
What FAQ deflection actually means (and three numbers people confuse)
Strip away the jargon and FAQ deflection is simple: a customer has a question you've answered a thousand times, and something other than a human answers it. That "something" used to be a help-center article they had to go find. Now it's increasingly an AI agent sitting in the live chat widget or replying to the email before it hits an agent's queue.
The trap is that "deflection" gets thrown around as if it's one number, when buyers are usually staring at three different ones. They are not the same, and conflating them is how you end up "deflecting 70% of tickets" while CSAT quietly tanks.
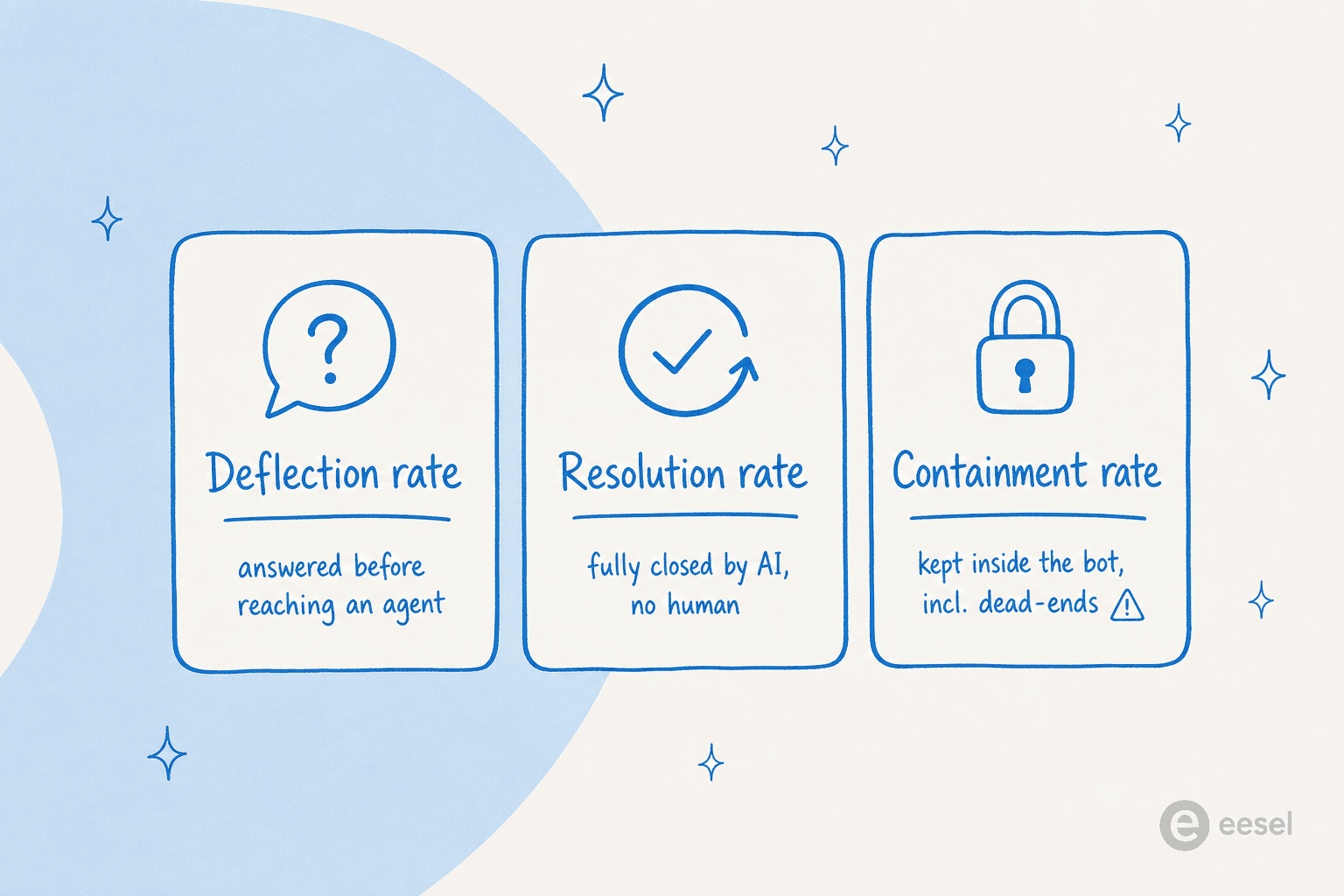
- Deflection rate is the share of questions answered before they reach an agent. It's the headline number, and the one this post is about. There's a full breakdown in our guide to deflection rate.
- Resolution rate is the share the AI fully closed with no human ever stepping in. A question can be deflected from the queue but not actually resolved, if the answer was weak enough that the customer gives up or re-asks.
- Containment rate is the share kept inside the bot, including the dead-ends. This is the dangerous one: a bot that traps a frustrated customer in a loop and never hands off scores a great containment number and a terrible experience. It's worth measuring containment and escalation quality together, not in isolation.
The number you actually want to optimise is "questions answered correctly without a human," not "questions kept away from a human." Those sound identical and are completely different in practice. If you only take one thing from this section: a high containment rate with no handover is a red flag, not a win. Our breakdown of AI vs human deflection goes deeper on why.
Why repetitive FAQs quietly burn out a support team
Here's the part I lived before I'll tell you the fix. On any normal support queue, a huge chunk of volume is the same handful of questions. Order status. Refund policy. How to change a plan. Where's the invoice. Business hours. None of them are hard. All of them are relentless.
One DTC supplements team I worked with was running about 7,000 email tickets a month on Gorgias, and more than half were WISMO ("where is my order"), subscription tweaks, and basic product questions. Their agents weren't burning out on hard problems. They were burning out on the boring ones, the ones that don't get easier on the two-hundredth repetition, just heavier. That's the actual cost of un-deflected FAQs: not the minutes per ticket, but the slow erosion of the people answering them, who could be doing work that needs a brain.
This is where reducing ticket volume with AI stops being a cost-cutting line and starts being a retention-of-your-good-agents line. Deflecting FAQs isn't about replacing the team. It's about not making your team do the one part of the job that any well-trained system can do.
How AI actually deflects an FAQ
Mechanically, a modern AI agent does four things on every incoming question. It's worth understanding the flow, because it's exactly where the "will it answer wrong?" fear gets resolved.
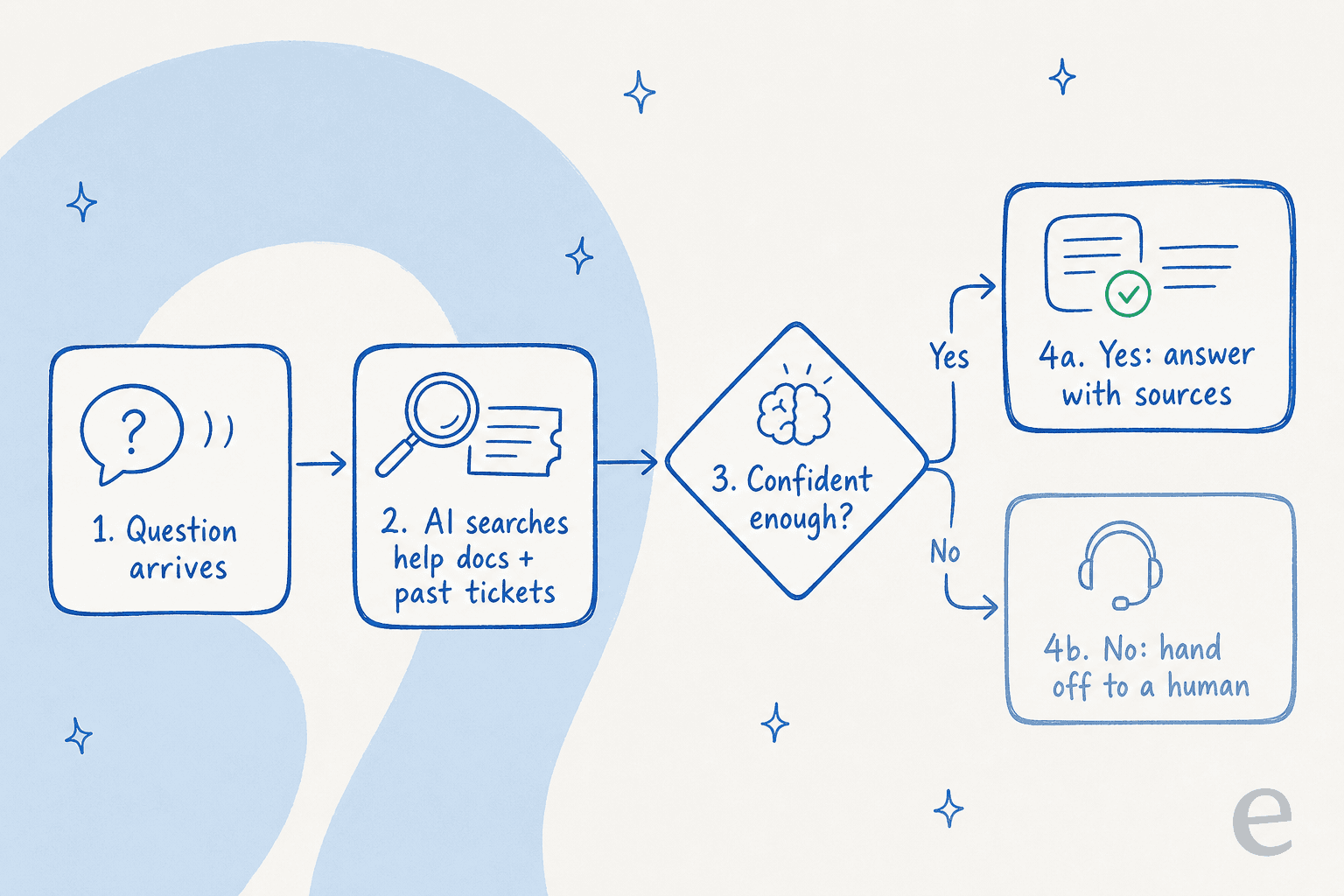
- It reads the question and figures out intent, even when the customer phrases it nothing like your help article does.
- It searches your knowledge — help center, past resolved tickets, internal docs, macros — for the actual answer. The best agents train on your knowledge base and your solved tickets, which is what lets them sound like your team instead of a generic FAQ bot.
- It checks its own confidence. This is the step that matters most. If the answer is well-supported, it replies. If it's a coin-flip, it doesn't guess.
- It answers with sources, or hands off cleanly to a human when it's not sure.
The handover is the unglamorous hero of the whole thing. A real chat I pulled from our logs went exactly like this: a customer on an SEO tool's chat widget asked "how do I delete keywords from my project?", got a clean doc-sourced answer, asked a second how-to, got that too, then typed "can I talk to a human?" — and the agent handed off to the team instantly, no fighting, no loop. Two FAQs deflected, zero friction on the escalation. That's the pattern you're aiming for, and it's the opposite of the FAQ-bot-from-hell everyone's been trapped in.
Permissioned customer results back this up. eesel resolved 73% of tier-1 requests in the first month for the gig-economy analytics app Gridwise, with results showing inside a 7-day trial:
"In the first month, eesel is resolving 73% of our tier-1 requests... Our team implemented and achieved results quickly during our 7-day trial. Responses are simple to fix and adjust."
Kim Simpson, Gridwise (eesel AI helpdesk agent)
The reason confidence routing matters so much is the thing I quoted up top. As one CX lead put it to me, the AI doesn't need to answer 100% of questions; it needs to answer the ones it's sure about and leave the other ones alone. An AI that confidently makes something up is worse than no AI, because now you're cleaning up after it and paying for the privilege. If you want to go deeper on that failure mode, we wrote a whole piece on preventing AI hallucinations in support.
What you should deflect (and what you shouldn't)
Not every question is a deflection candidate, and pretending otherwise is how teams get burned. After watching a lot of rollouts, the line is pretty consistent.
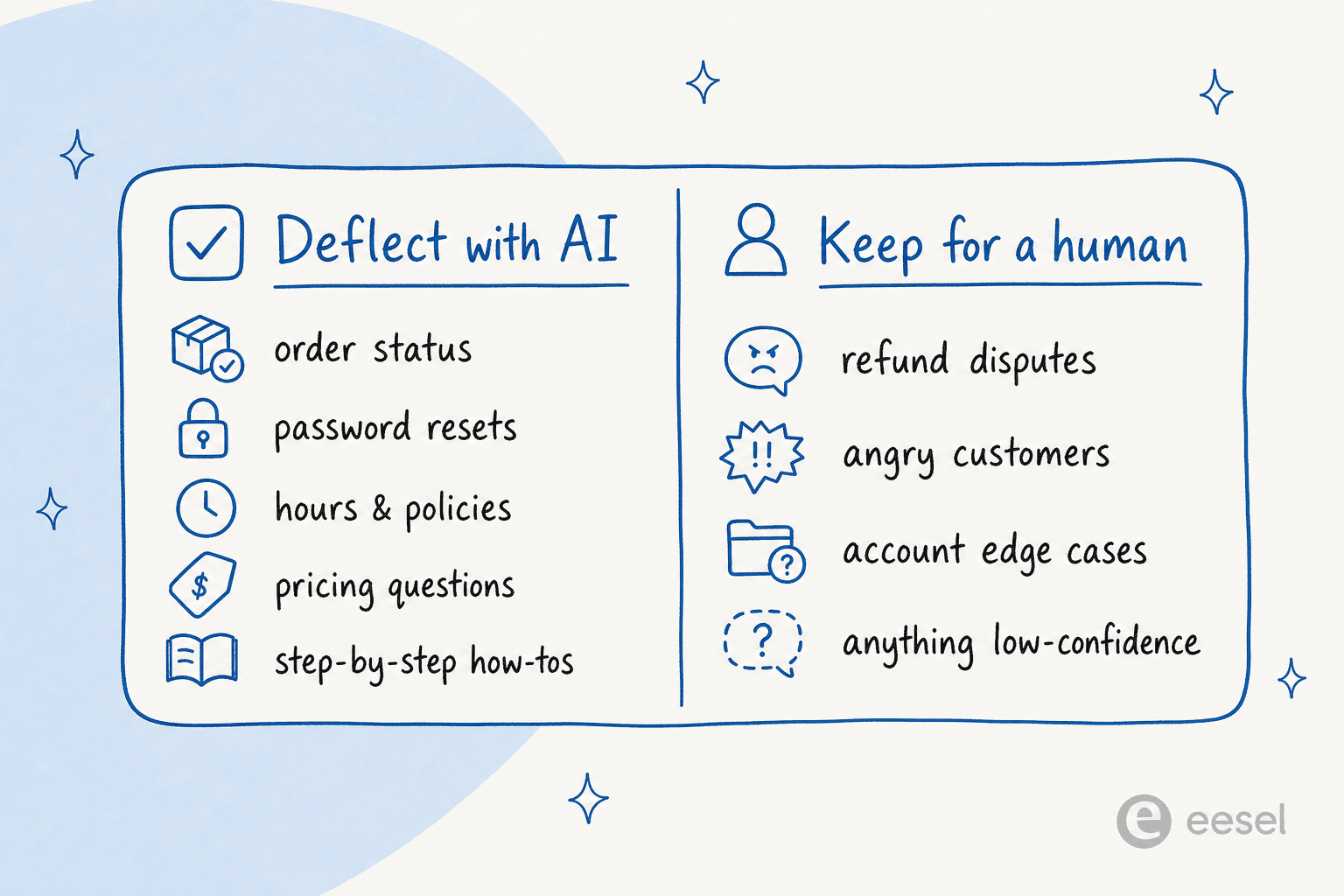
Good deflection candidates are high-volume, low-ambiguity, and have a knowable answer: order status, password and login resets, hours and policies, pricing questions, and step-by-step how-tos. These are the questions where a fast, correct, sourced answer at 2am beats a human reply eight hours later.
Keep these for a human: refund disputes, anything from an angry or at-risk customer, weird one-off account edge cases, and — the catch-all — anything the AI isn't confident about. You can usually exclude entire ticket types from automation so the AI never even attempts the categories you want a person on. That control is exactly what makes the difference between a tool you trust and one you turn off after a week.
A quick gut-check I use: if getting the answer slightly wrong would cost the customer money or trust, route it to a person. If the worst case is a slightly clumsy but correct answer, deflect it.
How to set up AI FAQ deflection without shipping wrong answers
This is the part most "AI deflection" guides hand-wave. Here's the actual sequence I'd run, and the order matters.
- Connect your knowledge, all of it. Help center, past tickets, internal docs, macros, even scattered Google Docs and Slack threads. Scattered knowledge is the number one reason deflection underperforms — the AI can only answer what it can see. The benefits of an AI-powered knowledge base compound here.
- Train on real tickets, not just the FAQ page. Your solved tickets contain the actual phrasing customers use and the answers that actually worked. A tool that only reads your polished help center will miss half of what people ask.
- Simulate before you go live. This is the step that kills the "will it answer wrong?" fear. Run the AI against your historical tickets and read what it would have said, by theme, before a single customer sees it. We built simulation into eesel for exactly this reason: we've watched confident-sounding bots give wrong answers, so now every rollout gets tested against real past tickets first.
- Set your confidence threshold and exclusions. Decide what "confident enough to send" means, and which ticket types the AI should never touch.
- Roll out partial, then widen. Start by deflecting one or two FAQ categories, or route only a slice of your volume. With usage-based tools you're only paying for what the AI handles, so a partial rollout costs partial money. Widen as the numbers earn your trust.
- Watch the metrics and feed corrections back. Every edit an agent makes should make the next answer better. Track first response time and resolution alongside deflection so you catch a containment-without-quality problem early.

The simulate-then-roll-out-partial loop is the whole safety story. You're never betting your CSAT on a guess; you're reading exactly what the AI would have done, fixing the gaps, and only then letting it touch live conversations.
Choosing an AI for FAQ deflection: what to actually compare
There are roughly three flavours of tool that claim to deflect FAQs, and they're not equivalent. Here's how I'd line them up.
| What to compare | Native helpdesk add-on | Generic FAQ chatbot | Dedicated AI agent |
|---|---|---|---|
| Trains on past tickets | Sometimes | Rarely (FAQ page only) | Yes |
| Confidence-based routing | Limited | Often none | Yes |
| Simulate on historical tickets before go-live | Rarely | No | Yes (eesel) |
| Works across email + chat + channels | Within that helpdesk | Chat widget only | Yes, 100+ integrations |
| Exclude ticket types / keep humans in loop | Varies | Limited | Yes |
| Pricing model | Bundled / per seat | Per resolution or seat | Usage-based, $0.40/ticket |
The two columns that separate a tool you keep from one you uninstall are confidence routing and simulation. A generic FAQ bot that only read your help page and answers everything at full confidence is the thing that gave AI support a bad name. A dedicated agent that trains on your tickets, tells you what it'll do before it does it, and knows when to back off is a different category of product. If you're weighing options broadly, our roundup of the best AI helpdesk software for 2026 and the best AI for support ticket triage both go wider.
On pricing specifically: watch the billable unit. Per-resolution pricing sounds fair until a vague "resolution" definition inflates your bill; usage-based per-ticket pricing is easier to predict because one ticket is one ticket no matter how many messages it takes. Teams switching off self-service portals that never deflected usually cite exactly this: they paid for seats or a flat platform fee and got a glorified search box.
The metrics that tell you it's working
Once you're live, deflection rate alone will lie to you. Track these together:
- Deflection rate — answered before an agent. Your headline.
- Resolution rate — fully closed by AI, no human. Catches the "deflected but didn't actually help" gap.
- Escalation quality — when the AI hands off, does it hand off cleanly and at the right moment? A high deflection rate with bad handovers is a worse experience than a lower one with clean ones.
- CSAT on AI-handled conversations — the truth serum. If customers are happy with the deflected answers, the deflection is real.
If you want the fuller picture, our guides to AI customer service metrics and automated ticket resolution lay out what to watch and how to read it. The short version: optimise for correctly answered without a human, and the rest follows.
Try eesel for FAQ deflection
If you want an AI agent built specifically for deflecting FAQs without the wrong-answer risk, that's what eesel AI does. It trains on your help docs and your past tickets, routes by confidence so it only answers what it's sure about, and — the part I'd push hardest — lets you simulate the whole thing against your historical tickets before a single customer sees it, so you know your deflection rate and answer quality up front instead of finding out live.
It plugs into Zendesk, Freshdesk, Gorgias, Help Scout, Front, and 100+ other tools in a few minutes, speaks 80+ languages out of the box, and is usage-based at $0.40 per ticket with no per-seat fee, so a partial rollout costs partial money. It's free to try with $50 of usage and no credit card.
If you'd rather see it move, here's eesel working inside Zendesk in real time:
Frequently asked questions
What is FAQ deflection?
How does AI deflect FAQ tickets?
What is a good FAQ deflection rate?
How much does AI FAQ deflection cost?
Will AI give customers wrong answers to FAQs?
What's the difference between FAQ deflection and ticket resolution?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.








