
まとめ
はい、AIでチケットのタグ付けを自動化できます。これはヘルプデスクでAIができる最も影響力の高いことの一つです。なぜなら、その後のすべてに影響するからです。ルーティング、レポート、SLA、そして最高のエージェントがどのチケットを見るかまで。仕組みはシンプルです。AIは受信チケットを読み取り、意図・言語・感情を検出し、タグリストと照合し、人間が開く前にタグを適用(またはチケットをルーティング)します。
問題はほぼAIではありません。タグリストです。モデルに複雑で重複した分類体系を与えると、新入社員と同じように一貫性のないタグ付けをします。本当の作業はタグを整理し、過去のチケットでAIを訓練し、自分の履歴に対してテストし、精度が維持されてから自動適用をオンにすることです。
ヘルプデスクにはおそらくネイティブオプション(Zendeskのインテリジェントトリアージ、Freshdeskの自動トリアージ、Gorgiasのルール)があり、それらは優れています。ただしほとんどはエージェントごとのアドオンと特定プランの背後に隠れています。過去の解決済みチケットでタグ付けを訓練してライブ前にシミュレーションしたい場合、それはまさにeeselのようなAIレイヤーが行うことです。すでに使っているヘルプデスクの上に乗せて動作します。
「AIでチケットにタグを付ける」とは実際にどういう意味か
私はeeselのサポートキューを管理しているので、価値がどこにあるかについて正直に話します。タグは退屈です。1日40回「請求」をドロップダウンから選ぶのが好きでカスタマーサポートに入った人はいません。しかしタグはまた組織化されたヘルプデスクの柱でもあります。どのチームにチケットが届くか、どのチケットルーティングルールが発動するか、週次レポートのトレンドが何を言うか、SLAの時計が正しい優先度で始まるかを決定します。
それを自動化するということは、読み取りとラベル付けのステップをAIに渡すことを意味します。内部的には、ほぼすべてのツールが同じ4つのことを行います。メッセージを読み取り、分類し(意図、言語、感情、ときには注文番号のような固有表現も)、その分類をリストのタグと照合し、適用します。優れたものは同じ処理でチケットフィールドを埋めてルーティングも行います。
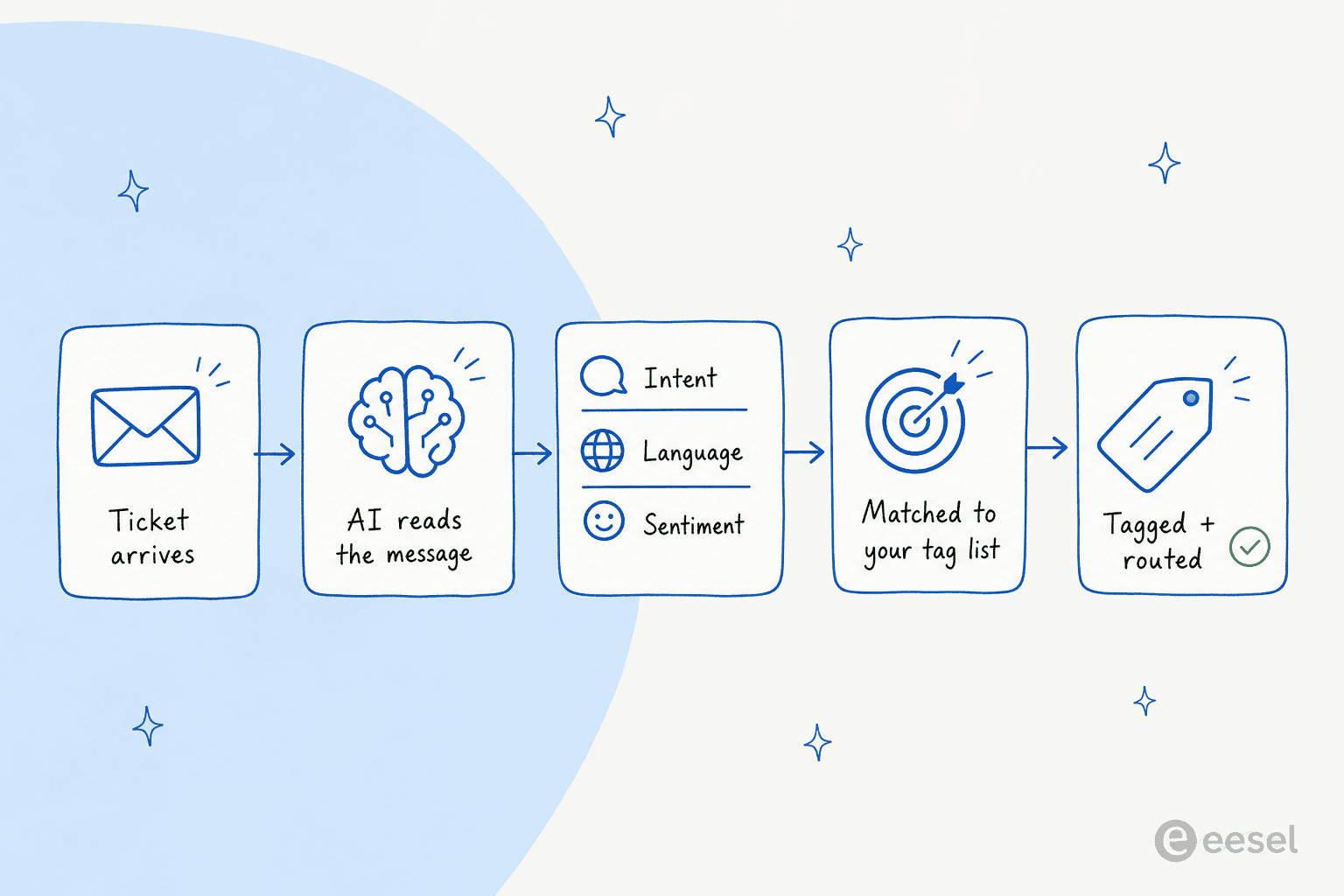
実際のチケットで動いているのを見て最も驚いたのは、どれだけ多くのコンテキストを把握するかです。チケットとして来た冷たいセールスのメッセージ(連絡先リストを売り込もうとしている人)があり、AIは過去のチケットと比較してスパムとして認識し、タグを付けて、内部メモとして丁寧な断りを残しました。それが、キーワードだけをパターンマッチングするAIチケット分類と、チケットの内容を実際に理解するものとの違いです。
手動タグ付けが静かに崩壊する理由
タグ付けがまだ手動であれば、実際に起きていることを正直に言います。おそらく3つすべてを感じたことがあるはずです。
エージェントはスキップします。キューが忙しいとき、タグ付けは最初に省略されます。そのため半分のチケットがタグなしか、汎用の「general」タグに放り込まれます。するとデータが最初からきれいでなかったため、レポートが嘘をつきます。
皆が異なるタグ付けをします。あるエージェントは「返金」を使い、別のエージェントは「払い戻し」を使い、3番目は「返金-払い戻し」を使います。今や1つのコンセプトに3つのタグがあり、実際に何件の返金チケットを受けたかを確実に数える方法がありません。これがサポートチケット分析プロジェクトが行き詰まる最大の理由です。
そしてスケールしません。週数百件のチケットを処理するチームは何とかなります。大量のチケットを処理するチームはできません。まさにそこで一貫したタグが最も重要であり、ルーティングとSLAが重労働を行う場所です。
悪いタグはタグがないよりも悪いです。なぜなら信号のように見えるからです。一貫性のないタグ付けで構築されたダッシュボードは確信を持った間違った数字を提供し、それに基づいて人員配置の決定を行います。
AIでチケットタグ付けを自動化する、ステップバイステップ
実際に実行するロールアウトを順番に示します。途中で意図的に慎重にしています。なぜならエラーのモードは「AIがタグ付けできない」ではなく、「誰かが確認する前にAIが10,000枚のチケットを誤ってタグ付けした」だからです。
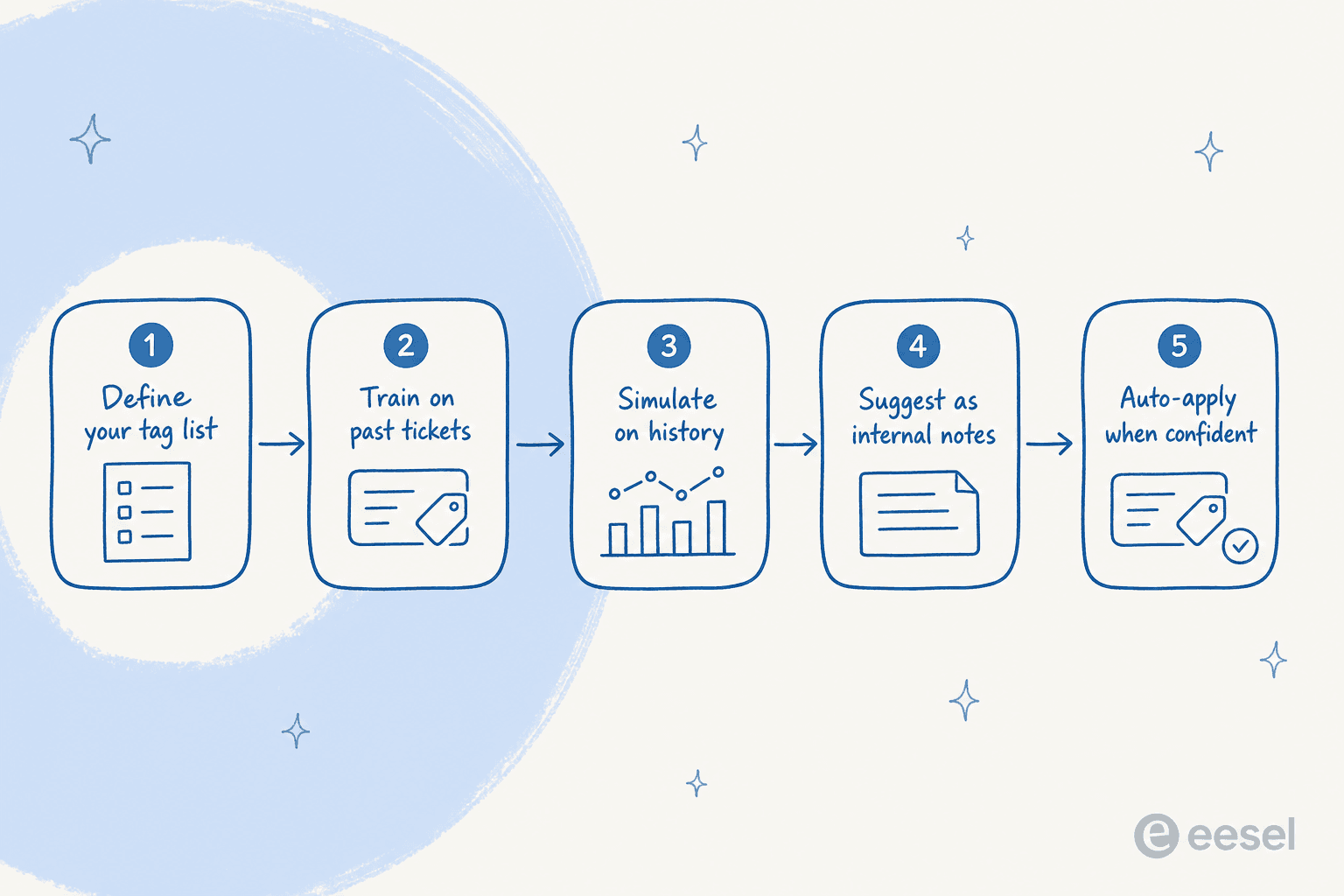
1. まずタグリストを監査して整理する
これは誰もがスキップしたいステップであり、すべてがうまくいくかどうかを決めるステップです。現在のタグリストを引き出して厳しく対処してください。重複を統合し(「返金」と「払い戻し」)、誰もルーティングやレポートで使っていないタグを削除し、明確で重複しない小さなカテゴリセットを目指します。AIはあなたが与えるリストと同じくらいしか一貫性を持てません。
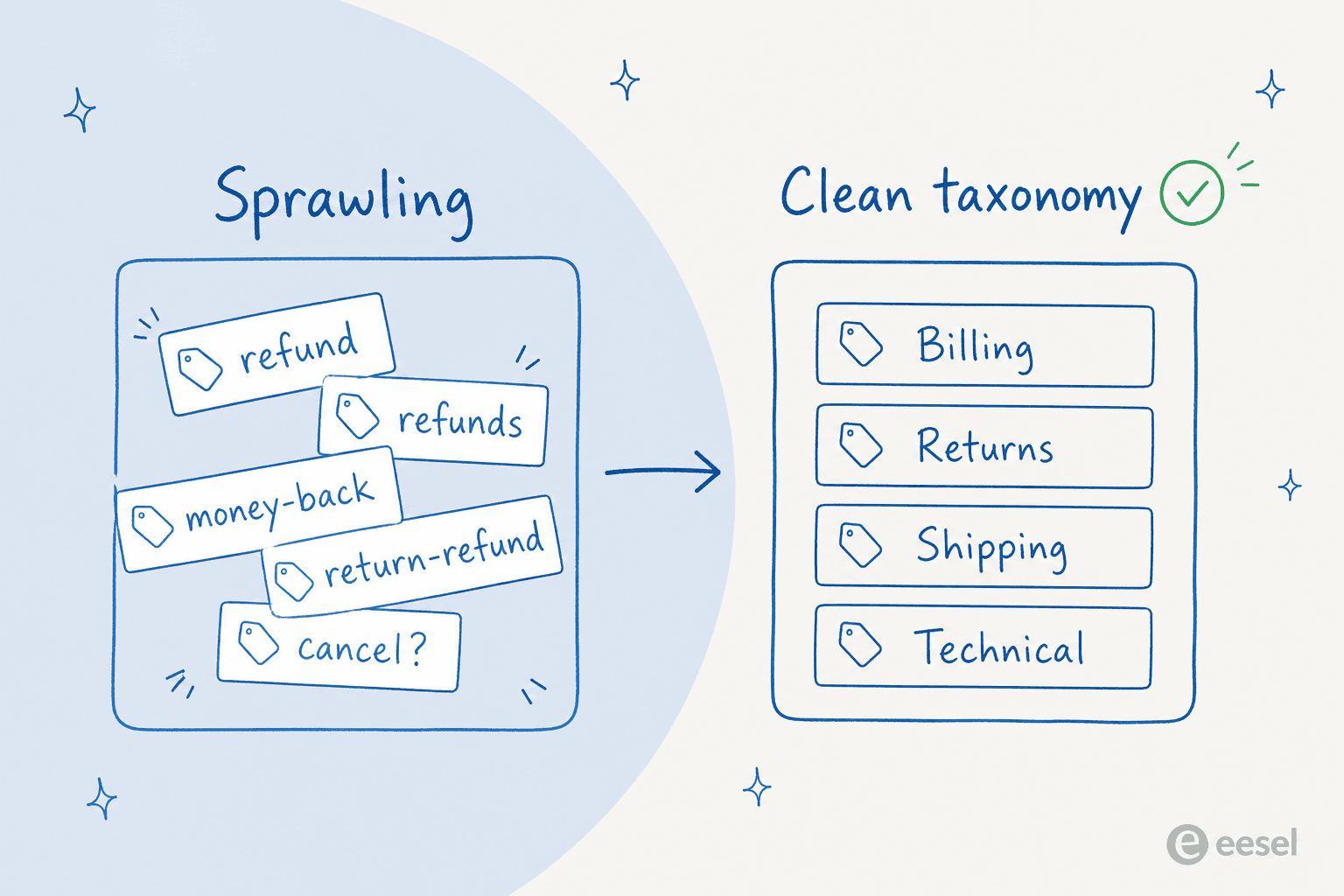
良いテスト:チームの2人がチケットのタグについて意見が分かれるなら、AIも意見が分かれます。分類体系のレベルで曖昧さを修正してください。より賢いプロンプトではなく。チケットタグの操作に関するガイドには必要に応じてより完全なチェックリストがあります。
2. 過去のチケットでAIを訓練する
汎用モデルは汎用的にタグ付けします。最高のエージェントのようにタグ付けするモデルと推測するモデルの違いは、実際の解決済みチケットから学んだかどうかです。過去のチケットがトレーニングデータです。正しいタグ、顧客が実際に使う言葉、エッジケースがすでに含まれています。
これはいくつかのネイティブツールが下限を設定する場所でもあります。例えばFreshdeskの自動トリアージはフィールドを確実に予測するのに約2,000枚の過去チケットが必要です。キューが少ない場合は、チケット量だけでなくヘルプドキュメントやマクロからも学習できるツールを選んでください。
3. ライブチケットに触れる前にシミュレーションする
これはスキップしないステップです。何かがライブになる前に、過去のチケットのバッチでモデルを実行し、そのタグをチームが適用したものと比較します。探しているのは2つの数字:チームとどれだけ一致するか、そして自信を持って意見が分かれるところ(それが分類体系の問題が現れているところ)。
過去チケットに対するシミュレーションは「精度が高いと思う」を「先四半期の請求チケットの91%でチームと一致した」に変換します。それがスイッチを入れる前にマネージャーに持っていく数字です。
4. 自動適用ではなく提案モードから始める
最初はコパイロットとしてAIを実行してください。タグを提案し、内部メモを残し、フィールドを事前入力し、人間が確認します。これにより信頼が構築され、まだ人間がループにいる間に奇妙なケースが捕捉されます。話したCXリーダーが言ったように、目標は確信を持って対処するものだけを処理して残りを放置するAIです。その直感は正しく、信頼度しきい値が存在する理由です。
5. 確信のあるケースの自動適用をオンにして、レポートを監視する
提案モードがチームと一貫して一致したら、信頼度しきい値を超えたタグをAIに自動適用させ、信頼度の低いものは提案として保持します。次に最初の数週間はレポートのタグ分布を監視します。タグが突然急増したなら、それは本物のトレンドかタグ付けのバグで、どちらの場合も知りたいはずです。きれいなタグがカスタマーサービス指標を再び信頼できるものにします。
ヘルプデスク別のオプション
ほとんどのヘルプデスクには何らかのネイティブAIタグ付けが搭載されています。各ツールの落とし穴を含む正直な現状と、ネイティブで十分か専用レイヤーを上に追加したいかを判断するための情報を以下に示します。
| ツール | タグ付け対象 | 必要なプラン | 開始価格 | 落とし穴 |
|---|---|---|---|---|
| Zendesk intelligent triage | トピック、感情(5段階)、言語(約150)、カスタムフィールドへのエンティティ | Suite/Support Professional + Copilotアドオン | $50/エージェント/月(年間) | トリガー、ビュー、レポートの構築時にトリアージ値は英語でのみ利用可能 |
| Freshdesk auto triage | 優先度、グループ、タイプ、カスタムフィールド、意図、感情(0-100) | Pro/Enterprise + Freddy AI Copilot | 合計約$84/エージェント/月 | 訓練に約2,000枚のチケットが必要;メールとポータルのみ;既存ルールがAIを上書き |
| Gorgias intents + rules | 意図分類体系、感情、その後ルールがタグを適用 | 全Helpdesプラン(粒度の高い意図はAI Agentが必要) | $10/月から | 70ルール上限;感情は手動編集不可 |
| eesel(レイヤー追加) | 意図、言語、感情、リストからのカスタムタグ、フィールド入力、ルーティング | 既存のヘルプデスクで動作 | $0.40/チケット、シート料金なし | ヘルプデスクのネイティブAIを置き換えるのではなく、補完する形で動作 |
Zendesk
Zendeskのインテリジェントトリアージは、トピック、5段階の感情スケール、約150の検出言語で受信チケットを自動分類し、さらに管理者定義のエンティティが抽出ルールを通じてカスタムフィールドを自動入力します。2026年半ばに「Intent」フィールドは「Topic」に名称変更されましたが、レガシーのインテントフィールドは引き続き関連タグを生成しています。
知っておくべき2つのこと:Copilotアドオン(旧「Advanced AI」)が必要で、SuiteまたはSupport Professional以上で年間請求$50/エージェント/月がかかります。そして約150の言語を分類しますが、トリガー、ビュー、またはレポートを構築するときにトリアージ値は英語でのみ表示されます。ZendeskでAIを使って返信を下書きする場合は、同じチケットに重ねる別の機能になります。
Freshdesk
Freshdeskの自動トリアージはFreddy AI Copilotの機能で、チケットの件名と説明に加えて意図と感情を読み取ることで優先度・グループ・タイプ・カスタムドロップダウン・ネストしたフィールドを予測します。手動モード(提案)または自動モード(作成時に適用)で実行でき、別の感情機能がチケットを0から100でスコアリングします。
落とし穴が重なります。ProまたはEnterpriseプランと有料のFreddy AI Copilotアドオンの背後にあり、現実的なFreddyの価格の最低価格を約$84/エージェント/月まで引き上げます。訓練に約2,000枚の過去チケットが必要で、メールとポータルチャンネルのみで動作し、フィールドごとに有効化するのに最大2日かかり、既存の自動化ルールは常にAIの提案を上書きします。これらはどれも決定的な障害ではありませんが、計画することが多いです。より広い設定を最適化している場合は、Freshdeskを自動化する方法に関するガイドが残りをカバーしています。
Gorgias
Gorgiasは2つの部分で行います。AIは各受信メッセージを固定の意図分類体系と感情(ポジティブ、ネガティブ、ニュートラル、そして新しい「プロモーター」)に対して分類し、次に決定論的なWHEN/IF/THENルールがそれらのメッセージの意図と感情を読み取って実際のタグを適用します。基本的な意図と感情の検出とルールビルダーは、「意図と感情を識別する」テンプレートが含まれており、すべてのHelpdesプランで$10/月から利用できます。
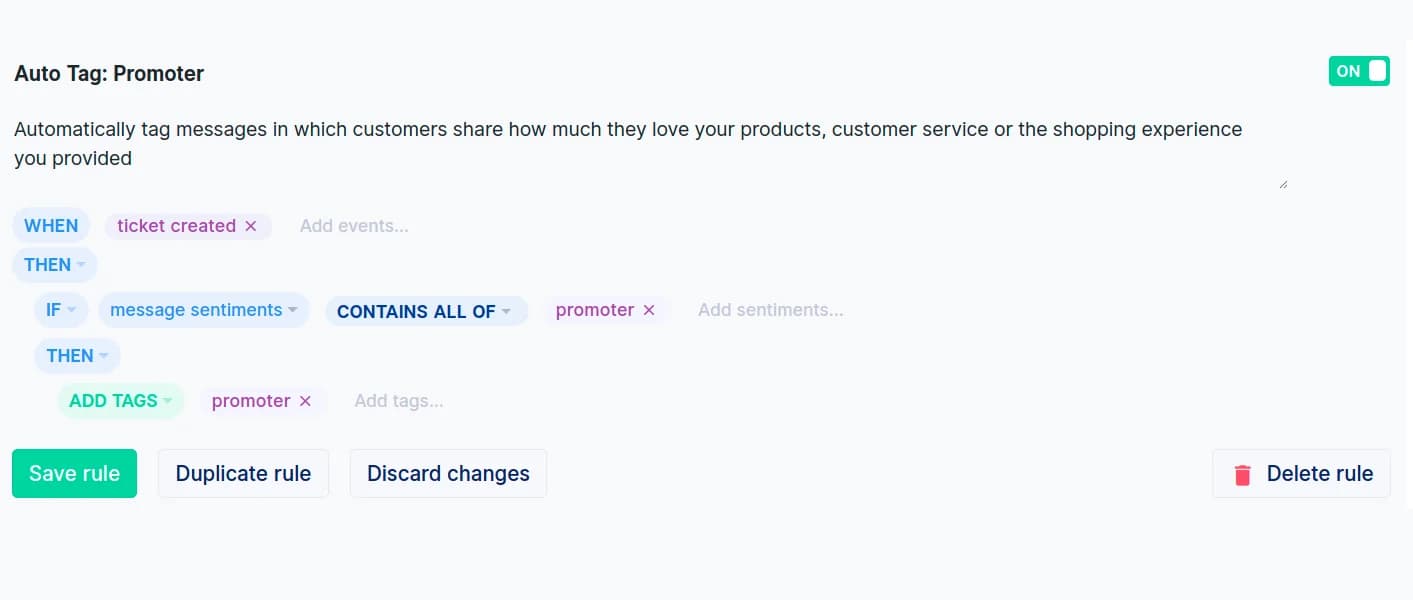
より豊富で粒度の高い意図分類体系と意図分析ページは、別のAI Agentサブスクリプションが必要です。制限に注意してください。70ルール上限、固定されたトリガー優先度の実行順序があり、感情は手動で編集できないため、AIがチケットを「ニュートラル」と判定した場合は手動で上書きできません。それらのタグに対して行動したい場合、Gorgiasの自動応答ルールは同じビルダーを使用します。
専用AIレイヤーのメリット
ではネイティブでは不十分なのはいつでしょうか?私の経験では3つのことに絞られます。ネイティブAIが薄いヘルプデスクを使っている、アドオンのエージェントごとの料金を払いたくない、または複数のツールにまたがって同じ方法でタグ付けしたい場合です。それが専用レイヤーが埋めるギャップであり、トレードオフを明確にする価値があります。
レイヤーの最も強い論拠は、解決済みチケットで訓練し、ライブ前にシミュレーションできることです。私が一緒に仕事をしたデンマークのB2B車両テレマティクスチームは、ドイツ、スペイン、イタリア市場に拡大していたのですが、まさにこれを求めていました。自社定義のタグリストからの自動タグ付け、自動フィールド入力、エスカレーションワークフロー、エージェント向けにチケットを英語に翻訳して顧客の言語で返信を送り返す、すべてZendeskの上で実現。ネイティブトリアージは最初の部分を処理します。残りはレイヤーの出番です。
正直な反論:レイヤーはスタックの一つのツールであり、ヘルプデスクのネイティブタグ付けがすでにニーズをカバーしていて、どうせそれを払っているなら、別のシステムを追加するのはやり過ぎです。上の表を使ってください。トピックと感情タグだけが必要で、すでに正しいZendeskプランにいるなら、ネイティブでおそらく十分です。
避けるべきよくある間違い
チームが陥るいくつかの落とし穴を、引き起こす痛みの大まかな順序で紹介します。
- 乱雑な分類体系を自動化する。 上述しましたが繰り返す価値があります。自動化の前にタグリストを整理してください。後ではなく。自動化は始まった一貫性(または混乱)を増幅します。
- すぐに自動適用に移行する。 提案モードをスキップすると、タグ付けの問題の最初のサインは3週間後の間違ったダッシュボードです。自動適用を勝ち取ってください。
- 信頼度しきい値なし。 曖昧なものも含めてすべてのチケットにタグを付けるよう強制されたAIは推測します。本当に不明確なチケットを人間のために残すようにすれば、誤検知を大幅に削減できます。
- 設定して忘れる。 製品、プロモーション、顧客の言葉は変化します。毎月タグ分布を再確認し、モデルが学習し続けるように訂正をフィードバックします。編集から学習するツールは改善し、学習しないものは改善しません。
これらをうまく行うと、タグ付けはチームが嫌う雑務でなくなり、チケットトリアージとチケット自動化を実際に機能させる静かなレイヤーになります。
チケットタグ付けにeeselを試してみる
解決済みチケットで訓練し、ライブチケットに触れる前にテストできるAIタグ付けが必要な場合、それがまさにeeselが構築された目的です。すでに使っているヘルプデスク(Zendesk、Freshdesk、Gorgias、100以上の統合)に接続し、初日から過去のチケットとヘルプドキュメントから学習し、そこからタグ付け・フィールド入力・ルーティングを行いながら、自動適用と提案の完全なコントロールを維持できます。
差別化要因はシミュレーションモードです。過去のチケットで実行して、何かがライブになる前にどのようにタグ付けされていたかを正確に確認できるので、精度について推測する必要はありません。価格はチケットごとであり、エージェントごとではありません。シートごとのアドオンと比較すると重要な違いになる傾向があります。

内部のJira Service ManagementヘルプデスクでAIをファーストレスポンダーとして使っているチームが魅力をわかりやすく表現しました。
「Jiraのヘルプデスクチケットのファーストレスポンダーとして使っています。本質的にエージェントと同じように動作します。」
Jason Loyola, Head of IT, InDebted (ケーススタディ)
Zendesk(または使っているヘルプデスク)に接続して数分でシミュレーションを実行できます。クレジットカード不要で無料でお試しいただけます。
よくある質問
AIはZendeskで自動的にチケットにタグを付けられますか?
はい。ZendeskのインテリジェントトリアージはCopilotアドオンでトピック・感情・言語によるタグ付けを行い、さらに過去のチケットで学習する専用ツールを上から追加することもできます。ZendeskのAI機能に関するメモと、Zendeskチケットの自動化についての解説もご覧ください。
AIはチケットを誤ってタグ付けしますか?
特に初期段階やタグリストが重複している場合は、ときどき誤る可能性があります。解決策はタクソノミーを整理し、まず過去のチケットに対してモデルを実行し、信頼度の低いチケットを提案モードに保つことです。誤検知の削減に関するガイドでより詳しく解説しています。
AIタグ付けを始めるには何千枚もの過去チケットが必要ですか?
一部のネイティブツールは必要です。Freshdeskの自動トリアージはフィールドを確実に予測するのに約2,000件の過去チケットが必要です。解決済みチケットとヘルプドキュメントから学習できるツールはより早く始めることができ、キューが少ない場合に重要です。AIチケット分類ガイドでアプローチを比較してください。

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.








