Kann KI mehrsprachigen Kundensupport übernehmen? Eine ehrliche Antwort
Alicia Kirana Utomo
Katelin Teen
Zuletzt bearbeitet June 22, 2026

Die ehrliche Antwort: Ja, aber „übernehmen" trägt viel Last
Ich entwickle KI-Agenten von Beruf, also lassen Sie mich die Marketing-Version überspringen. Die Frage „Kann es die Sprache sprechen?" war im Grunde gelöst, sobald große Sprachmodelle gut wurden. Die Modelle hinter den heutigen KI-Kundensupport-Tools wurden auf enormen mehrsprachigen Korpora trainiert, sodass Französisch, Deutsch, Brasilianisches Portugiesisch, Rumänisch und Japanisch keine Sonderfunktionen sind, die jemand nachträglich hinzugefügt hat. Sie sind einfach Dinge, die das Modell bereits kann.
Die ehrliche Antwort ist also ja. Aber „übernehmen" trägt viel Last in diesem Satz. Es gibt eine große Lücke zwischen „kann einen grammatikalisch korrekten spanischen Satz produzieren" und „kann Ihre spanische Support-Warteschlange sicher unbeaufsichtigt betreiben." Ersteres ist gelöst. Letzteres hängt vollständig davon ab, wie Sie das System einrichten – das ist der Teil, den die meisten Beiträge überspringen und der mich tatsächlich interessiert.
Zwei Dinge sind es wert, vor dem Weiterlesen klargestellt zu werden. Erstens ist mehrsprachiger Support eines der am meisten unterschätzten Dinge, die KI gut macht – Teams merken routinemäßig nicht, dass ihr Agent bereits sprachübergreifend funktioniert. Zweitens sind die Risiken real, aber nicht die, die die Leute befürchten. Fast niemand wird durch schlechte Grammatik in Schwierigkeiten gebracht. Man gerät in Schwierigkeiten durch die operativen Randstellen. Lassen Sie uns beides durchgehen.
Wie KI tatsächlich verschiedene Sprachen verarbeitet
Hier ist der Mechanismus, denn er erklärt sowohl warum es funktioniert als auch wo es scheitert.
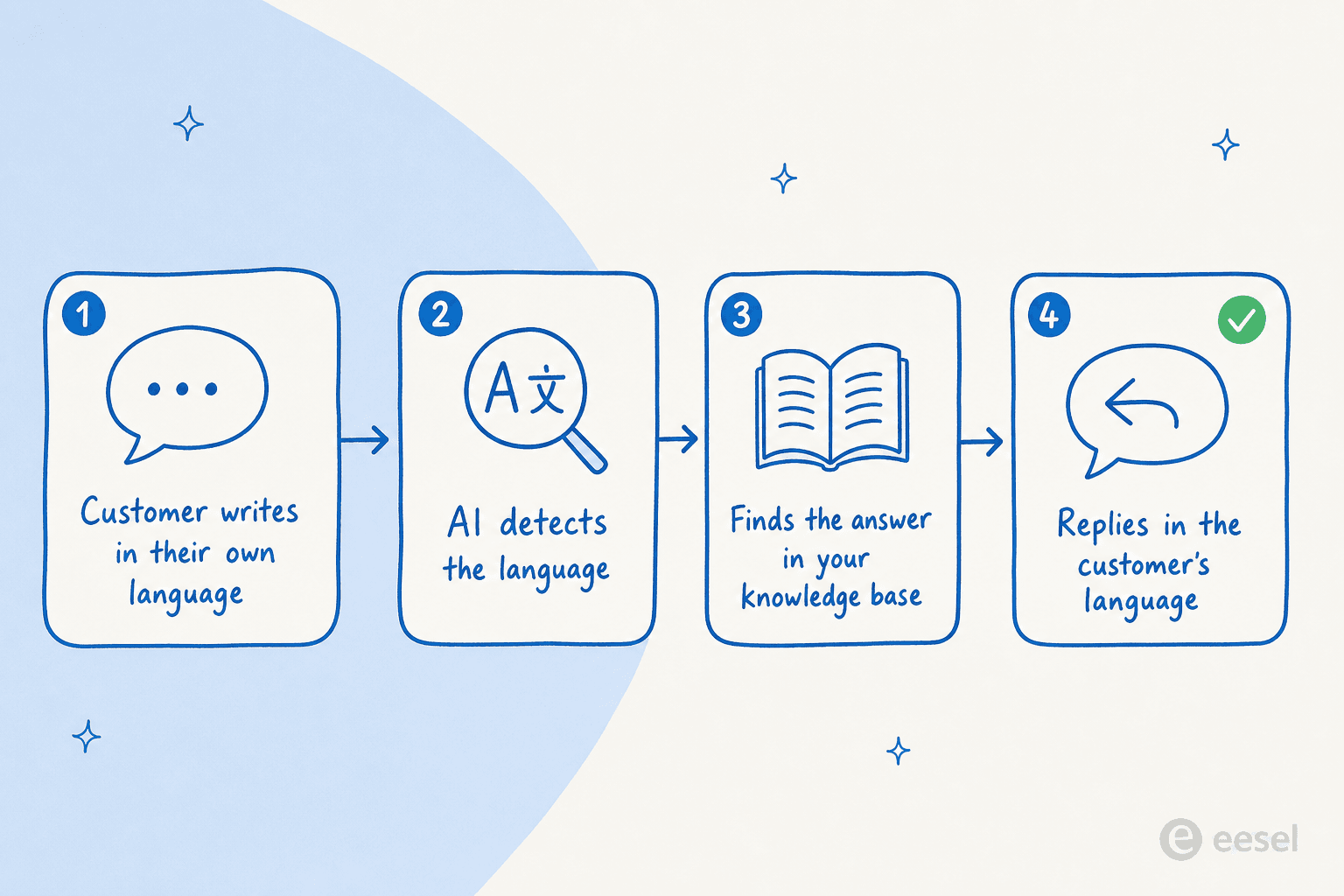
Wenn ein Ticket eingeht, erkennt der Agent die Sprache der Nachricht, findet die relevante Antwort in Ihrer Wissensdatenbank und schreibt die Antwort in der Sprache des Kunden zurück. Der clevere Teil ist der mittlere Schritt: Ihre Wissensdatenbank muss nicht mehrsprachig sein. Sie können Ihre Hilfedokumente, Makros und vergangenen Tickets auf Englisch halten, und das Modell beantwortet dennoch einen niederländischen Kunden auf Niederländisch, indem es die englische Quelle liest und sein Verständnis beim Ausgeben übersetzt. Deshalb müssen Sie keinen separaten Bot oder ein separates Help-Center pro Sprache erstellen und pflegen.
Das ist auch der Grund, warum ein guter Agent „in der Sprache antwortet, in der der Kunde schreibt, ohne manuelle Routing-Regeln", wie eesel's eigene Dokumentation es formuliert. Es gibt keine „Wenn Sprache = Deutsch, weiterleiten an deutschen Bot"-Regel zu pflegen. Die Erkennung erfolgt pro Nachricht, sodass ein Kunde, der mitten im Thread auf Englisch wechselt, Englisch zurückbekommt.

Das praktische Ergebnis: Die Kostenstruktur des mehrsprachigen Supports verändert sich grundlegend. Das alte Modell war: Einen Muttersprachler pro Markt einstellen oder ein Übersetzungstool pro Wort bezahlen. Mit einem KI-Agenten sind Sprachen kein Kostenpunkt. Sie zahlen nicht pro Sprache, sondern pro gelöstem Ticket, unabhängig davon, in welcher Sprache es eingegangen ist – genau so funktioniert eesel's Preismodell.
Wie es aussieht, wenn es tatsächlich funktioniert
Das ist nicht theoretisch. Ich habe es laufen sehen, und das Muster ist konsistent genug, dass ich ihm für Tier-1-Volumen in den wichtigsten Sprachen vertraue.
Ein belgisches Lieferunternehmen auf Freshdesk führte seinen ersten Test-Chat auf Niederländisch durch und fragte nach den Versandkosten nach Deutschland. Der Agent fand die richtigen Tarifdokumente und gab eine detaillierte, spezifische niederländische Antwort mit der tatsächlichen Preisgestaltung – keine niederländischsprachigen Dokumente erforderlich. Ein spanisches Versicherungsmaklerunternehmen auf Zendesk plus Messenger führte in 48 Stunden während eines kostenlosen Tests 564 echte spanische Gespräche durch einen benutzerdefinierten Agenten. Eine rumänische E-Commerce-Plattform erhielt eine vollständige, genaue rumänische Antwort zur Einrichtung eines Zahlungs-Gateways, die als interne Notiz für den Agenten zur Genehmigung hinterlassen wurde.
Was es mir wirklich klar gemacht hat, war eine deutsche Schmuckmarke mit etwa 1.000 Tickets pro Monat auf Zendesk und Shopify. Deren Agent bearbeitete Deutsch, Englisch, Französisch, Niederländisch, Spanisch, Polnisch, Kroatisch und Türkisch – acht Sprachen, von denen niemand eine konfiguriert hat. Es hat es einfach getan, weil das das Standardverhalten ist, kein Feature, das man pro Sprache einschaltet.
Der stärkste einzelne Datenpunkt: Das deutsche Kreditinstitut, das ich in der TL;DR erwähnte, betreibt einen vollautomatischen Agenten auf Zendesk, der über 100.000 Tickets pro Monat auf Deutsch abwickelt, wobei Menschen nur bei Grenzfällen eingreifen. Das ist keine Demo. Das ist eine Produktionswarteschlange, die die meisten Support-Teams als unhandhabbar betrachten würden, die in einer Sprache läuft, die das Team des KI-Anbieters größtenteils nicht spricht.
Wo mehrsprachiger KI-Support tatsächlich scheitert
Jetzt der Teil, den die Fallstudien nicht auf die Landing Page schreiben. Das sind die echten Fehlermodi, und sie handeln fast nie von Grammatik.
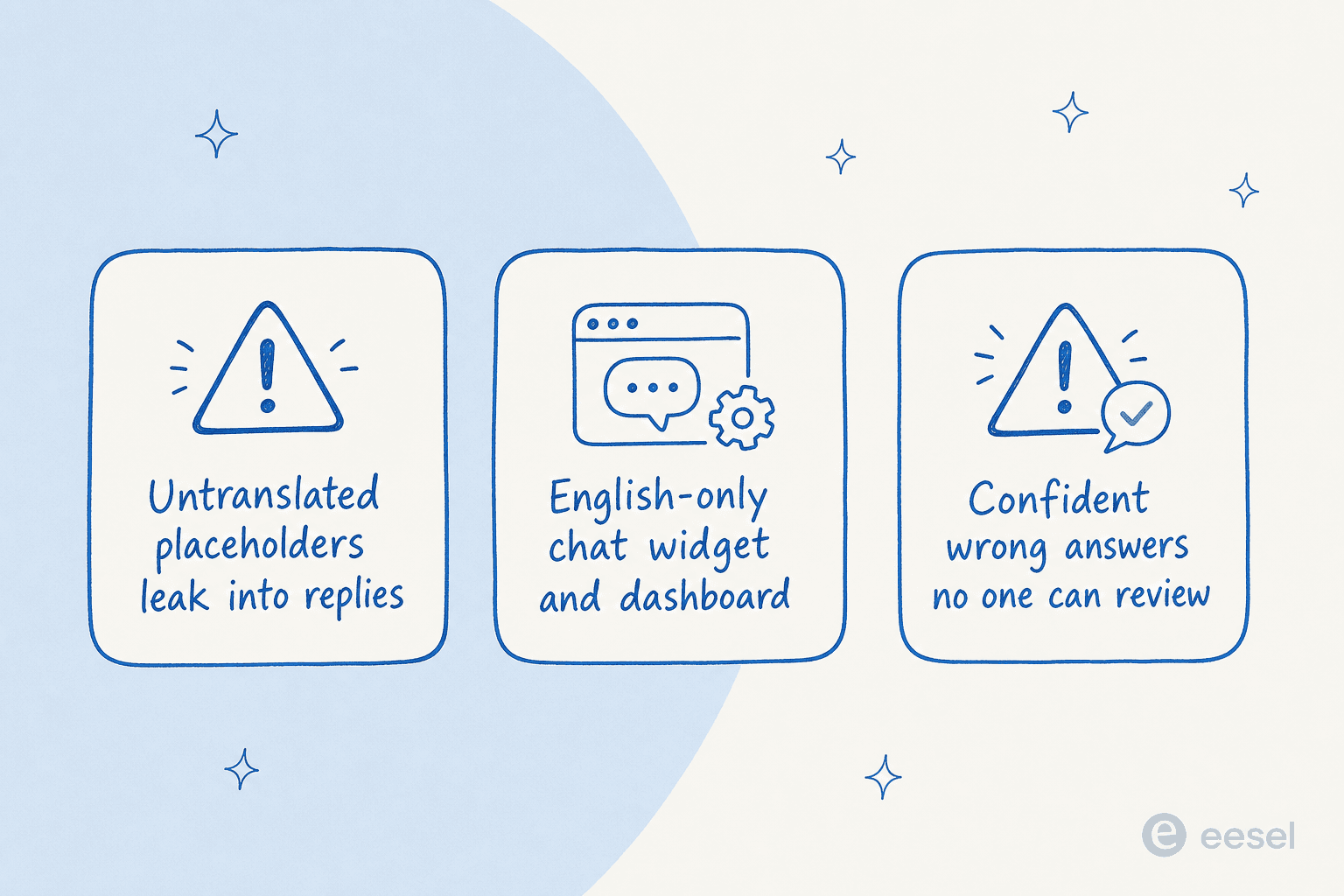
Unübersetzte Platzhalter und interner Text, der durchsickert. Das ist der, den ich echte Teams hat verbrennen sehen. Eine Antwortvorlage hat ein Token wie {{ticket.requester.first_name}} oder ein verirrtes [Employee Name], und im englischen Ablauf wird es korrekt befüllt, aber in einem deutschen oder niederländischen Entwurf leckt der Platzhalter roh durch – oder schlimmer, interner UI-Text ("Customise this Agent") landet in einer Nachricht, die an einen echten Kunden gesendet wird. Das Deutsche ist perfekt. Die Infrastruktur darum herum nicht. Es liest sich für den Endnutzer als defekt, und es zerstört Vertrauen schneller als ein Grammatikfehler es je könnte.
Nur-englische Widgets und Dashboards. Die KI kann tadelloses Deutsch schreiben, aber wenn das Chat-Widget selbst nicht auf Deutsch dargestellt wird oder die Vorschlags-Prompts unabhängig von der Sprache des Kunden auf Englisch stehen bleiben, hat man eine lokalisierte Antwort in einer nicht lokalisierten Hülle. Ein Kunde im deutschen Markt bezeichnete genau das als „Show-Stopper". Es ist eine Erinnerung daran, dass „die KI spricht die Sprache" und „das gesamte Erlebnis ist lokalisiert" zwei verschiedene Maßstäbe sind.
Selbstsichere Falschantworten, die niemand überprüfen kann. Das ist die ernste Sache. Wenn Ihre KI eine falsche Antwort auf Englisch gibt, wird jemand in Ihrem Team sie wahrscheinlich auffangen. Wenn sie eine selbstsichere, flüssige, völlig falsche Antwort auf Türkisch gibt und niemand in Ihrem Team Türkisch liest, kann dieser Fehler wochenlang laufen. Flüssigkeit macht das eigentlich schlimmer – eine falsche Antwort, die autoritativ klingt, ist schwerer zu bezweifeln. Das ist das Risiko, das Ihren gesamten Rollout prägen sollte.
Die Einstellung, die es sicher macht: konfidenzbasiertes Routing
Hier ist das, was „KI kann die Sprache sprechen" in „KI kann die Warteschlange sicher betreiben" verwandelt – und es ist überhaupt kein Sprachfeature.
Der mit Abstand häufigste Einwand, den ich von Käufern höre, ist, dass sie die KI nicht auf alles automatisch antworten lassen wollen. Ein CX-Lead bei einer DTC-Nahrungsergänzungsmarke auf Gorgias, der etwa 7.000 Tickets pro Monat bearbeitet, hat es so klar wie irgend jemand formuliert: Die KI wird niemals 100 % der Fragen beantworten, also brauchten sie „eine KI, die nur die Tickets bearbeitet, bei denen sie sich sicher ist, und alle anderen – in Ruhe lässt." Das ist das ganze Spiel beim mehrsprachigen Support ganz besonders.
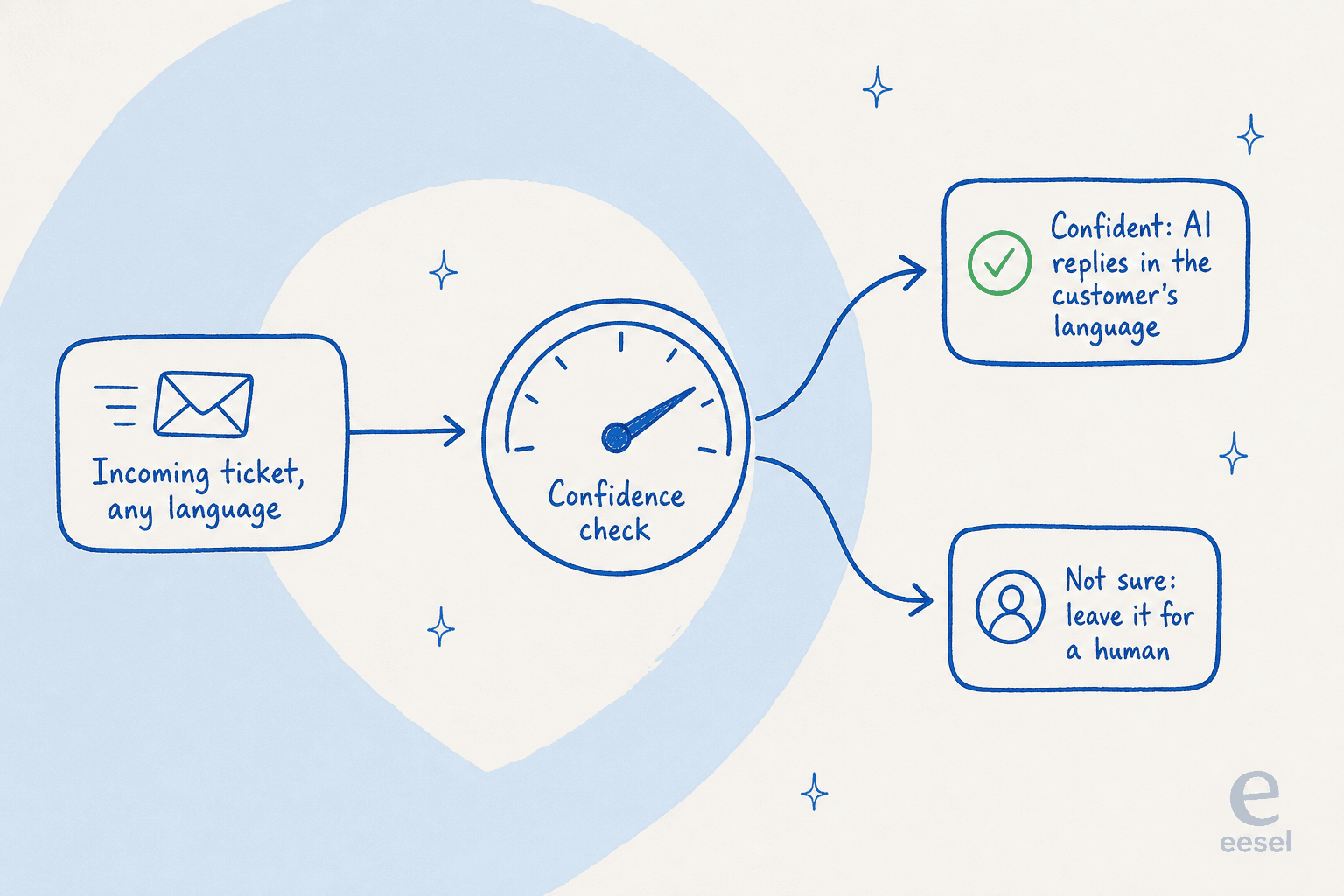
Konfidenzbasiertes Routing bedeutet, dass der Agent nur die Tickets beantwortet, bei denen er sich sicher ist, und den Rest – unberührt – an einen Menschen übergibt. In einem mehrsprachigen Setup ist das kein Nice-to-have, es ist die Sicherheitsschiene, die das Ganze einsatzbereit macht. Die KI bearbeitet die hochsicheren Tier-1-Fragen in jeder Sprache, und die mehrdeutige türkische Rückerstattungsstreitigkeit wird an eine Person eskaliert, anstatt eine flüssige Vermutung zu erhalten. Sie bekommen die Volumenentlastung, ohne Ihren Ruf auf Antworten zu setzen, die Sie nicht lesen können.
Die andere Hälfte der Sicherheit ist das Testen, bevor man vertraut. Der richtige Schritt ist, den Agenten zuerst gegen die eigenen historischen Tickets in jeder Sprache im Entwurfsmodus zu betreiben – wo er Antworten vorschlägt, die ein Mensch genehmigt – und erst auf automatisches Senden umzustellen, sobald man beobachtet hat, dass er bei echtem Volumen richtig liegt. So findet man das Platzhalter-Leck, bevor es ein Kunde tut, nicht danach.
„73 % der Tier-1-Support-Tickets wurden im ersten Monat gelöst."
Kim Simpson, Gridwise, geteilt in eesel's Kundenergebnissen
So führen Sie mehrsprachigen KI-Support ohne Horror-Geschichten ein
Wenn Sie das umsetzen wollen, ist hier die Reihenfolge, der ich tatsächlich folgen würde:
- Verbinden Sie zuerst Ihre echten Wissensquellen. Help-Center, Makros und vergangene Tickets. Sie müssen sie nicht übersetzen – der Agent liest die Quellsprache und antwortet in der Sprache des Kunden. Je reichhaltiger Ihre Wissensdatenbank, desto besser wird jede Sprache auf einmal.
- Simulieren Sie gegen Ihre eigenen vergangenen Tickets, pro Sprache. Lassen Sie den Agenten historische Gespräche in jeder Sprache, die Sie unterstützen, durchlaufen und lesen Sie die Entwürfe. Hier fangen Sie Platzhalter-Lecks, Tonprobleme und die Lücken in Ihren Dokumenten auf.
- Starten Sie im Entwurfsmodus, nicht mit automatischem Senden. Lassen Sie die KI für die erste Zeit Antworten vorschlagen, die ein Mensch genehmigt. Das baut Vertrauen auf und bringt die operativen Randstellen sicher ans Licht.
- Schalten Sie konfidenzbasiertes Routing ein, bevor Sie automatisieren. Entscheiden Sie, was die KI selbstständig senden darf und was immer zu einem Menschen geht. Für Sprachen, die Ihr Team nicht überprüfen kann, halten Sie diesen Schwellenwert konservativ.
- Lokalisieren Sie die Hülle, nicht nur die Antworten. Prüfen Sie, ob das Widget, die Vorschlagsfragen und jede kundengerichtete Benutzeroberfläche tatsächlich in den Sprachen Ihrer Kunden angezeigt werden. Eine perfekte deutsche Antwort in einem nur-englischen Widget liest sich trotzdem als halbfertig.
Tun Sie es in dieser Reihenfolge, und mehrsprachige KI hört auf, ein Glaubenssprung zu sein. Es wird zu etwas, das Sie eingeschaltet, beobachtet und – in dieser Reihenfolge – vertraut haben.
eesel für mehrsprachigen Support ausprobieren
Wenn Sie Support in mehreren Sprachen anbieten, ist eesel KI genau dafür gebaut: ein Agent, der die Sprache jedes Kunden erkennt und aus Ihrer bestehenden englischen Wissensdatenbank darauf antwortet, direkt eingebunden in Zendesk, Freshdesk, Gorgias oder Front. Das entscheidende Unterscheidungsmerkmal ist der Simulationsschritt – Sie können ihn gegen Tausende Ihrer eigenen vergangenen Tickets in jeder Sprache laufen lassen und genau sehen, wie er antworten wird, bevor eine einzige Kundennachricht abgeht, und dann einen Konfidenz-Schwellenwert beibehalten, sodass er nur das automatisch sendet, was er sicher weiß.
Es ist kostenlos auszuprobieren, und da das Preismodell pro Lösung statt pro Arbeitsplatz oder Sprache gilt, kostet die Unterstützung von zwanzig Sprachen dasselbe wie die Unterstützung von einer. Wenn Sie bisher Muttersprachler pro Markt beschäftigt haben, lohnt es sich, diese Rechnung durchzuführen.
Häufig gestellte Fragen
Kann KI mehrsprachigen Kundensupport in vielen Sprachen gleichzeitig übernehmen?
Woher weiß die KI, in welcher Sprache sie antworten soll?
Ist der mehrsprachige KI-Support genau genug, um ihm zu vertrauen?
Was kostet mehrsprachiger KI-Kundensupport?
Was ist das größte Risiko beim mehrsprachigen KI-Support?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








