Das 5-%-Problem, das Ihr CSAT-Dashboard nicht zeigt
Hier die ehrliche Version, wie die meisten Support-CSAT-Programme funktionieren: Ein Agent schliesst ein Ticket, eine automatisierte E-Mail wird verschickt, und irgendwo zwischen 2 % und 10 % der Kunden antworten tatsaechlich.
Das ist der gesamte Datensatz, auf dem Ihr Dashboard aufbaut.
Die Kunden, die antworten, sind nicht repraesentativ. Begeisterte Fuersprecher antworten. Wuetende Kritiker antworten. Die grosse, zufriedene Mitte - die Menschen, deren Frage beantwortet wurde, die dachten "gut, das war okay" und weitergezogen sind - antwortet fast nie. Ihre 82 % CSAT sind also in Wirklichkeit eine Momentaufnahme Ihrer lautesten Kunden, gewichtet zu Raendern hin, die Sie nicht immer kontrollieren koennen.
Es wird noch schlimmer. Forschung von Cresta dokumentiert, was Praktiker bereits wissen: Agenten loesen Umfragen oft selektiv aus, nachdem sie bereits eingeschaetzt haben, dass die Stimmung positiv ist. Die Umfrage misst nicht das Support-Erlebnis - sie misst, zu welchen Interaktionen der Agent sich gut genug fuehlte, um danach zu fragen. Das ist keine Metrik; es ist ein kuratiertes Best-of.
"Agents often trigger surveys at their own discretion, often only after they've gauged that sentiment is positive, ultimately distorting reality." - Cresta, The CSAT Mirage
Umfragemuedigkeit verschaerft das Problem. Die Antwortraten sinken mit zunehmendem Volumen. CSAT-Umfragen, die beim Schliessen eines Gespraechs gesendet werden, verlieren die emotionale Textur der Interaktion - die Erinnerung des Kunden verblasst, und beilaeufige Stimmungsfaktoren verfaelschen die Bewertung. Und weil kurze Umfragen an Tiefe verlieren, waehrend lange Umfragen an Teilnehmern verlieren, gibt es innerhalb des herkoemmlichen Formats keine saubere Loesung.
Die Implikation ist wichtig: Wenn sich Ihr Kundenzufriedenheitswert nicht bewegt, liegt das Problem moeglicherweise nicht am Support-Erlebnis. Es koennte an der Messung liegen.
Was KI-CSAT eigentlich ist
Predictive CSAT - auch inferred CSAT, model-scored CSAT oder KI-CSAT genannt - nutzt maschinelles Lernen, um fuer jede Support-Interaktion einen Zufriedenheitswert zu generieren, unabhaengig davon, ob ein Kunde auf eine Umfrage antwortet oder nicht.
Das Modell wird auf historischen Gespraechsdaten trainiert, die mit tatsaechlichen Umfrageantworten gepaart sind. Einmal kalibriert, sagt es die Zufriedenheit mit 80-90 % Genauigkeit gegenueber menschlich verifizierten Bewertungen voraus. Einige Implementierungen erreichen eine Uebereinstimmungsrate von 95 %.
Was das Modell analysiert, faellt in drei Kategorien:
Linguistische und NLP-Signale:
- Sentiment-Verlauf ueber das Gespraech hinweg - nimmt die Frustration zu oder loest sie sich auf?
- Spezifische Sprachmarker: Kuendigungsabsicht, wiederholte Phrasen, Eskalationsanfragen ("lassen Sie mich mit einem Vorgesetzten sprechen")
- Ob die eigentliche Frage des Kunden eine direkte Antwort statt einer Ausweichantwort erhalten hat
- Tonwechsel von der Eroeffnungs- zur Abschlussnachricht
Verhaltens- und Betriebssignale:
- Anzahl der Agentenuebergaben - jede Neuzuweisung verringert die Zufriedenheit messbar
- Reaktionsgeschwindigkeit und Wartezeiten im Verhaeltnis zu den Kundenerwartungen
- Ob der Kunde innerhalb von 7 Tagen erneut den Support kontaktiert hat (ein starkes Churn-Signal)
- Ob der Kunde das Gespraech mitten drin ohne Loesung abgebrochen hat
Signale zur Loesungsqualitaet:
- Wurde das Problem tatsaechlich geschlossen oder nur als geloest markiert?
- Hat der Kunde das Problem an irgendeinem Punkt erneut geschildert (Kontextverlust bei der Uebergabe)?
- Hat der Agent die Situation des Kunden anerkannt, bevor er zu Loesungen ueberging?
Einige Plattformen bewerten in Echtzeit waehrend des Gespraechs - sie loesen Supervisor-Warnungen aus, wenn Frustration oder Kuendigungsabsicht stark ansteigen, und ermoeglichen so ein Eingreifen vor der Eskalation. Andere bewerten im Batch nach Abschluss. So oder so ist das Ergebnis eine Zufriedenheitsschaetzung fuer jede einzelne Interaktion, nicht eine 5-%-Stichprobe.
Ein konkretes Beispiel fuer den Unterschied im Massstab: Ein grosses Gesundheitsunternehmen ging von der Bewertung von 5 % der Support-Anrufe zu 100 % Anrufbewertung ueber, nachdem es KI-QA-Tools eingefuehrt hatte - und begann sofort, Erkenntnisse auf Musterebene aufzudecken, die einzelne Anrufpruefungen nie offengelegt hatten. Nicht weil der Support ueber Nacht dramatisch besser wurde, sondern weil sie endlich alles sehen konnten.
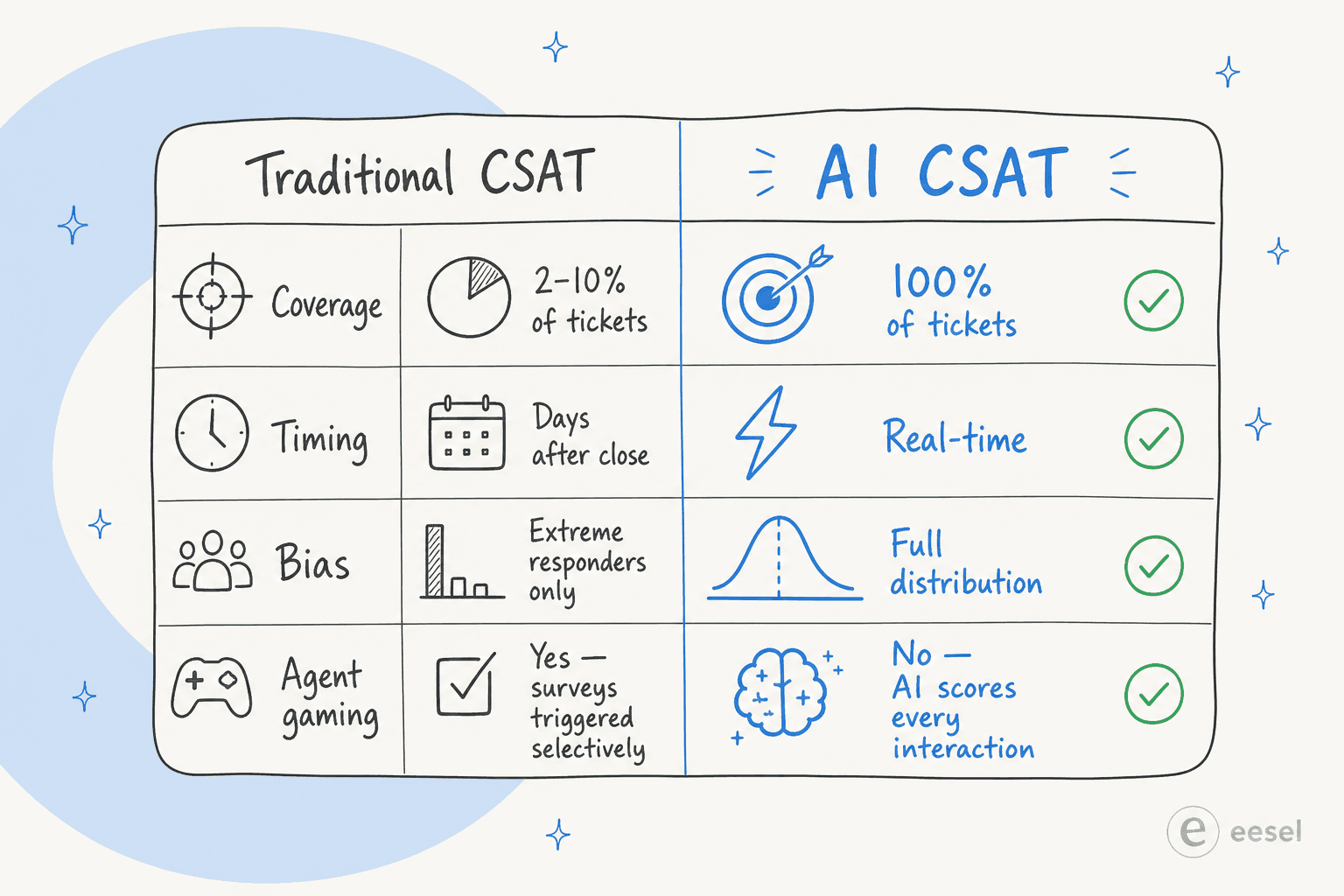
Der vollstaendige Analyse-Stack: Metriken, die KI ueber CSAT hinaus sichtbar macht
CSAT ist die Schlagzeilenzahl. Die Metriken, die erklaeren, warum CSAT so ist, wie er ist - und was man tatsaechlich aendern sollte - sind diejenigen, die KI automatisch sichtbar macht.
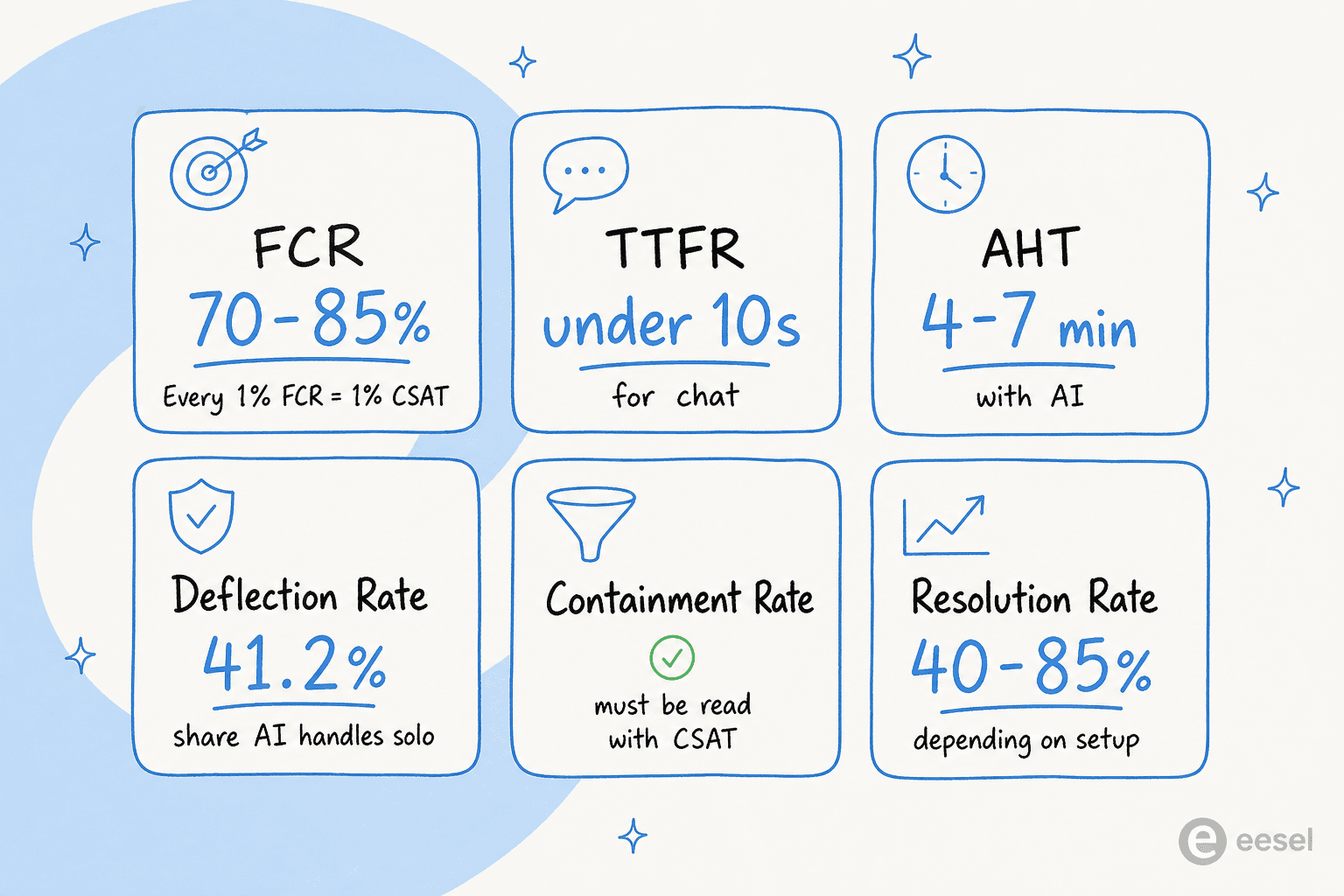
First Contact Resolution: der staerkste CSAT-Praediktor
FCR misst, ob das Problem eines Kunden beim ersten Versuch geloest wurde, ohne dass ein Folgekontakt erforderlich war. Der Zusammenhang mit CSAT ist nahezu linear: Jede Verbesserung der FCR um 1 % bringt etwa 1 % CSAT-Verbesserung - die Forschung der SQM Group belegt dies branchen- und bereichsuebergreifend konsistent.
Der Branchen-Benchmark fuer FCR liegt bei 70-79 % fuer den allgemeinen Support, wobei Spitzenreiter 85 % erreichen. KI bewegt diese Zahl, indem sie die Grundursachen fuer Wiederholungskontakte beseitigt: Die 24/7-Verfuegbarkeit beseitigt die "Ich rufe waehrend der Geschaeftszeiten zurueck"-Schleife; konsistente, wissensgestuetzte Antworten beseitigen das "Letztes Mal habe ich eine andere Antwort bekommen"-Problem; korrektes Ticket-Triage sorgt dafuer, dass das richtige Team das Ticket zuerst erhaelt.
Die FCR vor KI liegt typischerweise bei 60-75 %. Die FCR nach KI liegt bei 70-85 %, bei einigen Implementierungen hoeher, abhaengig von der Ticketkomplexitaet und der Qualitaet der Wissensdatenbank.
Zeit bis zur ersten Antwort
Die Zeit bis zur ersten Antwort (TTFR) ist, wie lange ein Kunde wartet, bevor er irgendeine Rueckmeldung erhaelt. Die durchschnittliche Reaktionszeit beim E-Mail-Support betraegt 12 Stunden 10 Minuten - aber Kunden erwarten unter 4 Stunden bei B2B-E-Mail und unter 10 Sekunden beim Live-Chat. Bei 5-10 Sekunden erreicht der Live-Chat-CSAT 84,7 %. Ueber 30 Sekunden hinaus faellt er stark ab.
KI beseitigt diese Luecke fuer automatisierte Kanaele vollstaendig: Die erste Antwort kommt in Sekunden. Fuer von Menschen gepruefte Warteschlangen verkuerzen KI-gestuetztes Ticket-Triage und Ticket-Zusammenfassung die Kontextwechselzeit, bevor ein Mensch antwortet.
Durchschnittliche Bearbeitungszeit
AHT umfasst das gesamte Loesungsfenster: Gespraechs- oder Chatzeit, Wartezeit und Nachbearbeitung nach der Interaktion. Allgemeine Support-Benchmarks liegen vor KI bei 6-10 Minuten; KI-gestuetzter Support landet typischerweise bei 4-7 Minuten; vollstaendig KI-native Ticketloesung liegt unter 3 Minuten.
Eine Nuance, die man kennen sollte: AHT steigt anfangs, wenn KI erstmals eingefuehrt wird, weil die KI einfache Tickets uebernimmt und den Menschen die schwierigeren ueberlaesst. Ueber eine Anlaufphase von 60-90 Tagen sinkt die AHT, da Agenten KI-generierten Kontext und Antwortentwuerfe auch fuer die verbleibenden komplexen Tickets erhalten. KI-gestuetzter Support verbessert den Durchsatz um 13,8 % mehr Anfragen pro Stunde; eine kombinierte KI-Implementierung am Anfang und am Ende des Gespraechs erreicht bei Reife eine AHT-Reduktion von 25-50 %.
Deflection-Rate
Die Deflection-Rate misst den Anteil der Support-Anfragen, die vollstaendig von KI oder Self-Service bearbeitet werden und nie einen menschlichen Agenten erreichen. Anbieterangaben liegen tendenziell bei 70-80 % Deflection. Unabhaengige Zendesk-Benchmark-Daten sind fundierter: Die mediane Deflection-Rate betraegt 41,2 %, das obere Quartil liegt bei 58,7 % und das untere Quartil bei 22,4 %. E-Commerce und Telekommunikation liegen hoeher; B2B-SaaS und Fintech niedriger, weil die Tickets schwieriger sind.
Die Deflection-Rate ist wichtig fuer die Kosten pro Loesung. KI-Loesungen kosten im Schnitt rund 0,62 $ gegenueber 7,40 $ fuer von Menschen bearbeitete Tickets. Aber lesen Sie sie neben dem CSAT - hohe Deflection bei sinkendem CSAT bedeutet, dass die KI Tickets schliesst, ohne sie zu loesen.
Containment-Rate
Die Containment-Rate ist der Anteil der Gespraeche, die mit KI beginnen und abgeschlossen werden, ohne an einen Menschen zu eskalieren. Der Zielbereich fuer KI-gestuetzten Support liegt bei 70-90 %.
Die Falle: Die Containment-Rate allein ist eine Vanity-Metrik. Ein Bot, der verwirrte Kunden zum Aufgeben draengt, hat 100 % Containment und einen katastrophalen CSAT. Containment bedeutet nur dann etwas, wenn es neben Loesungsqualitaet und CSAT gelesen wird. Wenn Containment steigt und CSAT steigt, loest die KI Probleme. Wenn Containment steigt und CSAT faellt, blockiert die KI den Zugang zur Hilfe.
Loesungsrate
Die Loesungsrate ist der Anteil der Tickets, die die KI korrekt loest - nicht nur schliesst, sondern tatsaechlich loest. Ein realistischer Ausgangspunkt liegt fuer die meisten Implementierungen bei 40-50 %; fortgeschrittene Systeme mit gut organisierten Wissensdatenbanken und abgestimmten Eskalationsregeln erreichen 70-85 %.
Dies ist die Metrik, mit der ehrliche KI-Anbieter fuehren. Gridwise, eine Fahreranalyse-Plattform fuer die Gig-Economy auf Zendesk, berichtete, dass eesel im ersten Monat 73 % ihrer Tier-1-Anfragen loeste - mit Ergebnissen, die innerhalb einer 7-Tage-Testphase sichtbar wurden.
"In the first month, eesel is resolving 73% of our tier 1 requests. Our team implemented and achieved results quickly during our 7-day trial. Responses are simple to fix and adjust. The platform even includes automations for ticket tagging, assignment, and status updates!"
Kim Simpson, Gridwise (G2 review)
Wie KI die CSAT-Zahl tatsaechlich bewegt
Den CSAT genauer zu messen, verbessert ihn nicht von selbst. Was den CSAT verbessert, ist das, was KI mit dem Support-Erlebnis selbst macht.
Schnellere Reaktionszeit ist der direkteste Hebel. Kunden, die unter 10 Sekunden auf eine erste Antwort warten, bewerten ihr Erlebnis 8-14 Punkte hoeher als Kunden, die 30+ Sekunden warten. Die KI-Erstantwort beseitigt Wartezeiten auf automatisierten Kanaelen, und KI-Antwortentwuerfe verkuerzen die menschliche Reaktionszeit beim Rest.
Konsistente, korrekte Antworten beseitigen den Wiederholungskontakt-Zyklus, der FCR und CSAT gleichzeitig zerstoert. Wenn jeder Agent - und jede KI - aus derselben Wissensdatenbank schoepft und dieselben Eskalationsregeln anwendet, hoeren Kunden auf, widerspruechliche Informationen zu erhalten. KI-Ticketklassifizierung und intelligentes Triage bringen Tickets schneller zum richtigen Team und reduzieren das "Herumgereicht-werden"-Erlebnis, das die Zufriedenheit ruiniert.
Warme Eskalationen - KI-Chat-Eskalation, die den vollstaendigen Gespraechsverlauf, den Kundenkontext und eine KI-generierte Zusammenfassung an den uebernehmenden Menschen weitergibt - verhindern den haeufigsten CSAT-Killer im hybriden Support: gezwungen zu sein, das Problem einer neuen Person erneut zu erklaeren. Forschung zeigt durchgaengig, dass Kunden, die eine warme Uebergabe erhalten, die menschliche Interaktion hoeher bewerten als Kunden, die bei gleicher Loesungsqualitaet eine kalte Weiterleitung erhielten.
Mustererkennung im grossen Massstab ist die Erkenntnisschicht, die herkoemmliches CSAT nicht liefern kann. Wenn KI 100 % der Interaktionen bewertet, koennen Sie sehen, dass eine bestimmte Produktkategorie dreimal so haeufig Frustration erzeugt wie andere - dass 40 % der Eskalationen auftreten, weil die KI nicht weiss, wie sie Rueckerstattungsstreitigkeiten ueber 100 $ behandeln soll, oder welche Agenten Tickets schnell schliessen, aber die meisten Wiedereroeffnungen erzeugen. Nichts davon ist in einer 5-%-Stichprobe sichtbar.
"eesel AI streamlines our workflow, boosts productivity, and ensures a higher level of service consistency." - Melissa Ryan, Zendesk Administrator, Discuss.io (Zendesk Marketplace review)

KI-CSAT-Analysen in den grossen Helpdesks
Zendesk
Die nativen Analysen von Zendesk leben in Zendesk Explore, das CSAT-Messung und -Reporting, erste Antwortzeit, Ticketvolumen und Loesungsraten von KI-Agenten sichtbar macht. Sie koennen geplante Berichte und E-Mail-Zustellung konfigurieren und berechnete Metriken ueber das Dashboard hinweg erstellen. Zendesk-Leistungsmetriken - einschliesslich erster Antwortzeit und geloester Tickets - werden alle nativ ueber Explore sichtbar.
Wo Explore zu kurz greift: Es generiert kein Predictive CSAT, macht keine Eskalationsqualitaet sichtbar und zeigt keine nach Tickettyp aufgeschluesselte Loesungsqualitaet. Zendesk-KI-Agenten-Analysen decken einen Teil davon fuer die native Zendesk-KI ab, aber Drittanbieter-Integrationen erweitern das Bild erheblich. Zendesk-KI-Agenten-Metriken zur Verfolgung automatisierter Loesungen und Eskalationsregeln liefern die Eingaben; das Dashboard von eesel kombiniert sie mit der Bewertung der Loesungsqualitaet in einer einzigen Ansicht.
Freshdesk
Die Freddy AI von Freshdesk uebernimmt grundlegende Analysen ueber ihr natives Reports-Modul - CSAT-Werte, Ticketvolumen, erste Antwortzeit und Loesungszeit sind alle verfuegbar. Freshdesk-Freddy-AI-Preise sind an die Copilot- und Autopilot-Stufen gebunden, wobei die Analysetiefe mit hoeheren Plan-Stufen zunimmt.
Die Einschraenkung aehnelt der von Zendesk: Freddy Analytics zeigt, was passiert ist, nicht warum. Bewertung der Loesungsqualitaet und Predictive CSAT sind nicht nativ verfuegbar. Einen fortgeschrittenen KI-Agenten mit Freshdesk zu verbinden ist der Weg zu umfangreicheren Analysen - das Loesungs-Tracking von eesel setzt auf die nativen Daten von Freshdesk auf, statt sie zu ersetzen.
Gorgias
Die Analysen von Gorgias konzentrieren sich auf E-Commerce-Metriken: dem Support zugeschriebener Umsatz, CSAT aus Umfragen nach der Interaktion und Automatisierungsrate - der Anteil der Tickets, die ohne menschliches Eingreifen bearbeitet werden. Gorgias AI Agent 2.0 hat mehr Metriken fuer automatisierte Tickets hinzugefuegt, aber Predictive-CSAT-Scoring ist nicht Teil der nativen Suite.
Fuer E-Commerce-Helpdesk-Teams, die den vollstaendigen Analyse-Stack wollen, traegt die Integration von eesel das Tracking der Loesungsqualitaet und die Containment-Rate-plus-CSAT-Ansicht, die die nativen Berichte von Gorgias nicht liefern.
Die Metriken zusammen lesen: die Falle, in die die meisten Teams tappen
Hier laufen die meisten KI-Support-Implementierungen schief: Sie optimieren auf eine Metrik und beschaedigen eine andere.
Hohe Deflection, sinkender CSAT - die KI bearbeitet Tickets, befriedigt aber keine Kunden. Haeufige Ursachen sind Wissensluecken (selbstbewusste, aber falsche Antworten), fehlende Eskalationsausloeser (Tickets, die Menschen erreichen sollten, bleiben bei der KI) oder Chatbot-Eskalations-Fehler, bei denen Kontext bei der Uebergabe verloren geht.
Verbesserte AHT, gleichbleibende FCR - die KI hilft Agenten, schneller zu arbeiten, aber die zugrunde liegenden Routing-Probleme bedeuten, dass Kunden trotzdem erneut Kontakt aufnehmen. Routing und Vollstaendigkeit der Wissensdatenbank zu beheben ist wichtiger, als Sekunden bei der Bearbeitungszeit einzusparen.
Steigendes Containment, unbekannter CSAT - die gefaehrlichste Kombination. Wenn die KI Gespraeche abschliesst, der Kunde aber frustriert ging, ohne zu eskalieren, haben Sie kein Signal. Genau hier fuellt KI-CSAT-Scoring die Luecke - es deckt das Schweigen ab, das sonst als "keine Beschwerde, muss in Ordnung gewesen sein" registriert wuerde.
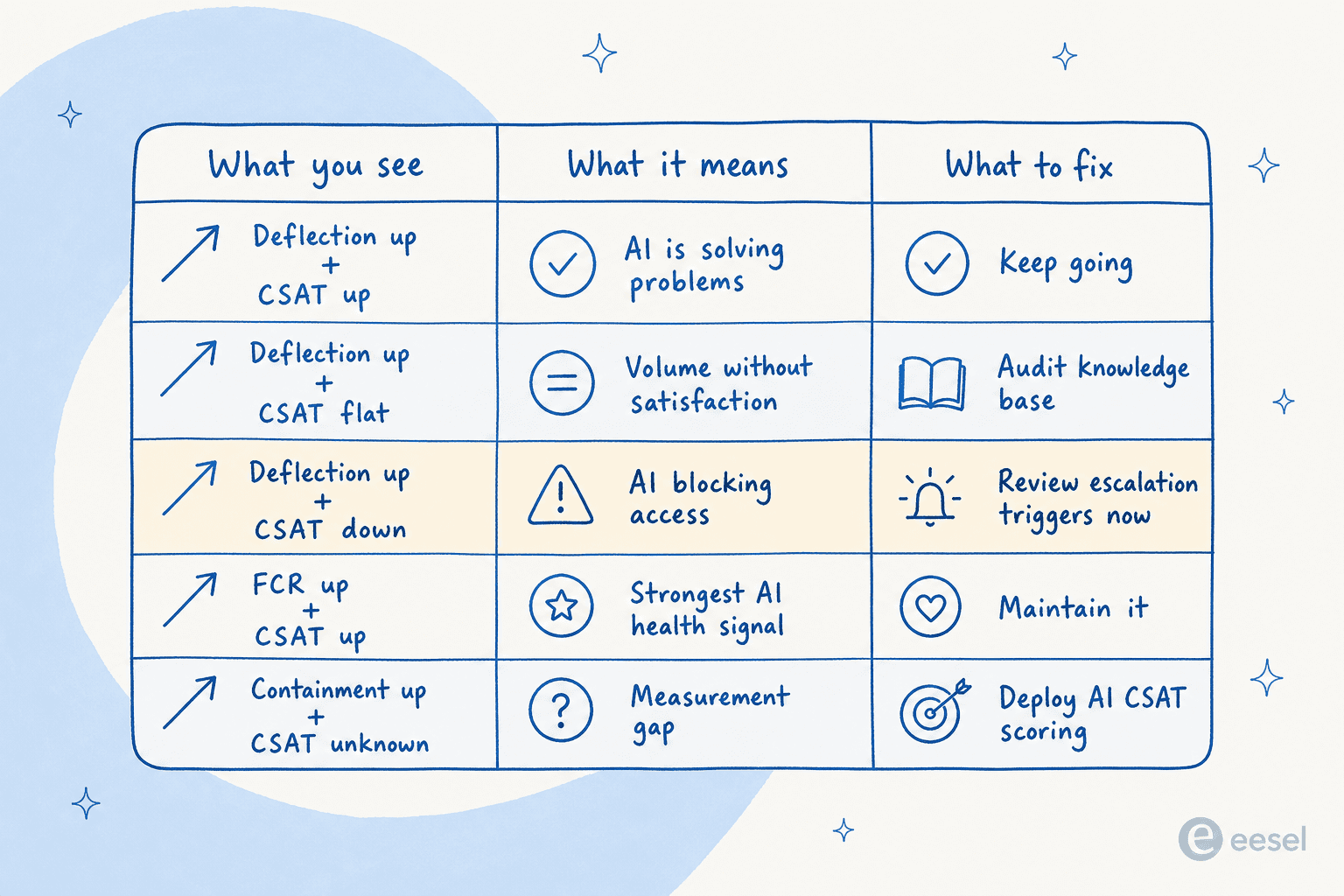
So lesen Sie die Signale zusammen:
| Was Sie sehen | Was es bedeutet | Was zu beheben ist |
|---|---|---|
| Deflection hoch + CSAT hoch | KI loest Probleme | Weitermachen; Eskalationsschwellen verfeinern |
| Deflection hoch + CSAT gleichbleibend | KI bewaeltigt Volumen, nicht Zufriedenheit | Wissensdatenbank pruefen; Konfidenzschwellen abstimmen |
| Deflection hoch + CSAT runter | KI blockiert den Zugang zu Menschen | Eskalationsausloeser sofort ueberpruefen |
| FCR hoch + CSAT hoch | Staerkstes Signal fuer KI-Gesundheit | Dokumentieren, was funktioniert; beibehalten |
| AHT runter + Wiedereroeffnungen hoch | Agenten schliessen Tickets vorzeitig | Schliesskriterien ueberpruefen |
| Containment hoch + CSAT unbekannt | Messluecke | KI-CSAT-Scoring einsetzen, um sie zu fuellen |
Der Vergleich der Kosten pro Loesung ergibt nur in diesem Kontext Sinn. Eine KI, die 60 % der Tickets zu 0,62 $ pro Loesung abwehrt, sieht hervorragend aus, bis Sie feststellen, dass die Wiederkontaktrate bei 40 % liegt - was bedeutet, dass diese "geloesten" Tickets nachgelagert mehr von Menschen bearbeitete Arbeit erzeugen.
Die andere haeufige Falle ist, KI vs. menschlicher Kundensupport als Entweder-oder zu lesen. Die besten Kundenservice-KI-Plattformen nutzen KI, um Volumen zu bewaeltigen und konsistente Grundlinien zu halten, und Menschen fuer komplexe, mit hohem Einsatz verbundene, emotional aufgeladene Tickets - bei denen der Vergleich der Kosten von KI-Agent vs. menschlichem Agent zusammenbricht, weil die menschliche Interaktion wirklich wichtig ist.
Drei Dinge, die KI-CSAT tatsaechlich bewegen
1. Priorisieren Sie FCR ueber Containment.
Jede FCR-Verbesserung um 1 % bringt 1 % CSAT. Die Containment-Rate ist eine Eingabe; CSAT ist die Ausgabe. Stellen Sie Ihre Routing-Regeln, Ihre Wissensdatenbank und Ihre Eskalationsschwellen so ein, dass korrekte Loesungen beim ersten Versuch maximiert werden - nicht, um Gespraeche im Bot zu halten. KI fuer Tier-1-Support-Deflection funktioniert nur dann als CSAT-Treiber, wenn die abgewehrten Tickets von vornherein wirklich von KI loesbar waren.
2. Pruefen Sie die Eskalationsqualitaet, nicht nur die Eskalationsrate.
KI-Chat-Eskalation ist der Punkt, an dem CSAT in hybriden Implementierungen gewonnen oder verloren wird. Eine saubere Eskalation mit vollem Kontext stellt die Kundenzufriedenheit selbst nach einer frustrierenden KI-Interaktion wieder her. Eine kalte Weiterleitung, die den Kontext verliert, vervielfacht die Frustration. Die Eskalationsqualitaet getrennt von der Eskalationsrate zu verfolgen, sagt Ihnen, ob Ihre Uebergaben funktionieren. Die besten KI-Agenten-Assistenz-Tools machen dies als Dashboard-Metrik sichtbar, nicht als etwas, das Sie manuell berechnen.
3. Nutzen Sie KI-CSAT, um die Tickets zu finden, die Sie nie manuell pruefen wuerden.
Wenn KI 100 % der Interaktionen bewertet, treten Ausreisser automatisch zutage - die Ticketkategorie, die dreimal so viel Unzufriedenheit erzeugt wie der Durchschnitt, der Wissensartikel, der selbstbewusste falsche Antworten produziert, der Agenten-Workflow, der durchgaengig zu Wiedereroeffnungen fuehrt. Support-Ticket-Analyse in diesem Massstab ist nur praktikabel, wenn KI das Scoring uebernimmt. Die besten KI-Kundensupport-Chatbots machen dies zunehmend als automatisierte Alarmierung sichtbar - wenn der CSAT einer Kategorie unter einen Schwellenwert faellt, kennzeichnet das System dies, bevor es zu einem Churn-Problem wird.
eesel ausprobieren
eesel ist ein KI-Teamkollege fuer den Kundenservice, der Tickets loest, Analysen sichtbar macht und die Loesungsqualitaet misst - ohne ein separates Analysetool zu erfordern. Das integrierte Reports-Dashboard zeigt Loesungsrate, Ticketqualitaet, Interaktionsvolumen und Aktivitaetsprotokolle ueber alle verbundenen Kanaele hinweg: Zendesk, Freshdesk, Gorgias, Slack, E-Mail, Shopify und 100+ weitere.
Die Einrichtung dauert Minuten statt Monate. Alex Capurro, Chief Innovation Officer bei Global Pay, berichtete von bis zu 80 % Zeitersparnis bei Antworten und Onboarding, nachdem er den AI Copilot von eesel ueber Confluence eingesetzt hatte. Gridwise erreichte im ersten Monat 73 % Tier-1-Loesung. InDebted liegt bei 15 % Ticket-Deflection in ihrem internen IT-Helpdesk mit einem Ziel von 55 %.
Die Analysen sind kein separates Produkt - sie sind das, was die KI generiert, waehrend sie arbeitet. Die Preisgestaltung ist nutzungsbasiert bei 0,40 $ pro Ticket, ohne Plattformgebuehr, ohne Gebuehren pro Platz. Das ergibt 40 $/Monat fuer 100 Tickets oder 400 $/Monat fuer 1.000 - mit Rabatten von 25 % bei Jahresbindung, verfuegbar ab 300 $+/Monat.

Probieren Sie eesel kostenlos aus - 50 $ Nutzungsguthaben, keine Kreditkarte erforderlich, alle Funktionen vom ersten Tag an freigeschaltet.
Haeufig gestellte Fragen
Kann KI mir CSAT und Support-Analysen automatisch liefern?
Was ist ein guter CSAT-Wert fuer den Kundensupport im Jahr 2026?
Wie unterscheidet sich KI-CSAT von herkoemmlichen CSAT-Umfragen?
Welche Support-Analysen kann KI ueber CSAT hinaus erfassen?
Verbessert das Hinzufuegen von KI zum Kundensupport tatsaechlich den CSAT?
Was ist KI-CSAT-Analyse fuer den Kundensupport in Zendesk?
Wie haengen Deflection-Rate und CSAT miteinander zusammen?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.