
Also, kann KI tatsächlich Support-QA durchführen?
Kurze Antwort: Ja, und auf der einen Dimension, die am meisten zählt – der Abdeckung –, besser als die manuelle Version.
Ich entwickle die KI-Agenten, die das tun, also lassen Sie mich präzise sein, was „Ja" bedeutet. Traditionelle Support-QA ist ein Analyst, der eine Handvoll Tickets pro Agent und Woche herauszieht, sie in einer Tabellenkalkulation bewertet und dann weitermacht. Wenn Ihr Team einige Tausend Gespräche pro Monat bearbeitet, bedeutet das eine Überprüfung von vielleicht 2 % davon – und eine verzerrte 2 % dazu, weil Prüfer dazu neigen, die Tickets anzuziehen, die einfach zu bewerten sind. Der seltsame Grenzfall, der stillschweigend einen Kunden verloren hat, schafft es fast nie in die Stichprobe.
KI dreht das um. Sobald ein Modell jedes Gespräch anhand Ihres Rubrics liest, kostet die Bewertung von 100 % der Gespräche ungefähr denselben Aufwand wie die Bewertung von 2 %. Abdeckung ist nicht mehr das, was Sie rationieren müssen. Der Haken ist, dass „alles lesen" und „alles korrekt beurteilen" zwei verschiedene Behauptungen sind. KI meistert die erste. Bei der zweiten behalten Sie einen Menschen in der Schleife.
Was KI gut macht (und der Beweis)
Hier ist KI-QA wirklich stark – und ich zeige Ihnen lieber echte Zahlen als Adjektive.
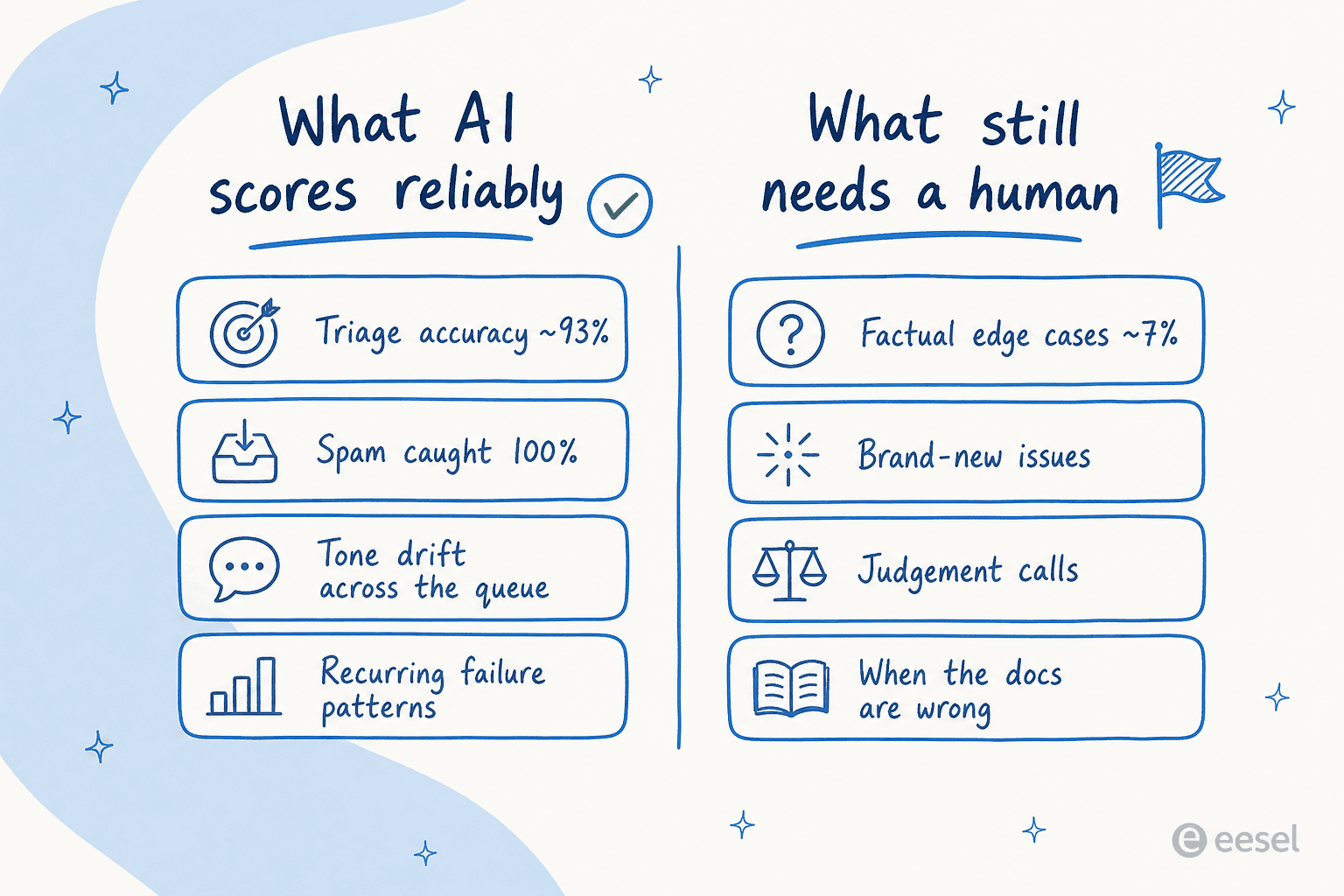
Als wir einen Agenten gegen den tatsächlichen Zendesk-Traffic eines Kunden laufen ließen, erzielte er etwa 93 % bei der Triage-Genauigkeit und erkannte 100 % des Spams ohne falsch-positive Ergebnisse – in einem Posteingang, der zu 22 % aus Spam bestand. Kategorie für Kategorie war er noch schärfer: nützliche Entwürfe bei Retouren und Erstattungen zu 93,8 %, Garantieansprüche zu 96,4 %, Produktanfragen und Erstattungsstatusabfragen zu 100 %. Das sind die repetitiven, musterlastigen Tickets, die QA konsistent halten soll – und ein Modell, das Ihre Geschichte gelesen hat, ist hervorragend darin, zu erkennen, wo eine Antwort vom Muster abweicht.
Dieselbe Stärke gilt für Ihre menschlichen Mitarbeiter. KI ist sehr gut in den Dingen, die ein müder Prüfer übersieht: ein Ton, der bei Erstattungen abrutscht, eine Richtlinie, die ein Agent immer wieder subtil falsch anwendet, ein Thema, bei dem jede Antwort niedrig bewertet wird, weil das zugrundeliegende Hilfedokument veraltet ist. Das sind Muster – und Muster sind das, was ein Modell, das die gesamte Warteschlange liest, findet, was eine 2-%-Stichprobe strukturell nicht kann. Außerdem wird sie beim 4.000. Ticket nicht gelangweilt, was ich von keiner menschlichen QA-Schicht sagen kann.
Wie KI ein Gespräch tatsächlich bewertet
Das ist der Teil, den sich die Leute als eine Art Black Box vorstellen – aber das ist er wirklich nicht. Der Mechanismus ist dasselbe Rubric, das ein menschlicher Prüfer verwenden würde, nur auf alles angewendet.
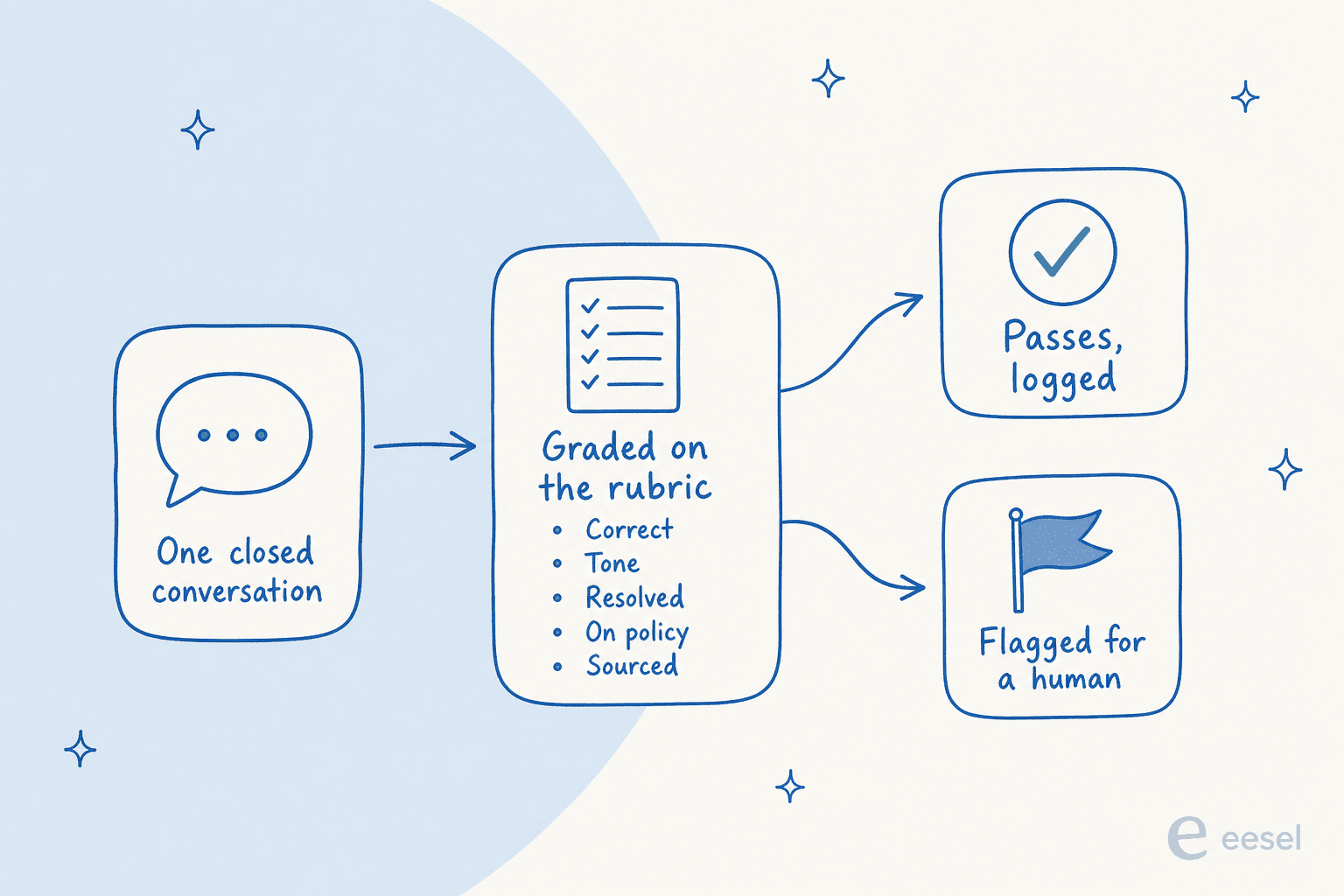
Ein abgeschlossenes Gespräch wird eingegeben. Die KI bewertet es anhand einiger expliziter Dimensionen: War es sachlich korrekt, war der Ton richtig, hat es das Problem tatsächlich gelöst, hat es die Richtlinie befolgt und hat es eine echte Quelle zitiert statt etwas zu erfinden? Gespräche, die bestehen, werden protokolliert; diejenigen, die niedrig bewertet werden, werden für eine Person zur Überprüfung markiert. Das Ergebnis, das Sie wollen, ist nicht eine einzige Zahl – es ist eine Aufschlüsselung, die Sie verfolgen können, damit Sie sehen können, dass diese Charge alle an derselben Richtlinie gescheitert ist oder dass ein Thema Ihre Werte nach unten zieht.
Zwei Dinge entscheiden darüber. Erstens muss das Rubric explizit sein – kein „Sie werden es wissen, wenn Sie es sehen." Fünf scharfe Dimensionen schlagen dreißig unscharfe – für die KI und für den Menschen. Zweitens müssen Sie ihr sowohl die Gespräche als auch die Wissensdatenbank mitgeben, aus der die Antwort hätte kommen sollen. Eine Bewertung von „falsch" ist nur nützlich, wenn Sie wissen, ob der Agent falsch lag oder die Dokumentation – und diese Unterscheidung ist der Unterschied zwischen dem Coaching einer Person und dem Umschreiben eines Artikels. Wenn Sie den vollständigen Aufbau möchten, haben wir eine Schritt-für-Schritt-Anleitung zum Support-QA mit KI geschrieben.
Wo KI-QA noch einen Menschen braucht
Jetzt die ehrliche andere Seite – denn ein QA-Beitrag, der nur Stärken auflistet, ist genau die Art von Sache, die KI-QA erkennen soll.
Zurück zu diesem Audit. Die Entwürfe des Agenten waren zu 88 % richtungsweisend korrekt, aber nur 12 % waren gut genug, um sie direkt von einem Agenten absenden zu lassen, und es gab eine Fehlerquote von 7 % bei Fakten. Wenn man in die Lücke eintaucht, ist es aufschlussreich: etwa 65 % der Überarbeitungen betrafen nur Länge und Ton (die KI schrieb acht Sätze, wo das Team drei schickt), etwa 20 % benötigten Daten, die die KI nicht sehen konnte (eine ERP- oder Logistikabfrage), und nur etwa 5 % waren Fälle, in denen die KI schlichtweg falsch lag. Also ist das meiste, was „einen Menschen braucht", durch besseres Training behebbar – aber dieser letzte Splitter an Faktenfehlern ist der Teil, den Sie nie vollständig automatisieren werden.
Das schärfste Beispiel, das ich beobachtet habe: Die KI eines Teams sagte Kunden selbstbewusst „Ja, wir unterstützen Ihr Modell" für Produkte, die tatsächlich nicht in ihrer Datenbank waren, weil das Help Center sagte „Wir unterstützen alle Modelle." Die KI halluzinierte nicht – sie wiederholte treu ein Dokument, das falsch war. Keine Menge an Modellqualität erkennt das von selbst. Ein Mensch, der das markierte Muster liest, erkennt es in fünf Minuten. Das ist die wahre Arbeitsteilung bei KI vs. menschlichem Support: Die KI liest alles und bringt das verdächtige Muster ans Licht, eine Person entscheidet, was es bedeutet und behebt die Grundursache.
Also die Dinge, für die ein Mensch zuständig bleiben sollte: neuartige Probleme ohne Präzedenzfall in Ihrer Geschichte, Ermessensentscheidungen wie eine Kulanzausnahme, alles, was von Geschäftskontext abhängt, der im Kopf von jemandem lebt statt in Ihren Dokumenten, und die periodische Kalibrierung der eigenen Bewertungen der KI. Behandeln Sie die Bewertung der KI als Meinung eines zweiten Analysten, nicht als endgültiges Urteil, und Sie erhalten die Abdeckung ohne die blinden Flecken.
Der Test, den die meisten Teams überspringen: Kann KI sich selbst einer QA unterziehen?
Hier ist der Teil, an dem die meisten „KI für QA"-Artikel vorbeischlittern – und er ist derjenige, der mir am wichtigsten ist. Wenn Sie KI Tickets bearbeiten lassen, muss diese KI QA bestehen, bevor sie einen Kunden berührt – und die meisten Teams führen diese Prüfung nie durch.
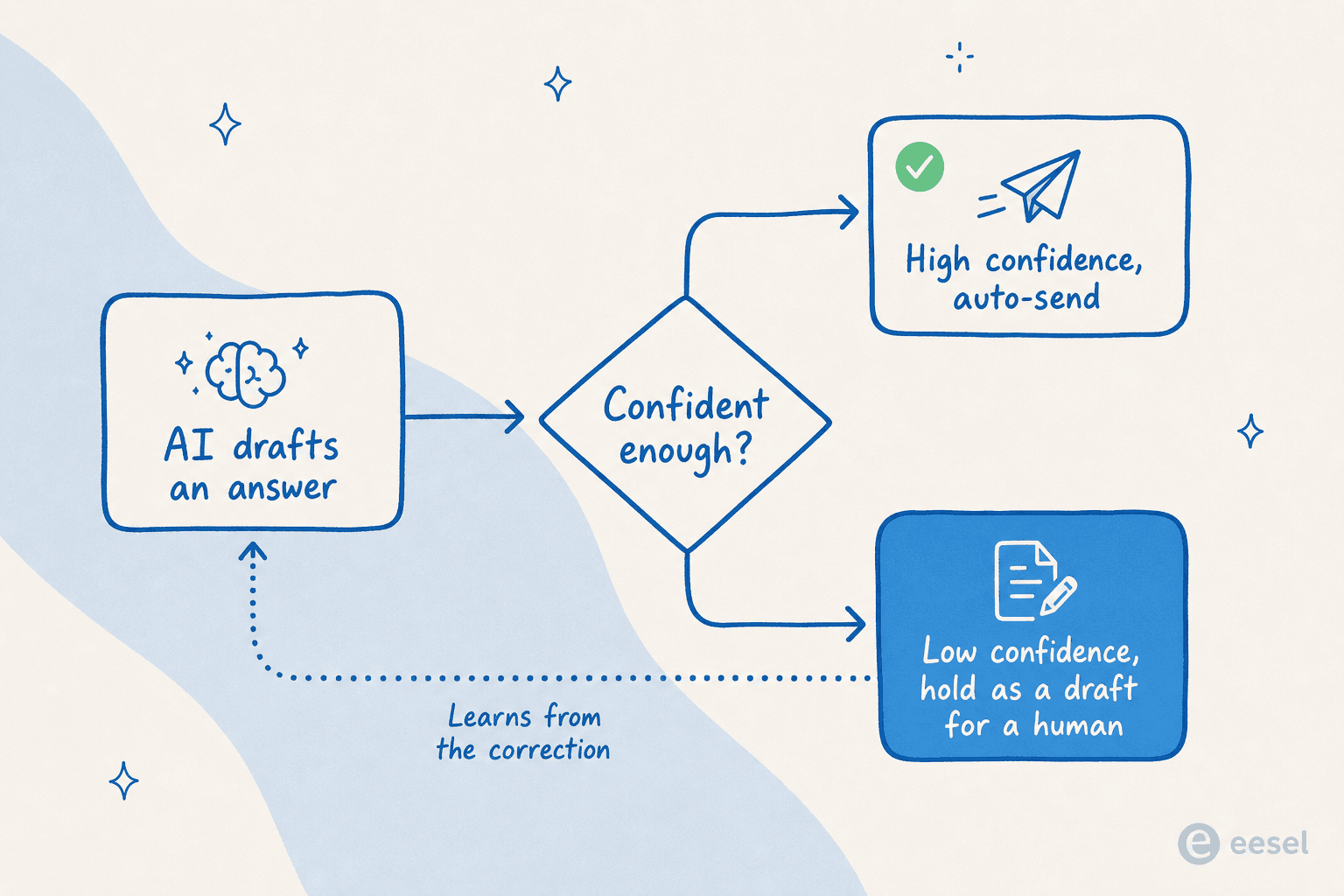
Der Mechanismus ist konfidenzbasiertes Routing. Der Agent sendet nur automatisch Antworten, bei denen er sich sicher ist; alles unterhalb des Schwellenwerts hält er als Entwurf für einen Menschen zurück, und er lernt aus der Korrektur, damit derselbe Fehler nicht wiederholt wird. Ein DTC-Ergänzungsleiter brachte den Einsatz für uns perfekt auf den Punkt: Eine KI, die auf alles „Entschuldigung, ich weiß es nicht" antwortet, ist nutzlos, aber eine KI, die rät, ist schlimmer, „weil niemand 7.000 Tickets erneut lesen kann, um die Ratereien zu erkennen." QA ist die Antwort auf beides.
Also haben wir die Prüfung in den Rollout integriert. Bevor ein eesel-Agent live geht, führen Sie ihn in einer Simulation gegen Ihre echten vergangenen Tickets aus und sehen seine Qualität und Abdeckung nach Thema – ohne Kundenbeteiligung. So haben wir die 93 %- und 7 %-Zahlen überhaupt erst erhalten, auf der sicheren Seite des Glases. Sobald er live ist, erscheinen dieselben Werte in Ihrer Agenten-Analytics, sodass die QA der Automatisierung nie wirklich aufhört.

Das ist auch die ehrlichste Antwort auf „Kann ich ihm vertrauen?" Sie vertrauen ihm nicht blind. Sie unterziehen es einer QA, setzen es auf Entwurf statt auf automatisches Senden, wo seine Sicherheit niedrig ist, und erweitern seine Autonomie, wenn die Werte es verdienen. Das ist die Grenze zwischen einer Demo und einer Bereitstellung.
Wie Teams KI-QA im Alltag tatsächlich nutzen
In der Praxis entwickelt es sich zu einer Schleife – und die Schleife ist wichtiger als jede einzelne Bewertung. Die KI bewertet jedes Gespräch, sobald es abgeschlossen wird. Sie bringt die Coaching-Momente ans Licht, auf die ein Mensch schauen sollte, gruppiert nach dem, was sie gemeinsam haben, statt fünf zufälliger Tickets. Ein Teamleiter handelt auf Grundlage der Muster: coacht die markierten Agenten, korrigiert die Dokumente hinter den wiederkehrenden Fehlern und aktualisiert die Regeln für Ticket-Tagging und Eskalation, die ein niedrig bewertendes Thema aufdeckt. Wenn Sie das Dokument hinter einem wiederkehrenden Fehler korrigieren, reduzieren Sie häufig gleichzeitig das Ticket-Volumen.
Was die Tools angeht, gibt es zwei Lager. Dedizierte QA-Plattformen wie Zendesk QA (das Produkt früher bekannt als Klaus) und MaestroQA bewerten Gespräche automatisch und speisen Coaching-Workflows, und sie sind eine solide Wahl, wenn QA eine eigenständige Funktion für Sie ist. Das andere Lager ist KI-Kundenservice-Software, die QA neben dem arbeitenden Agenten bündelt, sodass dieselbe Engine, die die Gespräche Ihres Teams bewertet, auch die KI-Entwürfe einer QA unterzieht. Eine letzte Schutzmaßnahme, die es wert ist, laut ausgesprochen zu werden: QA ist nicht CSAT. Ein Kunde kann eine selbstbewusst falsche Antwort mit fünf Sternen bewerten – daher möchten Sie sowohl Ihre QA-Werte als auch Ihren CSAT-Bericht, und nicht eines als Ersatz für das andere.
eesel für Support-QA ausprobieren
Wenn Sie KI-Support-QA möchten, ohne drei Tools zusammenzuschrauben, ist das genau das, wofür eesels KI-Helpdesk-Agent entwickelt wurde. Er verbindet sich mit Ihrem bestehenden Helpdesk, liest Ihre vergangenen Gespräche und Ihre Wissensdatenbank, und ermöglicht es Ihnen, eine Simulation über echte historische Tickets zu führen, damit Sie Qualität und Abdeckung sehen können, bevor irgendetwas live geht.

Das Nützliche für QA ist, dass dieselbe Engine, die die Entwürfe eines KI-Agenten bewertet, auch die Gespräche Ihres Teams liest – so leben QA für Menschen und QA für Automatisierung an einem Ort statt in zwei Tabellenkalkulationen. Es lässt sich an einem Nachmittag einrichten, kennt bereits Ihr Help Center, und die nutzungsbasierte Preisgestaltung berechnet Ihnen keine Gebühr pro Sitz für das Privileg, Ihre eigenen Tickets zu überprüfen. Kostenlos ausprobieren.
Häufig gestellte Fragen
Kann KI die Support-Qualitätssicherung zuverlässig durchführen?
Wie bewertet KI-Support-QA ein Gespräch eigentlich?
Was kann KI bei der Support-Qualitätssicherung nicht leisten?
Wie viel meines Support-Volumens kann KI-QA abdecken?
Kann KI auch einen KI-Support-Agenten einer QA unterziehen?
Ersetzt KI-Support-QA meine QA-Analysten?
Welche Tools können KI-Support-Qualitätssicherung durchführen?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








