KI-Wissensdatenbank-Artikelschreiber: wie man ihn wirklich nutzt (2026)
Kurnia Kharisma Agung Samiadjie
Katelin Teen
Zuletzt bearbeitet June 23, 2026

Kurzfassung
Ein KI-Wissensdatenbank-Artikelschreiber erstellt Hilfecenter- und Wissensdatenbank-Artikel aus Quellen, die Sie bereits haben – wie gelöste Tickets, verstreute Dokumente und die Antworten, die Ihre Agenten täglich senden –, anstatt auf einer leeren Seite anzufangen. Der Wert liegt nicht in der Geschwindigkeit, sondern darin, das Wissen, das Ihr Team bereits hat, in Artikel zu verwandeln, die Ihre Kunden tatsächlich finden können.
Der häufigste Fehler: Teams richten eine KI auf eine Marketing-Seite oder ihr internes Wiki aus und veröffentlichen, was dabei herauskommt. Das Ergebnis liest sich gut und hilft niemandem, weil es für den falschen Leser geschrieben wurde. Die guten Tools verankern jeden Entwurf in Ihren echten Inhalten, schreiben für die Person, die die Frage tatsächlich stellt, und kennzeichnen die Lücken, wo gar kein Artikel vorhanden ist.
Ich arbeite im Bereich Content und SEO bei eesel AI, und wir haben jahrelang beobachtet, wie KI echte Support-Tickets aus echten Wissensdatenbanken beantwortet. Das hier ist also kein Tool-Vergleich. Es geht darum, was ein KI-Wissensdatenbank-Artikelschreiber tut, wie die wirklich nützlichen funktionieren und welcher Workflow Artikel hervorbringt, die ihren Platz verdienen – plus wo eesel passt, wenn Sie möchten, dass das Schreiben und Beantworten aus derselben Quelle laufen.
Was ein KI-Wissensdatenbank-Artikelschreiber wirklich tut
Ohne Marketing-Sprache ist die Aufgabe klar umrissen: Wissen, das in Tickets, Chats und halbfertigen Dokumenten steckt, in einen sauberen, strukturierten Artikel verwandeln, den ein Kunde lesen und daraus selbst helfen kann.
Das ist eine andere Aufgabe als ein allgemeiner KI-Texter oder ein KI-Content-Generator für Blog-Beiträge. Ein Blog-Beitrag kann lose korrekt sein und trotzdem seinen Zweck erfüllen. Ein Wissensdatenbank-Artikel, der lose korrekt ist, erzeugt ein Ticket – oder schlimmer: eine falsche Handlung des Kunden. Die Messlatte ist also: Genauigkeit zuerst, Schliff danach.
In der Praxis erledigt ein guter Schreiber drei Dinge:
- Zieht aus Ihren Quellen, nicht aus seiner Fantasie. Gelöste Tickets, Ihr bestehendes Hilfecenter, interne Dokumente in Notion oder Google Docs, Agenten-Makros, Release-Notes. Der Artikel ist eine Umstrukturierung dessen, was Sie bereits wissen – die KI übernimmt die Struktur.
- Schreibt in Ihrer Stimme und Ihrem Format. Schritt-für-Schritt-Listen für Anleitungen, kurze Antworten für FAQs, die Überschriften und den Ton Ihrer bestehenden Artikel. Hier spielt das Training der Markenstimme eine Rolle, damit ein neuer Artikel nicht wirkt, als käme er von einem anderen Unternehmen.
- Sagt Ihnen, was Sie als nächstes schreiben sollen. Die besten Tools sehen, wonach Kunden suchen und was sie in Tickets fragen, und zeigen dann die Themen auf, zu denen noch kein Artikel existiert.
Dieser letzte Punkt ist derjenige, über den Teams hinwegsehen – und er ist meistens der Bereich, in dem die Zeit tatsächlich gespart wird.
Der Fehler, der den gesamten Aufwand still vergeudet
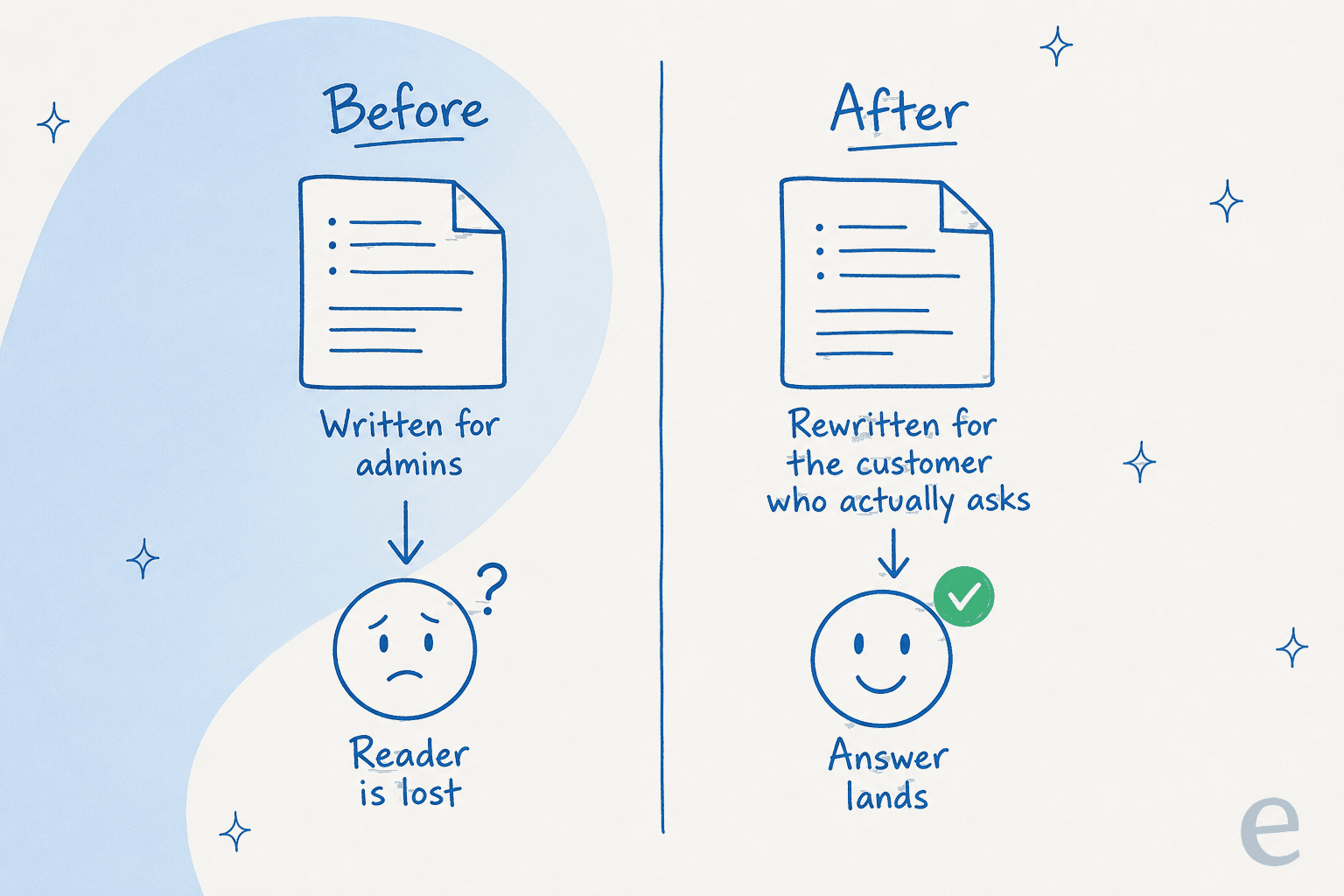
Hier ist der Fehler, den ich mehr Wissensdatenbank-Projekte hat scheitern sehen als jede Modellbeschränkung: Die Artikel werden für den falschen Leser geschrieben.
Ich habe in Gesprächen mit einem Support-Manager eines Bus-Tracking-Dienstes gesessen, der ein paar hundert Zendesk-Tickets pro Monat bearbeitet und dessen gesamte Wissensdatenbank für Administratoren geschrieben war – während jedes einzelne Ticket von Fahrgästen kam. Die Dokumente waren technisch korrekt und für die Menschen, die sich meldeten, völlig nutzlos. Eine KI, die auf diese Dokumente gerichtet wird, produziert einfach schneller mehr Artikel für Administratoren. Sie haben das Falsche automatisiert.
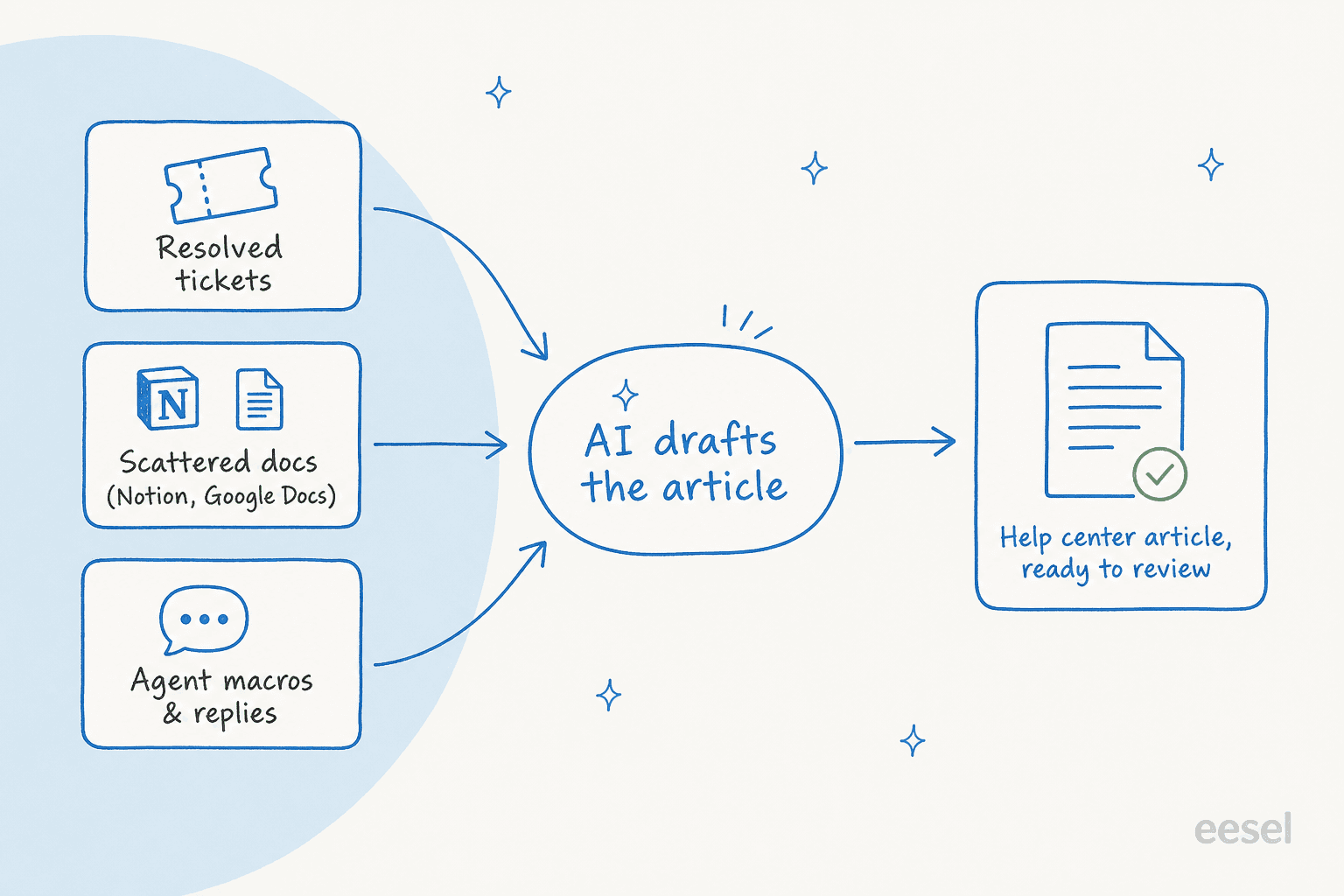
Genau deshalb ist es besser, der KI Ihre gelösten Tickets zu übergeben, als Ihre vorhandenen Dokumente. Tickets enthalten die Frage in den eigenen Worten des Kunden, die Formulierung, die er tatsächlich verwendet, das, worüber er verwirrt war. Ein aus dieser Quelle generierter Artikel beantwortet die echte Frage. Ein aus einer internen Spezifikation generierter Artikel beantwortet eine Frage, die niemand gestellt hat.
Prüfen Sie daher bei jedem Tool zuerst, woraus es liest. Ein Schreiber, der nur Ihre aktuellen Dokumente aufnimmt, reproduziert zuverlässig alles, was daran falsch ist. Der Sinn eines KI-Wissensdatenbank-Artikelschreibers ist es, die Lücke zwischen dem, was Sie dokumentiert haben, und dem, was die Leute tatsächlich fragen, zu schließen – nicht Ihre bestehenden Dokumente zu vervielfältigen.
Wie die guten wirklich funktionieren
Wenn die Quellen stimmen, ist der Mechanismus, der ein nützliches Tool von einem Spielzeug unterscheidet, die Verankerung: Schreibt die KI nur aus abgerufenem Inhalt, oder greift sie auf ihre Trainingsdaten zurück, wenn sie keine Antwort findet?
Das ist dasselbe Problem, das einen KI-Wissensdatenbank-Chatbot vertrauenswürdig oder gefährlich macht, und es lohnt sich, es zu verstehen, weil die Schreibseite dasselbe Risiko hat. Wenn das Retrieval nichts zurückgibt und das Modell trotzdem antwortet, entsteht selbstsichere Fiktion. Wir haben gesehen, wie Bots von zahlenden Kunden Produktaussagen erfunden und an echte Personen gesendet haben, einfach weil die Wissensdatenbank keinen passenden Eintrag hatte und das Modell die Stille füllte. Ein Artikelschreiber mit demselben Fehler erstellt bereitwillig eine Anleitung für eine Funktion, die es nicht gibt.
Die entscheidenden Fragen für jeden KI-Dokumentationsassistenten:
- Zitiert er das Quelldokument hinter jedem Abschnitt, damit ein Prüfer es nachvollziehen kann?
- Lehnt er ab oder kennzeichnet er, wenn er keine verankerte Quelle hat, anstatt zu raten?
- Kann er auf Ihrer Wissensdatenbank trainieren und auf Ihren vergangenen Tickets – nicht nur auf einem von beidem?
Wenn Sie aus diesem Abschnitt eine Sache mitnehmen: Ein Tool, das zugibt „Ich habe dafür keine Quelle", ist mehr wert als eines, das immer eine Antwort hat. Das selbstsichere ist das, das Ihnen Probleme bereitet.
Selbst bauen oder kaufen?
Eine berechtigte Frage, besonders wenn Sie Entwickler haben: Warum nicht die OpenAI- oder Claude-API an Ihre Dokumente anschließen und selbst entwickeln? Karel von GENERAL BYTES, der eesel AI mit Confluence und Telegram verbindet, hat den Kompromiss klar auf den Punkt gebracht:
„Wir könnten versuchen, unsere eigene LLM-Anwendung zu schreiben, aber wir wollten unsere Zeit nicht dafür aufwenden. Wir wollten etwas, das wir nicht warten müssen."
Karel, GENERAL BYTES (Fallstudie)
Das ist die ehrliche Rechnung. Der erste Entwurf einer Retrieval-plus-Schreib-Pipeline ist Sache eines Wochenendes. Sie aktuell zu halten, wenn sich Ihre Dokumentation ändert, Ihr Produkt weiterentwickelt wird und Randfälle sich anhäufen, ist eine dauerhafte Aufgabe. Für die meisten Teams ist die Wartung der Kostenfaktor, nicht der Aufbau.
Ein Workflow, der Artikel hervorbringt, die es wert sind, behalten zu werden
Abgesehen von den Tools: Hier ist die Schleife, die ich tatsächlich einsetzen würde. Sie funktioniert, egal ob Sie ein speziell entwickeltes Tool verwenden oder KI-Hilfe beim Schreiben manuell zusammenstellen.
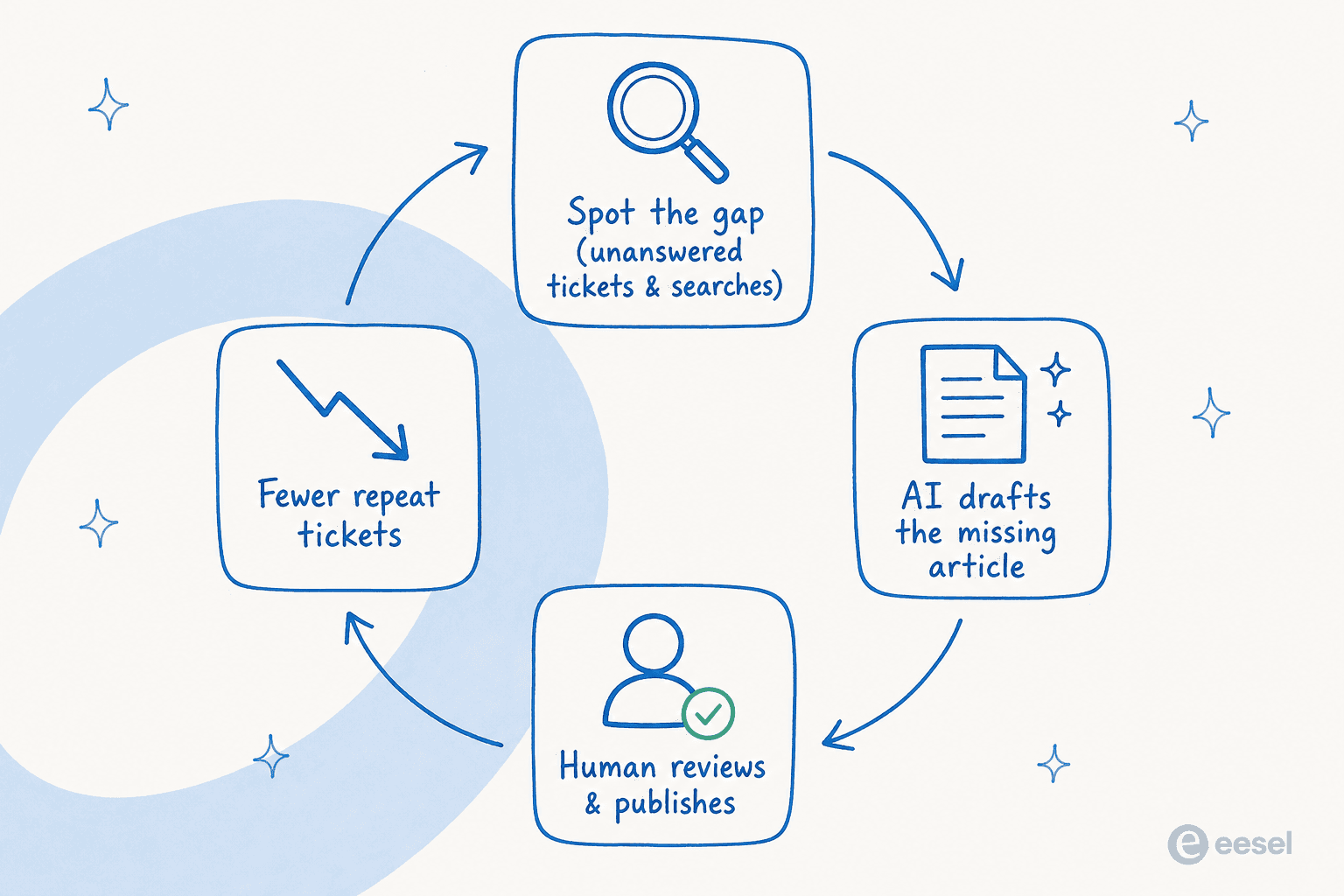
- Finden Sie die Lücke, bevor Sie schreiben. Beginnen Sie nicht mit einem Content-Kalender, sondern mit der Nachfrage. Ziehen Sie die Tickets heraus, die immer wiederkehren, und die Suchanfragen, die auf eine Hilfecenter-Lücke treffen. Das sind Ihre Artikelthemen, gerankt nach dem Schmerz, den sie verursachen.
- Entwerfen Sie aus dem gelösten Ticket, nicht aus der Spezifikation. Übergeben Sie der KI das tatsächliche Gespräch, in dem ein Agent es gelöst hat. Die Antwort, die Ihr Agent bereits geschrieben hat, ist zu 80 % der Artikel – in der Sprache des Kunden.
- Behalten Sie einen Menschen im Prüfsitz. KI entwirft, eine Person genehmigt. Das ist kein Ritual, sondern der Moment, in dem Sie die eine falsche Zahl oder den Schritt erkennen, der sich im letzten Release geändert hat. Der Prüfer sollte Fakten überprüfen, nicht Prosa umschreiben.
- Veröffentlichen Sie in der Quelle, die Ihr Support bereits liest. Ein Artikel lenkt nur dann Tickets ab, wenn sowohl Ihre Agenten als auch Ihr Bot ihn sehen können. Das ist das Argument dafür, Schreiben und Beantworten auf einer Plattform zu halten.
- Aktualisieren Sie nach einem Zeitplan. Verwenden Sie KI, um veraltete Hilfecenter-Inhalte zu kennzeichnen, damit Sie den veralteten Artikel korrigieren, bevor ein Kunde ihn findet. Das ist der Unterschied zwischen einer Wissensdatenbank und einem Friedhof.
Führen Sie diese Schleife durch, und die Anzahl der Artikel hört auf, die Kennzahl zu sein. Stattdessen zählt: Wiederholungs-Tickets gehen zurück.
Welcher Ansatz passt zu Ihrem Team?
Die meisten Teams landen je nach Volumen und dem Ort, an dem ihr Wissen bereits lebt, an einem von drei Punkten. Schnelle Selbsteinschätzung:
Wo lebt Ihr Wissen derzeit?
Wo es schiefläuft
Ein paar Fallstricke, die es wert sind, benannt zu werden, weil sie vorhersehbar sind:
- Veralteter Inhalt, den niemand besitzt. KI macht das Schreiben günstig, was bedeutet, es ist einfach, 200 Artikel zu veröffentlichen und keinen zu aktualisieren. Eine größere Wissensdatenbank, die veraltet ist, ist schlechter als eine kleine, die aktuell ist. Das ist wirklich ein Problem des Wissensdatenbank-Managements, und es beißt still.
- Zielgruppen-Drift. Wir haben es oben behandelt, aber es kehrt wieder: Prüfen Sie alle paar Monate, ob neue Artikel noch dazu passen, wie Kunden Dinge formulieren – nicht wie Ihr Produktteam es tut.
- Das Wiki, das zum Sumpf wird. Interne Dokumente und kundenseitige Artikel sind unterschiedliche Aufgaben. Wenn Sie auch eine interne Wissensdatenbank verwalten, halten Sie die beiden klar getrennt, sonst mischt Ihre KI interne Fachbegriffe in öffentliche Artikel.
- Einquellen-Scheuklappen. Ein Schreiber, der nur Dokumente liest, verpasst Tickets; einer, der nur Tickets liest, verpasst Ihre Release-Notes. Starkes KI-Wissensmanagement für Support-Teams zieht gleichzeitig aus allem.
Das sind keine Modellprobleme. Es sind Prozessprobleme, und ein Tool, das die Schleife in seine Funktionsweise einbaut, bewahrt Sie vor den meisten davon.
eesel für das Schreiben und Beantworten ausprobieren
Wenn Sie möchten, dass das Schreiben von Artikeln und das Beantworten von Tickets aus demselben Gehirn laufen, ist das die Wette, die eesel AI eingeht. Es verbindet sich mit Ihrem Help-Desk und Ihren Dokumenten – ob das Zendesk, HubSpot, Confluence oder Jira ist –, lernt aus Ihren vergangenen Tickets und erstellt Antworten und Artikel, die in diesem Inhalt verankert sind, anstatt zu raten.
Das Stück, das mit diesem gesamten Beitrag zusammenhängt: Weil dieselbe Engine, die Artikel entwirft, auch Tickets beantwortet, tauchen die Lücken auf natürliche Weise auf. Wenn die KI etwas nicht sicher beantworten kann, ist das Ihr nächster Artikel – bereits identifiziert. Ein Kunde verwaltet eine wirklich große Wissensdatenbank mit eesel AI und tut genau das, und ein anderes Team hat uns mitgeteilt, dass ihre Agenten aufgehört haben, in Notion und Google Docs zu suchen, weil die KI das Retrieval für sie übernimmt.
Sie können es in Ihren bestehenden Stack integrieren, auf Ihre Tickets und Dokumente richten und beobachten, wie es gegen Ihre echte Geschichte entwirft, bevor Sie sich festlegen. Es ist kostenlos auszuprobieren und funktioniert wie ein Teammitglied, das Ihr Hilfecenter bereits gelesen hat. Wenn Sie noch Optionen vergleichen, stellt unser Überblick über KI-Wissensdatenbank-Tools und Wissensmanagement-Software das Feld dar, und unser Beitrag zu den Vorteilen einer KI-gestützten Wissensdatenbank erklärt das Warum.