Die 8 besten KI-Tools für Customer-Support-QA im Jahr 2026
Riellvriany Indriawan
Katelin Teen
Zuletzt bearbeitet June 23, 2026

Warum Support-QA heute völlig anders aussieht
Ich bin im Kundensupport-Team von eesel und lebe in der Queue. Das alte QA-Ritual hat mich immer gestört: Man bewertet eine Handvoll Tickets, schreibt einige Notizen, und die Muster, die wirklich schaden (eine Richtlinie, die jeder falsch versteht, ein Tonproblem auf einem Kanal), kommen Wochen später ans Licht, wenn überhaupt. Die meisten Teams überprüfen zwischen 1 % und 3 % ihrer Support-Interaktionen manuell. Die anderen 97 % sind ein blinder Fleck.
Der eigentliche Grund für den Wandel der QA ist jedoch, dass ich die letzten drei Jahre bei eesel beobachtet habe, wie KI-Agenten in Live-Support-Queues eingesetzt wurden, und ich habe gesehen, wie ein selbstsicher klingender Bot leise eine falsche Antwort gab. Einem Kunden, einem dänischen Fahrzeugtelematik-Team auf Zendesk, ist es früh passiert: Ihr Bot begann Kunden zu sagen „Ja, wir unterstützen Ihr Automodell" für Marken, die nicht in ihrer Datenbank waren, weil das Help-Center sagte „Wir unterstützen alle Modelle." Niemand hat das als Regel geschrieben. Die KI hat es abgeleitet, klang sicher – und lag falsch.
Diese Erfahrung ist genau der Grund, warum ich nun jeden Rollout gegen historische Tickets simuliere, und sie definiert neu, was „Support-QA" bedeutet. Es gibt jetzt zwei Aufgaben:
- QA für bereits stattgefundene Gespräche (menschlich oder KI) – die klassische Scorecard-Aufgabe.
- QA des KI-Agenten vor und nach seiner Antwort, damit er nie die oben beschriebene selbstsichere-aber-falsche Antwort liefert.
Die meisten Tools auf dieser Liste sind sehr gut in Aufgabe eins. Eine kleinere Anzahl macht Aufgabe zwei. Das beste Stack macht beides, und ich werde für jedes Tool kennzeichnen, welches was ist.
Wie KI-Support-QA tatsächlich funktioniert
Wenn Sie nur manuelle QA kennen, lohnt sich ein kurzer Blick auf die Mechanik eines AutoQA-Tools, denn sie ist bei fast allen Anbietern gleich. Sie verbinden Ihre Helpdesk- oder Contact-Center-Plattform, definieren eine Scorecard in einfacher Sprache (Begrüßung, Verifizierung, Empathie, Lösung, Compliance), und die KI liest jedes Gespräch dagegen, gibt eine Bewertung mit der angehängten Begründung zurück und hebt die Hochrisikofälle für einen Menschen hervor.
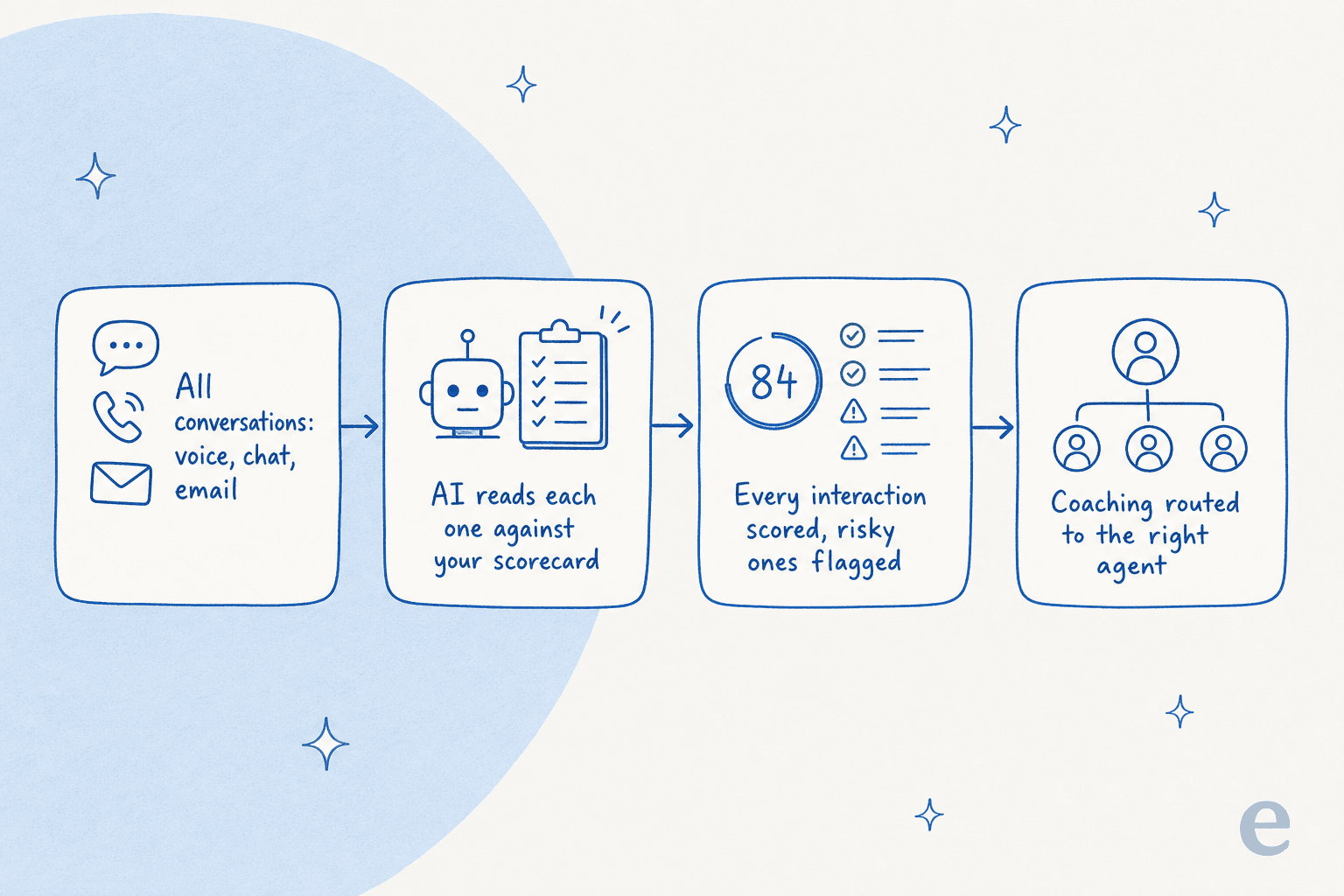
Der Sprung von der Stichprobe zur vollständigen Abdeckung ist real, und die Support-Kennzahlen, denen Sie endlich vertrauen können (konsistente Qualitätswerte, Sentiment-Trends, Eskalationsmuster), werden viel aussagekräftiger, wenn sie auf 100 % der Gespräche basieren. Das eine, das Sie im Hinterkopf behalten sollten: Eine automatische Bewertung ist nur so gut wie ihre Kalibrierung, daher lässt jedes seriöse Tool hier die Bewertung an vergangenen Tickets testen, bevor Sie der Zahl vertrauen.
Was ich gesucht habe
Ich habe diese Faktoren so gewichtet, wie ich es tun würde, wenn ich das Tool für mein eigenes Team kaufen würde:
- Abdeckung. Bewertet es tatsächlich 100 % der Gespräche, oder ist es Sampling mit zusätzlichen Schritten?
- Scorecard-Flexibilität. Kann ich meine eigenen Kriterien in einfacher Sprache schreiben und die Begründung hinter jeder Bewertung sehen?
- Die Coaching-Schleife. Bewertung ist die halbe Arbeit. Schließt es die Schleife in Agenten-Coaching und Verbesserung?
- KI-Agenten-QA. Bewertet es (und testet es vorab) Bot-Gespräche, nicht nur menschliche?
- Preistransparenz. Kann ich eine Zahl sehen, oder muss ich ein Verkaufsgespräch führen, um zu erfahren, ob ich es mir leisten kann?
- Passform. Helpdesk-nativ und für kleine Teams geeignet, oder für ein 500-Sitzplatz-Voice-Contact-Center gebaut?
Die besten KI-Tools für Support-QA im Jahr 2026 auf einen Blick
| Tool | Am besten für | AutoQA-Abdeckung | Bewertet KI-Agenten? | Startpreis | Bewertung |
|---|---|---|---|---|---|
| eesel AI | QA des KI-Agenten vor dem Go-live | Simulation auf 100 % vergangener Tickets | Ja, das ist seine Kernaufgabe | 0,40 $ / Ticket, keine Sitzplatzgebühr | 4,6 / 5 (G2) |
| Zendesk QA | Teams bereits auf Zendesk | 100 % (AutoQA) | Ja (KI-Agenten-QA) | ~35 $ / Agent / Monat (Add-on) | 4,9 / 5 (Capterra, n=23) |
| MaestroQA | Enterprise, tiefe Anpassung | 100 % (AutoQA) | Ja | Nur auf Anfrage | 4,7 / 5 (G2, 324) |
| EvaluAgent | Mittelstand, QA + Coaching | 100 % (AutoQM) | Ja (Bot-Observability) | 35 $ / Benutzer / Monat | 4,5 / 5 (G2, 440) |
| Loris (Contentsquare) | Gesprächsanalyse in großem Maßstab | 100 % | Ja (KI-Agenten-Analytik) | Nur auf Anfrage | 4,8 / 5 (G2, 11) |
| Level AI | Contact Center mit Echtzeit-Bedarf | 100 % (QA-GPT) | Teilweise | Nur auf Anfrage | 4,7 / 5 (G2, 200) |
| Playvox (NiCE) | QA mit WFM gebündelt | 100 % (AutoQA) | Begrenzt | Nur auf Anfrage | 4,8 / 5 (G2, 1.163) |
| Cresta | Großes Enterprise Voice | 100 % (Qualitätsmanagement) | Ja (einheitliches Scoring) | Nur auf Anfrage | 4,2 / 5 (G2, 43) |
Eine Möglichkeit, das Feld zu lesen: Es teilt sich klar nach Zielgruppe auf. Helpdesk-nativ und für kleine Teams geeignet auf der einen Seite, Enterprise-Voice und Contact-Center auf der anderen.
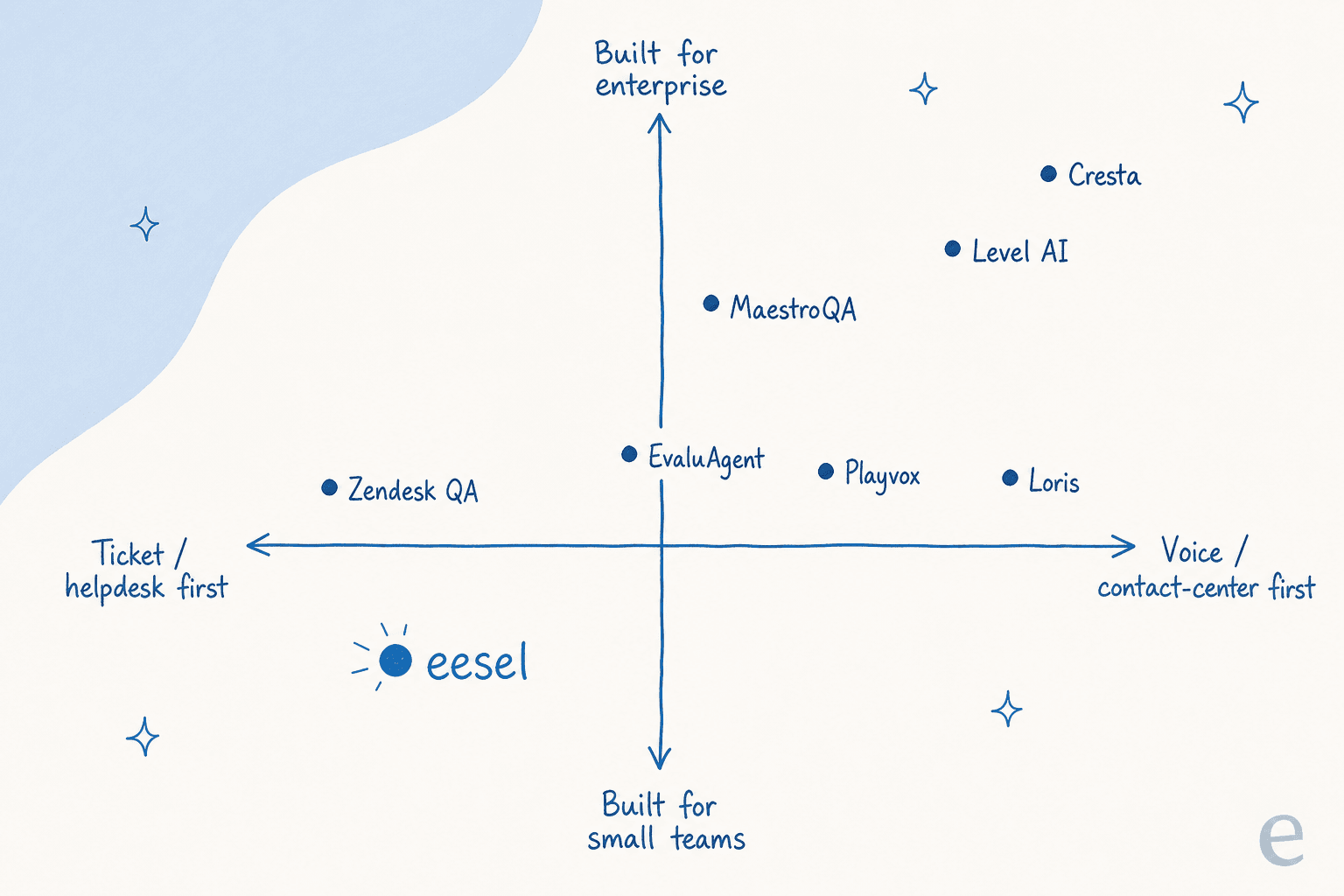
Wenn Sie keinen Quadranten betrachten möchten, hier ist dieselbe Logik als schnelle Auswahl.
Nun zu den Tools im Detail.
1. eesel AI
Am besten für: QA Ihres KI-Support-Agenten vor und nach dem Kundenkontakt.
Lassen Sie mich direkt erklären, warum eesel eine QA-Liste anführt, denn es ist kein traditionelles Scorecard-Tool. eesel ist ein KI-Support-Agent, der sich in Ihren bestehenden Helpdesk einklinkt, aus Ihren vergangenen Tickets und Dokumenten lernt und Tickets beantwortet. Der Grund, warum es hierher gehört: Die einzige QA mit dem höchsten Einsatz im Jahr 2026 betrifft die eigenen Antworten der KI, und eesel ist darauf ausgerichtet, diese Antworten vor dem Go-live zu testen.
Was es für QA tut. eesel's Simulationsmodus führt die KI gegen Tausende Ihrer echten historischen Tickets aus und zeigt Ihnen genau, wie sie geantwortet hätte, was sie gelöst hätte und wo sie gestolpert wäre – aufgeschlüsselt nach Thema. Sie sehen Abdeckung und Genauigkeit, bevor ein einziger Kunde betroffen ist, beheben dann die Lücken und führen die Simulation erneut aus. Auf der Live-Seite sorgt konfidenzbasiertes Routing dafür, dass die KI nicht antwortet, wenn sie unsicher ist: Tickets mit geringer Konfidenz werden zu Entwürfen für einen Menschen statt zu autonomen Antworten. Das ist die Absicherung, die den „Wir unterstützen Ihr Automodell"-Fehler verhindert hätte.
Stärken.
- Es bewertet das, was die meisten Listen ignorieren: die eigene Ausgabe der KI, vor dem Go-live.
- Lernt aus gelösten Tickets, nicht nur aus Help-Center-Artikeln, sodass die Simulation widerspiegelt, wie Ihr Team tatsächlich antwortet.
- Jede Live-Antwort kann überprüft und korrigiert werden, und diese Korrekturen verbessern zukünftige Antworten.
- Echter Self-Service-Setup, mit 100+ Integrationen für Zendesk, Freshdesk, Gorgias, Front, HubSpot und Slack.
Einschränkungen.
- Es ist keine Scorecard-Plattform für menschliche Agenten. Wenn Ihre Aufgabe darin besteht, 200 menschliche Agenten nach einer Bewertungsmatrix zu benoten und Kalibrierungssitzungen abzuhalten, ist ein dediziertes Tool wie Zendesk QA oder MaestroQA die bessere Wahl – und die ehrliche Antwort ist, eesel parallel zu einem solchen zu betreiben.
- Die Berichterstattung ist auf KI-Leistung und Ticket-Themen ausgerichtet, nicht auf formelle QA-Einsprüche oder HR-taugliche Leistungspläne.
Preise. Nutzungsbasiert und transparent – was in dieser Kategorie selten ist.
| Plan | Preis | Hinweise |
|---|---|---|
| Kostenlose Testversion | 50 $ in kostenlosem Guthaben | Keine Kreditkarte |
| Pay-as-you-go | Ab 0,40 $ / Ticket | Keine Sitzplatzgebühr, keine Plattformgebühr, kein Minimum |
| Jahresvertrag | 25 % weniger | Verpflichtung zu 300 $+/Monat für das Jahr |
| Enterprise | 1.000 $/Monat Plattformgebühr + Nutzung | SSO, HIPAA, BAA, dedizierter SE |
Meine Einschätzung: Wählen Sie eesel, wenn der KI-Agent das ist, was Sie einer QA unterziehen möchten. Ein Kunde, Gridwise, sah eesel 73 % der Tier-1-Anfragen im ersten Monat lösen, mit Ergebnissen während einer 7-Tage-Testphase – genau weil sie zunächst simulieren und der Abdeckung vertrauen konnten, bevor sie es aktivierten. Kombinieren Sie es mit einem der nachfolgenden Scorecard-Tools, wenn Sie auch formelle QA für menschliche Agenten benötigen.
2. Zendesk QA (früher Klaus)
Am besten für: Teams, die bereits in Zendesk arbeiten.
Zendesk QA ist das frühere estnische Startup Klaus, das Anfang 2024 von Zendesk übernommen wurde und als Pro-Agenten-Add-on in die Plattform integriert wurde. Es ist die natürlichste Wahl, wenn Ihr Support bereits auf Zendesk läuft, und eesel-Kunden nutzen es regelmäßig zur Bewertung der KI-Agenten-Leistung.
Was es tut. AutoQA bewertet jede Interaktion über alle Kanäle hinweg, einschließlich KI-Agenten und Voice, mit sofort einsatzbereiten Kategorien (Empathie, Lösung) plus no-code benutzerdefinierten promptbasierten Kategorien. Spotlight markiert automatisch Abwanderungsrisiken, Eskalationen und Wissenslücken, und KI-Agenten-QA vergleicht menschliche und Bot-Bewertungen nebeneinander.
Stärken.
- 100 % Abdeckung statt Stichproben, nativ zu Zendesk.
- No-code benutzerdefinierte Kategorien, die Sie in einfacher Sprache schreiben.
- Starker Klaus-Ruf. Wie ein Reddit-Nutzer beim Vergleich von Anbietern sagte: „+1 für Klaus, ich hatte nie Probleme mit ihnen, der Support war großartig."
„Sampling + CSAT erfasst nur einen Bruchteil der Probleme, sodass Muster spät auftauchen." – ein Support-Manager beschreibt das Problem, das AutoQA löst, r/Zendesk
Einschränkungen.
- Es ist ein kostenpflichtiges Add-on zusätzlich zu einem bereits teuren Basisplan. Ein Capterra-Rezensent formulierte den Nachteil klar: „Ein bisschen teuer."
- Die Anpassung ist weniger tief als MaestroQA für ungewöhnliche Bewertungsmatrizen.
- Die Berichtsoberfläche verlangsamt sich bei vielen Agenten.
Preise. Der eigenständige QA-Add-on-Preis wird nicht veröffentlicht; Community-Schätzungen setzen ihn bei etwa $35/Agent/Monat, und das gebündelte WFM + QA-Paket kostet 50 $/Agent/Monat, alles zusätzlich zu einem $19 bis $115/Agent-Basisplan.
Meine Einschätzung: Wenn Sie auf Zendesk sind, ist das die Standardwahl – und eine gute. Es wird mit 4,9/5 auf Capterra bewertet (kleine Stichprobe, n=23). Planen Sie einfach die gestapelten Add-on-Kosten ein und denken Sie daran, dass es Gespräche nach dem Fait bewerten, statt Ihren Bot vorzutesten.
3. MaestroQA
Am besten für: Enterprise-Teams, die eine tiefe, transparente, anpassbare Bewertung wünschen.
MaestroQA begann 2017 als Contact-Center-QA-Tool und hat sich als „Conversation-Data-Plattform" neu positioniert, die von Support-Organisationen bei Etsy, DraftKings, Stitch Fix und Brex genutzt wird. Es befindet sich am Enterprise-Ende und verdient diese Einordnung.
Was es tut. AutoQA analysiert 100 % der Tickets und leitet menschliche Prüfer explizit dorthin, wo Urteilsvermögen wichtig ist. Das Herausragende ist die KI-Plattform, eine Prompt-zu-Metrik-Engine, bei der Sie die Regel schreiben, sie an echten Tickets testen und die Begründung sehen, bevor Sie sie starten – positioniert gegen „Black-Box-Tools". Dazu kommt GPT-basierte Root-Cause-Analyse und KI-Kalibrierung.
Stärken.
- Tiefe Anpassbarkeit. Ein Support-Operator, der es bei mehreren Unternehmen nutzte, sagte, es „erlaubt ein hohes Maß an Anpassung" und eignet sich für „größere Umgebungen mit datengesteuerten Metriken."
- Transparentes, kontrollierbares Scoring (Sie sehen die Begründung).
- Starke Zendesk-Integration und 16+ Konnektoren.
Einschränkungen.
- Nur auf Anfrage und teuer. G2 markiert die wahrgenommenen Kosten in der höchsten „$$$$$"-Stufe, und ein wiederkehrender Nachteil ist, dass „KI-Funktionen zusätzliche Käufe erfordern, was die Kosten erheblich treibt."
- Ungefähr eine 3-monatige Implementierung; schwer für kleine Teams.
„Ich habe Maestro bei einigen Unternehmen verwendet und war generell zufrieden... es erlaubt ein hohes Maß an Anpassung. Die neueren KI-basierten Funktionen sind irgendwie interessant, aber ich habe sie nicht eingesetzt, also kann ich nicht sagen, wie gut sie wirklich funktionieren." – Brosenjew, r/Zendesk
Meine Einschätzung: Die Wahl für ein ernsthaftes, gut ausgestattetes QA-Team, das seine Bewertungsmatrix besitzen und die Begründung hinter jeder Bewertung sehen möchte. Es wird mit 4,7/5 aus 324 G2-Bewertungen bewertet. Kleinere Teams werden es als überdimensioniert empfinden, und Sie können den Preis nicht ohne ein Verkaufsgespräch prüfen.
4. EvaluAgent
Am besten für: mittelständische Teams, die QA plus Coaching wünschen, mit Preisen, die Sie tatsächlich sehen können.
EvaluAgent ist eine britische QA- und Conversation-Intelligence-Plattform, die „vollständige Transparenz über jeden Agenten, menschlich und KI" verspricht. Es ist das seltene Tool in dieser Kategorie, das Richtpreise veröffentlicht, was ich schätze.
Was es tut. AutoQM bewertet jedes Gespräch automatisch über Voice, Chat und E-Mail, mit SmartScore-KI-Zeileneinträgen, die jeder Bewertung eine Begründung beifügen. Gemischte Scorecards kombinieren automatische Prüfungen mit menschlicher Beobachtung („KI übernimmt die Routine, Menschen übernehmen das Urteil"), und der Context Engine hat eine Testkonsole, um Scoring-Änderungen an archivierten Gesprächen auszuprobieren, bevor sie live gehen. Sein KI-Agenten-Observability bewertet Bots von jedem Anbieter gegen Ihre Wissensbasis, einschließlich Halluzinationserkennung.
Stärken.
- Eine der vollständigsten Coaching-Schleifen in der Kategorie: 1-zu-1s, HR-taugliche Pläne, Gamification, Agenten-Einsprüche.
- Wirklich transparente Preise und ein dedizierter CSM auf jeder Stufe.
- Starke Compliance-Position (SOC 2 Type II, ISO 27001, DSGVO, HIPAA), gut für regulierte Branchen.
Einschränkungen.
- Scorecard-Setup ist der Reibungspunkt. Die Hauptbeschwerde eines G2-Rezensenten: „die Zeit und Klarheit, die erforderlich sind, um eine Scorecard zu entwerfen... der KI-gestützte Scorecard-Builder sollte verbessert werden."
- Die Benutzeroberfläche hat für Neulinge eine Lernkurve, laut G2.
Preise. Veröffentlicht und pro Sitzplatz.
| Plan | Preis | Für |
|---|---|---|
| AutoQM & Verbesserung | Ab 35 $ / Benutzer / Monat | Menschliche Agenten: automatische Bewertung + Coaching |
| AutoQM + Conversation Intelligence | Ab 65 $ / Benutzer / Monat | Fügt Sentiment, Intent, prädiktive VoC hinzu |
| AutoQM für KI-Agenten | Ab 0,05 $ / Gespräch | Bot-Qualitätsbewertung |
| Vollpaket für KI-Agenten | Ab 0,13 $ / Gespräch | Bot-QA + Conversation Intelligence |
Meine Einschätzung: Mein Favorit unter den dedizierten Scorecard-Tools für mittelständische Teams. Es wird mit 4,5/5 aus 440 G2-Bewertungen bewertet, die Coaching-Tiefe ist real, und man kann tatsächlich budgetieren. Planen Sie einfach Zeit für das Scorecard-Setup ein.
5. Loris (jetzt Contentsquare Conversation Intelligence)
Am besten für: Gesprächsanalyse und Voice-of-Customer in großem Maßstab.
Loris hat eine ungewöhnliche Geschichte: Es begann als gewinnorientierter Ableger von Crisis Text Line, was 2022 zu einer bemerkenswerten Datenschutzkontroverse wurde, und wurde 2025 von Contentsquare übernommen. Es wird jetzt als Contentsquare's Conversation-Intelligence-Linie vertrieben.
Was es tut. Automatisierte QA bewertet jedes Gespräch und verknüpft wichtig Qualitätssignale mit echten Ergebnissen wie Wiederholungskontakten und Eskalationen, sodass die Bewertung keine Eitelkeitszahl ist. Conversation Insights decken Intent und Sentiment-Verschiebungen im Zeitverlauf auf, und KI-Agenten-Analytik verfolgt Bot-Eindämmung, Transfers und Abbrüche.
Stärken.
- Analysetiefe und sofort einsatzbereites Intent-Tagging, das Rezensenten hervorheben.
- Herausragendes Implementierungs- und Support-Team (das konsistenteste Lob auf G2).
- Verknüpft QA mit Ergebnissen, nicht nur mit Rubrik-Bestehensraten.
Einschränkungen.
- Sentiment ist nicht perfekt. G2's eigene Zusammenfassung weist darauf hin, dass die KI „die Kundenstimmung möglicherweise nicht immer genau widerspiegelt" – was für ein Tool wichtig ist, dessen Kernaussage die automatische Bewertung ist.
- Es ist jetzt eine Funktion einer größeren Analysesuite, kein eigenständiger QA-Anbieter.
- Nur auf Anfrage, enterprise-orientiert, und die kleine G2-Stichprobe (11 Bewertungen) macht die Crowd-Validierung schwierig.
Meine Einschätzung: Stark, wenn Sie Gesprächsanalyse und VoC neben QA möchten und sich wohl dabei fühlen, in das Contentsquare-Ökosystem einzukaufen. Es wird mit 4,8/5 auf G2 bewertet, aber die geringe Rezensionsanzahl und die Übernahme sind echte Überlegungen.
6. Level AI
Am besten für: Contact Center, die semantisches AutoQA plus Echtzeit-Unterstützung wünschen.
Level AI positioniert sich als die „Intelligenz- und Orchestrierungsschicht für das Kundenerlebnis" und analysiert 100 % der Interaktionen über Voice, Chat und E-Mail mittels semantischen Verstehens statt Schlüsselwortabgleich.
Was es tut. Seine QA-GPT-Engine nutzt ein auf Ihren eigenen Daten trainiertes LLM, um über 90 % der Scorecard-Standards zu bewerten, einschließlich subjektiver Elemente, und liefert transparente Bewertungen mit unterstützenden Belegen. Es kombiniert das mit Agenten-Bildschirmaufzeichnung, Echtzeit-AgentGPT-Unterstützung und einem Coaching-Modul.
Stärken.
- Semantisches NLU bewertet subjektive Rubrikelemente, nicht nur exakte Phrasen. Ein Operator: „Wir sind von der manuellen Bewertung von 1–2 % unserer Anrufe zu 100 % Bewertung übergegangen."
- Echtzeit-Unterstützung plus Bildschirmaufzeichnung mit starker Schwärzung, geschätzt in regulierten Branchen.
Einschränkungen.
- Die Bewertungsgenauigkeit reift noch – der häufigste G2-Nachteil. Ein Rezensent bemerkte, dass das System „den Agenten abwerten kann", wenn er nicht genau ein Wort verwendet hat, obwohl er eindeutig konform war.
- Nur auf Anfrage mit einer öffentlichen Preisseite, die einen 404 gibt, und ungefähr einer 3-monatigen Implementierung.
- Für Anruf-/Contact-Center gebaut; schwer für ein kleines ticketbasiertes Team.
„Es hat QA für mein Team bedeutungsvoll gemacht. Es war einfach einzurichten und zu nutzen." (Der Nachteil: „Das Prompting-Setup braucht etwas Feinabstimmung, um es genau richtig zu bekommen.") – Validierter Rezensent, Level AI auf G2
Meine Einschätzung: Eine starke Contact-Center-Wahl, bewertet mit 4,7/5 aus 200 G2-Bewertungen. Die Echtzeit-Schicht ist das Unterscheidungsmerkmal. Rechnen Sie damit, das Scoring zu kalibrieren und mit dem Vertrieb über eine Zahl zu sprechen.
7. Playvox by NiCE
Am besten für: Teams, die QA in einer vollständigen Workforce-Suite gebündelt wünschen.
Playvox ist eine digital-first Workforce-Engagement-Suite (QA, WFM, Coaching, Lernen, VoC, Gamification), die im Oktober 2024 von NiCE übernommen wurde und in den CXone-Stack integriert wird.
Was es tut. AutoQA (aufgebaut auf der Prodsight-Übernahme) erweitert QA auf 100 % der Interaktionen mit sentiment-basierter Bewertung und befindet sich in einer Suite neben WFM und Coaching. Es verbindet sich mit Zendesk, Salesforce, Freshdesk, Kustomer und Help Scout.
Stärken.
- Breite: QA, WFM, Coaching, Lernen und Gamification in einer Plattform.
- Starke native Integrationen (20+) und ein dominantes Benutzerfreundlichkeitsthema in Bewertungen.
- Sehr hohe Bewertungen: 4,8/5 über 1.163 G2-Bewertungen.
Einschränkungen.
- Nachübernahme-Unsicherheit. NiCE führt mit dem WFM-Winkel, die eigenständige Website ist ausgehöhlt, und die Roadmap ist im Fluss.
- G2-Nachteile nennen schwache Berichterstattung und begrenzte Anpassbarkeit.
- Nur auf Anfrage, keine kostenlose Version, und ein breites Plattformgewicht, das für ein kleines Team schwer ist.
Meine Einschätzung: Macht am meisten Sinn, wenn Sie QA als Teil eines vollständigen Workforce-Management-Stacks wünschen, besonders wenn Sie sich bereits in Richtung NiCE CXone bewegen. Als fokussiertes, unabhängig entwickelndes QA-Tool ist es weniger sicher als noch vor einem Jahr.
8. Cresta
Am besten für: große Enterprise-Voice-Operationen, die Echtzeit-Coaching wünschen.
Cresta ist eine Enterprise-CX-KI-Plattform, die 2017 aus dem Stanford AI Lab ausgegründet wurde und $280M+ eingesammelt hat, die großen Voice-Operationen wie United Airlines, Marriott und Verizon bedient. Es ist gut finanziert, skaliert und unapologetisch enterprise.
Was es tut. Cresta Quality Management bewertet automatisch 100 % der Gespräche mit generativer KI, korreliert das Verhalten der Agenten mit Geschäftsergebnissen und bewertet sowohl menschliche als auch virtuelle Agenten nach einer Rubrik. Sein Markenzeichen ist die Echtzeit-Agent-Assist, die Agenten live mitten im Gespräch coacht, statt nur nach dem Anruf.
Stärken.
- Echtzeit, nicht nur nach dem Anruf. Ein Holiday Inn Club Vacations-Direktor: „Cresta ist sofortig... es ist 100 % besser, weil es sofortiges Coaching ist."
- 100 % Abdeckung mit quantifizierten Ergebnissen. Ein Oportun VP: „Wir sind von einem Stichprobenansatz zu 100 % QA" übergegangen mit einer 50 %igen Arbeitslastreduzierung des QA-Teams.
- Als Leader im Forrester Wave für Conversation Intelligence, Q2 2025 eingestuft.
Einschränkungen.
- Nur Enterprise. Cresta's eigenes ICP nennt „250+ Mitarbeiter" und „$250M+" Umsatz und listet Kleinunternehmen als nicht ideal auf.
- Opakes, modulbasiertes Pricing, das einen Vertriebszyklus erfordert, um es auch nur zu schätzen.
- Integrationen sind servicegesteuert. Ein ehemaliger Mitarbeiter auf Reddit bemerkte, dass sie „alle von einem Professional-Services-Team verwaltet werden."
Meine Einschätzung: Wenn Sie ein großes Voice-Contact-Center betreiben und Live-Coaching wünschen, ist Cresta ein echter Leader, auch mit einem bescheidenen 4,2/5 aus 43 G2-Bewertungen. Für ein modernes ticketbasiertes Helpdesk oder ein kleines Team hat es die falsche Form und das falsche Budget.
Also, welches wählen Sie tatsächlich?
Nachdem ich in diesem Bereich gelebt habe, ist die Entscheidung weniger „welches Tool ist das beste" und mehr „was QA-en Sie":
- Sie bewerten menschliche Agenten auf einem Helpdesk: Zendesk QA wenn Sie auf Zendesk sind, EvaluAgent wenn Sie transparente Preise und Coaching wünschen, MaestroQA wenn Sie Enterprise sind und die Rubrik besitzen möchten.
- Sie betreiben eine große Voice-Operation: Cresta oder Level AI für die Echtzeit-Schicht, oder Playvox wenn Sie es mit WFM gebündelt möchten.
- Sie setzen einen KI-Agenten in Ihrer Queue ein: Beginnen Sie mit QA an der KI selbst. Das ist das Gespräch, das am wahrscheinlichsten eine selbstsichere-aber-falsche Antwort liefert, und es ist das, das ein Scorecard-Tool erst nach dem Sehen durch den Kunden erwischt.
Dieser letzte Punkt ist der, den ich am stärksten betonen würde, weil er die Lücke ist, in die Teams immer wieder fallen. Sie können die beste Scorecard-Plattform auf dieser Liste kaufen und dennoch Ihren KI-Agenten haben, der Kunden falsche Informationen gibt – weil die QA nach der Antwort stattfindet. Die Lösung ist, den Bot vor dem Sprechen zu QA-en.
eesel für KI-Agenten-QA ausprobieren
Wenn Sie einen KI-Support-Agenten einsetzen, ist das der Ort, wo eesel seinen Platz auf der Liste verdient. Statt darauf zu warten, die Antworten der KI zu benoten, nachdem Kunden sie gesehen haben, spielt eesel's Simulationsmodus Tausende Ihrer echten vergangenen Tickets erneut ab und zeigt Ihnen genau, wie die KI geantwortet hätte, was sie gelöst hätte und wo sie gescheitert wäre – bevor sie live geht. Dann hält konfidenzbasiertes Routing sie davon ab, zu antworten, wenn sie unsicher ist.

Es verbindet sich in Minuten mit Ihrem bestehenden Helpdesk, lernt aus Ihren gelösten Tickets und ist kostenlos ausprobierbar ohne Kreditkarte. Wenn Ihre eigentliche Sorge beim KI-Support „wird es falsch antworten" ist, ist das genau die Sorge, für deren Beseitigung eesel entwickelt wurde. eesel ausprobieren.
Häufig gestellte Fragen
Was ist die beste KI für Customer-Support-QA im Jahr 2026?
Wie viel kostet KI-Support-QA-Software?
Kann KI wirklich 100 % der Support-Gespräche bewerten?
Worauf sollte ich bei einem KI-Support-QA-Tool achten?
Unterscheidet sich KI-Support-QA von der QA eines KI-Agenten?
Hat Zendesk integrierte KI-Qualitätssicherung?
Wie kann ich einen KI-Support-Agenten vor dem Go-live einer QA unterziehen?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.



