So baut man einen Support-Ticket-Rückstand mit KI ab
Riellvriany Indriawan
Katelin Teen
Zuletzt bearbeitet June 22, 2026

Kurzzusammenfassung
Ein Support-Rückstand entsteht fast nie durch schwierige Tickets. Er entsteht durch dieselben einfachen Fragen, die sich schneller anhäufen, als ein kleines Team dieselben Antworten eintippen kann. Der schnellste Weg, ihn abzubauen, besteht deshalb darin, die KI zuerst auf die repetitiven Dinge zu richten – nicht auf die gesamte Warteschlange auf einmal.
So würde ich es kurz machen: Helpdesk verbinden, KI-Agenten von bisherigen Tickets und Hilfedokumenten lernen lassen, ihn gegen die echte Tickethistorie simulieren, um zu sehen, was er gesagt hätte, und ihn dann auf die Handvoll hochkonfidenter Kategorien (Bestellstatus, Erstattungen, Passwortrücksetzungen) loslassen, während jede Ermessensentscheidung weiterhin an einen Menschen geht. Richtig gemacht, leert das den Großteil eines Rückstands, weil der Großteil eines Rückstands aus denselben fünf Fragen besteht.
Die eine Regel, die mehr zählt als alle anderen: Die KI sollte nur Tickets bearbeiten, bei denen sie zuversichtlich ist, und den Rest in Ruhe lassen. Wer das richtig hinbekommt, lässt KI die Warteschlange leeren, ohne die Arbeit nachprüfen zu müssen.
Warum Ihr Rückstand fast sicher abbaubar ist
Ich arbeite in der Support-Warteschlange, also sage ich das Offensichtliche: Ein Rückstand fühlt sich wie ein Berg einzigartiger Probleme an, aber das ist er fast nie. Es ist eine kleine Anzahl von Fragetypen, die hunderte Male wiederholt wurden und sich angehäuft haben, weil es mehr Kunden als Mitarbeiter gab, die sie beantworten konnten.
Das ist genau die Situation, die Rückstände überhaupt erst erzeugt. Ein Support-Direktor bei einem schnell wachsenden EdTech-Unternehmen brachte es auf den Punkt, als er erklärte, warum er auf Automatisierung setzte:
„Als schnell wachsendes Startup mit einem kleinen Team übersteigt die Anzahl unserer Kunden bei weitem die unserer Mitarbeiter. Es ist entscheidend, dass wir robuste Self-Service-Lösungen sowie Tools haben, die die Effizienz unserer kundenseitigen Teams steigern."
Jon Miron, Director of Support, Yellowdig Fallstudie
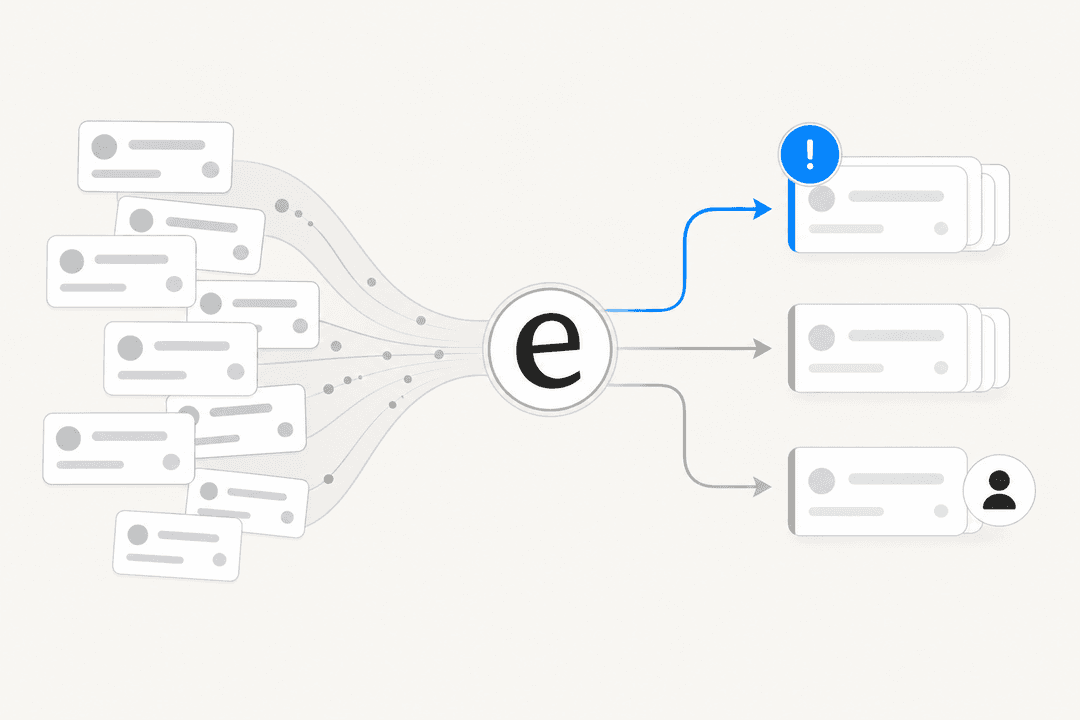
Wenn Kunden Agenten übersteigen, gewinnt die Warteschlange. Und die Tickets, die sie gewinnen lassen, sind selten die kniffligen; es sind die „Wo ist meine Bestellung"- und „Wie setze ich mein Passwort zurück"-Tickets, die jeder KI-Support-Agent aus einem Makro beantworten kann, das man bereits geschrieben hat.
Deshalb bin ich zuversichtlich, dass Ihr Rückstand abbaubar ist, bevor ich ihn überhaupt gesehen habe. Wenn wir uns die Historie eines neuen Kunden ansehen, ist der repetitive Anteil meist enorm. In einem Test mit dem echten Zendesk-Traffic eines deutschen Schmuckhändlers erzielte eesel 93 % Triage-Genauigkeit und 100 % Spam-Erkennung bei rund 1.000 monatlichen Tickets, mit einer Nützlichkeit der Kategorie-Entwürfe von über 93 % für Retouren, Erstattungen und Produktfragen. Das ist der Teil der Warteschlange, den KI zum Frühstück isst.
Bevor Sie beginnen: Was Sie brauchen
Sie brauchen kein Data-Team oder ein sechswöchiges Projekt. Sie brauchen drei Dinge:
- Ein Helpdesk, in den die KI eingebunden werden kann. Zendesk, Freshdesk, Gorgias, Help Scout oder was auch immer Sie nutzen. Wenn Sie noch keinen haben, hier ist eine Übersicht der KI-Helpdesk-Software für 2026.
- Ihre vorhandenen Antworten. Bisherige Tickets, Makros oder gespeicherte Antworten und Hilfecenter-Artikel. Das ist das Trainingsmaterial der KI, und es ist das Meistgewünschte, was ich von Kunden höre: Menschen wollen den Agenten auf ihrer eigenen Tickethistorie trainiert sehen, nicht auf einem generischen Modell.
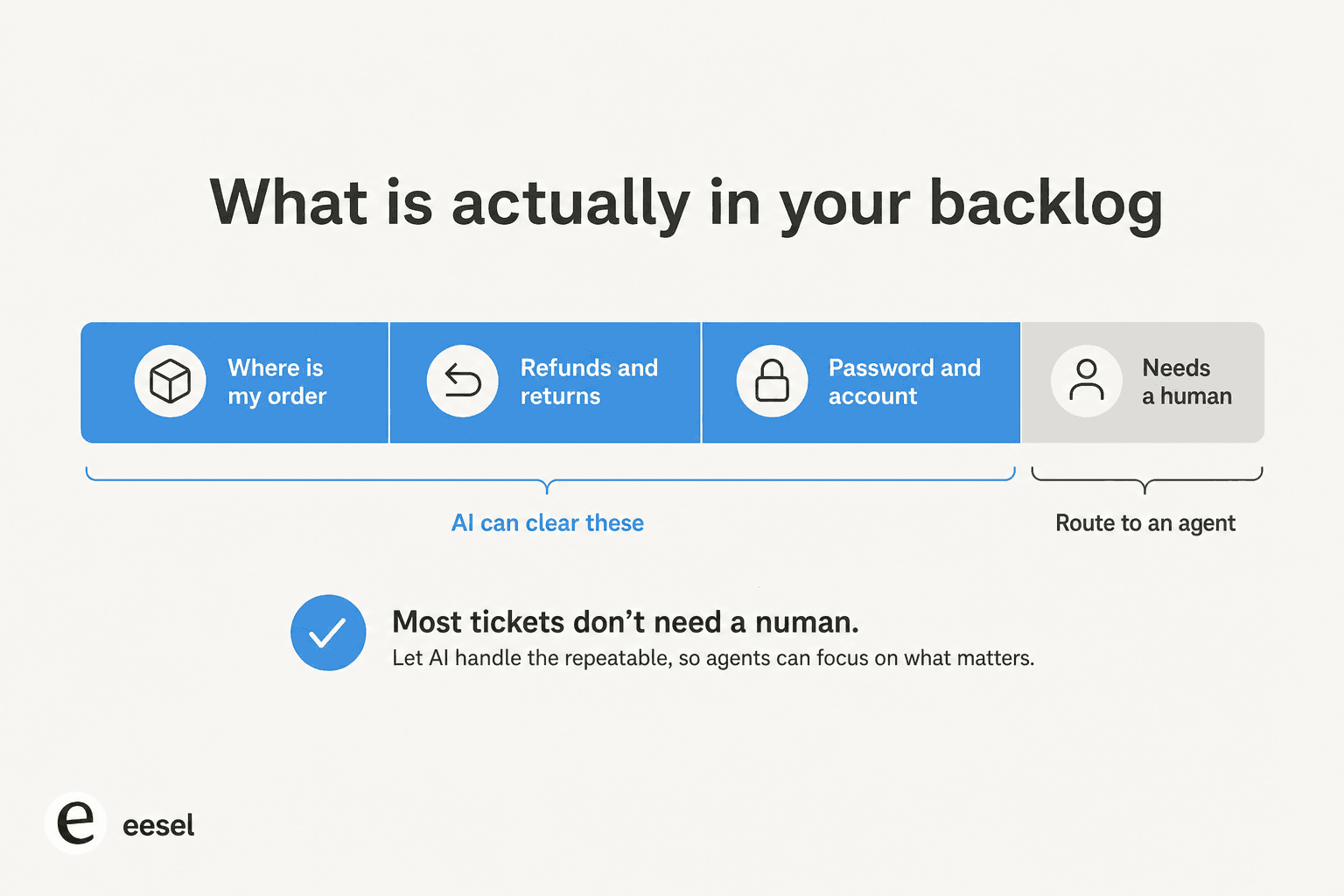
- Eine kurze Liste „sicherer" Fragetypen. Die fünf oder so Kategorien, die man jedes Mal auf dieselbe Weise beantwortet. Das ist das erste Automatisierungsziel, und sonst nichts.
Das war es. Der Rückstand, auf den Sie schauen, ist eigentlich Ihr wertvollstes Asset hier, weil er das Rohmaterial ist, aus dem die KI lernt.
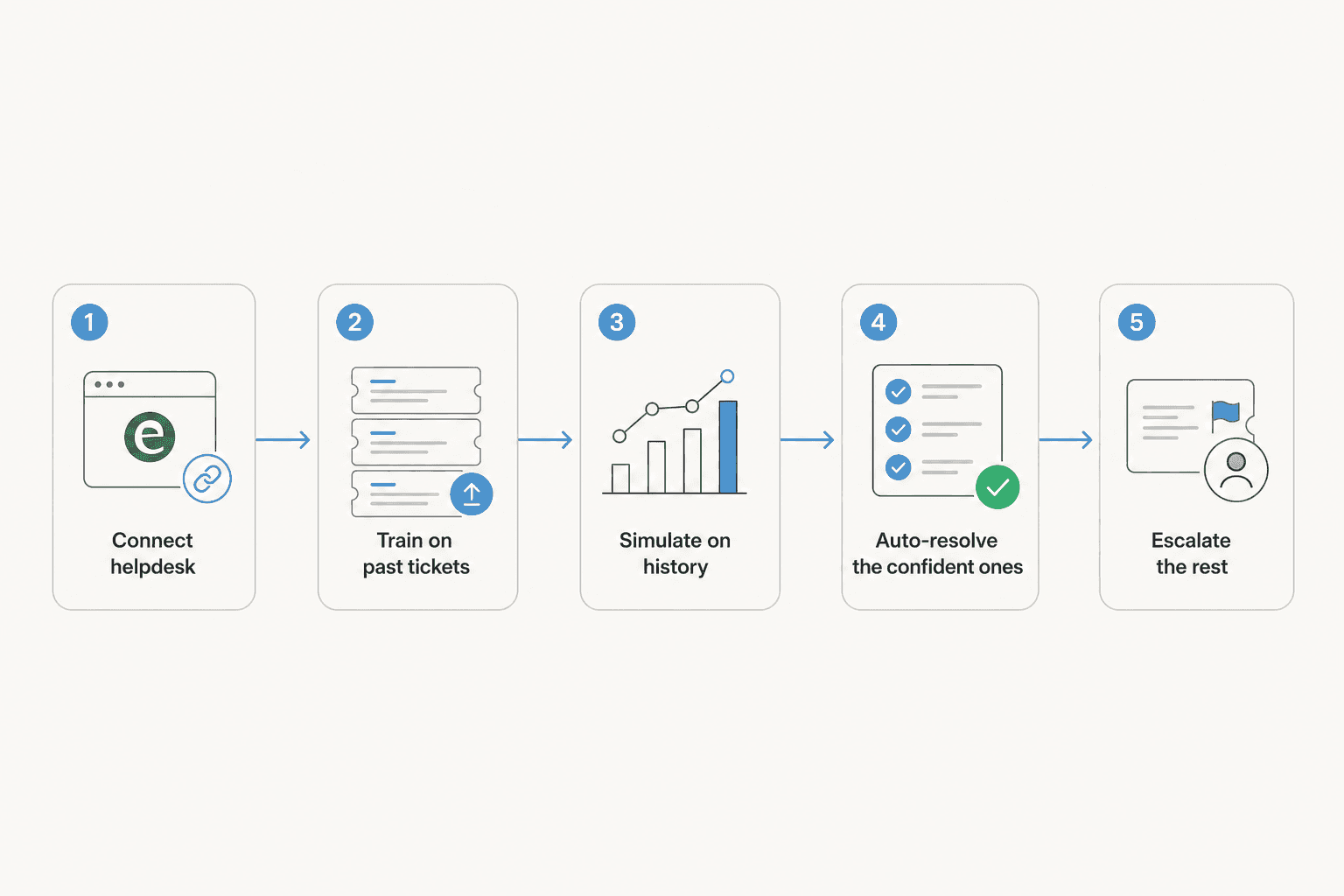
Schritt 1: Helpdesk verbinden und KI Ihre Historie lernen lassen
Der erste Schritt besteht darin, die KI mit dem Ort zu verbinden, an dem Ihre Tickets bereits sind, und sie Ihre bisherigen Lösungen, Makros und Hilfedokumente lesen zu lassen. Ein guter KI-Helpdesk-Agent behandelt diese als seine Quellen: Er lernt, wie Ihr Team antwortet, in Ihrer Stimme, mit Ihren Richtlinien.

Der Teil, den Teams unterschätzen: Das geht jetzt schnell. Self-Serve-Tools verbinden sich in Minuten, was weit entfernt ist von dem mehrtägigen Onboarding, das ältere Anbieter noch angeben. Ein Gig-Economy-Analyseunternehmen auf Zendesk erzielte echte Ergebnisse innerhalb einer 7-tägigen Testphase (mehr zu deren Zahlen weiter unten). Wenn ein Anbieter Ihnen sagt, dass das Leeren Ihres Rückstands mit einer quartalslangen Implementierung beginnt, ist das das Problem des Anbieters, nicht Ihres.
Schritt 2: Simulieren, bevor die KI echte Kunden berührt
Das ist der Schritt, der einen sauberen Rollout von einem beängstigenden trennt, und der, den ich nie überspringen würde.
Wir haben das auf die harte Tour gelernt, nachdem wir KI jahrelang in Live-Warteschlangen eingesetzt haben: Ein zuversichtlich klingender Bot gibt still falsche Antworten, wenn man ihn lässt, und bei einem 7.000-Ticket-Rückstand wird niemand jede Antwort gegenlesen, um es zu bemerken. Eine CX-Leiterin bei einer Hochvolumen-DTC-Marke mit rund 7.000 Tickets pro Monat formulierte die Angst in einem Gespräch mit uns genau richtig. Die KI wird nie jede Frage beantworten, sagte sie, aber „Ich kann nicht 7.000 Tickets durchgehen, um zu sehen, ob die KI tatsächlich eine gute Antwort gegeben hat." Ihre Anforderung war einfach: „Ich brauche eine KI, die nur die Tickets bearbeitet, bei denen sie sich sicher ist, und alle anderen in Ruhe lässt."
Deshalb simuliere ich jeden Rollout zuerst gegen historische Tickets. Man lässt die KI in einem sicheren Modus über einen Teil des echten Rückstands laufen, in dem sie nichts sendet, und liest, was sie geantwortet hätte. Man sieht die Lösungsrate, erkennt die Kategorien, bei denen sie unsicher ist, und optimiert sie, bevor ein einziger Kunde involviert ist. Es verwandelt „Ich hoffe, das funktioniert" in „Ich habe genau gesehen, was das tut."
Schritt 3: Repetitive Tickets automatisch lösen, den Rest weiterleiten
Jetzt leeren Sie die Warteschlange. Richten Sie die KI auf Ihre sicheren Kategorien und lassen Sie sie diese von Anfang bis Ende lösen, während alles außerhalb ihrer Konfidenzschwelle triagiert und weitergeleitet wird an den richtigen Menschen.
Hier spielen auch Automatisierungen jenseits von Antworten ihre Rolle: Tagging, Zuweisung und Statusaktualisierungen. Ein Fahreranalyseunternehmen auf Zendesk, das 73 % seiner Tier-1-Anfragen im ersten Monat gelöst hat, betonte, dass die Plattform auch „Ticket-Tagging, Zuweisung und Statusaktualisierungen" automatisch handhabte, nicht nur das Entwürfen von Antworten. Dieses Haushalten ist die Hälfte dessen, was eine Warteschlange unübersichtlich erscheinen lässt, also räumt das Automatisieren von Ticket-Tagging und Weiterleitung neben den Antworten auf.
Der Hebel hier ist real. Ein britisches Team erzielte 56 gelöste Tickets aus nur 9 synchronisierten Makros und nutzte den Agenten noch mehr als einen Monat nach Ablauf seiner Testphase. Man braucht keine riesige Wissensdatenbank, um anzufangen; man braucht die Handvoll Antworten, die am häufigsten aufkommen.
Schritt 4: Phasenweiser Rollout, nicht alles auf einmal
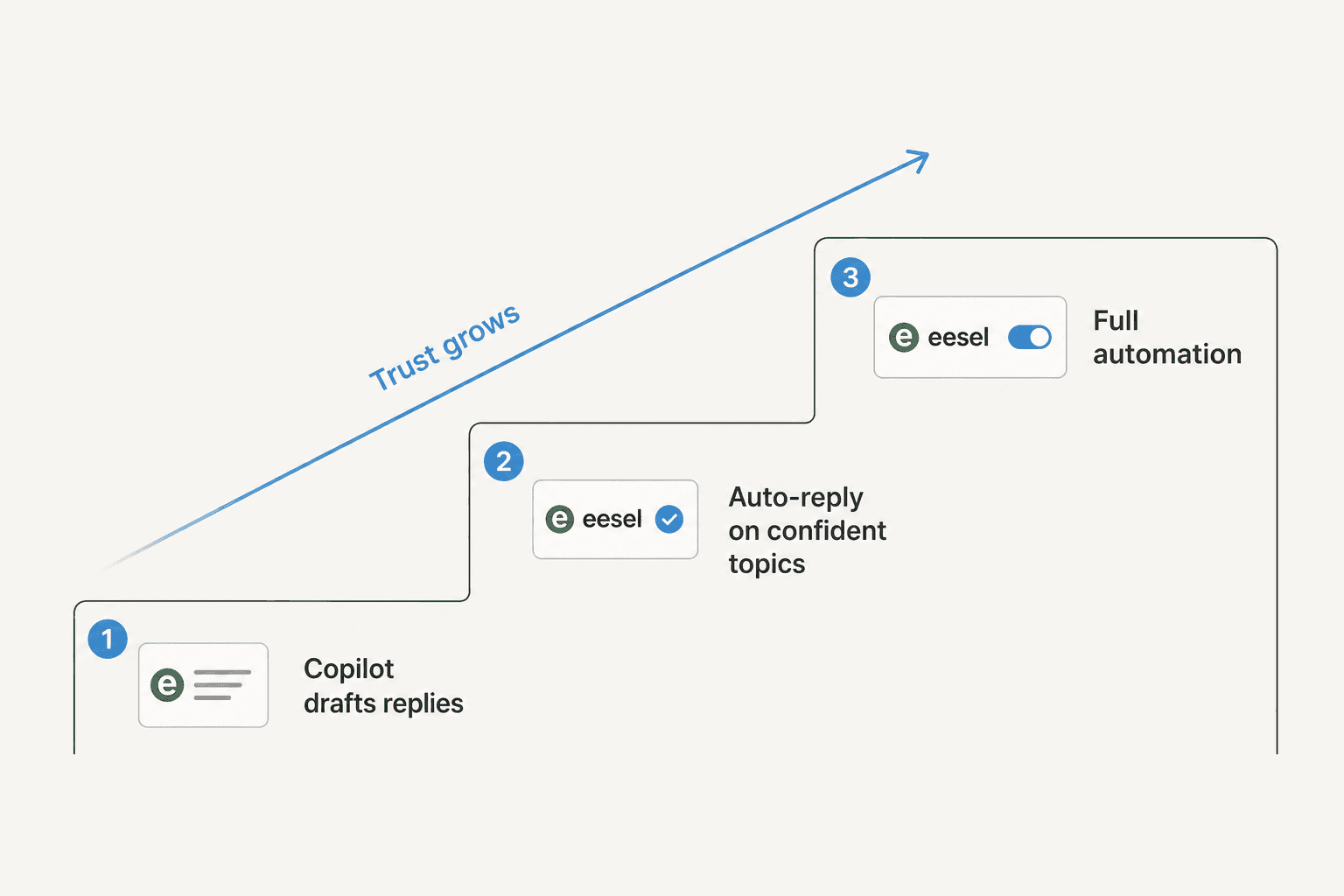
Der Fehler, den ich bei Teams sehe, ist, KI am ersten Tag auf vollständige Automatisierung zu stellen und dann zu paniken. Das Muster, das tatsächlich funktioniert, und das, was die meisten Kunden verlangen, ist eine Leiter:
- Zuerst Copilot. Die KI entwirft Antworten, Ihre Agenten prüfen und senden. Sie bauen Vertrauen auf und die Warteschlange beginnt sich zu bewegen, weil das Eintippen der Antwort der langsame Teil ist.
- Automatische Antwort bei den sichersten Kategorien. Sobald Simulation und Copilot-Modus zeigen, dass die KI bei, sagen wir, Bestellstatus gut ist, lassen Sie sie diese Kategorie autonom bearbeiten.
- Den Bereich erweitern. Fügen Sie Kategorien hinzu, wenn die Daten es rechtfertigen. Vollständige Automatisierung ist ein Ziel, das man erreicht, kein Schalter, den man blind umlegt.
Der Punkt der Leiter ist nicht Vorsicht um ihrer selbst willen. Es ist, dass jede Stufe Ihnen Beweise für die nächste liefert, sodass Sie, wenn die KI einen großen Teil des Rückstands automatisch löst, bereits wissen, dass es sicher ist, weil Sie gesehen haben, wie sie dahin gekommen ist.
Schritt 5: Den Rückstand daran hindern zurückzukommen
Einen Rückstand einmal zu leeren ist befriedigend. Ihn geleert zu halten ist der eigentliche Gewinn.
Lassen Sie die KI als Ersthelfer aktiv, damit neue Tickets triagiert und die repetitiven in dem Moment gelöst werden, in dem sie ankommen, anstatt sich über Nacht zum Rückstand von morgen anzuhäufen. Dann schließen Sie die Schleife: Jede häufige Frage, die die KI beantwortet, ist ein Kandidat für einen besseren Hilfeartikel oder eine Self-Service-Antwort, die verhindert, dass das Ticket überhaupt eingereicht wird. Beobachten Sie Ihre Berichte, um zu sehen, welche Kategorien noch durchsickern, und speisen Sie diese zurück.

Hier wird auch die Ökonomie angenehm. Ein E-Commerce-Konto mit rund 700 Tickets pro Woche betrieb die KI für rund 1 $ pro Ticket, was die Art von Zahl ist, die einen Rückstand von „wir müssen einstellen" zu „wir haben bereits die Kapazität" neurahmt. Wenn Sie die tiefere Mathematik wollen, hier ist ein ehrlicher Blick auf wie viel KI im Support spart.
Häufige Fehler, die man vermeiden sollte
- Alles auf einmal automatisieren. Konfidenz-Gating ist das ganze Spiel. Lassen Sie die KI das behandeln, was sie kennt, und den Rest den Menschen überlassen.
- Simulation überspringen. Wenn man nicht sehen kann, was die KI geantwortet hätte, bevor sie antwortet, spielt man Glücksspiel. Testen Sie es an Ihrer Historie zuerst.
- Als einmalige Bereinigung behandeln. Ein von Hand geleerte Rückstand wächst zurück. Ein von einem immer aktiven Ersthelfer geleerte Rückstand bleibt geleert.
- Das Haushalten vergessen. Antworten sind sichtbar; Tagging, Weiterleitung und Statusaktualisierungen sind die unsichtbare Arbeit, die eine Warteschlange verstopft. Automatisieren Sie auch Triage und Weiterleitung.
- Auf Demo kaufen, nicht auf Daten. Eine glatte Demo beweist nichts über Ihre Tickets. Lassen Sie jedes Tool sich an Ihrem Rückstand beweisen, bevor Sie sich festlegen.
eesel für die Bereinigung Ihres Rückstands ausprobieren
Wenn Sie den schnellsten Weg durch alles oben Genannte suchen, ist das der Teil der Warteschlange, für den eesel gebaut wurde. Es verbindet sich mit Zendesk, Freshdesk, Gorgias, Help Scout und mehr, lernt von Ihren bisherigen Tickets und Makros, und tut dann das Eine, das einen Rückstand sicher zu automatisieren macht: Es lässt Sie den Agenten auf Ihrer echten Tickethistorie simulieren, bevor er einen Kunden berührt, sodass Sie die Lösungsrate sehen und zuerst optimieren können.

Es ist ein No-Code-Setup, das man in Minuten zum Laufen bringen kann, konfidenz-gegatetes damit es nur automatisch löst, was es sicher weiß, und kostenlos ausprobierbar. Richten Sie es auf den Rückstand, auf den Sie gerade schauen, und beobachten Sie, welche Tickets es leeren würde.
Häufig gestellte Fragen
Wie kann ich einen Support-Ticket-Rückstand mit KI schnell abbauen?
Welche Tickets sollte die KI beim Abbau eines Rückstands zuerst bearbeiten?
Ist es sicher, KI automatisch auf einen Rückstand von Kundentickets antworten zu lassen?
Wie verhindere ich, dass der Support-Rückstand zurückkommt?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.