein Hilfeartikel bereits beantwortet) sollte einen Agenten überhaupt nicht erreichen – es ist ein Kandidat für automatische Lösung. Die zwei unangenehmen Ecken in der Mitte sind dort, wo die KI ihren Wert beweist: das wichtige, aber noch nicht dringende Ticket, das einen Spezialisten braucht, und das lärmende, aber triviale, das nur eine schnelle, korrekte Antwort benötigt.
Wie KI ein Ticket in einem Durchgang priorisiert
Hier ist der Teil, der Menschen überrascht: Klassifizieren, Bewerten und Weiterleiten eines Tickets sind nicht drei separate Aufgaben, die die KI nacheinander ausführt. Ein moderner KI-Helpdesk-Agent tut alles davon sofort, wenn ein Ticket eintrifft, in einem einzigen Lesevorgang.
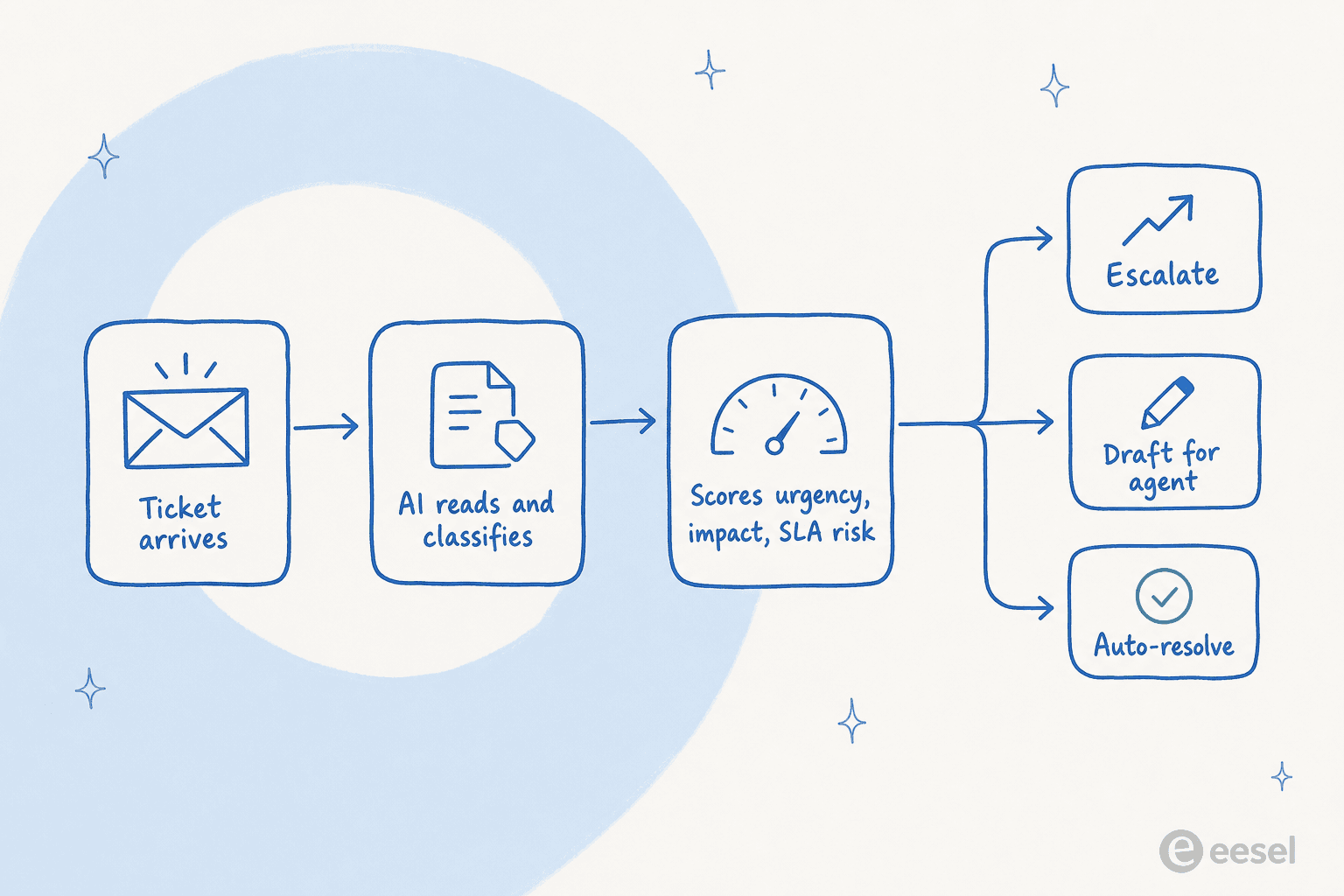
Lassen Sie uns das an einem echten Beispiel durchgehen. Ein Ticket kommt herein: „Immer noch kein Login, das ist das dritte Mal, dass ich schreibe, unser Demo mit dem Vorstand ist in einer Stunde." In einem Durchgang liest der Agent es, klassifiziert es als Zugriffsproblem, erkennt die Dringlichkeitssignale (dritter Kontakt, harte Frist), bewertet die Auswirkung (klingt nach einem Schlüsselkonto) und bemerkt, dass die SLA-Uhr bereits gefährdet ist. Er markiert das Ticket, erhöht die Priorität und eskaliert an einen Menschen mit einer Zusammenfassung – alles bevor jemand den Posteingang öffnet.
Im Vergleich dazu ein Ticket mit geringem Einsatz: „Wie ändere ich mein Profilbild?" Gleicher einziger Durchgang, völlig anderes Ergebnis. Der Agent erkennt eine dokumentierte Anleitung, entwirft oder sendet die Antwort und fügt es nie zum Stapel eines Menschen hinzu. Das ist der Kern der Tier-1-Deflection – die einfachen Tickets werden herausgefiltert, damit in der Agenten-Warteschlange nur noch Dinge landen, die ein Gehirn brauchen.
Die Signale, die eine KI abwägt, sind reichhaltiger als jedes Regelwerk, das Sie manuell erstellen würden: die eigentliche Formulierung und der Ton, die Kontaktanzahl, die Kundenstufe, der Kontowert, das Thema selbst (ein Ausfall schlägt eine Feature-Anfrage) und die bereits verstrichene Zeit. Sie müssen diese Logik nicht pflegen – das Modell leitet sie aus jedem Ticket und Ihren historischen Lösungsmustern ab.
Ausprobieren: Was würde KI mit Ihrem Ticket machen?
Wählen Sie das Ticket, das am ehesten Ihrer chaotischen Montagswarteschlange entspricht, und sehen Sie, wo ein gut eingestellter KI-Agent es einordnen würde. Dies ist eine vereinfachte Version der gleichen Dringlichkeits-plus-Auswirkungslogik von oben.
Das Fazit sind nicht die vier Kategorien – es ist, dass die Entscheidung automatisch, pro Ticket, in dem Moment getroffen wird, in dem es ankommt, anstatt darauf zu warten, dass ein Mensch manuell triage betreibt.
Wo Ticket-Priorisierung leise schiefläuft
Das ist der Teil, den die meisten „Schalten Sie einfach KI ein"-Ratschläge überspringen, und der entscheidet, ob das Projekt den Kontakt mit einer echten Warteschlange überlebt.
Das größte Versagensmuster ist, die KI auf Tickets reagieren zu lassen, bei denen sie sich nicht sicher ist. Wenn sie versucht, alles zu beantworten und bei den schwierigen „Entschuldigung, ich weiß es nicht" sagt, haben Sie gerade eine zweite Warteschlange zum Überprüfen erstellt. Eine CX-Leiterin formulierte den Einwand besser, als ich es könnte:
„Die KI wird nie in der Lage sein, 100 % der Fragen zu beantworten. Aber wenn sie es versucht und nur 'Entschuldigung, ich weiß das nicht' antwortet, kann ich nicht alle meine 7.000 Tickets durchsehen, um zu prüfen, ob die KI tatsächlich eine gute Antwort gegeben hat. Ich brauche eine KI, die nur die Tickets bearbeitet, bei denen sie zuversichtlich ist, und alle anderen in Ruhe lässt."
– eine CX-Leiterin bei einer DTC-Supplements-Marke auf Gorgias, aus einem Verkaufsgespräch über konfidenzbasiertes Routing
Das ist der gesamte Grund für konfidenzbasiertes Routing. Ein guter Agent priorisiert und kennt die Grenzen seiner eigenen Kompetenz: Hohe Konfidenz bedeutet handeln, niedrige Konfidenz bedeutet entwerfen oder an einen Menschen eskalieren. Die Zahl, die wichtig ist, ist nicht „wie viele Tickets hat er angerührt", sondern wie viele er korrekt bearbeitet hat, ohne dass Sie nachprüfen mussten.
Zwei weitere Fallen, die ich häufig sehe:
- Kein Ausschalter für sensible Ticket-Typen. Viele Teams möchten, dass bestimmte Kategorien (rechtliche Drohungen, Kündigungen, alles Regulierte) vollständig von der Automatisierung ferngehalten werden. Sie müssen in der Lage sein zu sagen: „KI berührt diese nie", und die meisten regelbasierten Setups können das nicht sauber ausdrücken. Suchen Sie nach Ticket-Typ-Ausschluss, bevor Sie dem Routing vertrauen.
- Live gehen ohne Tests. Die Priorisierung in einer Live-Warteschlange einzuschalten und zu hoffen, ist der Weg, den Raum zu verlieren. Die Lösung ist, zuerst auf vergangenen Tickets zu simulieren, damit Sie genau sehen, wo die KI falsch priorisiert hätte, und es zu korrigieren, bevor ein Kunde es spürt.
Priorisiert KI tatsächlich richtig?
Berechtigte Frage, und die ehrliche Antwort lautet: nur wenn Sie es messen. Der Grund, warum ich diesem Ansatz vertraue, ist keine Anbieter-Präsentation, sondern das, was auftaucht, wenn Sie einen Agenten auf echten Ticket-Traffic richten und ihn bewerten.
In einem Test mit Live-Zendesk-Traffic für ein mittelgroßes E-Commerce-Team erreichte die KI-Triage-Schicht 93 % Triage-Genauigkeit, fing 100 % des Spams ohne falsch positive Treffer ab (bei einem Posteingang mit 22 % Junk) und produzierte 88 % der Zeit richtungsweisend korrekte Entwürfe.
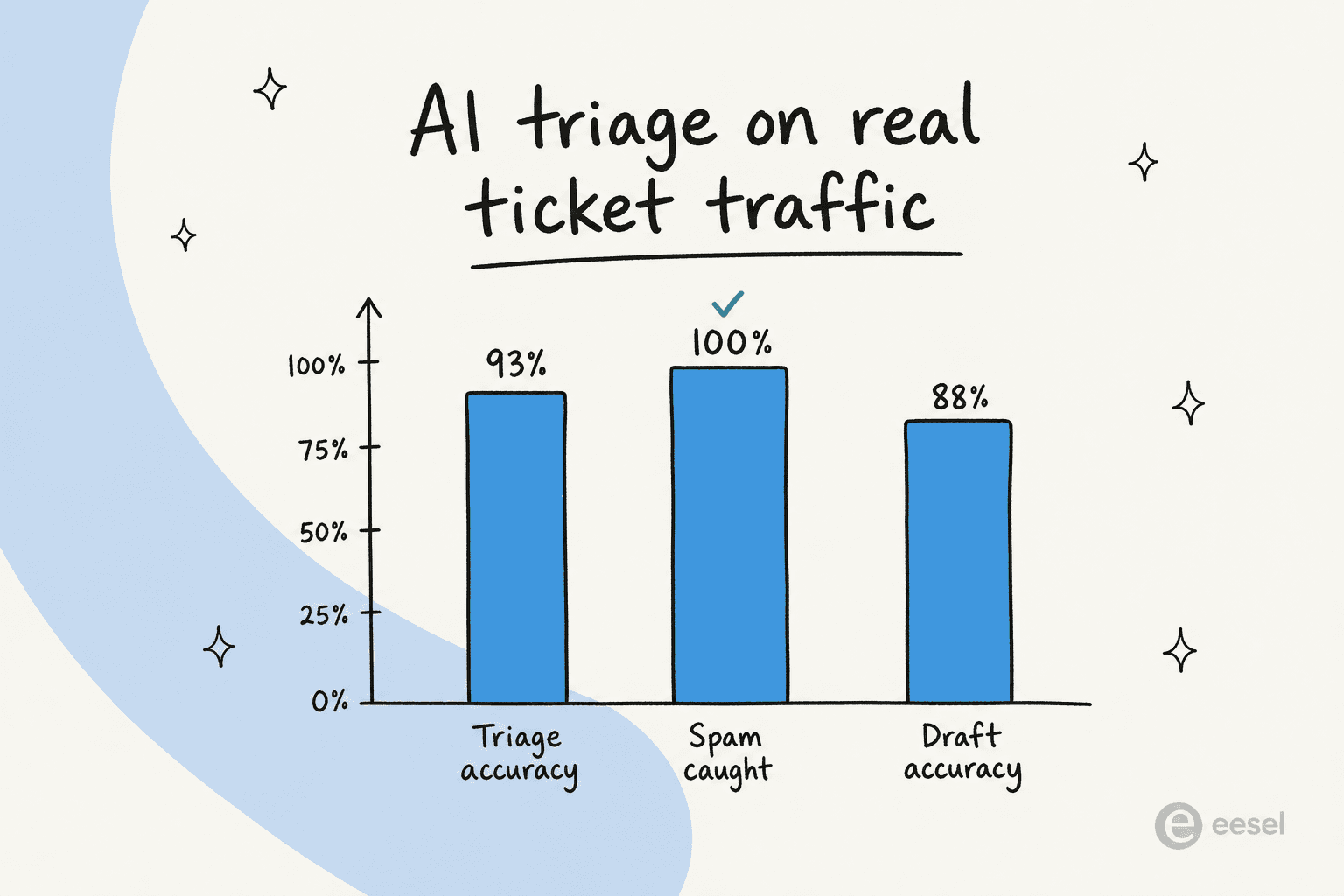
Die Spam- und Triage-Zahlen sind der Priorisierungsgewinn, der sich im Verborgenen zeigt: Ein Fünftel dieser Warteschlange war Lärm, der keinen Menschen brauchte, und die KI zog ihn heraus, bevor er die Aufmerksamkeit jemandes verwässerte. Das ist First-Contact-Resolution und Warteschlangen-Hygiene in einem Schritt.
Das zeigt sich auch in der Produktion. Ein Gig-Economy-Analytics-Team auf Zendesk sagte uns direkt:
„Im ersten Monat löst eesel 73 % unserer Tier-1-Anfragen. Die Plattform enthält sogar Automatisierungen für Ticket-Tagging, Zuweisung und Status-Updates."
– Kim Simpson, Gridwise, auf unserer Helpdesk-Seite
Tagging, Zuweisung, Status – das ist Priorisierung, nur ausgedrückt als Aktionen auf dem Ticket statt als Zahl in einem Feld. Der Sinn der Verfolgung von Resolution-Rate-Metriken und Ihren übergeordneten Kundenservice-Metriken ist, dass Sie beweisen können, dass die Prioritätsentscheidungen richtig waren, nicht nur beschäftigt.
Routing im Helpdesk, den Sie bereits nutzen
Sie müssen Ihren Stack nicht ersetzen, um das zu tun. Die Priorisierungsschicht liegt über dem Helpdesk, den Sie bereits haben, liest Tickets und schreibt Tags, Priorität, Zuweisung und Antworten über dieselbe API zurück, die Ihre Agenten verwenden.
Das Muster ist dasselbe, ob Sie Zendesk, Freshdesk, Gorgias oder HubSpot verwenden. Wenn Sie nach Optionen suchen, schlüsselt die Übersicht der besten KI-Helpdesk-Software und unsere Anmerkungen zu E-Commerce-spezifischen Helpdesks und B2B-Support auf, welche Tools Priorisierung nativ handhaben versus eine zusätzliche Schicht benötigen. Für Zendesk-Teams gibt es einen tieferen Einblick in seine KI-Fähigkeiten und Klassifizierungs-Apps.
Wie ich das tatsächlich einführen würde
Wenn ich das diese Woche von Grund auf einrichten würde, ist die Reihenfolge wichtiger als das Tooling:
- Definieren Sie, was „Priorität" für Ihr Team bedeutet. Schreiben Sie auf, was wirklich vorgezogen werden soll (Ausfälle, Abwanderungsrisiko, VIP-Konten) im Vergleich zu dem, was warten kann. Die KI braucht ein Ziel.
- Verbinden Sie Ihren Helpdesk und Ihr Wissen. Richten Sie es auf vergangene Tickets und Hilfedokumente, damit es Ihre Muster lernt, nicht die Annahmen eines generischen Modells.
- Schalten Sie zuerst die Klassifizierung ein, im Copilot-Modus. Lassen Sie es eine Woche lang taggen und bewerten, ohne zu handeln, und lesen Sie die Ergebnisse.
- Simulieren, dann nach Konfidenz eskalieren. Führen Sie es auf historischen Tickets aus, beheben Sie die Lücken, dann lassen Sie es nur handeln, wo es sicher ist, und übergeben Sie alles andere.
- Erweitern Sie die Autonomie, wenn die Zahlen stimmen. Verfolgen Sie Genauigkeit und Resolution Rate und erweitern Sie nur, was es handhabt, sobald die Daten es rechtfertigen.
Für die vollständige Schritt-für-Schritt-Version mit Screenshots führt unser Leitfaden zur Priorisierung von Tickets mit KI jede Phase im Detail durch, und die KI-Ticket-Triage-Übersicht vergleicht die Tools, die das tun.
eesel für Ticket-Priorisierung ausprobieren
Wenn Sie das ohne eine sechswöchige Einführung möchten, integriert sich eesel AI in Ihren bestehenden Helpdesk, lernt am ersten Tag aus Ihren vergangenen Tickets und beginnt im Hintergrund, Tickets zu klassifizieren, zu bewerten und weiterzuleiten. Die zwei Dinge, die es speziell für die Priorisierung geeignet machen: konfidenzbasiertes Routing, damit es nur handelt, wo es sicher ist, und den Rest für Menschen lässt, sowie ein Simulationsmodus, der Ihre historischen Tickets wiedergibt, damit Sie genau sehen können, wie es priorisiert hätte, bevor ein einzelner Kunde betroffen ist.
Die Preisgestaltung ist nutzungsbasiert (ab 0,40 $ pro Ticket, das die KI bearbeitet, keine Sitzplatzgebühr), und es gibt eine kostenlose Testversion ohne Karte, damit Sie es auf Ihre eigene Warteschlange richten und sehen können, wo es die Dinge hinschickt. Testen Sie eesel und sehen Sie, wie Ihr echter Rückstand aussieht, sobald das Dringende aufhört, sich zu verstecken.