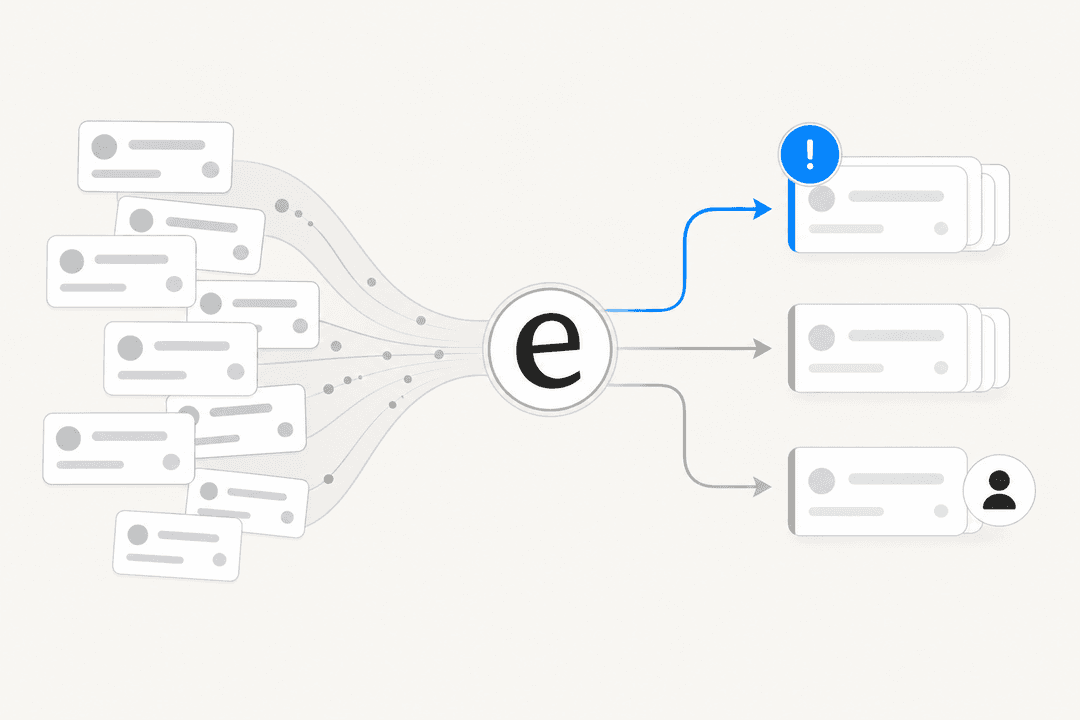
Kann KI Sentiment-Analyse auf Support-Tickets anwenden?
Alicia Kirana Utomo
Katelin Teen
Zuletzt bearbeitet June 21, 2026

Zusammenfassung
Ja, KI kann Sentiment-Analyse auf Support-Tickets anwenden, und Sie besitzen wahrscheinlich schon eine Version davon. Zendesk, Freshdesk, Gorgias, Sprinklr und Salesforce liefern alle ein Feature, das ein Ticket liest und es als positiv, neutral oder negativ kennzeichnet – in der Regel als benutzerdefiniertes Feld, auf das Sie routen und berichten können.
Der ehrliche Haken: Es ist über Tausende von Tickets wirklich zuverlässig, und bei einzelnen Tickets merklich unsicher. Sarkasmus, gemischte Botschaften ("liebe das Produkt, hasse die Wartezeit") und einzeilige Beschwerden sind die Stolpersteine. Der kluge Schritt ist also, den Trend zu nutzen, nicht das Ticket-Label, und einen einzelnen Sentiment-Score niemals automatisch eine Aktion auslösen zu lassen.
Ich baue KI-Agenten, die Live-Support-Tickets bei eesel lesen, und das, was ich jedem sagen würde, der das einschaltet: Simulieren Sie es zuerst auf Ihren eigenen vergangenen Tickets. Der Score, der in einer Demo 90 % richtig aussieht, verhält sich in Ihrem tatsächlichen Posteingang ganz anders.
Kann KI also wirklich lesen, wie sich ein Kunde fühlt?
Kurze Antwort: Ja, und das ist seit einiger Zeit still und leise in die Helpdesk-Tools eingebaut, die Sie verwenden. Die längere Antwort ist der interessante Teil, denn "Sentiment lesen" klingt so, als ob die KI den Kunden versteht – und das ist nicht ganz das, was passiert.
Ich arbeite an der Seite davon, die die meisten Blog-Beiträge überspringen: was das Modell tatsächlich tut, wenn es entscheidet, dass ein Ticket "verärgert" ist. Und der Grund, warum ich vorsichtig damit bin, ist nicht theoretisch. Beim Aufbau von KI für den Helpdesk habe ich beobachtet, wie ein selbstsicher klingendes Modell zehn Runden lang "Zendesk-Suchen ausführt", ohne jemals die API zu berühren, und Ergebnisse berichtet, die schlicht nicht real waren. Sentiment-Scoring hat dieselbe Fehlerform: Es gibt Ihnen ein sauberes, selbstsicheres Label, egal ob es den Kunden tatsächlich richtig eingeschätzt hat. Deshalb simulieren wir es bei eesel zuerst auf historischen Tickets, bevor eine Sentiment-Regel eine Live-Warteschlange berührt, sodass die Fehlerrate in einem Bericht auftaucht, nicht im Posteingang eines wütenden Kunden.
Das Feature ist also real und nützlich. Es ist nur kein Zaubermittel, und die Lücke zwischen diesen beiden Dingen ist, wo Teams verbrannt werden.
Wie KI-Sentiment-Analyse tatsächlich funktioniert
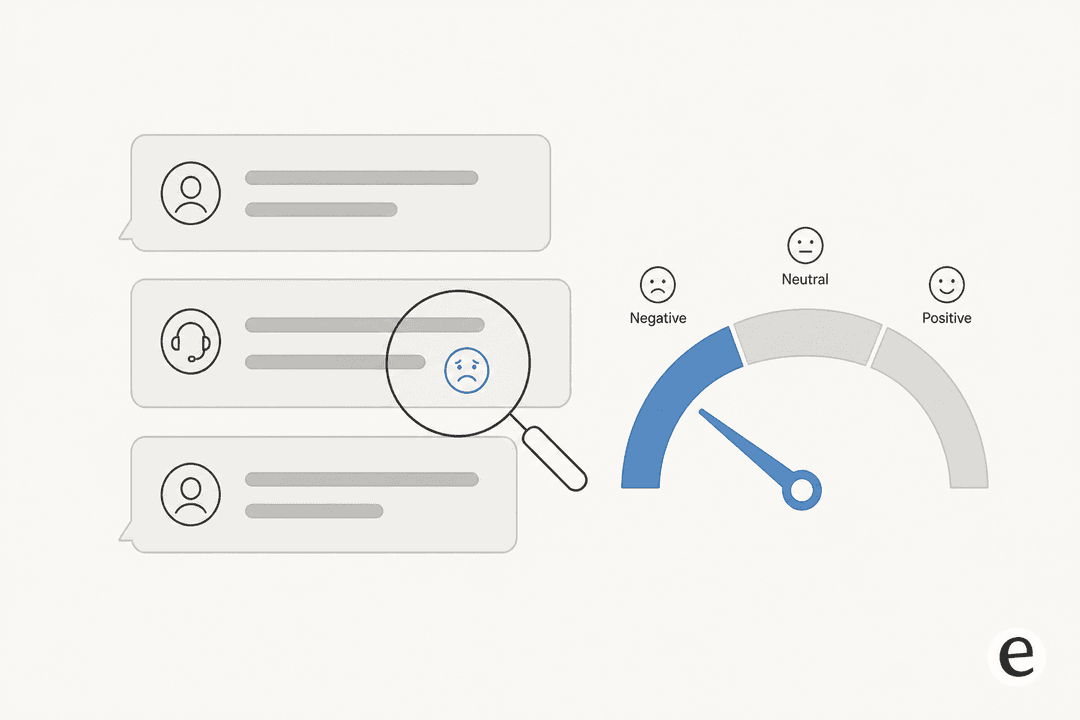
Im Kern ist Sentiment-Analyse ein Textklassifizierungsjob. Das Modell liest die Wörter in einer Nachricht und sortiert sie in einen kleinen Satz von Kategorien – meistens positiv, neutral und negativ. Ältere Systeme taten dies mit einem Lexikon (ein Wörterbuch, das "defekt" als negativ und "danke" als positiv bewertet); moderne verwenden ein transformer-basiertes Modell, das auf beschrifteten Beispielen trainiert wurde, was bei weitem besser darin ist, Wörter im Kontext statt einzeln zu lesen.
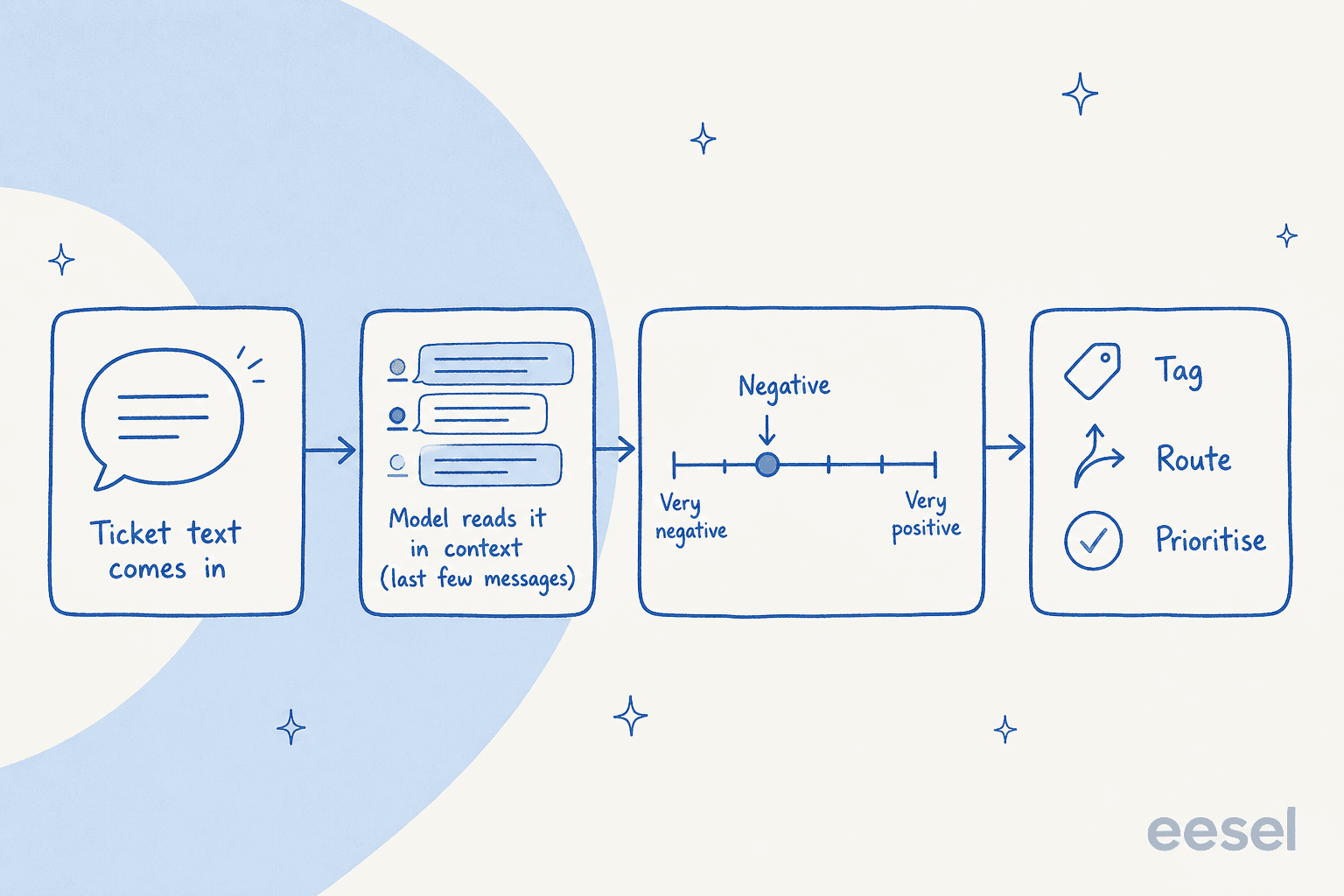
Zwei Details sind wichtiger als der Rest:
Es liest im Kontext, nicht isoliert. Das Sentiment-Modell von Sprinklr bewertet die letzte Nachricht anhand der letzten zehn Nachrichten von beiden Seiten des Gesprächs und tut dies live, während der Chat sich entfaltet, und nicht nachdem der Fall geschlossen wurde. Deshalb kann eine "na gut, wie auch immer"-Antwort als negativ registriert werden, auch wenn die Wörter allein neutral klingen.
Gute sind für Support kalibriert. Das ist das Detail, das ich mir wünsche, dass mehr Käufer kennen würden. Ein naiver Scorer markiert jede Beschwerde als negativ, was nutzlos ist, weil die meisten Tickets Beschwerden sind. Zendesk stimmt sein Modell explizit ab, sodass "einem Ticket nicht einfach deshalb negatives Sentiment zugewiesen wird, weil ein Kunde ein Problem hat." Diese Kalibrierung ist der Unterschied zwischen einem Signal und Rauschen.
Wenn Sie die tiefere Version davon möchten, wie diese Modelle in einen Support-Stack integriert sind, haben wir einen längeren Artikel über KI-Sentiment-Analyse für Support geschrieben, der über die Grundlagen hinausgeht.
Was die großen Helpdesks tatsächlich tun
Hier wird es praktisch. "Sentiment-Analyse" ist keine einheitliche Sache, und die Unterschiede sind wichtig, wenn Sie Regeln darauf aufbauen. Das Label-Set, die Bewertung und sogar welche Tickets bewertet werden, variieren je nach Anbieter.
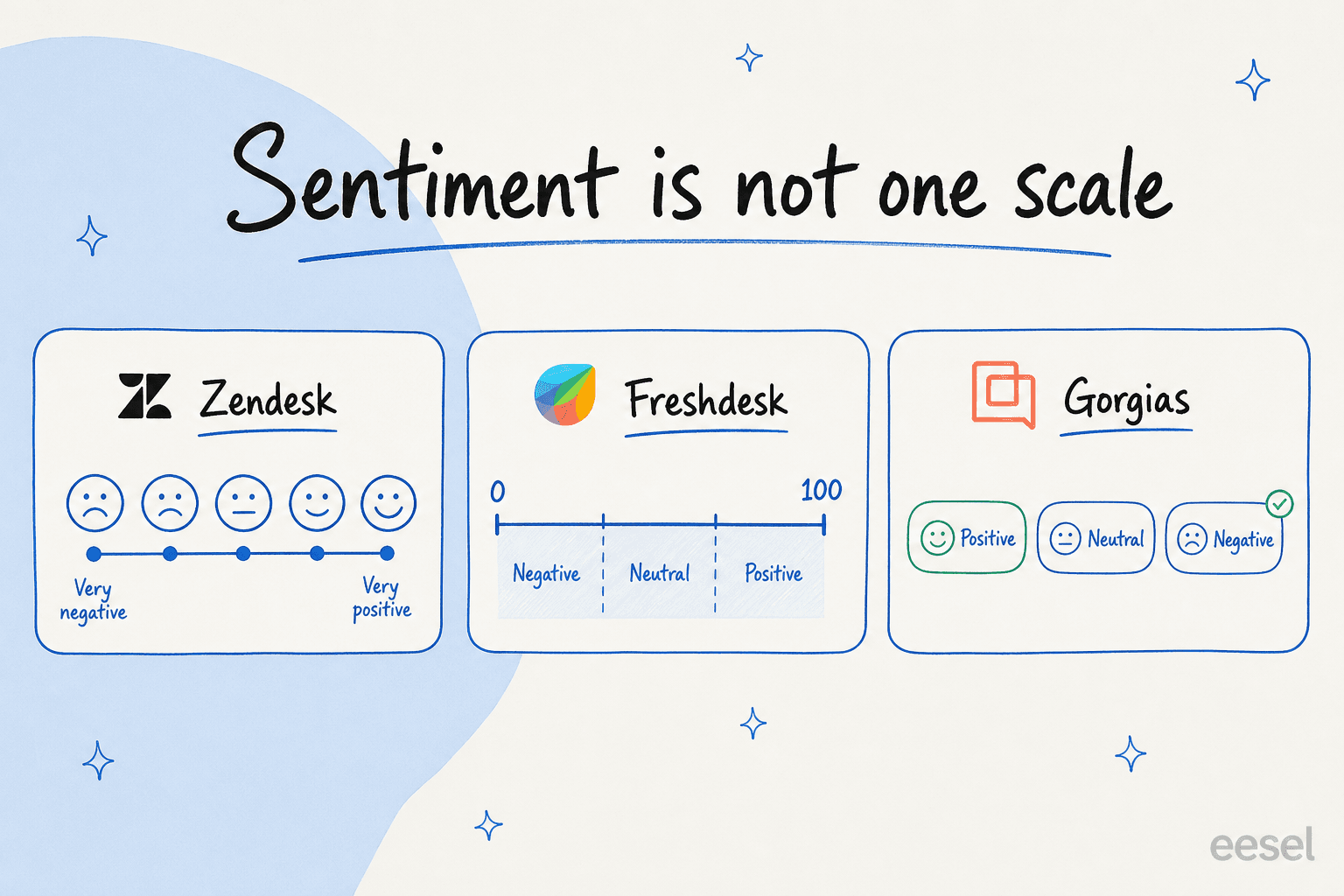
| Tool | Sentiment-Labels | Bewertet auf | Angegebene Grenzen | Plan |
|---|---|---|---|---|
| Zendesk Intelligent Triage | 5 Punkte: Sehr Negativ → Sehr Positiv | Erste Nachricht; aktualisiert bei jeder Antwort | Nur öffentliche Kommentar-Tickets; ~150 Sprachen | Copilot Add-on |
| Freshdesk Freddy | Score 0–100, aufgeteilt in Negativ / Neutral / Positiv | Letzte Kundennachricht | Nur E-Mail- und Portal-Tickets; keine von Agenten erstellten oder Chat-Tickets | Pro / Enterprise / Copilot |
| Gorgias Sentiments | 3 Labels: Positiv / Neutral / Negativ | Jede eingehende Kundennachricht | Ein Sentiment pro Nachricht; nur KI-zugewiesen, nicht bearbeitbar | Enthalten in KI-Plänen |
| Sprinklr | Positiv / Neutral / Negativ | Live, letzte 10 Nachrichten | Transformer-basiert; >80 % Genauigkeit in unterstützten Sprachen | Service-Pläne |
| Salesforce Einstein | Positiv / Negativ / Neutral | Beliebiger Textausschnitt, den Sie übergeben | Trainiert auf 1–2-Satz-Ausschnitte | Einstein-Lizenz |
Ein paar Dinge sind erwähnenswert. Zendesks Fünf-Punkte-Skala ist die granularste der Gruppe, und sie bewertet bei jeder Antwort neu, sodass Sie sehen können, wie ein Ticket in Echtzeit schlechter wird. Freshdesks 0–100-Score ist am besten abstimmbar, läuft aber nur auf E-Mail- und Portal-Tickets, nicht auf von Agenten erstellten. Und Sprinklr gibt an, täglich 10 Milliarden Vorhersagen mit über 80 % Genauigkeit zu machen, was ein nützlicher Realitätscheck dafür ist, wie "gut" aussieht: Ungefähr einer von fünf Treffern ist immer noch falsch.
Ein Mythos, den es zu widerlegen gilt: Nicht jedes Tool hat das. Help Scouts eigene Docs behandeln KI-Antworten, Entwürfe und Zusammenfassungen, dokumentieren aber kein Sentiment-Feature – gehen Sie also nicht davon aus, dass es vorhanden ist. Und während HubSpots Marketing sagt, dass Breeze "Sentiment erkennt", sind die technischen Docs stiller über die Einzelheiten – behandeln Sie das als eine zu verifizierende Behauptung, nicht als Spezifikation. Wenn Sie diese Plattformen abwägen, vergleicht unser KI für Kundenservice-Artikel sie richtig.
Wo Ticket-Sentiment-Analyse versagt
Das ist der Teil, den Anbieter übertünchen, und der Teil, der entscheidet, ob Sie dem Feature in sechs Monaten noch vertrauen werden. Die Fehlerformen sind konsistent und bekannt.
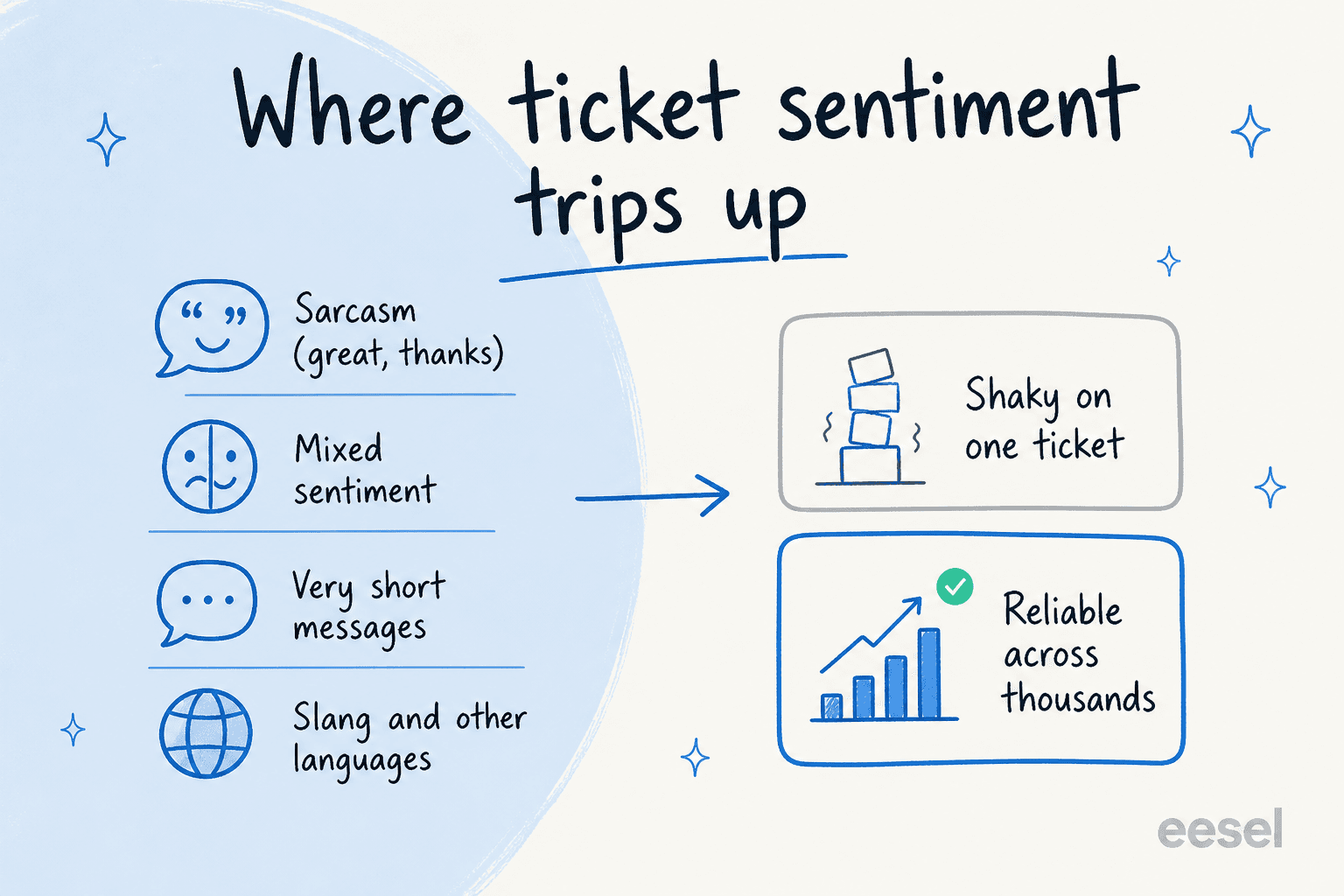
Sarkasmus und Ironie. "Toller Service, wirklich hilfreich" kann das Gegenteil bedeuten, und das Modell kann es meistens nicht erkennen. Wie die Textanalyseforscherin Alyona Medelyan es ausdrückt:
"Jemand sagt 'Toller Service, ja klar!' und der dumme Algorithmus markiert es als positiv... es sei denn, es gibt klare Ironie-Hinweise wie Emoji oder starke Interpunktion, wird die heutige Textanalyse mit Sarkasmus kämpfen."
Ihre Rettung – und ein fairer Punkt – ist, dass Sarkasmus in weniger als 5 % der Kundennachrichten vorkommt, also ist es ein echter Fehler, aber kein fataler.
Gemischtes Sentiment, kurze Nachrichten und andere Sprachen. "Die App ist großartig, aber der Checkout versagt immer wieder" ist wirklich sowohl positiv als auch negativ, und ein einzelnes Label macht es flach. Ein einzeiliges "immer noch kaputt" gibt dem Modell fast nichts zu arbeiten. Und eine Genauigkeit, die auf Englisch stark ist, wird bei Umgangssprache und Redewendungen wackelig – deshalb braucht eine mehrsprachige Warteschlange ihre eigenen Tests.
Die größere Lektion steht über all diesen. Die Gartner-Analystin Jenny Sussin hat es klar gesagt über die Genauigkeit pro Nachricht und nennt Sentiment-Analyse einen Bereich, der "für Kunden und Referenzkunden eine massive Enttäuschung war." Ich lese das weniger als "verwende es nicht" und mehr als "verwende es nicht auf die falsche Weise." Bei einem Ticket ist das Label ein Hinweis. Über zehntausend Tickets hinweg ist der Trend real. Bauen Sie Ihre Erwartungen rund um das Aggregat auf und Sie werden zufrieden sein; bauen Sie eine harte Auto-Aktion auf einem einzelnen Score auf und Sie werden sich irgendwann entschuldigen müssen.
Wofür es wirklich gut ist
Wenn Sie also einem einzelnen Label nicht vertrauen sollten, wofür ist es dann tatsächlich? Für ziemlich viel, sobald Sie es richtig ausrichten.
Verärgerte Tickets priorisieren. Das ist der Killer-Anwendungsfall. Eine Regel, die Tickets mit negativem Sentiment an die Spitze der Warteschlange hebt, bedeutet, dass Ihre verärgersten Kunden am schnellsten einen Menschen erreichen. Es passt natürlich zu Ticket-Triage und Eskalationsmanagement und ist die sauberste ROI-Geschichte für das Feature.
Routing und Eskalation. Sentiment ist eine gute Regelbedingung. Das dokumentierte Muster von Salesforce ist, negative Anfragen ab einem Schwellenwert an einen Supervisor zu eskalieren; Gorgias lässt Sie Sentiment-basiert routen auf dieselbe Weise. Kombinieren Sie es mit KI-Ticket-Tagging und einer Agent-Assist-Schicht, und Sie haben eine Warteschlange, die sich selbst organisiert.
Voice-of-Customer-Trends. Hier glänzt Sentiment, weil das Aggregat genau das ist, was Sie wollen. Ein negativer Sentiment-Spike nach einem Release sagt Ihnen etwas Reales, und es ist die Grundlage solider KI-Kundenfeedback-Analyse. Es arbeitet Hand in Hand mit der KI, die jedes Ticket zusammenfasst, sodass Sie Themen lesen, nicht Transkripte.

Der Anwendungsfall, vor dem ich warnen würde, ist die CSAT- oder Abwanderungsvorhersage. Anbieter listen es gerne als Vorteil auf, aber ein dokumentiertes prädiktives Modell, das Sentiment in einen Abwanderungs-Score umwandelt, ist seltener als das Marketing impliziert. Verwenden Sie Sentiment als ein Signal, das ein Kundenservice-KPI-Dashboard speist, nicht als Kristallkugel.
Wie ich es tatsächlich einrichten würde
Wenn ich das morgen für ein Team einschalten würde, hier ist die Reihenfolge, in der ich es tun würde – und es ist dieselbe Disziplin, die jeden KI-Support-Agenten ehrlich hält.
- Simulieren Sie zuerst auf Ihrer eigenen Geschichte. Führen Sie das Modell über einige Tausend Ihrer vergangenen Tickets aus und lesen Sie die Fehlerrate, bevor es etwas Live berührt. Das ist der eine Schritt, den die meisten Teams überspringen und am meisten bereuen.
- Setzen Sie einen Konfidenzschwellenwert. Handeln Sie automatisch nur auf die Labels, bei denen das Modell sicher ist. Ein Käufer, mit dem ich sprach, fasste die gesamte Philosophie perfekt zusammen. Anonymisiert als DTC-Supplements-CX-Lead sagte sie:
"Die KI wird niemals in der Lage sein, 100 % der Fragen zu beantworten... Ich brauche eine KI, die nur die Tickets bearbeitet, bei denen sie sich sicher ist, und alle anderen in Ruhe lässt."
Das ist auch das richtige mentale Modell für Sentiment: Handeln Sie auf die sicheren Calls, routen Sie den Rest zu einem Menschen.
- Halten Sie einen Menschen für Grenzfälle bereit. Sentiment sollte ändern, wohin ein Ticket geht, nicht ob ein Kunde eine vorgefertigte Antwort bekommt. Verwenden Sie es für Routing und Priorisierung, und lassen Sie Urteilsanrufe bei Menschen.
- Beobachten Sie den Trend, nicht das Ticket. Berichten Sie über aggregiertes Sentiment im Laufe der Zeit. Das ist die Zahl, der Sie wirklich vertrauen können, und die es wert ist, auf Ihr Support-Metriken-Dashboard zu setzen.
Tun Sie diese vier Dinge, und Sentiment-Analyse wird ein leise nützlicher Teil der Warteschlange. Überspringen Sie den ersten, und Sie werden verärgerte Eskalationen debuggen, die das Modell fälschlicherweise als "neutral" markiert hat.
Wo eesel passt
Wenn Sie möchten, dass Sentiment echte Arbeit leistet und nicht nur in einem Feld sitzt, lautet die Frage: "Was passiert nach dem Label?" Das ist der Teil, für den eesel gebaut ist. Es verbindet sich mit Ihrem vorhandenen Helpdesk, liest Tickets so, wie diese Modelle es tun, und dann sagen Sie ihm in normaler Sprache, was mit einem frustrierten Kunden zu tun ist – eskalieren, priorisieren, eine sorgfältige Antwort für einen Menschen zum Senden entwerfen, oder sauber übergeben.
Das Unterscheidungsmerkmal ist das, auf das ich immer wieder zurückkomme: Sie können das Ganze auf Tausenden Ihrer eigenen historischen Tickets simulieren, bevor es live geht, sodass Sie genau sehen, wie es echte Kunden triagiert und geroutet hätte. In einer Studie mit dem echten Zendesk-Traffic eines Kunden zeigte diese Simulation 93 % Triage-Genauigkeit und erkannte 100 % des Spams ohne falsche Positive – die Art von Zahl, der Sie nur vertrauen, weil sie aus ihrem eigenen Posteingang kam, nicht aus einer Demo. Das ist der Unterschied zwischen der Hoffnung, dass das Modell Ihre Kunden richtig versteht, und dem Wissen, dass es das tut.
Sie können eesel kostenlos ausprobieren und es an einem Nachmittag gegen Ihre eigenen Tickets laufen lassen – keine Kreditkarte zum Starten. Wenn Sie speziell auf Zendesk sind, ist unser beste KI für Zendesk-Leitfaden eine gute nächste Lektüre.
Häufig gestellte Fragen
Kann KI Sentiment-Analyse auf Support-Tickets anwenden?
Wie genau ist die KI-Sentiment-Analyse bei Kundentickets?
Was ist die beste KI für Sentiment-Analyse auf Support-Tickets?
Kann KI Sentiment nutzen, um verärgerte Tickets zu priorisieren?
Funktioniert Sentiment-Analyse in mehreren Sprachen?
Kann KI CSAT oder Abwanderung aus Ticket-Sentiment vorhersagen?
Wie richte ich KI-Ticket-Sentiment ein, ohne dass es nach hinten losgeht?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.