
Ich wurde lieber nichts als etwas Falsches sagen
Ich arbeite im Support-Team von eesel und lese daher beruflich KI-Antworten - unsere und die, die Kunden uns von Tools weiterleiten, denen sie entfliehen. Das Muster, das mich wach halt, ist nicht der Agent, der stolpert und eine Klarungsfrage stellt. Es ist der Agent, der eine saubere, zuversichtliche, vollig falsche Antwort erfindet und sie abschickt, bevor jemand nachgesehen hat.
Ein Beispiel ist mir besonders im Gedachtnis geblieben. Ein B2B-Fahrzeugtelematik-Team in Danemark, das Zendesk betreibt und von einigen hundert Tickets pro Monat auf einige Tausend skaliert, teilte uns mit, dass ihr Bot Kunden standig sagte: "Ja, wir unterstutzen Ihr Automodell" - fur Marken, die uberhaupt nicht in ihrer Datenbank standen. Warum? Ihre Wissensdatenbank enthielt eine freundliche Zeile, die besagte, sie "unterstutzen alle Modelle." Die KI glaubte es. Sie log nicht, sie wiederholte ein Dokument, das fur das Marketing geschrieben wurde, nicht fur einen autonomen Agenten, der echte Fragen beantwortet. Ihre eigene Zusammenfassung der fruhen Tage: "Versuch und Irrtum."
Das ist das Ding mit Halluzinationen im Support: Sie sind selten das Modell, das ausreisst. Es ist das Modell, das eine Lucke in Ihrem Setup getreu wiedergibt. Wir setzen seit Jahren KI-Agenten auf Live-Support-Warteschlangen ein, uber Tausende echter Tickets, und fast jede falsche Antwort, die ich zuruckverfolgt habe, hat eine langweilige, behebbare Grundursache. Also fangen wir da an.
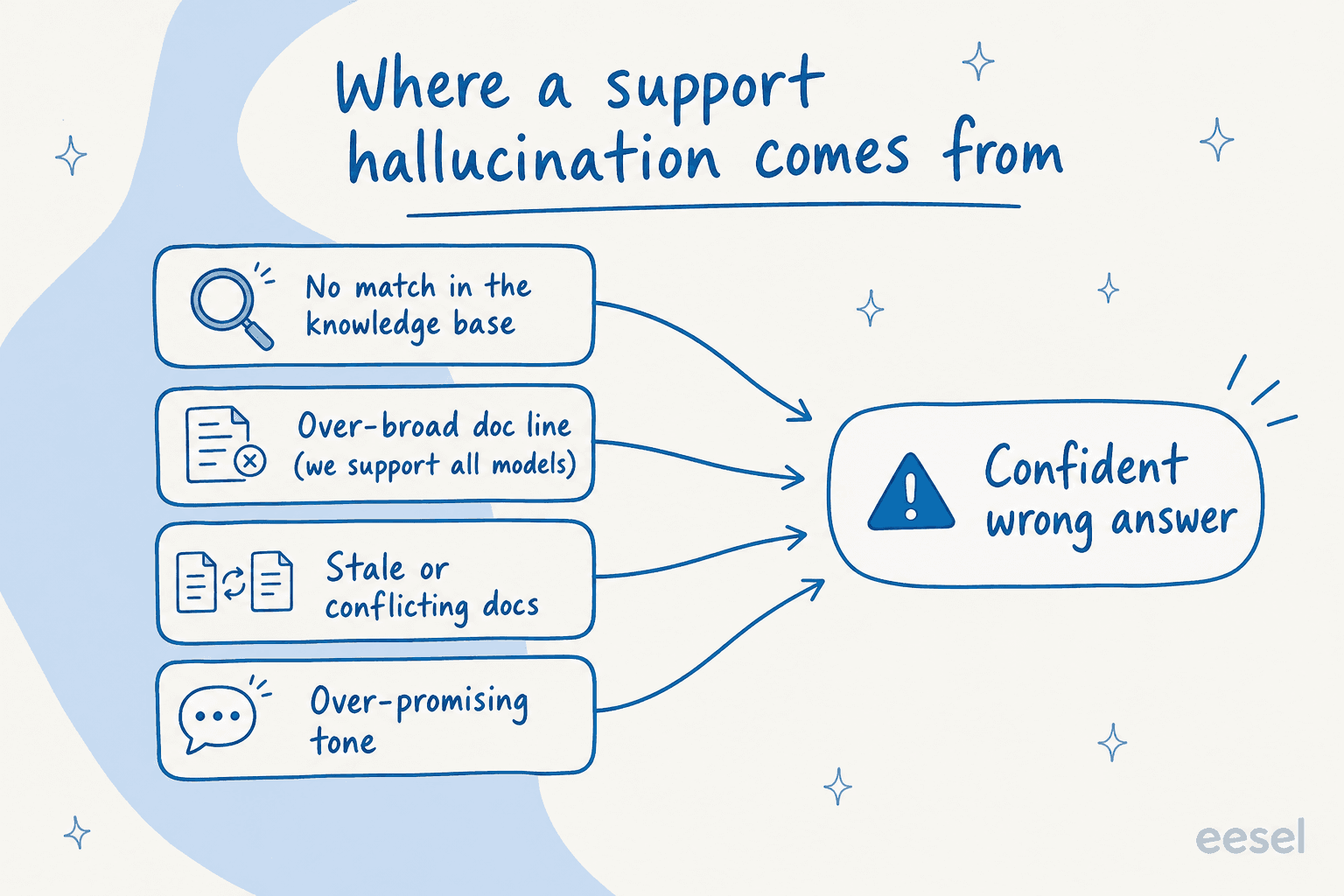
Warum eine Support-Halluzination mehr kostet als eine Chatbot-Halluzination
Wenn ein allgemeiner Chatbot etwas erfindet, zucken Sie mit den Schultern und formulieren den Prompt neu. Wenn ein Support-Agent es tut, handelt der Kunde danach. Er wartet auf ein Lieferdatum, das Sie nicht versprochen haben. Er befolgt Einrichtungsschritte fur eine Funktion, die Sie nicht haben. Bei regulierten Tatigkeiten werden die Einsatze schnell grosser - ein Mitgrunder eines Legal-Tech-Unternehmens erklarte uns, er konne es sich nicht leisten, irgendetwas falsch zu machen, weil es einen schmalen Grat zwischen hilfsbereit sein und unbemerkt in die Erteilung von Rechtsberatung abgleiten gibt.
Dieselbe Angst ist in offentlichen Bewertungen zu sehen. Ein Salesforce Business Analyst, der einen KI-Support-Agenten auf G2 bewertet, brachte die Datenqualitatsversion davon direkt auf den Punkt:
"Wenn Ihre Content Version-Dateien (Knowledge Articles) seit 2021 nicht aktualisiert wurden, gibt der KI-Agent Kunden zuversichtlich veraltete Informationen."
Muhammad O., Salesforce Business Analyst, Bewertung von Agentforce Service auf G2
Und die nicht verankerte Version, von einem anderen Rezensenten derselben Tool-Familie:
"Ausserdem sind die Halluzinationen wirklich schlimm, da wir nicht trainieren und es auf einem allgemeinen Modell lauft, gibt es manchmal einfach Informationen, die nicht zu uns gehoren."
Arjun G., Associate Salesforce Consultant, Bewertung von Salesforce Agentforce auf G2
Beide Bewertungen landen von entgegengesetzten Seiten am selben Punkt: Ein Agent ist nur so wahrhaftig wie das, was er lesen darf, und ob er gezwungen ist, es zu lesen. Das ist das ganze Spiel. Hier erklare ich, wie ich es absichern wurde.
Die funf Tore, die eine Support-KI am Halluzinieren hindern
Betrachten Sie es weniger als eine Einstellung und mehr als eine Reihe von Toren, durch die eine Frage gehen muss, bevor sie jemals einen Kunden erreicht. Jedes Tor fangt eine andere Fehlerart ab, und die Antworten, die alle funf uberstehen, sind die, die Sie wirklich vertrauensvoll selbstandig senden konnen.
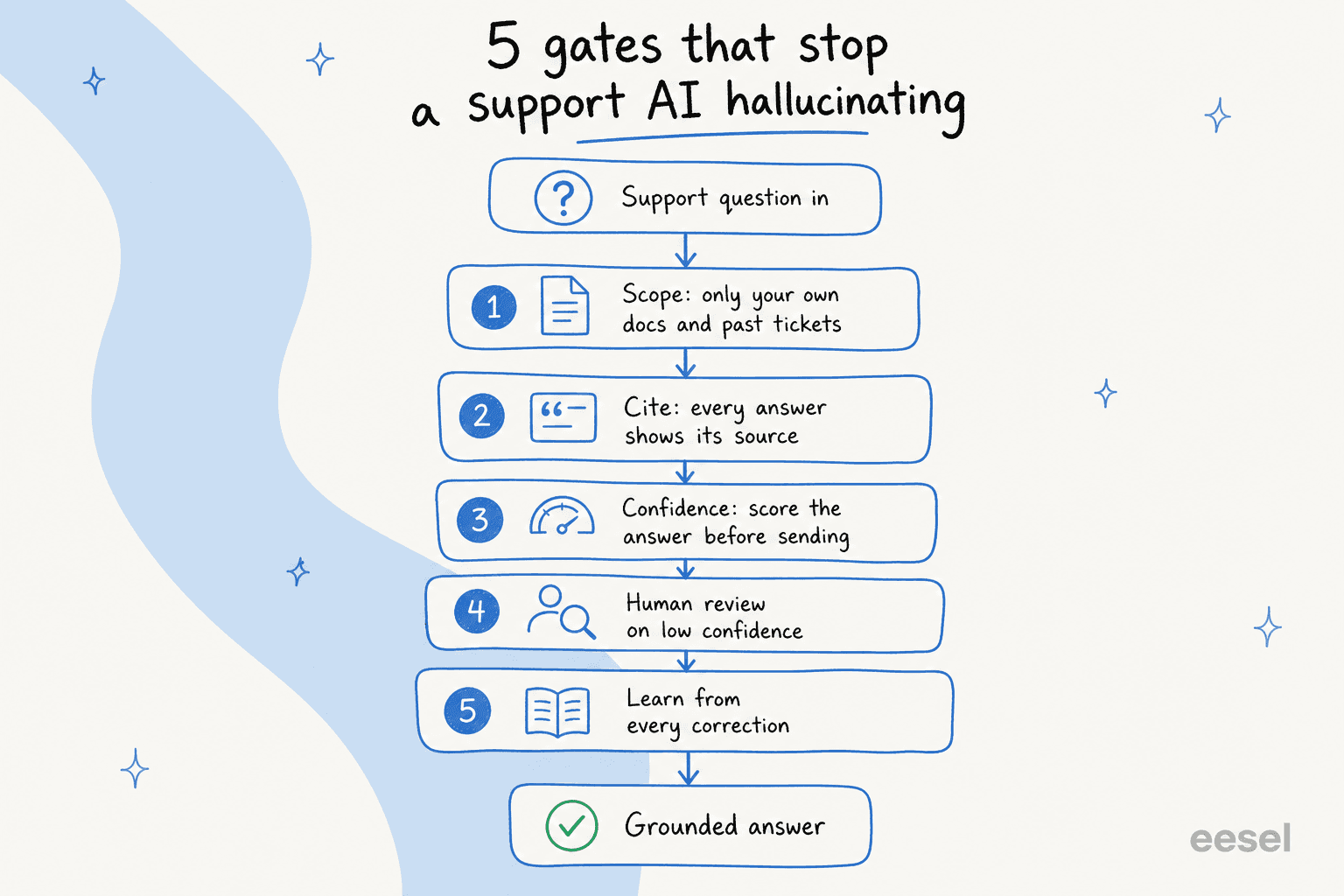
Tor 1: das Wissen eingrenzen, dann nochmals eingrenzen
Der erste und grosste Hebel ist, was der Agent lesen darf. Eine Support-KI sollte aus Ihrer eigenen Grundwahrheit antworten - Ihrem Help Center, Ihren vergangenen gelosten Tickets, Ihrer internen Wissensdatenbank, und sonst nichts. In dem Moment, in dem sie auf "allgemeines Wissen" zuruckfallen darf, um eine Lucke zu fullen, haben Sie ihr die Erlaubnis gegeben zu raten.
Hier zahlt sich auch die langweilige Dokumentenhygiene aus. Diese "wir unterstutzen alle Modelle"-Zeile ist eine Halluzination, die darauf wartet, zu passieren - nicht weil die KI dumm ist, sondern weil es eine zuversichtliche, unkualifizierte Aussage ist, die in einer Quelle sitzt, die der Agent als Wahrheit behandelt. Wenn Sie eine KI auf Ihrer Wissensdatenbank trainieren, zeigen Sie ihr nicht nur Dokumente, Sie prufen, ob diese Dokumente sicher sind, sie einem Fremden wortwortlich zu wiederholen.
eesel lernt von Beginn an von Ihren vergangenen Tickets, Help-Dokumenten und Team-Workflows, sodass jahrelange geloste Gesprache zu Wissen werden, auf das sich der Agent stutzen kann, anstatt zu erfinden. Es verbindet sich direkt mit Ihren bestehenden Wissensquellen und Helpdesks, sodass der Agent dieselben Artikel liest, denen Ihr Team bereits vertraut.

Wenn ein Thema wirklich nicht abgedeckt ist, ist das richtige Verhalten, dies zu sagen oder weiterzuleiten - nicht zu improvisieren. Ein guter Agent sollte auch die Lucken markieren, auf die er immer wieder stosst, damit Sie den fehlenden Artikel schreiben konnen, anstatt sie mit einem Raten zu ubertunchen. Das ist die halbe Halfte des Wertes eines KI-Wissensdatenbank-Chatbots: Er sagt Ihnen, was Ihre Dokumente noch nicht abdecken.
Tor 2: bei jeder Antwort eine Quellenangabe erzwingen
Quellenangaben sind eine Halluzinations-Stolperfalle. Wenn der Agent auf das spezifische Dokument zeigen muss, aus dem seine Antwort stammt, passieren zwei gute Dinge: Ein menschlicher Prufar kann es mit einem Klick verifizieren, und der Agent kann uberhaupt nicht antworten, wenn keine Quelle zum Zitieren vorhanden ist. Keine Quelle, keine zuversichtliche Antwort.
Der Legal-Tech-Mitgrunder, den ich zuvor erwahnte, wurde genau deshalb zuversichtlich, weil er genaue Leitplanken fur die Quellenangabe setzen konnte und der Agent immer transparente Quellenangaben zeigte. Das ist fur ihn kein nettes Zusatzfeature, sondern das, was ihm erlaubte, die KI uberhaupt einzuschalten. Unter der Haube ist das der Zweck eines Retrieval-Augmented-Setups: Die Antwort wird aus abgerufenen Passagen zusammengestellt, und die Passagen reisen mit ihr.
Ein schneller Schnellcheck fur jedes Tool, das Sie evaluieren: Bitten Sie darum, eine Antwort mit ihren angehangten Quellen zu sehen. Wenn der Anbieter Ihnen nicht zeigen kann, woher eine bestimmte Antwort stammt, kann es Ihr Team nicht - und Ihr Kunde auch nicht.
Tor 3: nach Konfidenz weiterleiten (das ist das Wichtigste)
Wenn Sie nur eines aus diesem Beitrag tun, tun Sie das. Ein Konfidenz-Schwellenwert lasst den Agenten die Fragen beantworten, bei denen er sich sicher ist, und alles andere in Ruhe lassen. Hohe Konfidenz, er antwortet und sendet. Mittel, er erstellt einen Entwurf fur einen Menschen zur Genehmigung. Niedrig, er berurhrt das Ticket nicht und leitet es an eine Person weiter.
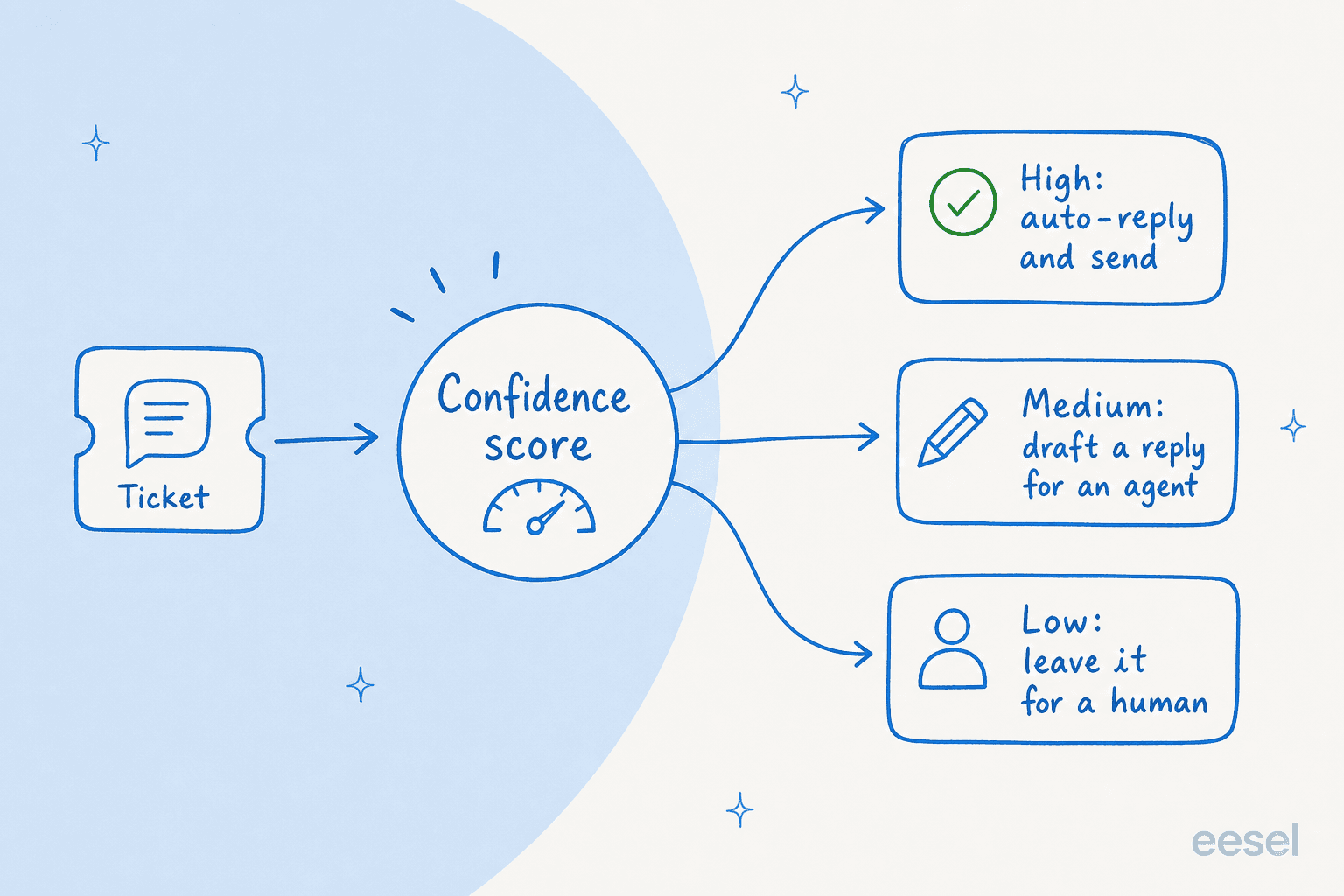
Dies kam im denkwurdigsten Verkaufsgesprach auf, das ich zuruckgelesen habe. Ein CX-Lead einer DTC-Nahrungserganzungsmittelmarke auf Gorgias und Shopify, die rund 7.000 Tickets pro Monat abwickelt, teilte uns mit, dass der Deal genau davon abhing. Seine Worte, ungefahr: Die KI wird nie 100 % der Fragen beantworten, aber wenn sie es versucht und einfach "Tut mir leid, ich weiss es nicht" antwortet, kann er nicht alle 7.000 Tickets uberprufen, um zu sehen, ob die Antwort gut war - also ist der Sinn verloren. Er brauchte eine KI, die nur die Tickets bearbeitet, bei denen sie zuversichtlich ist, und den Rest in Ruhe lasst. Das ist die gesamte These der Halluzinationspravention in einem frustrierten Satz.
Konfidenz-Routing macht auch den Unterschied zwischen einem KI-Agenten und einem regelbasierten Chatbot: Der Agent weiss, wenn er etwas nicht weiss. eesel liefert das sofort einsatzbereit, und Sie starten vollstandig uberwacht, um dann Autonomie fur die einfachen Ticket-Typen zu gewaehren, wahrend Sie Vertrauen aufbauen - Ticket-Kategorie fur Ticket-Kategorie. Die meisten Helpdesks bieten eine Version davon an; wenn Sie Zendesk verwenden, lohnt es sich, den Intent-Konfidenz-Schwellenwert und die Fallback-Nachricht zu verstehen, auf die der Agent zuruckfalt.
Tor 4: einen Menschen fur die schwierigen Tickets bereithalten, mit einer sauberen Ubergabe
Konfidenz-Routing hilft nur, wenn die darauf folgende Ubergabe sauber ist. Wenn der Agent zuruckzieht, sollte das Ticket mit vollem Kontext bei einem Menschen landen - dem Gesprach, dem Kunden, womit der Agent unsicher war - kein kalter Neustart, der den Kunden zwingt, sich zu wiederholen.
Hier geben Sie Ihrem Team auch explizite Kontrolle daruber, was die KI beruht. Viele Teams mochten bestimmte Ticket-Typen vollstandig von der Automatisierung fernhalten: Rechnungsstreitigkeiten, Kundigungen, alles Rechtliche. Das ist ein Feature, keine Einschrankung. Ein gutes Setup ermoglicht es Ihnen, Ticket-Typen auszuschliessen, den Agenten so einzustellen, dass er nur auf explizite Aufforderung handelt, und zu definieren, wann er eskalieren soll. Wenn Sie das kartieren, deckt unser Leitfaden zu KI-Agent-Eskalationen die funktionierenden Muster ab. Die Mechanik einer sauberen Ubergabe an einen Menschen ist genauso wichtig wie der Ausloser, der sie auslosst.
Es gibt eine verwandte Falle, die es wert ist zu benennen: Ubertreiben von Versprechen. Ein eCommerce-Support-Manager, mit dem wir gearbeitet haben, musste seinem eCommerce-KI-Chatbot standig sagen, aufzuhoren, Kunden zu versichern, er werde sie "in Ordnung bringen", und aufzuhoren, eine Lieferung bis Freitag zu versprechen, weil niemand das garantieren konnte. Halluzination ist nicht nur das Erfinden von Fakten, es ist auch das Erfinden von Verpflichtungen. Leitplanken fur Ton und Versprechen gehoren in denselben Bereich wie Leitplanken fur Fakten.
Tor 5: aus jeder Korrektur lernen
Das letzte Tor ist dasjenige, das sich summiert. Jedes Mal, wenn ein Mensch einen Entwurf bearbeitet oder ablehnt, sollte dieses Signal die nachste Antwort verbessern - nicht im Nichts verschwinden. Ein Agent, der aus Korrekturen lernt, wird mit der Zeit genauer und zuversichtlicher, was bedeutet, dass mehr Tickets Tor 3 ehrlich passieren, anstatt die Messlatte zu senken.

Mit eesel stimmen Sie das in einfacher Sprache ab: Sie sagen dem Agenten, wann er einspringen soll, welchen Ton er verwenden soll und was er niemals versprechen soll, und Korrekturen fliessen in sein Verhalten zuruck. Kein Umschulungsprojekt, kein Data-Science-Team. Sie konnen in den Gespracheprotokollen uberprufen, was er tut, und von dort aus anpassen - dieselbe Schleife, auf der ein Zendesk Schulungszentrum aufgebaut ist.
Vertrauen Sie den Toren nicht blind: erst simulieren
Hier ist der Schritt, den die meisten Teams uberspringen - und den ich nie ohne starten wurde. Bevor eine einzige Live-Antwort herausgeht, fuhren Sie den Agenten gegen Ihre echten historischen Tickets und sehen Sie, wie er sie beantwortet hatte.
Die Simulation verwandelt "Ich denke, das ist sicher" in eine Zahl. Sie zeigen dem Agenten Tausende vergangener Gesprache, und er zeigt Ihnen, wie er geantwortet hatte, wo er zuversichtlich ist, wo er geraten hatte, und welchen Anteil des Volumens er selbstandig hatte bearbeiten konnen. Sie finden die Lucken, fullen sie und fuhren die Simulation erneut durch - alles, bevor ein Kunde involviert ist. Das ist der Unterschied zwischen der Hoffnung, dass Ihre Leitplanken halten, und dem Zusehen, wie sie gegen Ihre tatsachliche Ticket-Geschichte halten.

Das ist auch der ehrliche Weg, Ihre Losungsrate zu prognostizieren, anstatt der Headline-Zahl eines Anbieters zu vertrauen. Ein CX-Lead, den ich zuvor zitiert habe, brachte denselben Punkt auf andere Weise: Er wollte nicht auf einen Monatsbericht warten, um herauszufinden, dass die KI falsch lag - er wollte es im Voraus wissen. Simulation ist, wie Sie es im Voraus wissen. Der Simulationsmodus von eesel lauft gegen Ihre vergangenen Tickets und meldet die Abdeckung nach Thema, sodass Sie bei den Ticket-Typen live gehen, die es bewiesen hat bearbeiten zu konnen - und nur bei diesen.
Ich mochte ehrlich uber den Kompromiss sein, da gleichformiger Optimismus seine eigene Art von Hinweis ist. Das richtig zu machen bedeutet, dass Sie nicht an Tag eins einen Schalter umlegen und alles automatisieren. Sie starten eng, bei den Ticket-Typen, fur die die Simulation eingestanden hat, und erweitern, wahrend der Agent es verdient. Wenn Sie einen Agenten wollen, der von Stunde eins an 100 % der Tickets mit null Aufsicht lost, kann kein ehrliches Tool das liefern - und die, die es behaupten, sind die, die halluzinieren. Der Vorteil ist, dass der langsamere, verankerte Weg auch derjenige ist, dem Kunden tatsachlich vertrauen.
Wo das Modell selbst hilft
Ich habe stark auf "Es liegt an Ihrem Setup, nicht am Modell" gesetzt, weil dort die Losungen sind. Aber das zugrunde liegende Modell ist nicht irrelevant. Neuere Modelle sind besser darin, "Ich bin nicht sicher" zu sagen, anstatt zu bluffen, besser darin, sich an abgerufene Quellen zu halten, und besser darin, Anweisungen wie "versprich nie ein Lieferdatum" zu befolgen. Ein starkes Verankerungs-Setup auf einem starken Modell schlagt ein starkes Setup auf einem schwachen. Es ist auch das, was ein echtes KI-Agent-Assist-Tool von einem glorifizierten Makro-Auswahler trennt.
Die praktische Konsequenz: Sie mussen das Modell nicht selbst auswahlen oder Upgrades babysitzen. Die Aufgabe einer guten Support-Plattform ist es, ein fahiges Modell zu betreiben und es in die funf oben genannten Tore einzuwickeln, damit Sie die Verbesserungen des Modells erhalten, ohne etwas neu architektieren zu mussen. Das ist die Schicht, auf der eesel sitzt, und das ist, warum sich derselbe Agent konsistent uber 100+ Integrationen verhalt. Unabhangig davon, ob Ihr Stack auf einem Gorgias-KI-Agenten oder einem HubSpot-Agenten aufgebaut ist, reisen die Verankerungs- und Konfidenzschichten mit.
eesel ausprobieren
Ich bin voreingenommen - ich arbeite hier, und wir integrieren uns mit den Helpdesks, die ich erwahnt habe, also bewerten Sie meine Meinung entsprechend. Aber Halluzinationspravention ist genau das Problem, um das der KI-Helpdesk-Agent von eesel gebaut wurde. Er lernt von Beginn an von Ihren vergangenen Tickets und Dokumenten, zitiert seine Quellen, leitet nach Konfidenz weiter, sodass unsichere Antworten an einen Menschen statt an Ihren Kunden gehen, und lasst Sie gegen Ihre echte Ticket-Geschichte simulieren, bevor Sie live gehen - die funf Tore, eingebaut statt nachtraglich hinzugefugt. Teams fuhren es in echtem Massstab dazu: Ein Kunde lost 73 % der Tier-1-Anfragen im ersten Monat, und ein anderer betreibt einen vollautomatischen Agenten uber mehr als 100.000 deutschsprachige Tickets pro Monat.
Die Preisgestaltung ist nutzungsbasiert ohne Gebuhren pro Platz, sodass Sie nicht dafur bezahlen, dass ein Agent dort sitzt und rat. Sie konnen die Plane sehen oder eine kostenlose Testversion starten und zuerst eine Simulation mit Ihren eigenen Tickets durchfuhren. Diese Simulation ist der schnellste Weg, in Ihren eigenen Daten genau zu sehen, wo ein KI-Agent helfen wurde und wo er halluziniert hatte - bevor er jemals mit einem Kunden spricht.
Haufig gestellte Fragen
Was verursacht KI-Halluzinationen im Kundensupport?
Wie verhindere ich, dass mein KI-Support-Agent Antworten erfindet?
Reicht konfidenzbasiertes Routing aus, um Halluzinationen zu verhindern?
Wie teste ich einen KI-Support-Agenten, bevor er live geht?
Wird ein KI-Support-Agent, der Halluzinationen vermeidet, trotzdem genug Tickets losen?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.







