KI-Kundensupport-Qualitätssicherung: wie Sie Ihrem KI-Agenten wirklich vertrauen können
Riellvriany Indriawan
Katelin Teen
Zuletzt bearbeitet June 19, 2026

Was Qualitätssicherung bedeutet, wenn der Agent eine KI ist
Traditionelles Support-QA ist ein Stichprobenspiel. Eine Teamleiterin zieht vielleicht 2–5 % der Tickets der letzten Woche, bewertet sie nach einem Rubrik (Hat der Agent das Problem gelöst? War er freundlich? Hat er die Richtlinien eingehalten?) und coacht die Menschen, die geschwächelt haben. Das funktioniert, weil Menschen überwiegend konsistent sind und auf vorhersehbare Weise versagen.
Ein KI-Agent bricht zwei dieser Annahmen auf. Er bearbeitet weit mehr Volumen, als jeder Stichprobenprozess ausgelegt war, und er scheitert auf ungewohnten Wegen. Ein neuer menschlicher Mitarbeiter erfindet selten spontan eine Rückerstattungsrichtlinie; eine nicht verankerte KI wird es tun, und zwar in einem selbstbewussten, gut geschriebenen Satz, der genau wie eine korrekte Antwort aussieht. Daher hört QA auf, „Ausreißer coachen" zu bedeuten, und wird zu „das System verifizieren" – ähnlich wie die KI-Agenten-Evaluation, die Sie für jede automatisierte Pipeline durchführen würden.
Die entscheidende Umdeutung: Qualitätssicherung für einen KI-Agenten findet an zwei Stellen statt – vor dem Go-live und danach – und ist kein monatlicher Bericht, den Sie lesen, nachdem der Schaden schon angerichtet ist.
Warum die Deflection Rate die Kennzahl ist, die Sie anlügt
Wenn Sie nur eine Kennzahl einer QA unterziehen, dann bitte nicht die Deflection Rate. Sie zählt Gespräche, die keinen Menschen erreicht haben, und bündelt dabei still zwei sehr unterschiedliche Ergebnisse: Kunden, denen die KI wirklich geholfen hat, und Kunden, die aufgegeben haben.
Support-Praktiker spüren das instinktiv. Eine Ops-Leiterin auf r/CustomerExperience beschrieb das Versagensmuster deutlich:
„Mein Chef liebt unsere Deflection-Zahlen, aber ich vertraue ihnen nicht. Ich habe versucht, einen Bericht über Tickets zu erstellen, die innerhalb von 24 Stunden wieder geöffnet wurden, aber Kunden öffnen einfach EIN WEITERES Ticket statt das geschlossene zu verwenden. Das lässt es so aussehen, als hätte der Bot gute Arbeit geleistet, obwohl er den Kunden eigentlich nur verärgert hat."
Eine Antwort in einem verwandten Thread zog die Linie noch schärfer: „Ein Bot kann einen Chat ‚erfolgreich' abschließen, aber wenn der Nutzer 20 Minuten später ein E-Mail-Ticket einreicht, war der Bot Schrott."
Das ist das ganze Problem mit der Optimierung allein auf Tier-1-Deflection. Schweigen ist nicht dasselbe wie Lösung. Die Kennzahl, die Sie wirklich wollen, ist die Resolution Rate kombiniert mit Wiederöffnungs- und Wiederholungskontaktraten, damit ein frustriert abgewanderter Kunde als Verlust erscheint statt sich hinter einer hübschen Dashboard-Zahl zu verstecken.
Die Kennzahlen, die wirklich zeigen, ob Ihr KI-Support gut ist
Keine einzelne Zahl erledigt den Job. Gute KI-Support-Kennzahlen funktionieren als Panel, wobei jede ein Versagen aufdeckt, das die anderen verpassen:
- Resolution Rate ist die Hauptkennzahl – definieren Sie sie aber ehrlich als „Problem des Kunden ohne menschliche Hilfe gelöst", nicht „Gespräch beendet". Diese Zahl ist es wert, prognostiziert und im Laufe der Zeit verfolgt zu werden. Die Resolution Rate ist die nächste Annäherung an eine einzige Wahrheitsquelle.
- Fehlerquote bei Fakten ist die KI-spezifische Kennzahl. Wie viele Antworten waren in einer bewerteten Stichprobe selbstbewusst falsch? Das ist Ihre Halluzinations-Prüfung – und die Kennzahl, die die meisten Teams vergessen aufzubauen.
- Eskalationsqualität fragt, ob der Agent sauber und zum richtigen Zeitpunkt übergeben hat. Eine saubere Übergabe an Menschen bei einem schwierigen Ticket ist ein gutes Ergebnis, kein Versagen.
- Wiederöffnungs- und Wiederholungskontaktrate ist der Lügendetektor für die Deflection Rate. Wenn „gelöste" Tickets immer wieder zurückkommen, waren sie nicht gelöst.
- KI-CSAT, getrennt von Human-CSAT gemessen. Verfolgen Sie den KI-CSAT separat, damit ein guter Bot-Score nicht von Ihren besten menschlichen Agenten gestützt wird – und umgekehrt.
So sieht ein echter Bewertungsdurchlauf aus, wenn man Zahlen anlegt. Als das Team bei einem Piloten QA durchführte – einem deutschen Online-Schmuckhändler mit etwa 1.000 Tickets pro Monat auf Zendesk und Shopify – war das Bild konkret statt vage: 93 % Triage-Genauigkeit, 100 % Spam-Erkennung ohne Fehlalarme bei den 22 % des Posteingangs, die Junk waren, aber nur 12 % der Entwürfe gut genug zum unveränderten Versenden und eine Fehlerquote bei Fakten von 7 %. Diese Streuung zeigt genau, wo Sie die nächste Woche investieren sollen – was keine Deflection-Zahl je könnte.

Derselbe Reddit-Thread, auf den ich immer wieder zurückkomme, hatte jemanden, der fast genau dieses Panel aufgelistet hat. Wie ein Reddit-Praktiker, der mit vielen Support-Teams gesprochen hatte, es formulierte: „Deflection Rate sieht auf Dashboards gut aus, verbirgt aber Qualitätsprobleme. Bessere Kennzahlen wären: Automatisierte Resolution Rate, KI- vs. Human-CSAT, Eskalationszeit, Wiederöffnungsrate nach Bot-Antworten." Wenn die Leute, die echte Zendesk-Automatisierung betreiben, und die Leute, die sie bauen, bei derselben Liste landen, ist das die Liste.
QA vor dem Go-live: Simulation gegen Ihre eigenen Tickets
Das ist der Teil, den die meisten Teams überspringen – und der wertvollste in diesem ganzen Beitrag. Sie müssen nicht herausfinden, ob Ihre KI gut ist, indem Sie sie auf echte Kunden loslassen und die wütenden Antworten lesen. Sie können es zuerst herausfinden.
Die Methode ist Simulation: Nehmen Sie den Agenten, richten Sie ihn auf Tausende Ihrer historischen, bereits gelösten Tickets aus und lassen Sie ihn die Antwort generieren, die er gesendet hätte, und vergleichen Sie dann mit dem, was Ihr menschliches Team tatsächlich getan hat. Da Sie die richtige Antwort bereits kennen, erhalten Sie eine Prognose der Resolution Rate, eine Liste der Themen, bei denen die KI unsicher ist, und eine Fehlerquote bei Fakten – alles ohne einen einzigen echten Kunden im Wirkungsbereich. Es ist die sichere Version von Adversarial Testing, durchgeführt gegen Ihre echten Ticket-Historien statt gegen ein synthetisches Testset.
Das ist für uns nicht theoretisch. eesel betreibt einen Simulationsmodus, der genau das tut, bevor ein Agent live geht – und der Grund für seine Existenz ist Narbengewebe. Ich habe erlebt, wie ein selbstbewusst klingender Bot still eine falsche Antwort gab, und das hat jeder erlebt, der einen deployed hat. Einem unserer Kunden, einem dänischen Fahrzeug-Telematik-Team auf Zendesk, passierte früh die klassische Variante: Weil ihre Wissensdatenbank sagte „wir unterstützen alle Modelle", teilte die KI Kunden munter mit, sie unterstütze Automarken, die tatsächlich nicht in ihrer Datenbank waren. Der einzig zuverlässige Weg, diese Klasse von Fehlern zu finden, besteht darin, die falschen Antworten vor den Kunden zu sehen – gegen Ihre eigenen Tickets.
QA nach dem Go-live: Stichproben, bewerten und abstimmen
Sobald Sie live sind, wird Qualitätssicherung zu einem Rhythmus. Ziehen Sie wöchentlich eine neue Stichprobe echter Gespräche, bewerten Sie sie anhand des obigen Panels und geben Sie das Gelernte zurück an den Agenten. Ihr Helpdesk bewahrt bereits das Rohmaterial: Die meisten Plattformen legen Gesprächsprotokolle offen, aus denen Sie eine Stichprobe ziehen können, und ein gutes Analytics-Dashboard macht daraus einen Trend statt einer einmaligen Lektüre.

Die Bewertung selbst muss nicht aufwendig sein. Genehmigen und verwerfen Sie Antworten mit einer Begründung („zu formal", „Rückgaberichtlinie übersehen") und stellen Sie sicher, dass dieses Signal den Agenten tatsächlich trainiert statt in einem Vakuum zu verschwinden. Überraschend viele Käufer stellen uns genau diese Frage während der Evaluierung – irgendeine Variante von „Verfolgen Sie, ob ich Antworten genehmige oder ablehne, und ändert das etwas?" Wenn die Feedbackschleife real ist, verbessert jeder QA-Durchlauf die Antworten der nächsten Woche. Wenn nicht, bewerten Sie ins Leere.
Achten Sie auf Folgendes: wie der Agent sich verhält, wenn etwas kaputtgeht – zum Beispiel wenn Ihre Helpdesk-API mitten in einem Gespräch gedrosselt wird. Amogh, eesels Gründer, hat dazu eine Formulierung, die unserem Team hängengeblieben ist: Ein stilles Versagen gehört zur „Silent-Failure-Klasse, der schlimmsten Klasse für Vertrauen". Ein KI, der laut versagt und übergibt, erledigt die Arbeit des QA für Sie; einer, der still versagt und rät, ist genau das, was Ihre wöchentliche Stichprobe aufdecken soll.
Das Schwierigste: Der KI vertrauen zu wissen, was sie nicht weiß
Alle oben genannten Kennzahlen werden leichter, sobald die KI aufhört, alles beantworten zu wollen. Das ist das Häufigste, was ich von Teams höre, die uns evaluieren, und es ist mehr wert als jedes Modell-Upgrade.
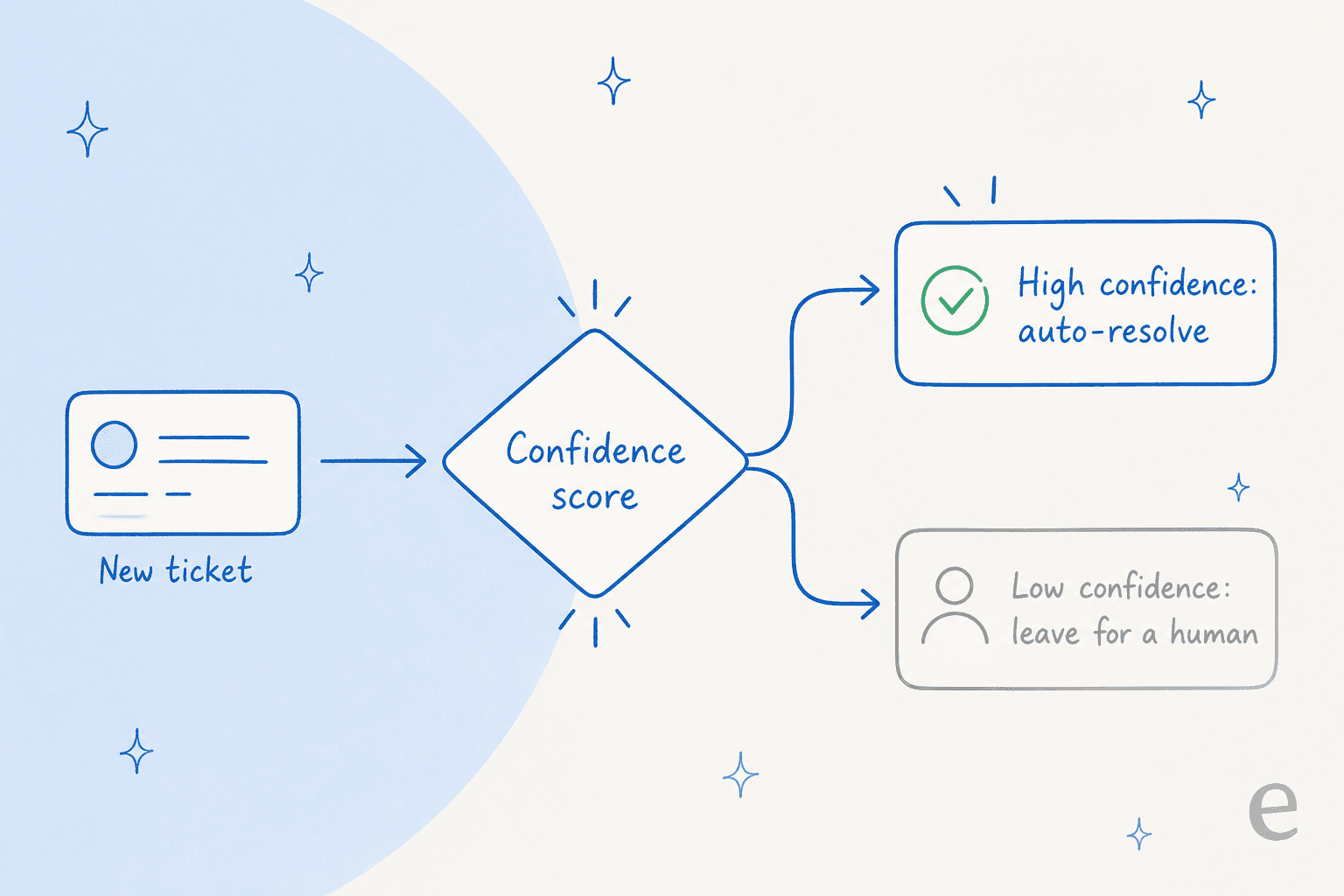
Eine CX-Leiterin bei einer DTC-Supplement-Marke auf Gorgias mit etwa 7.000 Tickets pro Monat formulierte es besser als ich es je könnte: Die KI wird nie 100 % der Fragen beantworten, aber wenn sie es versucht und einfach sagt „tut mir leid, ich weiß es nicht", kann niemand 7.000 Tickets zurückverfolgen, um zu prüfen, ob sie wirklich gute Arbeit geleistet hat. Was sie wollten, war eine KI, „die nur die Tickets bearbeitet, bei denen sie zuversichtlich ist, und alle anderen in Ruhe lässt."
Das ist konfidenzbasiertes Routing – und es ist die wirkungsvollste QA-Kontrolle, die Sie haben. Wenn der Agent nur oberhalb eines Konfidenz-Schwellenwerts spricht und den Rest still an einen Menschen weiterleitet, sinkt die Fehlerquote bei Fakten, Ihre Eskalationen werden bedeutsam, und die Antworten, die Sie QA unterziehen müssen, sind eine kleinere, höherwertigere Menge. Derselbe Reddit-Thread enthielt eine scharfe Warnung: Ein Praktiker erinnerte alle daran, nicht auf das „Null-Halluzinations"-Zeug hereinzufallen, während er das gesamte Gespräch um Resolution statt Deflection neu rahmte. Konfidenz-Routing ist der Weg dorthin: nicht indem man behauptet, die KI irre nie, sondern indem man sie zum Schweigen bringt, wenn sie es vielleicht tut.
Für regulierte Teams ist das nicht verhandelbar. Ein Mitgründer eines Legal-Tech-Unternehmens sagte uns, sie konnten KI nur adoptieren, weil sie „exakte Leitplanken bei der Quellenangabe setzen konnten und es immer transparente Zitate liefert" – der Unterschied zwischen hilfreich sein und in Rechtsberatung abdriften. Zitate und Konfidenz-Gates sind keine Features, sie sind das QA.
Ein QA-Workflow, den Sie tatsächlich durchführen können
Wenn Sie einen konkreten Ausgangspunkt wollen, hier ist die Schleife, die ich für jedes Team einrichten würde, das einen KI-Agenten aufstellt – egal ob auf Zendesk, Freshdesk oder einem anderen Helpdesk mit KI:
- Zuerst simulieren. Spielen Sie den Agenten vor dem Launch gegen ein paar Tausend vergangene Tickets ab und lesen Sie eine Stichprobe der hypothetischen Antworten. Setzen Sie Ihre Go-live-Hürde auf die prognostizierte Resolution Rate, nicht auf Bauchgefühl.
- Schmal starten. Schalten Sie den Agenten für ein oder zwei zuversichtliche Themen ein, nicht für die gesamte Ticket-Queue. Konfidenz-Routing macht das einfach.
- Wöchentlich bewerten. Stichproben echter Gespräche ziehen, nach Resolution Rate, Faktenfehlern und Eskalationsqualität bewerten und schlechte Antworten mit einer Begründung ablehnen, die den Agenten trainiert.
- Die Lügendetektoren beobachten. Wiederöffnungs- und Wiederholungskontaktraten neben der Deflection Rate verfolgen, damit ein frustrierter Kunde nicht als Sieg zählen kann.
- Bei Drift alarmieren. Monitoring einrichten, damit ein plötzlicher Qualitätsabfall Sie zwischen den Überprüfungen benachrichtigt.
Führen Sie das einen Monat durch und Sie haben etwas, das die meisten „Wir haben eine KI deployed"-Geschichten nie bekommen: eine vertretbare Antwort auf „Wie wissen Sie, dass es gut ist?"
eesel für KI-Support ausprobieren, den Sie wirklich QA unterziehen können
Der größte Teil dieses Beitrags beschreibt schlicht, wie eesel funktioniert, weil Qualitätssicherung das ist, um das wir das Produkt herum gebaut haben. Sie verbinden Ihren Helpdesk und Ihre Wissensdatenbank, eesel trainiert auf Ihren vergangenen Tickets und Dokumenten, und bevor Sie live gehen, spielt sein Simulationsmodus den Agenten über Tausende Ihrer historischen Gespräche ab – damit Sie die Resolution Rate prognostizieren und die falschen Antworten privat lesen können. Nach dem Launch hält konfidenzbasiertes Routing den Agenten bei allem still, wofür er sich nicht sicher ist, und die Berichte zeigen Ihnen, was Sie jede Woche bewerten sollen.

Die Nutzung ist kostenlos und Sie können eine vollständige Simulation mit Ihren eigenen Tickets durchführen, bevor Sie sich zu irgendetwas verpflichten – was das ehrlichste QA ist, das es gibt: sehen Sie, wie es Ihren echten Kunden geantwortet hätte, und entscheiden Sie dann. eesel ausprobieren und mit einer Simulation starten.
Häufig gestellte Fragen
Was ist KI-Kundensupport-Qualitätssicherung?
Wie misst man die Qualität eines KI-Support-Agenten?
Ist die Deflection Rate eine gute Kennzahl für die KI-Support-Qualitätssicherung?
Wie verhindert man Halluzinationen eines KI-Support-Agenten?
Wie oft sollte man den KI-Support-Agenten einer QA-Prüfung unterziehen?
Kann man einen KI-Support-Agenten vor dem Go-live testen?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.








