Wie man einen KI-Support-Agenten trainiert (damit er Kundenvertrauen verdient)
Alicia Kirana Utomo
Katelin Teen
Zuletzt bearbeitet June 20, 2026

Kurzfassung
Das Training eines KI-Support-Agenten ist kein Codierungsprojekt und auch kein einmaliger „FAQ hochladen"-Schritt. Die Arbeit besteht aus vier Dingen: echtes Wissen einspeisen, gegen vergangene Tickets simulieren, falsch beantwortete Antworten coachen und per Konfidenz absichern, damit er nur antwortet, wenn er sicher ist.
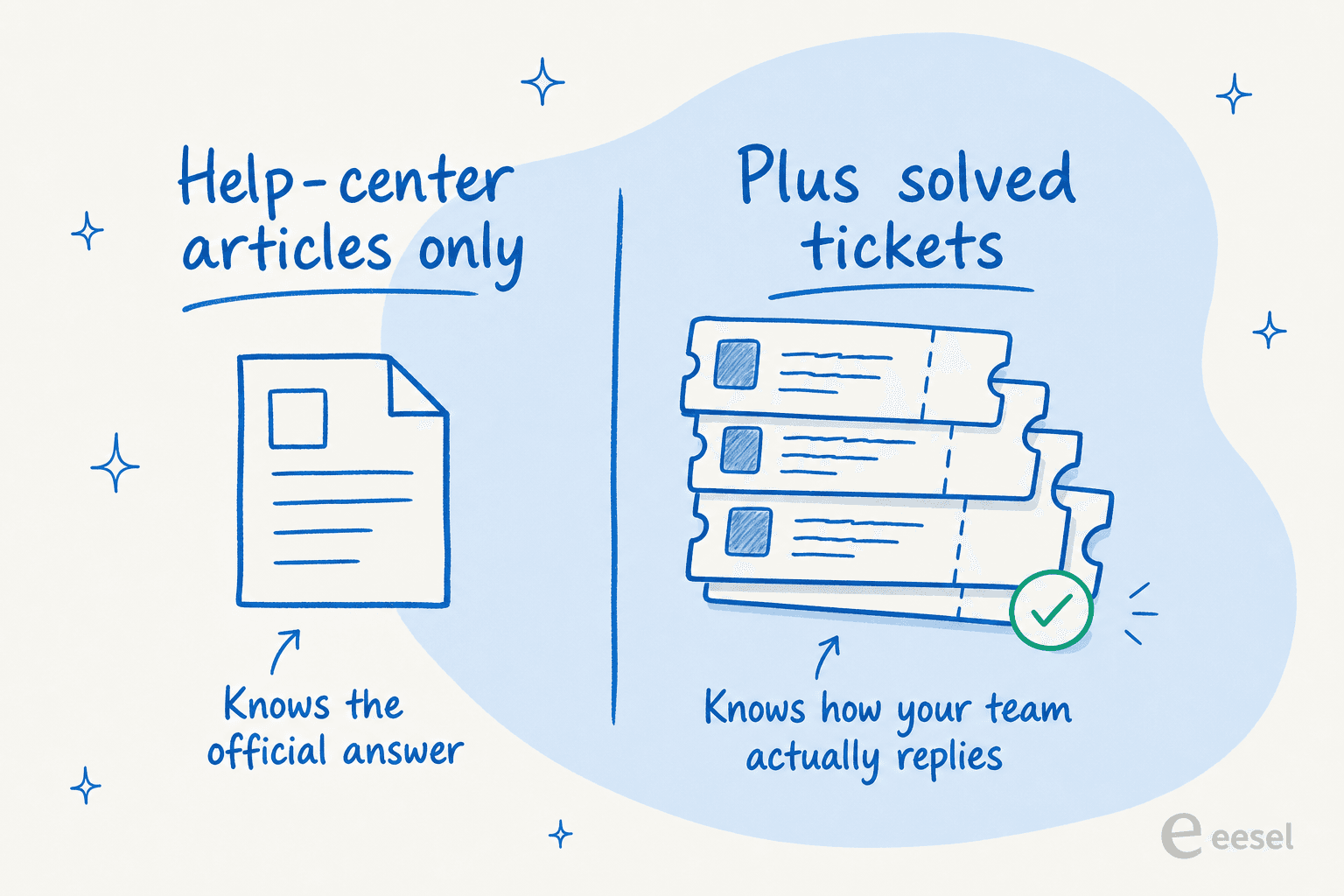
Der größte Fehler, den ich sehe, ist das Training ausschließlich auf Hilfecenter-Artikeln. Artikel vermitteln dem Agenten die offizielle Antwort; gelöste Tickets lehren ihn, wie das Team tatsächlich antwortet – in Ihrem Ton, auf die unordentlichen Fragen, die Kunden wirklich stellen. Ohne Ticket-Geschichte erhält man einen höflichen Bot, der klingt wie jemand anderes.
Die andere Hälfte ist Vertrauen. Ein Agent, der selbstsicher rät, ist schlimmer als gar kein Agent. Die Lösung ist, vor dem Launch zu simulieren und danach nach Konfidenz zu routen, sodass ein Ticket mit niedriger Konfidenz zu einem Entwurf oder einer sauberen Übergabe wird statt zu einer falschen Antwort. Wenn Sie das nicht selbst aufbauen möchten, ist das genau das, was eesel in Ihrem bestehenden Helpdesk tut – und Sie können einen kostenlosen Agenten trainieren und simulieren, bevor Sie irgendetwas bezahlen.
Ich entwickle KI-Agenten bei eesel, deshalb basiert das meiste davon auf der Beobachtung, was funktioniert (und was schiefgeht) bei tausenden von Live-Support-Rollouts. Den Vertrauensteil habe ich auf die harte Tour gelernt: Ich habe beobachtet, wie ein selbstsicher klingender Bot still falsche Antworten gab – deshalb simuliere ich jeden Rollout jetzt gegen die historischen Tickets eines Unternehmens, bevor er je einen Kunden berührt. So würde ich von Grund auf einen trainieren.
Was das Training eines KI-Support-Agenten wirklich bedeutet
„Training" klingt nach maschinellem Lernen: Daten beschriften, ein Modell feinabstimmen, auf einen abgeschlossenen Job warten. Bei einem modernen Support-Agenten ist das nicht so. Das zugrundeliegende Sprachmodell ist bereits trainiert. Was Sie tun, ist, es Ihr Unternehmen zu lehren: Ihre Richtlinien, Ihr Produkt, Ihre Stimme und die Grenzen dessen, was es tun darf.
Unter der Haube bedeutet das hauptsächlich Retrieval statt Fine-Tuning. Der Agent liest Ihr Wissen zur Antwortzeit und stützt jede Antwort auf eine zitierbare Quelle, anstatt Ihre Dokumente in seine Gewichte zu memorieren. Diese Unterscheidung hat einen praktischen Grund: Wenn Sie einen Hilfeartikel korrigieren, ist der Agent sofort „neu trainiert", ohne dass ein Modell-Job erneut ausgeführt werden muss. Es bedeutet auch, dass ein regelbasierter Chatbot und ein KI-Agent nicht dasselbe sind. Einer folgt Entscheidungsbäumen, die Sie manuell aufbauen; der andere denkt über Ihr Wissen nach und entscheidet selbst.
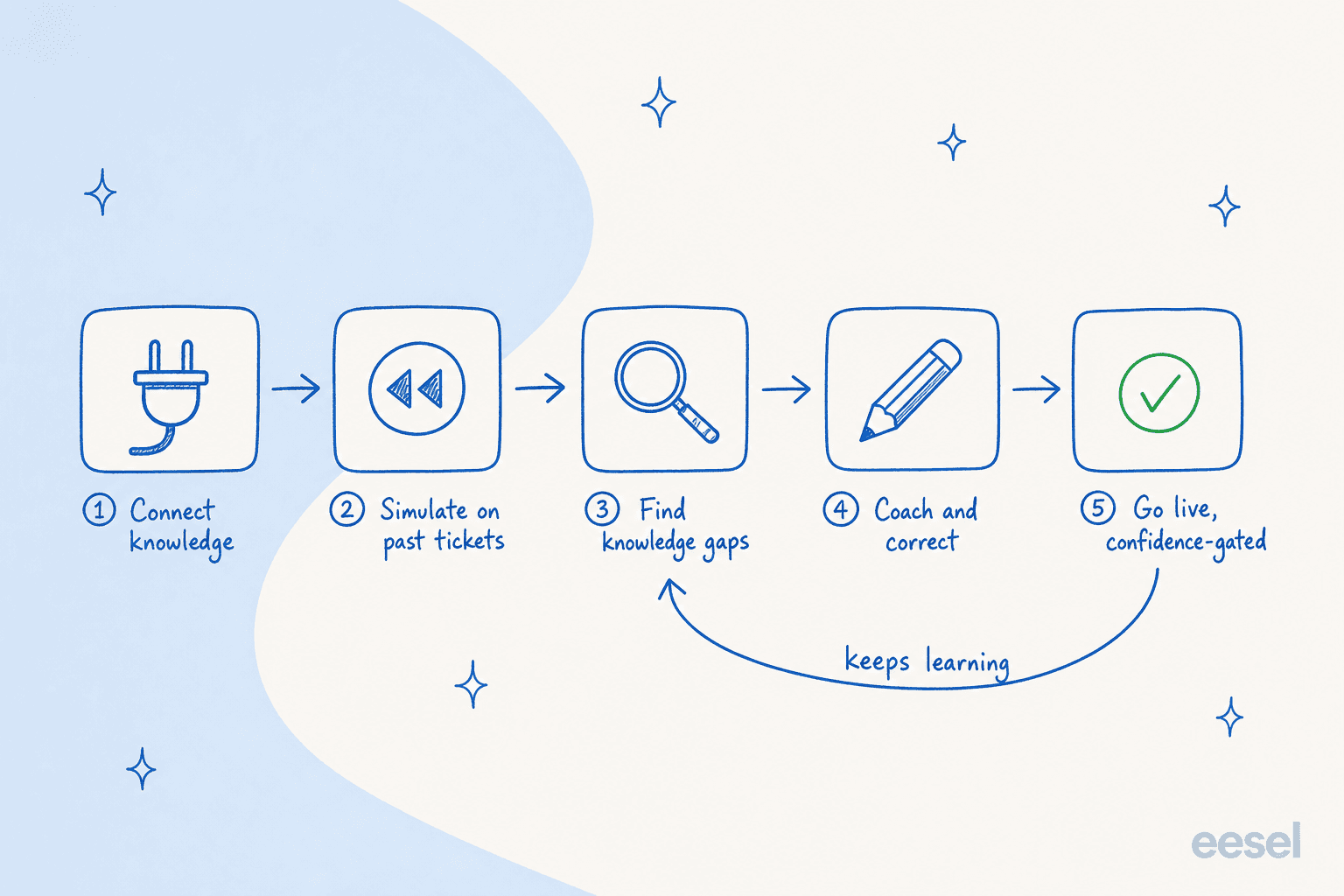
Die Aufgabe gliedert sich also in fünf Phasen, und der Kreislauf ist genauso wichtig wie die Schritte: Die letzte Phase speist nach dem Launch dauerhaft in den Agenten zurück.
Schritt 1: Das Wissen einspeisen, das zu Ihren Tickets passt
Alles Folgende hängt davon ab. Ein Agent ist nur so gut wie das, was er lesen kann, also ist die erste Aufgabe, ihn auf die richtigen Quellen in der richtigen Wertreihung zu zeigen.
Beginnen Sie mit Ihren gelösten Tickets. Das ist der Teil, den Teams überspringen, und der Teil, der am meisten zählt. Hilfecenter-Artikel sind für eine aufgeräumte Version einer Frage geschrieben; echte Tickets zeigen, wie Kunden tatsächlich fragen und wie Ihre besten Mitarbeiter tatsächlich antworten. Trainieren Sie auf den Tickets, und der Agent übernimmt Ihre Formulierungen, Ihren Erstattungswortlaut, Ihren „hier ist die Umgehungslösung, während wir das beheben"-Ton. Training auf vergangenen Tickets ist die am häufigsten gewünschte Funktion, die ich in Verkaufsgesprächen höre, und sobald ein Team den Unterschied in der Sprache sieht, hören sie auf danach zu fragen und fangen an zu fragen, warum nicht alle das machen.
Dann fügen Sie den Rest hinzu:
- Ihr Hilfecenter und öffentliche Dokumente, für die kanonischen Richtlinien- und Produktantworten.
- Internes Wissen, die Dinge, die nie in einen Artikel gelangt sind, in Confluence, Google Docs, Notion oder einem Slack-Kanal leben.
- Makros und gespeicherte Antworten, die im Wesentlichen vorab genehmigte Antworten sind, denen Ihr Team bereits vertraut.
- Bestell- und Kontodaten, über Tools wie Shopify, sodass der Agent „wo ist meine Bestellung" mit einer echten Abfrage statt einer Ablenkung beantworten kann.
Auf etwas ist zu achten: Wissen, das für eine Zielgruppe geschrieben, aber von einer anderen gelesen wird. Ich habe das mit einem Transit-Tech-Team durchgearbeitet, dessen Dokumente alle für Administratoren geschrieben waren, während ihre Tickets von alltäglichen Fahrgästen kamen. Der Agent hatte die Fakten, aber den falschen Tonfall. Die Lösung war nicht mehr Dokumente, sondern dem Agenten zu sagen, mit wem er spricht – ein Coaching-Schritt (Schritt 3), keine Wissenslücke. Gutes Wissensmanagement für den Support ist die halbe Miete beim Training eines Agenten.
Bei eesel ist die Verbindung davon der erste Bildschirm: Zeigen Sie auf einen Helpdesk wie Zendesk oder Freshdesk, fügen Sie Ihre Dokumente hinzu, und er indexiert sie mit 100+ Integrationen verfügbar. Wenn Sie mehrere Marken betreiben, können Sie einen separaten Agenten pro Marke trainieren, jeder lernt nur aus seiner eigenen Geschichte.
Schritt 2: Vor dem ersten Kundenkontakt gegen die eigene Geschichte simulieren
Das ist der Schritt, der einen verantwortungsvollen Rollout von einem optimistischen unterscheidet – und der eine, den die meisten Tools Ihnen nicht geben.
Bevor der Agent einem einzigen Live-Kunden antwortet, lassen Sie ihn gegen die bereits abgeschlossenen Tickets laufen. Sie kennen die richtigen Antworten, weil Ihr Team sie bereits geschrieben hat – eine Simulation sagt Ihnen also auf Ihren Daten, wie der Agent abgeschnitten hätte: wie viele Tickets er gelöst hätte, wo er gezögert hat und wo er selbstsicher falsch gewesen wäre. Diese letzte Kategorie ist die, nach der man suchen muss. Ein Bot, der „ich weiß nicht" sagt, ist lästig; ein Bot, der eine Rückerstattungsrichtlinie erfindet, ist ein Haftungsrisiko.
Das ist, wo ich den Drang widerstehen würde, früh live zu gehen. Die Versuchung nach einer sauber bestandenen ersten Antwort ist, ihn einzuschalten. Nicht tun. Lesen Sie die simulierten Antworten Ticket für Ticket, besonders die, die er falsch hatte, denn jede ist eine Coaching-Möglichkeit, die Sie kostenlos erhalten, bevor es Sie einen Kunden kostet.
Simulation ist auch, wie Sie eine ehrliche Prognose statt einer Marketing-Zahl des Anbieters erhalten. Sie sehen die voraussichtliche Lösungsrate des Agenten bei Ihrem echten Volumen – das ist die Zahl, die Ihre Launch-Entscheidung treiben sollte. Für ein Team, das dies durchführte, war die Rendite schnell:
„Im ersten Monat löst eesel 73 % unserer Tier-1-Anfragen... Ergebnisse schnell während unseres 7-tägigen Tests."
Kim Simpson, Gridwise (G2-Bewertung)
Schritt 3: In einfacher Sprache coachen, nicht in Code
Sobald Sie eine Liste von Antworten haben, die der Agent falsch hatte, korrigieren Sie diese. Die gute Nachricht ist, dass modernes Training gesprächsbasiert ist: Sie sagen dem Agenten, was er anders machen soll, so wie Sie einen neuen Mitarbeiter einweisen würden, statt eine Konfigurationsdatei zu bearbeiten.
Coaching nimmt meist einige Formen an:
- Die Quelle korrigieren. Wenn die Antwort falsch war, weil ein Hilfeartikel veraltet war, aktualisieren Sie den Artikel, und der Agent ist sofort korrigiert.
- Die Anweisungen anpassen. Ton, Länge, wann eskaliert wird, was nie gesagt werden soll. „Immer entwerfen, nie automatisch senden bei Abrechnungsfragen" ist eine einzeilige Anweisung, kein Workflow-Aufbau.
- Die Zielgruppe festlegen. Wie im Fahrgast-versus-Administrator-Fall oben können Sie dem Agenten sagen, interne, technische Dokumente in kundenfreundliche Antworten zu übersetzen.

Was hier zu überprüfen ist: dass das Coaching tatsächlich haftet. Ein Hundeschul-Kleinunternehmen, mit dem ich arbeite, brachte es gut auf den Punkt: Sie liebten es, dass der Agent beim erneuten Testen das Coaching korrekt einbezog, sodass sie sehen konnten, wie er lernt, statt es auf Treu und Glauben hinzunehmen. Diese Rückkopplungsschleife – etwas ändern, dann neu simulieren – ist das eigentliche Spiel. Wenn ein Tool Ihnen erlaubt zu coachen, aber nicht neu zu testen, bearbeiten Sie blind.
Hier bauen Sie auch Ihre Eskalationsregeln ein. Ein gut trainierter Agent weiß, was er nicht bearbeitet, und gibt das sauber weiter – was genauso wichtig ist wie die Fragen, die er beantwortet. Die Übergabe richtig zu gestalten sorgt dafür, dass Kunden sich nicht in einem Bot gefangen fühlen.
Schritt 4: Per Konfidenz absichern, bevor der Agent antwortet
Das ist die wichtigste Idee in diesem gesamten Leitfaden, und die, die Käufer am meisten beschäftigt. Sie müssen nicht zwischen „KI beantwortet alles" und „KI beantwortet nichts" wählen. Sie legen einen Konfidenzschwellenwert fest, und der Agent antwortet nur selbstständig, wenn er die Messlatte übertrifft.
Ein CX-Lead bei einer Nahrungsergänzungsmarke mit etwa 7.000 Tickets pro Monat sagte es direkter als ich es könnte: Die KI wird nie 100 % der Fragen beantworten, und das ist in Ordnung, aber „Ich brauche eine KI, die nur die Tickets bearbeitet, bei denen sie sicher ist, und alle anderen in Ruhe lässt." Das ist die gesamte These eines sicheren Rollouts. Hohe Konfidenz, automatische Antwort. Niedrige Konfidenz, Entwurf für einen Menschen oder Übergabe. Kein Raten.
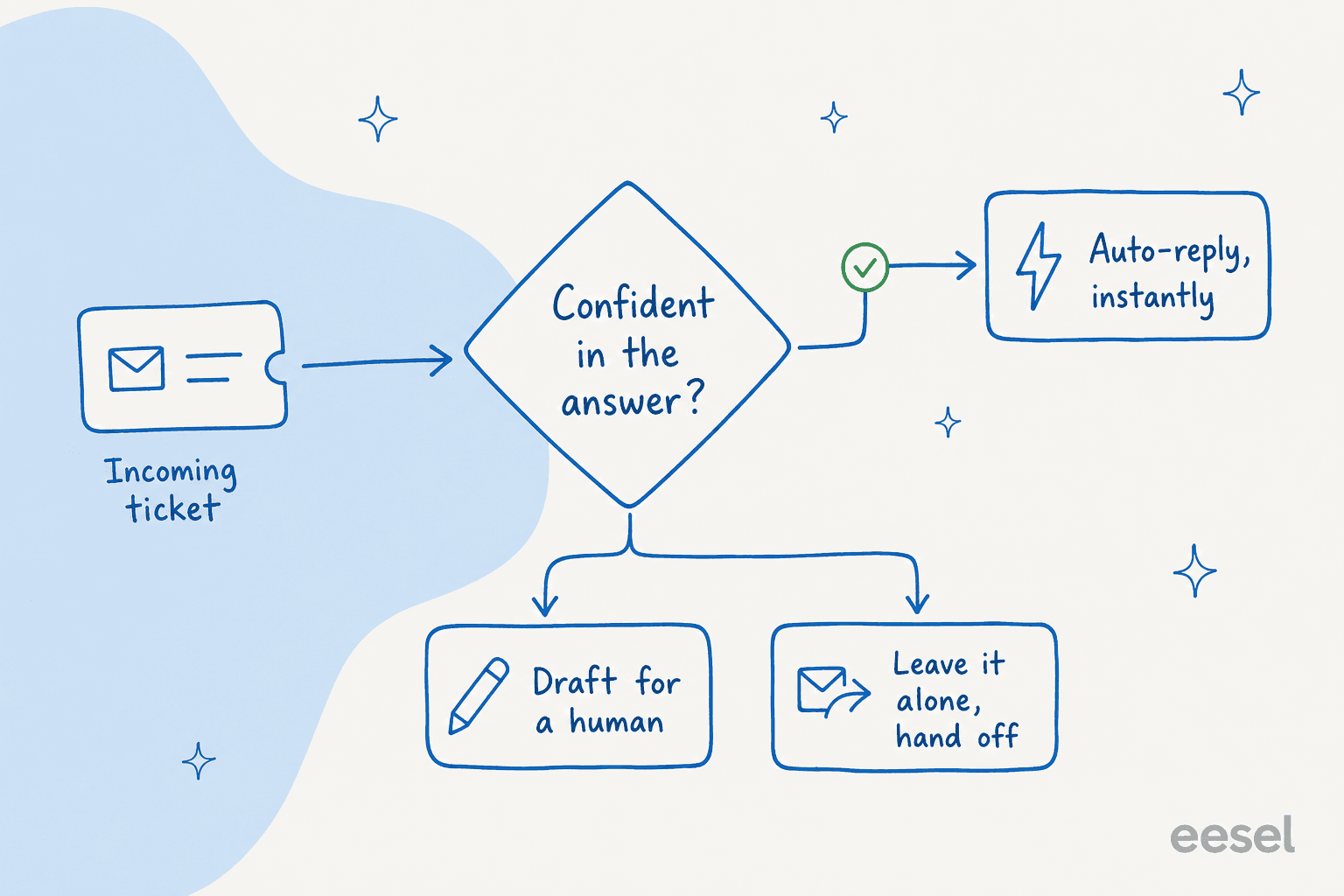
Konfidenzsteuerung ist auch, wie man sicher hochfährt. Starten Sie den Agenten im reinen Entwurfsmodus, sodass ein Mensch jede Antwort genehmigt, beobachten Sie die Qualität, geben Sie ihm dann Autonomie bei den Ticket-Typen, bei denen er sich bewährt hat – wie Passwort-Resets oder Bestellstatus –, während die schwierigen unter Aufsicht bleiben. Sie können auch ganze Kategorien vollständig von der Automatisierung ausschließen, was genau das ist, was Teams verlangen, wenn sie sagen „bestimmte Tickets sollen nicht durch KI laufen." Kombinieren Sie Konfidenz-Routing mit Quellenangaben bei jeder Antwort, und Sie haben die zwei stärksten Leitplanken gegen einen bluffenden Bot. Dieser stufenweise Ansatz ist das Fundament jedes vernünftigen Plans zur Tier-1-Deflection.
Schritt 5: Nach dem Launch weiter trainieren
Training ist kein Launch-Meilenstein, den man abhakt und vergisst. Die besten Agenten werden jede Woche besser, weil das Team die Schleife am Laufen hält.
Drei Gewohnheiten halten einen Agenten scharf:
- Die Fehler überprüfen. Beobachten Sie die Tickets, die der Agent entworfen oder eskaliert hat, und die, bei denen ein Kunde zurückgedrückt hat. Jedes ist ein Coaching-Input, wie in Schritt 3.
- Die gefundenen Lücken füllen. Ein guter Agent zeigt die Themen auf, nach denen er immer wieder gefragt wird, für die er aber keine Quelle hat, damit Sie den Artikel schreiben können (oder ihn für Sie entwerfen lassen). Hier verbessern sich Ihre Wissensdatenbank und Ihr Agent gegenseitig.
- Trends beobachten, nicht nur Tickets. Support-Metriken wie Lösungsrate, Eskalationsrate und Bearbeitungszeit zeigen, ob das Training zahlt oder still abdriftet.

Ein netter Nebeneffekt: Ein gut trainierter KI-Agent fungiert auch als Coach für das menschliche Team. Ein Kleinunternehmen erzählte mir, sie seien am meisten begeistert davon, dass neue Mitarbeiter „einen 24/7-Supervisor haben, der sie coacht, wie sie mit Anfragen umgehen sollen", weil die Entwürfe des Agenten neueren Mitarbeitern zeigen, wie eine gute Antwort aussieht. Das Training des KI hebt das gesamte Team, nicht nur die Ticket-Ablenkung.
Häufige Fehler beim Training eines KI-Support-Agenten
Die Fehlermuster sind vorhersehbar, also hier ist, was zu vermeiden ist:
- Nur auf Dokumente trainieren. Oben bereits erläutert, aber es ist der häufigste Fehler Nummer eins. Keine Ticket-Geschichte bedeutet keine Stimme.
- Ohne Simulation live gehen. Wenn Sie nicht sehen können, wie der Agent auf Ihren eigenen vergangenen Tickets abschneidet, starten Sie auf Hoffnung. Bestehen Sie zuerst auf einem ordentlichen Test.
- Alles-oder-nichts-Autonomie. Den Agenten am ersten Tag auf vollautomatische Antwort zu schalten, ist der Weg zu den Horrorgeschichten. Hochfahren mit Konfidenz-Steuerung.
- Setup als einmalig behandeln. Ein Agent, der im Januar auf die Richtlinien des Januars trainiert wurde, wird bis März falsch liegen, wenn niemand die Schleife am Laufen hält.
- Keine saubere Übergabe. Ein Agent, der nicht angemessen eskalieren kann, hält Kunden gefangen. Bauen Sie den Eskalationspfad vor dem Launch, nicht nach den Beschwerden.
Wenn Sie das richtig machen, hört Training auf, sich wie ein Projekt anzufühlen, und fängt an, sich wie die Betreuung eines Teammitglieds zu fühlen, das zufällig sehr schnell lernt. Wenn Sie die tiefere Version der Vertrauensseite möchten, geht mein Leitfaden zur Verhinderung von Halluzinationen weiter, und der Helpdesk-Agent-Überblick vergleicht die Tools, die das einfach machen, mit denen, die es mühsam machen.
eesel ausprobieren
Wenn Sie lieber einen Agenten trainieren als eine Trainingspipeline aufbauen wollen, ist das der ganze Punkt von eesel. Es bindet sich in Ihren bestehenden Helpdesk ein, lernt ab Tag eins aus Ihren vergangenen Tickets und Dokumenten und ermöglicht Ihnen, gegen Ihre Ticket-Geschichte zu simulieren, bevor ein einziger Kunde eine Antwort sieht – damit Sie auf Evidenz statt auf Optimismus starten.
Das Unterscheidungsmerkmal, auf das ich hinweisen würde, ist diese Simulations-plus-Konfidenz-Schleife: Sie erhalten eine echte Lösungsprognose auf Ihren eigenen Daten, coachen in einfacher Sprache und kontrollieren genau, welche Tickets die KI berühren darf. Die Preisgestaltung ist nutzungsbasiert ohne Pro-Seat-Gebühren, und die kostenlose Testversion gibt Ihnen 50 $ Nutzung zum Trainieren und Testen eines Agenten, bevor Sie sich verpflichten.
Häufig gestellte Fragen
Wie trainiert man einen KI-Support-Agenten?
Wie lange dauert es, einen KI-Kundensupport-Agenten zu trainieren?
Welche Daten benötigt man zum Training eines KI-Support-Agenten?
Kann man einen KI-Support-Agenten auf vergangenen Tickets trainieren?
Wie verhindert man, dass ein trainierter KI-Support-Agent falsche Antworten gibt?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








